In my previous article, I talked about what to look for once you have a performance issue with Apps 11i. In this article, I’ll discuss four maintenance activities that you can do proactively to reduce the chances of encountering certain types of performance issues:
- Check performance against a baseline
- Follow a regular purging schedule
- Gather schema statistics regularly
- Follow a systematic pinning strategy
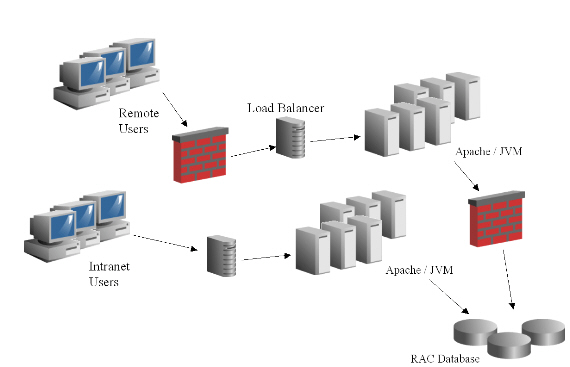
1. Check Performance Against a Baseline
- Create a baseline so you can monitor performance in response to changes or over time. For example, you may create 6-10 repeatable short transactions of at least 10 seconds each, which represent common functions and/or areas of particular concern.
- Always execute this baseline test from the same PC and the same location in order to get consistent results.
- Rerun the test as part of your normal User Acceptance Testing for any system changes.
- Review and update your performance baseline as part of any upgrade project.
2. Follow a Regular Purging Schedule
Concurrent Jobs to Purge Data
Most customers will need to schedule these Concurrent Purge processes:
- Purge Obsolete Workflow Runtime Data (FND)
- Purge Debug Log and System Alerts (FND)
- Purge Signon Audit data (FND)
- Workflow Control Queue Cleanup (FND)
- Delete Data from Temporary Tables (ICX)
Naturally, your business requirements may be unique; review our purging documentation for suitability and establish your own list of jobs to run.
Workflow Specific Purging Tips
Review the following documents for Workflow-specific tips on purging:
3. Gather Schema Statistics Regularly
- Speeding Up And Purging Workflow (Metalink Note 132254.1)
- FAQ on Purging Oracle Workflow Data (Metalink Note 277124.1)
In general, running this monthly to bi-weekly should be sufficient with 10%, unless there is any known data skew. As with any generic suggestion, this would need to be proven for suitability on your own environment. For example, it is more important to run this when your data distribution changes, rather than when the amount of data changes.
If your environment is a 24×7 system, you should pick “N” for “Invalidate Dependent Cursors” to prevent fragmentation of the shared pool
For more details about gathering statistics, see:
- This recent article from my fellow blogger, Avanish Srivatsan
- How To Gather Statistics For Oracle Applications 11i (Metalink Note 122371.1)
Despite new 10g features making ORA-4031 errors a rare occurrence, it is still recommended to have a pinning strategy, even with Apps 11.5.10 running on 10gR2 databases.
General guidance
- Monitor X$KSMLRU for candidates to pin (> 4100 bytes)
- Do not pin more than 20% of the Shared Pool
- Review your Pinning Strategy for changing business cycle, such as month end or overnight batch runs
- No need to pin objects used only for batch jobs
- Also have an “un-pinning” strategy
- Pinning Oracle Applications Objects into the Shared Pool (Metalink Note 69925.1). This Note is Apps 11i specific, but you will still need to manually interpret and act on the scripts provided.
- ORA-4031 and DBMS_SHARED_POOL.KEEP remarks and PIND toolkit overview (Metalink Note 311689.1) and Toolkit for dynamic marking of Library Cache objects as Kept (PIND) (Metalink Note 301171.1) describe a generic automated script (PIND) but this shouldn’t be used unmodified with Apps 11i
Conclusion
Running regular maintenance tasks and ongoing monitoring are essential activities to ensure that your system is performing to the best of its ability. This article highlights a few of the areas that are sometimes overlooked in Apps DBA schedules.
Related
