皆さんこんちには、今年は寒冬で大変ですが体調の方は如何でしょうか。インフルエンザも流行っているようですので気をつけましょう。私は今のところどうにかダウンもせずに頑張っております。
今回は、バッチ処理について説明しようと思います。これは第1回と第2回で簡単に説明しましたが、バッチ処理は難しいので、もう少し説明しようと思います。皆さんの中でも悩まれている方も多いのではないかと思いますので、参考にして下さい。
■1. バッチ処理とは
まずは、バッチ処理について簡単に説明しましょう。
バッチ処理は、例えば、日中のオンライン処理が終了した時間から翌日のオンライン開始時間までに行う処理のようにある程度まとめて一括処理するようなことをいいます(その日のオンライン・データに対する様々なレポート出力処理、その日のリアルタイムで行う必要がない処理などを行います)。このような夜間の日次のバッチ処理は、オンライン開始時間までに終了する必要があります(このバッチ処理のために使用できる時間のことをバッチウィンドウとも言います)。ただし、システムのデータは日々増加してくる場合が多いため、処理時間が長くなってきますので、時間内に終了できるかの注意が必要になります。それが終わらなくなることを「バッチ処理の突き抜け」と言います。

「バッチ処理の突き抜け」についても少し話しましょう。良く聞く言葉ですが、なぜ発生するか(そのように呼ばれているか)分かりますか。
上記図のようにバッチ処理が終了しなくなってオンライン開始時まで来てしまうことから(オンライン開始時間に突き抜けてしまうから)、突き抜けると言う訳です。
これは、データ量が増加するなどによってシステムの処理時間が徐々に長くなり、あるときに予定した時間に終了しなくなってしまうからです。また、データを編集する処理(バッチ処理に含まれる処理)が増えてしまうことも理由としてあるかと思います。最近のシステムはオンライン処理が24時間動作している場合も多くなっているため、バッチ処理に使用できる時間も少なくなってきているので、時間内に終わるのが難しくなってきていると思います(単独で実行できないため負荷が少ない夜間などに実行する必要があります)。バックアップもこの時間に含めている場合もあります(Oracle Database 10g以降ではオプティマイザ統計の収集も行う必要があります)ので、更に時間が足りなくなってきていると思います(バックアップもできるだけ短時間で終わるようにする必要がありますが、これはこれで考えなければいけないことが多くありますので、説明は別の機会とさせていただきます)。そのため、十分に検討しないと「バッチ処理の突き抜け」が発生してしまう可能性があるという訳です。だからバッチ処理は難しいのです。
■2. バッチ処理の突き抜ける原因
次に、バッチ処理の突き抜ける(処理が終わらなくなる)原因について説明します。
原因としてはデータ量の増加によることが大きいと思いますので、その対処として第1回で説明したように並列化処理を行うことだと思います。ただし、データ量が増加しているのであればいつかはバッチ処理が終わらないという危険性があることは認識しておいて下さい。バッチ処理が突き抜ける原因として以下のことが考えられます。
- データ量に対する対策が悪い
- REDOログ書込みのボトルネック
- 読取り一貫性の多発
- アプリケーションの問題
ここからは、それぞれについて説明します。
(1)データ量に対する対策が悪い
データ量の増加に対する性能アップには並列化処理を行いますが、それにも限界があります。データが増加しているのであれば、現在の並列度でも時間内に終わらないことがいつか発生するでしょう。その場合に単純に並列度を増やすだけで解決できれば良いのですが、リソース不足(CPU、ストレージ、ネットワークなど)になって性能が向上しない場合もあります。そのため、考えておかなければいけないことはデータ量の増加の推移を予想して「並列度を上げる」「リソースを増強する」などの対策を検討することです。対策にはこのほかにも「サーバーに対するデータ量が増加しないように複数サーバーに分散する」と言った方法も有ります。例えば、顧客番号でサーバーに分散するなどはよく行われていることです。そうしないと、ある日突然「バッチ処理が突き抜ける」という問題が発生してしまうことになります。これは、起きた場合、あるいは起きそうになった時に、急に対処するのは簡単ではありませんので注意して下さい。そのため、予測して事前に対策が必要です。
(2)REDOログ書込みのボトルネック
更新データ量が増加すればREDOログの量も増加します。これによりREDOログ書込みがネックになって性能が出ない場合がありますが、これの対処は簡単にはいきませんので注意して下さい。これは、LGWRプロセスが1つだけなので書込みの限界があるため、並列度を増やしてもREDOログ書込みがあまり性能向上しないからです。これは、並列化処理をパラレルDMLとプログラム分割のどちらで行っても同じです。そのため、あまり頻繁にCOMMITを行わないようにするなどが必要になります(log_bufferの1/3を使用すると自動的にREDOログ書込みが行われますので、log_bufferサイズを大きくする必要があることも知っておいて下さい)。ただし、これにも限界はあります(だからバッチ処理の性能を改善するのは難しいのです)。できればREDOログを出力しないSQL文にすることを検討して下さい(例えば、ダイレクト・パス・インサートにするなどです)。
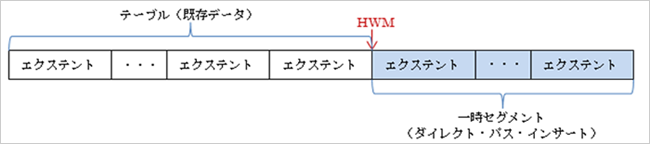
ダイレクト・パス・インサートについて
既に何回か説明に出てきていますが説明していなかったので、ご存知ない方のためにダイレクト・パス・インサートについて簡単に説明します。
ダイレクト・パス・インサートはAPPENDインサートともいいます(パラレル・インサートのときはデフォルトになります)が、以下の図のように常に新規領域(新規に追加エクステントした領域)にインサートする処理になります(通常のインサートは空きブロックに行われます)。このとき、このエクステントはインサートが完了するまで一時セグメントとして管理されますので、処理が完了できなかった場合はこの一時セグメントを解放して元の状態に戻せるようになっています。そのため、NOLOGGINGモード(テーブルの属性がNOLOGGING、またはログ・モードがNOARCHIVELOGモードの場合)で行うとREDOログを出力せずにインサートすることが出来るようになっています。この処理は、常に新規ブロックを作成することになりますので(書込みはバッファ・キャッシュ経由しないで直接行いますので)、競合が発生しないためオーバーヘッドも少なく行うことが出来るようになっています。
(3)読取り一貫性の多発
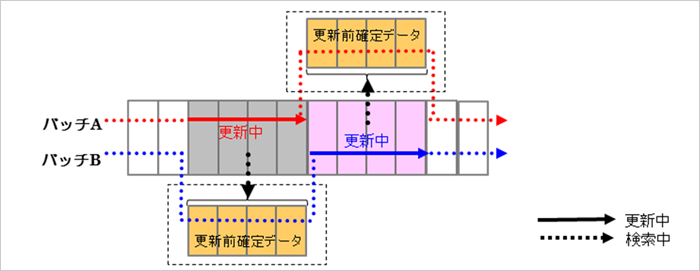
REDOログ量が増えればUNDOセグメント・サイズも増えます。これはREDOとは異なり、通常のブロックと同様にDBWRプロセスで書き込まれますので並列化してもI/Oがボトルネックになることはありません。ただし、並列度が増えてくると更新中のデータに対する読取り一貫性のためのUNDOデータ読込みが多発する場合があります。これは、行ロック待ちよりは効率は良いですが、通常のブロックをアクセスするよりは効率が悪いです。そのためにバッチ処理のような大量データの更新時は注意が必要です。大量にデータ更新するバッチ処理では、読取り一貫性が大量に発生して性能が出ないなどと良く聞きます(これは何も考えないで並列化する場合の悪い例です)。
例えば、それぞれのプロセスで同一テーブルの異なるデータを更新するような処理を実行するとします。このとき、データを更新するためにテーブルをフルスキャンしてしまうと以下の図のように読取り一貫性が多発します(これは、それぞれのプロセスが別のプロセスによって更新したデータをアクセスするため読取り一貫性が行われるからです。デフォルトでは分離レベルがREAD COMMITTEDなのでSQL文レベルでの読取り一貫性になるため、トランザクションレベルよりは発生は少ないです。この分離レベルなどもデータベースには重要になりますので、機会があれば説明したいと思います)。
この読取り一貫性については、更新中のデータをアクセスしなくて良いようにアプリケーションを検討して下さい。また、COMMIT間隔が長くなるとUNDOセグメント・サイズが大きくなってしまいます(つまり、読取り一貫性を行う割合が増加します)。そのため、あまり長くしないことも検討する必要があります。
それから、ORA-1555(スナップショットが古すぎます)も注意が必要です。これも検索を行う処理が長いと発生し易くなりますので(検索が開始したときに確定データにアクセスする必要があるため、検索処理時間が長いとその時点のUNDOデータが存在しない可能性があるからです)、その場合は初期化パラメータUNDO_RETENTION(UNDOデータの保持期間)で調整する必要があります。このときUNDO領域の不足に注意が必要です。ただし、Oracle Database 10gからは領域不足するような場合にはUNDO_RETENTIONが自動チューニングされます。UNDOセグメントも難しいので(今は自動UNDO機能があるので簡単にはなったと思いますが)機会があれば説明したいと思います。
(4)アプリケーションの問題
データ量が増えてくると負荷の多い(効率悪い)SQL文を使用すると更に処理時間が長くなってしまうため、どのSQL文が効率悪いかを知っておく必要があります。ここでは、バッチ処理で行われる代表的なことを少し説明しようと思います。その他のSQL文については第9回と第11回の「良いSQLについて」を参照して下さい。
- TRUNCATE TABLE文について
データを編集するときに中間テーブルを作成して行うような処理がよくありますが(複雑な処理のため1回では処理できないためです)、このときにテーブルを再利用するためにTRUNCATE TABLE文を行っている場合をよく見受けられます。ただし、TRUNCATE TABLE文を行うと整合性のためにオブジェクト・チェックポイントを行ってしまいます(対象のテーブルのダーティ・ブロックをすべてディスクに書込みます)。これもデータ量が増えると影響が大きくなりますので注意して下さい。
その場合にはDELETE文(すべてのデータがキャッシュ上に載っていればチェックポイントしないので速いです)の方が速いです。これだとアプリケーションとしてはあまり綺麗ではないと思いますので、第11回で説明した一時表(GLOBAL TEMPORARY TABLE)を使用すると良いと思います。一時表を使用するとオブジェクト・チェックポイントが発生しないため高速に行うことができます(DELETE文やUPDATE文に対してもREDOログの出力を削減できるため更に効率が良いです)ので、知っておくと便利かと思います。
- クライアント・アプリケーションで大量にデータを取得
すべてのデータを検索して(例えば”SELECT * FROM tab1″を実行して検索する)から処理するかどうかの判断まで含めてアプリケーション側で行っている場合もよく見受けられます(通常は”SELECT * FROM tab1 WHERE co1 = xx”などを行って必要なデータだけを検索します)。無駄なデータを検索するのは効率が良くありません、ネットワーク経由であれば更に効率が悪いですね。これもデータ量が増えれば影響が大きいので注意が必要になります。
その場合にはPL/SQLなどを使用して、できるだけOracleデータベースで処理するようにしましょう。それが難しいのであれば、バッチ処理をOracleデータベース上のマシンで動作させて下さい。ネットワーク負荷だけは軽減することができます。
■3. REDOログについて
やはりバッチ処理の性能向上は並列化することだと思います。ただし、REDOログは並列化だけでは向上しませんので、それのチューニングについて少し説明しようと思います。
REDOログ生成量が増加する(並列化すると時間当たりのREDOログ生成量も増加します)とREDOログファイルの出力がボトルネックになります。そのため、そのボトルネックを解消する必要があります。対処方法としては以下が考えられます。
- REDOログファイルのI/O性能の改善
- REDOログを出力させない
ただし、I/O性能の改善は難しいかと思います。LGWRプロセスは1つなので書込みがパラレルで行われません。そのため、単純にディスクの数を増やしても性能は向上しません。つまり、第12回のRAIDレベル(ストライピング)で説明したようにストライプサイズを小さくして1回のI/O要求が複数のディスクにアクセスするようにする必要があるということです。この対応のためにASMでもストライピング粒度を細かい(AUサイズより小さいサイズでストライピングする)に設定できるようになっています。このように行っても限界はありますので、できるだけREDOログを出力しないようにするのが最適だと思います。
そうは言ってもすべてのSQL文でREDOログを出力しないようにはデータ整合性のためできません(ダイレクト・パス・インサートだけがREDOログを出力しないで行うことができます。これでUNDOセグメントも出力されません)。だからと言って諦めることはできませんので、ここで少しアイデアを紹介しようと思います。
INSERT文にできないか検討してみて下さい。UPDATE文とDELETE文はREDOログを出力しないようにはできません。そのため大量に処理する場合には(特にパラレルで行うような場合には)、INSERT文に変換することを検討すると良いと思います。以下にSQL文の例を載せておきます。このDELETE文はテーブルの大部分(またはパーティションの大部分)を削除するとします。
このような場合は、以下のSQL文にすることでINSERT文(ダイレクト・パス・インサート)で削除を行うことができますので、知っておくと良いかと思います。この欠点はディスク領域が多少多く必要になるということです(同じデータが二つのテーブルに存在するタイミングがあるからです)が、これが許容範囲であれば検討してみて下さい。第2回でも説明しましたが、パーティション化してDROP PARTITIONする方がより効率が良いことも忘れないで下さい。
2 SELECT * FROM tab1 WHERE 日付 >= TO_DATE(‘20120101′,’YYYYMMDD’) ;
SQL> DROP TABLE tab1 ;
SQL> RENAME tab2 TO tab1 ;
これはUPDATE文の場合も同じです。
以下のようにすることでINSERT文だけで行うことができます。
2 SELECT * FROM tab1 WHERE 日付 >= TO_DATE(‘20120101′,’YYYYMMDD’) ;
SQL> INSERT INTO tab2
2 SELECT col1*10,col2,col3,日付 FROM tab1 WHERE日付 < TO_DATE(‘20120101′,’YYYYMMDD’) ;
SQL> DROP TABLE tab1 ;
SQL> RENAME tab2 TO tab1 ;
あくまでも大量に(テーブルの大部分を)処理する必要がある場合だけです。テーブルの数%だけを更新するような場合はUPADTE文を使用した方が効率が良いので間違わないようにして下さい(この場合はREDOログのネックにはならないからです)。
■4. その他について
最後に、バッチ処理で考えておく必要がある、その他のことについて少し説明しようと思います。
最近のシステムはオンライン処理が24時間動作している場合が増えていると思いますので、オンライン処理をしながらバッチ処理をするなどをしているシステムも多いのではないでしょうか。サーバーに対するオンライン処理負荷の割合を少なくするなど、オンライン処理の性能に影響しなようにする必要があると思いますので、バッチ処理の計画が益々難しいくなってきていると思います。そのため、なかなかオンライン処理中のバッチ処理を実現できずに悩まれているのが現状だと思います。上手く設計しないと同じデータにアクセスすることになり競合などが発生し易くなります。例えば、バッチ処理を行うデータは前日の24:00までとして、オンライン処理と競合しないようにするなどを検討する必要があるでしょう。
益々データ量が増加すると思われるので、更なる性能向上にはもう少し高度な並列化を行う必要があるということでしょう。できれば別マシンに複製を作成して(またはOracle Real Application Clustersの別インスタンスを使用して)、そちらでバッチ処理やバックアップなどを行うようにすることで効果的に行えたりすると思いますので(Oracleデータベースには、これを実現する様々なソリューションがあります)、検討してみて下さい。このようなことについてもいつか機会があれば説明したいと思います。
■5. おわりに
今回はバッチ処理について説明しました。すべてを詳細に説明することはできませんでしたので、また機会があれば説明しようと思います。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
