皆さんこんにちは、ゴールデンウィークはゆっくり休めましたでしょうか。
今回は、第12回で説明した「I/O周りについて」の続きとして、最近のストレージについて説明しようと思います。益々データ量は増加する傾向だと思いますので、データベースに対するI/O性能は更に重要になりますので、参考にしてください。
1. データファイルのI/Oについて
まずは、Oracleデータベースのデータファイルに対するI/Oについてもう少し説明しましょう。
第12回で少し説明したOracleデータベースのI/Oは、データファイルに対するものが大部分ですので、これを効率化するのが重要になります。そのデータファイルに対するI/Oには、通常のDBバッファ・キャッシュ(DBキャッシュ)を経由するI/O(非ダイレクトI/O)と経由しないI/O(ダイレクトI/O)があることは何回か説明してきました。それぞれのI/Oがどのようなときに行われて、どのようにボトルネックになるかを意識することも重要になります。ここからは、そのようなことについて説明していきます。
(1)非ダイレクトI/O
Oracleデータベースの性能といえば、DBキャッシュのヒット率を意識する人が多いと思いますが、これは正確には非ダイレクトI/Oの索引スキャンなどに対してのみになります(高速全索引スキャンは、全表スキャンと同じフル・スキャンなのでダイレクトI/Oになる場合があります)。一般的なデータベース処理では、索引スキャンがメインになりますので、ほとんどのシステムはDBキャッシュのヒット率を改善することで性能が向上します(通常のUPDATE/DELETE/INSERTも非ダイレクトI/Oになります)。ただし、ダイレクトI/Oが多いシステムでは、DBキャッシュを増やしても効果があまりありませんので、何がボトルネックになっているかは重要です。以下に、非ダイレクトI/Oのときの代表的な待機イベントとパフォーマンス統計情報を載せておきましたので、参考にしてください(DBキャッシュ上のブロック使用中とI/O待機になりますので、I/O性能以外にブロック競合の改善が必要になる場合があります。ブロック競合については第4回を参照してください)。
| 待機イベント | db file sequential read | 索引スキャンの待機(キャッシュ・ヒット率が低いと増加) |
| db file scattered read | 全表スキャンの待機(キャッシュ・ヒット率が低いと増加) | |
| db file parallel write | DBWRによる書込みの待機 | |
| db file parallel read | リカバリ中、第13回のPrefetching機能の読込みの待機 | |
| buffer busy waits | バッファが使用可能になるまで待機(ブロック使用中) | |
| read by other session | 別セッションの読込みが完了するまで待機(ブロック使用中) | |
| write complete waits | バッファの書込みが完了するまで待機(ブロック使用中) | |
| free buffer waits | 空きバッファ取得が完了するまで待機(DBキャッシュ不足による書込み終了待ち) | |
| パフォーマンス統計情報 | physical reads cache (①) | ディスクからDBキャッシュに読込んだDBブロックの合計数 |
| physical writes from cache | DBキャッシュからディスクに書込んだDBブロックの合計数 | |
| consistent gets from cache (②) | DBキャッシュからブロックの読取り一貫性が要求された回数(キャッシュ・ヒット率の論理リードに含む) | |
| db block gets from cache (③) | DBキャッシュからCURRENTブロックが要求された回数(キャッシュ・ヒット率の論理リードに含む) | |
| recovery block gets from cache (④) | リカバリ中にDBキャッシュからブロックが要求された回数(キャッシュ・ヒット率の論理リードに含む) |
キャッシュ・ヒット率は”(1-①/(②+③+④))*100”になり、AWRやStatspackではこれで計算しています。
(2)ダイレクトI/O
パラレル・フル・スキャン(パラレル全表スキャンなど)を行うとLong Tables(大きいテーブル)の場合にダイレクトI/Oになります(これは第13回で少し説明しましたよね)。Oracle Database 11gR2からは、シリアル全表スキャンでもダイレクトI/Oを行うようになっています(実行される閾値は異なります)。また、APPENDインサート(パラレル・ダイレクト・パス・インサートまたはAPPENDヒント)を行ってもダイレクトI/Oになります(これは第15回で少し説明しましたよね)。読込みについては、大きいテーブルを全表スキャンするとダイレクトI/Oになりますが、テーブルの大きさの閾値はDBキャッシュの大きさに依存しますので、変化する場合があります(つまり、DBキャッシュを大きくするとダイレクト・リードから非ダイレクト・リードになる場合があるということです)。ダイレクトI/Oを多くしたい場合は、DBキャッシュを小さくすることも必要です。また、複雑なSQLではPGAを多く使用するため、ダイレクトI/Oが多いかを意識してメモリ・チューニングすると効果的です。以下に、ダイレクトI/Oのときの代表的な待機イベントとパフォーマンス統計情報を載せておきましたので、参考にしてください(I/O待機のみになりますので、I/O性能の改善が必要です)。
| 待機イベント | direct path read | ダイレクト・フル・スキャン |
| direct path write | ダイレクト・パス・インサート | |
| パフォーマンス統計情報 | physical reads direct(①) | DBキャッシュをバイパスしてディスクから直接読込んだ合計数 |
| physical writes direct | DBキャッシュをバイパスしてディスクへ直接書込んだ合計数 | |
| physical reads(②) | ①を含んだ物理読込みの合計数 | |
| physical writes | 物理書込みの合計数 |
ダイレクト・リードの割合は”(①/②)*100”で分かります。
(3)I/Oの性能基準
ここでは、I/Oの性能基準について説明します。
非ダイレクトI/Oで行う索引スキャンなどのランダム・アクセスは、サイズが小さいI/Oになります(データファイルはDBブロック・サイズになります)。これの性能基準は、IOPS(1秒間に処理できるI/O要求数)になります。これをストレージがどのくらい実行できるかで性能が決まります。ただし、搭載されるHDD(Hard Disk Drive)の性能は、格納位置やアクセス順(シーク幅など)によって多少の変化はありますので注意が必要です。それに対して、全表スキャンなどのシーケンシャル・アクセスは、ストレージの性能も必要ですが、I/O帯域幅(GB/Sなどの1秒間に転送できるサイズ)の方が重要になるます(これは、マルチ・ブロック・リードなどの1回のI/Oサイズが大きくなるからです。Oracleデータベースは、最大1Mバイトで行います)。一般的には、FC(ファイバチャネル)などのインタフェースが限界になる場合が多いと思います。このようにI/O性能を向上するといっても、様々なことを考慮してリソースの追加をする必要があるため、I/O性能を改善するのは難しい訳です。一般的には、以下のように問題を改善します。
- IOPSの限界
これは、HDDの性能の限界ですので、高速なHDDに交換する、HDDの数を増やす、RAID方式を変更する、キャッシュを増やすなどで改善します。 - I/O帯域幅の限界
これは、インタフェース(FCなど)の限界ですので、高速なインタフェースの使用、サーバー側のHBA(ホスト・バス・アダプタ)やストレージ側のCHA(チャネル・アダプタ)を増やす、データ圧縮をしてデータ量を削減するなどで改善します。ただし、サーバーマシンなどによってインタフェースの数の制限や性能の限界があります。 - ホットスポット
これは、処理が集中して時間が掛かる部分を言いますので、アクセスが集中しないようにデータ配置を調整して改善しますが、発生する箇所が変化して解決が簡単ではありません(ほとんどのI/O性能問題は、これが原因になっていると思います)。
2. 最近のストレージとI/Oチューニング
ここからは、最近のストレージとそのI/Oチューニングについて説明しましょう。
Oracleデータベースは、データ容量の増加などでI/Oのチューニングが益々複雑になってきています。そのため、ストレージにも性能や管理性の向上のために、様々な機能(圧縮・重複排除、シン・プロビジョニング、自動階層化、SSD/Flashカードの使用など)が追加されています。このような機能の使用を検討されている方も多いと思いますので、Oracleデータベースと使用するとどうなのかをまとめてみました。ここからは、そのような代表的なストレージの機能について説明します。
(1)圧縮・重複排除
まずは、様々なところで有効な圧縮機能について説明します。
大規模データでは、データ容量を削減できる圧縮機能は非常に有効ですので、ストレージの圧縮・重複排除機能(ストレージ圧縮機能)がどのように有効なのか、Oracleデータベースにも第13回で説明した表圧縮機能がありますので、これとどのように使い分けるのかを説明します。
ストレージ圧縮機能は、ストレージにバックアップするときに効果がある機能になります。これは、ストレージ上だけで圧縮されるため、あまりアクセスされないデータの方が効果的だからです(アクセスで非圧縮にする必要があるので、それによる性能ダウンが発生し易いからです)。また、バックアップ・データは、増分または何世代と取得すると、重複データが多く存在するから圧縮され易くなります。圧縮方法も表圧縮のDBブロックレベル(DBブロック内で重複データを削減する)とは異なるファイルレベルで行うため、一緒に使用しても圧縮の効果はあります。ただし、第16回で説明したRMANの圧縮機能と同じような機能になるため、どちらかを選択することになります。バックアップにRMANを使用する場合は、RMANの圧縮機能の方が効果的ですので、RMANの圧縮機能を使用してください。
表圧縮は、テーブルの構造化データには効果がありますが、非構造化データ用のLOB(Large Object)には効果がありませんので、ストレージ圧縮機能の効果がある場合があります。ただし、Oracle Database 11gからはSecureFilesが使用できますので、DBバッファ・キャッシュ上でも圧縮の状態になるこちらの方が効果的です(SecureFilesの説明については別の機会とします)。
(2)シン・プロビジョニング
次に、シン・プロビジョニングについて説明します。
シン・プロビジョニング機能は、ストレージで領域をプール化して柔軟に管理する以外に、サイズも仮想化できる機能です(物理サイズより論理サイズを多くすることができます)。これを使用することで、将来利用する予定のサイズまで作成ができ、以下のようなメリットがあります。
- 実際に必要になるまで物理サイズを割当てる必要がない(初期コストを削減できる)
- 領域を追加するときに停止する必要がない(アプリケーションが論理サイズを認識している)
ただし、Oracleデータベースのデータファイル領域は、指定されたサイズをDBブロック・フォーマットしますので、物理サイズが必要になります。そのため、作成時に大きなサイズの領域を指定することはできませんので、データファイルの自動拡張(AUTOEXTEND ON句)を行う必要があります(拡張するときにDBブロック・フォーマットの負荷が掛かるので、オンライン処理などに負荷が掛かるのを嫌う場合は、システムの負荷が少ないとき以下のように手動拡張するようにしてください)。
SQL> ALTER TABLESPACE <表領域名> RESIZE <サイズ>; -- BIGFILEタイプ表領域 SQL> ALTER DATABASE DATAFILE '<ファイル名>' RESIZE <サイズ>; -- SMALLFILEタイプ表領域
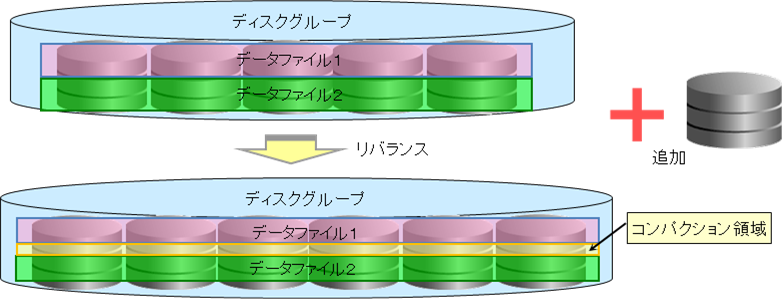
ASM(自動ストレージ管理)では、ディスク・グループ(DG)単位にディスクの追加を行いますが、その追加はシン・プロビジョニングとASMリバランスのどちらかで行うことになります(シン・プロビジョニングを使用する目的は、DG全体をシン・プロビジョニングで管理することで、ディスク追加などの操作を簡略することですから、DGは一つのディスクだけで構成するので、リバランスすることができないからです)。それから、削除したデータファイルなどの再利用は、自動的に行いませんので注意してください(シン・プロビジョニング機能が解放領域として検出しないからです)。ASMを使用している場合は、ASRU(ASM Storage Reclamation Utility)によって割当てられていない領域にゼロ・データ書込みなどを行うことで、解放領域として検出させることが可能になります。
ASMリバランスについて
ご存知ない方のために(説明していなかったので)、ここでASMのリバランスについて簡単に説明します。
ASMでは、全体最適化のためにS.A.M.Eという考え方を行っていますので(詳細は第12回を参照してください)、常に最適化されていることを前提に動作します。そのため、領域の追加または削除を行うと最適化されていない状態になるため、それを調整するリバランス機能が必要になります。ただし、このリバランス処理には、AU単位に大量のデータ移動を行うので、オンライン処理中などはシステムにとって好ましくありません。そのため、リバランスの負荷(リバランス速度)とリバランス開始タイミング(変更時に自動/手動)を指定できるようになっています。また、単純にディスク上のデータサイズから分割するのでは、デーブルなどのオブジェクトが均等に分割されないので、以下のようにデータファイルごとのディスク・アクセスが均等になるように、メタデータを元に最小限のデータ移動で最配置します(つまり、対象ディスクを均等になるようにしますので、性能が異なると遅いディスクに引きずられます)。リバランス後に発生した未使用領域を詰める処理(コンパクション)も自動的に行うので、断片化も発生しないようになっています。
(3)SSD/Flashカード
次に、最近増えてきたSSD(Solid State Device/Drive)/Flashカードについて説明します。
最近は、安価になったNAND型フラッシュメモリなどのSSD/Flashカード(フラッシュ)を、HDDの代わりに使用するのが増えてきました(どちらもSSDと呼んでいる場合もありますが、一般的にHDDと同じSASインタフェース形態などをSSD、内部バスに接続するPCIeインタフェース形態などをFlashカードと呼んでいて、以下のように使用しています)。
- SSD(SASインタフェース)
ストレージの高速化のためHDDの代わりに使用します。すべてSSDにして使用する場合やストレージ側の二次キャッシュとしても使用できるようです(最近では、数十テラ・バイトぐらいのサイズをすべてSSDにしているフラッシュ・ストレージも存在するようです)。 - Flashカード(PCIeインタフェース)
サーバーに搭載するもので、搭載できるサイズが増えてきて、DAS(Direct Attached Storage)として使用するようになってきました(格納できる数は、サーバー側のPCIeスロット数によります)。ただし、これの問題はサーバーをクラスター構成にできないなどの可用性です。そのため、サーバーの二次キャッシュなどで利用する場合も多いです(第13回で説明したOracle DB Smart Flash Cacheもこのように使用します)。それから、サーバーとDASの構成をストレージとして、HDDの代わりや二次キャッシュに使用する場合もあります(Exadata Storage Serverもこれになります)。これにもすべてをFlashカードにしているフラッシュ・ストレージが存在するようです。
これは、コスト的に問題なければIOPSの改善には良いソリューションだと思いますが、シーケンシャル・アクセスに対するコスト・メリットは少ないので(HDDの2倍ぐらいの性能と言われています)、使用するデータには検討が必要です。また、I/O帯域幅の限界になる場合がありますので、全表スキャンやダイレクト・パス・インサートなどが多いシステムでは、I/O帯域幅にも注意するようにしてください。また、すべてのデータがフラッシュに入りきらないようなシステムで、フラッシュを部分的に使用すると、遅いHDDがホットスポットになってしまいます(これは「ASMリバランスについて」で説明しているように、ASMを使用しても解決できません)。そのため、以下のどれかで使用するのがベストだと思います。
- すべてSSD/Flashカードとして使用する
- 二次キャッシュとして使用する
- ILM(Informiation Lifecycle Management)として使用する
- REDOログファイルとして使用する(”log file sync”待機が多発する場合)
最近では、サーバーマシンに搭載できるメモリ容量の増加により、物理メモリ(DBキャッシュ)の増加による性能向上も可能になっています。そのため、フラッシュを使用するかは、物理メモリを増加するのも含めて、どちらが効果的かを検討するようにしてください。
Exadata Storage Serverについて
ストレージを説明するのであれば、Exadata Storage Serverについても説明する必要があると思いますので、ご存知ない方のために、ここで簡単に説明します。
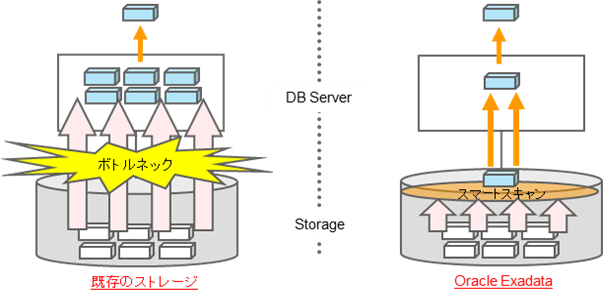
Oracle Exadata Database Machine(Oracleデータベース)用に開発したストレージになりますので、Oracleデータベースが性能向上するための様々な機能が実装されています。これは、サーバーとDASの構成でストレージとすることで、FlashカードをSmart Flash Log(REDOログ用)やSmart Flash Cache(データファイル用)などとして、効果的に使用することで高速化を行っています。I/O帯域幅の限界については、以下のようなスマート・スキャン(通常は左図のようにDBブロック単位にサーバーにデータを転送するが、右図のように必要な列と行だけを転送することでデータ量を削減する)などの転送量を削減する機能で解決しています。つまり、ストレージにOracleデータベース処理をオフロードすることで、高速化しているのが特長です(つまり、フル・スキャンにはスマート・スキャンなどを使用して、ランダムI/OにはSmart Flash Cacheなどを使用して、高速化しています)。
Exadata X3から追加されたSmart Flash Cache Write-Backは、書込み時に通常のキャッシュのように格納することで物理I/Oを削減しますが、不揮発性メモリ(電源を切ってもデータを保持できる)を生かして、キャッシュから追い出されない限り、HDDに書込まないようになっています(チェックポイントのように定期的なHDDへの書込みが必要ありません)。これで物理書込みを少なくすることができる訳です。つまり、アクセス頻度の高いデータの格納領域として使用させるようになる訳です(キャッシュの欠点は、チェックポイントなどの大量の書込みが発生すると、HDDの性能が限界になり易いことにあります)。
(4)自動階層化
次に、自動階層化機能について説明します。
ストレージのホットスポットは、特定のデータにアクセスが集中するために発生します。そのようなデータは高速な領域(アクセスが集中しない領域)に調整すれば良いのですが、問題はその場所がシステムの動作状況などで変化することです。そのため、手動で行うのは非常に大変ですので、これを自動的に行うようにしたのが自動階層化です(ただし、調整するサイズと間隔は、指定する必要があるので、これを上手く指定しないと、ある時点の負荷による調整を、また元に戻すなども発生してしまいます)。Oracleデータベースは、この最適化をその都度行うのは無理と考え、S.A.M.Eで行うことにしました。そして、その考え方を実装した機能がASMということです。
このように、自動階層化とASMでは異なる考え方で最適化を行っていますので、一緒に使用することは効率良くありません。どちらが効率的かは、システムによって異なると思いますので一概に言えませんが、Oracleデータベースには、データベースのチューニングを長年検討して考えたASMの方がベストだと思います(自動階層化を使用していると、AWRなどで分析するときに、実際のデータの格納先を調べるのが、難しいという問題もあります)。
それから、高速なディスクにSSDを使用した自動階層化は、頻繁にアクセスするデータをSSDに格納するという意味で、「(3)SSD/Flashカード」のSSDを二次キャッシュに使用する場合と同じように思えますが、頻繁にアクセスするデータをSSDに配置するときに、データの入れ替えを行うのが大きな違いです。これがキャッシュ・アウトとは違うオーバーヘッドになり、データベース側から物理的な位置を把握することができないことになりますので、間違わないようにしてください。
3. ネットワークのチューニング
最後に、ストレージのI/Oと多少異なりますが、ネットワークのチューニングについて説明しましょう。
大量のデータを検索する以下のようなネットワーク経由のアプリケーションで、性能が出なくて悩まれているのをたまに見かけます。BI(ビジネスインテリジェント)ツールの分析で、大量のデータをBIツールに取得してから行うような場合などで発生しています。このようなアプリケーションは、ほとんどがネットワークのボトルネックになっていて、CPU使用率が少なくなっていると思います。そのため、ネットワークの性能を向上するのも必要ですが、ネットワークのラウンドトリップ数(クライアントとサーバー間のやりとりの回数)を削減するのが重要になります。
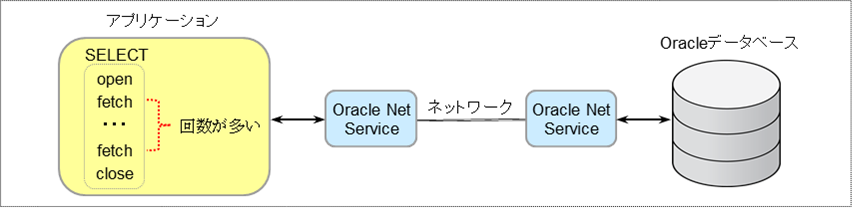
以下のサイズを調整することでネットワークのラウンドトリップ数を削減することができます。
- FETCHサイズ(ARRAYサイズなど)
1回のFETCH文で取得する行数の数です。これを大きくすることで、FETCH回数を削減することができます(これで、1回の転送サイズを大きくすることが可能になります)。これは、SQL*PlusのSET ARRAYSIZEコマンド(デフォルトは15です)、JDBCのsetFetchSizeメソッドのフェッチサイズ(Oracle JDBCのデフォルトはOracle行プリフェッチの10です)、Pro*Cの配列フェッチ(変数の配列サイズ)などで設定できます。ただし、ネットワークの送受信サイズが小さいと効果がありません。 - SDU(Session Data Unit)サイズ
Oracle Net ServicesのNetwork Session (NS) レイヤーのバッファです(デフォルトは2048バイト、最大は65535バイトです)。このバッファが一杯になる(またはアプリケーションからデータを要求される)と送信するので、Oracle Netに渡されるデータサイズを基準に設定することで、通信回数を削減することができます(つまり、FETCHサイズを基準にサイズを調整するのがベストになります)。 - SEND_BUF_SIZE/RECV_BUF_SIZE
Oracle Database 10gからSEND_BUF_SIZE/RECV_BUF_SIZEパラメータを使用して、個別にTCPソケットのバッファ・サイズを設定できるようになっています(デフォルトはOSのTCPソケットの送受信バッファ・サイズです。Linuxの場合はカーネル・パラメータnet_core.rmem_default、net_core.wmem_defaultです)。これはACKを受信する前に送信できるサイズになりますので、ネットワーク遅延が発生している(ACKを待っている)ような場合に効果があります。指定できる最大値はOSによって異なります(Linuxの場合はカーネルパラメータnet_core.rmem_max、net_core.wmem_maxになります)。
4. おわりに
今回はOracleデータベースのI/Oとストレージについて説明しました。また機会があれば他のI/O周りについても説明しようと思います。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
