今回は少し趣向を変えてみることにしました。パフォーマンスに関するいくつかのトピックについて、Q&A形式で説明します(これまでの説明でまたの機会に説明しますなどと記述した内容や、もう少し説明が必要と思われる内容を取り上げます)ので、参考にして下さい。
■1.StatspackからSQLの実行計画を確認する方法について
前回も触れましたが「CPU time」が「Top 5 Timed Events」の上位の場合は、SQL文が過剰にCPUを使用していないかを確認する必要があります。
以下の「SQL」セクションの「SQL ordered by CPU Time」を参照すると「CPU Time(s)」の長い順に出力されます。その上位に出力されるSQL文がCPU時間が長いということですので、その実行計画を出力して確認します(「CPU time」が「Top 5 Timed Events」の上位にない場合でも1回の実行の「Elapsd Time(s)」が長いSQL文は問題の可能性がありますので同じように分析して下さい)。

SQL文の実行計画はStatspackやAWRには出力されません。出力するにはStatspackの場合は以下のスクリプト”sprepsql.sql”を実行して対象のSnapshot IDとSQLのHash Valueを入力します。SQLトレースなどの他のツールでも出力できますが、問題点のSQL文を特定してから実行計画を出力できるところが、StatspackやAWRと他のツールとの大きな違いです。ただし、これは実行計画のキャッシュ機能を使用しているので、SQL文がキャッシュに残っている間だけ出力が可能ですので注意して下さい。

実行計画を出力したら、その分析をする必要がありますので、簡単に説明します。ただし、実行計画についてはパターンが多くすべての説明はできないので、ここでは主要な部分(「テーブルを結合する場合の結合順やアクセス順」、「フルスキャンか索引スキャン(どの索引を使用したか)」など)の説明をします。
以下の実行計画の例を見ると各ステップ(実行計画の各行)がツリー構造になってインデントされていますので、次のルールで見ます。
- 同じ深さにインデントされたステップがあった場合は上位のステップが先に実行されます。
- インデントの一番深いステップのうち、最上位に表示されたものが最初に実行されます(Id=3、Id=5、Id=4の順に実行される。Id=5(Id=4に対する下位の処理なので)が最初ではないのに注意して下さい)。
以下の出力例を説明すると、先ず結合はId=2のネステッドループ結合(Operation=NESTED LOOPS)、Id=1のネステッドループ結合の順に行います(Id=2の方が深いインデントだから)。結合方法はネステッドループ結合以外にもありますが、この出力例にはありませんのでまたの機会にします。Id=2のネステッドループ結合(赤い点線の部分)はEMPテーブルを外部表として先にフルスキャン(Id=3)してから、DEPTテーブルをdept_pkによる索引スキャン(Id=5、Id=4)します。Id=1のネステッドループ結合(赤い実線に部分)は(Id=2の結果と結合するために)LOCATIONテーブルをloc_pkによる索引スキャン(Id=7、Id=6)します。
アクセスタイプは「Operation」の「TABLE ACCESS FULL」(フルスキャン)または「TABLE ACCESS BY INDEX ROWID」(索引スキャン)で判断します。どの索引を使用したかは「TABLE ACCESS BY INDEX ROWID」の次の行の「Name」に表示されます。目的の索引が出力されていない場合やフルスキャンになっている場合には索引があるかなどを確認して下さい。「Rows」(アクセス行数)が多い場合には他の索引やパーティション化も検討して下さい(アクセス行数が多いことがCPU時間が多い原因ですから「Cost」が高いです)。それから、オプティマイザ統計情報が古い場合もありますので再収集も検討して下さい(これは第1回で説明しましたね)。

Oracle Database 11gから図のようなOracle Enterprise Managerの「リアルタイムSQL監視」を使用することで簡単にSQLを監視できます(実行中のSQLを自動で監視(各ステップでの詳細な待機アクティビティなどの統計情報を取得)してグラフィカルなレポート画面から分析ができる)ので、これを使用することをお勧めします(時間かかるSQL文については、私もこれは非常に楽だと感じています)。
![]()
■2.バッファ・キャッシュ・ヒット率について
「バッファ・キャッシュ・ヒット率が低いときに初期化パラメータDB_CACHE_SIZEを増やすのは分かるのですが、メモリ不足で増やせない場合は、やはり物理メモリの追加が必要なのでしょうか。物理メモリの制限のために増やせない場合はH/Wの買い替えになるのでしょうか。」というご質問に対して説明します。
基本は物理メモリを増やして下さい。どうしても増やせない場合は、多少大変ですが「セグメント統計」(「Segments by Logical Reads」と「Segments by Physical Reads」など)を利用してアクセスが多いセグメントを特定します。それをKEEPバッファプール(初期化パラメータDB_KEEP_CACHE_SIZEの領域)に指定するなどして頻繁にアクセスするセグメントのキャッシュヒット率を上げたり、ディスクアクセスを向上させたり(性能の速いストレージに移す)することも良い案です。これは、頻繁にアクセスするテーブルが複数あり、その内の一つが大きくてバッファキャッシュに載りきれない場合(大きなテーブルのために他のテーブルもバッファキャッシュから追い出されてしまうため)などに有効です(前回に説明した「Buffer Pool Advisory」はそれぞれのバッファプールごとに出力されますので、KEEPバッファプールを使用しても利用できます)。ただし、これはアクセスパターンが変更されると再度調整が必要になり大変ですので将来的には物理メモリを増やすようにして下さい。
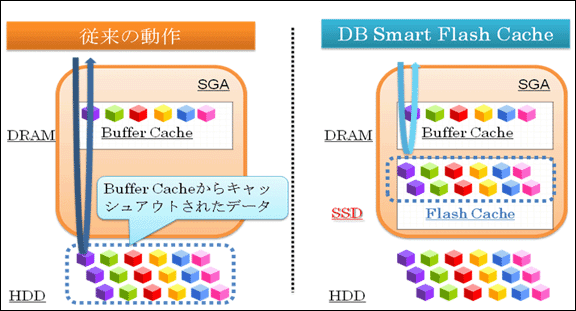
物理メモリを増やすのが価格的に難しい場合は、Oracle Database 11gR2からのDatabase Smart Flash Cache機能を使用するのはどうでしょうか。図のようにSSD(Solid State Device/Drive)をバッファキャッシュの2次キャッシュとして使用できるので、安価でバッファキャッシュを増やす効果になるので検討してみると良いです。
■3.ライブラリキャッシュについて
「ライブラリキャッシュはどんな時に不足するのですか。これもメモリサイズを増やすしか対応はないのでしょうか。アプリケーションの作成によって改善できるのでしょうか。」という疑問に対してお答えします。
実行するSQL文の種類が多いとライブラリキャッシュ上にすべての共有カーソルを格納できなくなり、再度実行した場合でもハードパースが行われてしまい効率が悪い状態をライブラリ・ヒット率が低い(ライブラリキャッシュが不足している)といいます。例えば、以下のように定数を使用したSQL文は別々に識別されます(テキストとして「完全一致」するSQL文が実行されたときのみ共有される)ので、ハードパースが多発してライブラリキャッシュが不足してきます。

これらのSQL文でカーソルを共有させる方法として、一般的には「バインド変数」の使用があります。例えば、上記SQL文は次のようにバインド変数を使用したSQL文で記述します。
![]()
バインド変数を使用できないとき(例えばパッケージソフトのためアプリケーションを変更できない場合など)は初期化パラメータCURSOR_SHARINGを使用して下さい。この初期化パラメータのデフォルトは”EXACT”(共有しません)ですが、”FORCE”もしくは”SIMILAR”にすると内部的に定数の部分をバインド変数に置換して実行するので、バインド変数を使用していないSQL文を簡単に共有させることができます。
“FORCE”と”SIMILAR”の違いは、共有カーソルを再利用するかを統計情報を参照して決定する(”SIMILAR”)か参照せずに再利用する(”FORCE”)かです。”SIMILAR”はデータの値に偏りがある列を条件にしたSQL文に効果があるということです。例えば、上記SQL文のlast_name列の場合でも’鈴木’さんと’林’さんでは件数が大分異なると思います。そのような場合に(例えば’鈴木’さんが全体の10%で、’林’さんが1%未満だとすると)索引スキャンとフルスキャンの判断が異なってくるため、同一カーソルにするか統計情報を参照して判断した方がよい場合に有効な指定です(この例の場合は統計情報にヒストグラム統計が作成されている必要があります。そうでないと正確なアクセス件数が分かりません)。少し難しくなったので説明はここまでとします(このようなことを理解するにはオプティマイザの説明をしないといけないのだが、それはまたの機会としましょう)。
■4.ブロック競合について
「ブロック競合はなぜ発生するのですか。行ロックとは異なるのですか。その場合の改善方法はどうするのでしょうか。」という疑問に対してお答えします。
ブロックに格納されているデータの更新については、行ロックを使用することで整合性を確保しているのですが、ブロックの管理情報(例えばブロック内の利用可能な領域や領域サイズなど)についても同時に変更すると不整合になってしまうので(二つのプロセスで同一領域を使用してしまい、データが無くなってしまう可能性もあるので)、同時変更できないようになっているのです。だから、同一ブロックを同時に変更しようとすると競合が発生してしまうのです(ブロックの変更はデータベース・バッファ・キャッシュ上で行うので一瞬です。普通はあまり気にする必要はありません)。
改善方法について前回は簡単に説明しましたが、ここではもう少し詳細に説明します。以下の「Buffer wait Statistics」を見ると何が競合しているのか分かります。以下の例のように「data block」が多い場合はセグメントのブロックが競合しているので、競合が発生しているセグメント(前回で説明したように競合が多発しているセグメントを特定する)を
- パーティション化する
- DBブロックサイズを小さくする(対象セグメントだけをマルチブロックサイズ機能で小さくする)
- PCTFREEを大きくする(ブロック内のレコード数を少なくする)」
などをすると良いです。「Segment header」が多い場合はパーティション化だけが改善方法です。「undo header」と「undo block」は自動UNDO管理を使用すれば普通は気にしなくて問題ありません。

パーティション化により分散させることは、第1回で説明したので競合が発生しなくなる理由は分かりますよね。ただし、バッチ処理のように処理する単位が明確になっているのであれば、それと同じレンジでパーティション化すれば良いのですが、OLTPシステムのような(大量のユーザが少量のデータをどのようにアクセスするか予想がつかない)場合は、ハッシュ・パーティション化すると良いです(パーティションの数だけアクセスが分散されます)。ただし、ハッシュ・パーティションされた列に等価条件で実行していないと分散されませんので注意して下さい(一般的には主キーで一意アクセスすると思いますので、主キーでハッシュ・パーティション化すれば問題ないと思います)。
■5.おわりに
今回はいくつかの疑問点について説明しました。
次回は「オプティマイザとオプティマイザ統計情報の収集について」(最近このことについて聞かれる機会がありましたので)説明しようと思いますので、ご期待願います。
それでは、ごきげんよう。
