皆さんこんにちは、もう12月になりましたので、これが今年最後のコラムになります。今年は東日本大震災などいろいろあったのであっという間の1年だった気がします。このコラムは、来年も続ける予定ですのでよろしくお願いします。
今回は、前回のI/O周りに続いてキャッシュ周りについて説明しようと思います。これも性能に大きく影響するため大事なことですので、参考にして下さい。
■1. バッファキャッシュとI/Oについて
Oracleデータベースは、前回説明したように非常にI/O負荷が高いソフトウェアです。そのため、I/Oを削減するための様々な機能があります。その代表的な機能がデータベース・バッファキャッシュ(以降はバッファキャッシュといいます)になります。
まずは、皆さんも良く知っているバッファキャッシュについて少し説明します。Oracleデータベースは、物理I/Oを削減するためにバッファキャッシュを使用しますが、前回説明したように可用性のためにはI/Oが増加してしまうので、性能を良くするためにはできるだけ無駄なI/Oを少なくする(=キャッシュ・ヒット率を高くする)必要があります。そのため、内部的に頻繁に使用されるブロックはキャッシュされるようなアルゴリズムになっています(これをLRU:Least Recently Usedアルゴリズムと呼びます)。ただし、大量のブロックをバッファキャッシュ上に読込むとキャッシュしておきたくてもできなくなります。また、Oracleデータベースを起動した直後などはキャッシュにデータが何もない状態なので、キャッシュに載せるまで処理が遅くなってしまいます。そのため、明示的にキャッシュするような処理などをしていると思います。Oracleデータベースでは、バッファキャッシュを効率良く使用するため(I/O待ちを削減するため)に以下のような様々な機能を提供しています。知っておくと無駄な事を手動で行わないで済み、便利です。
- Pre-Warming機能
- バッファキャッシュのバイパス機能
- マルチ・バッファプール
- 圧縮機能
- Data Block Prefetching機能
それでは、それぞれについて説明していきます。
(1)Pre-Warming機能
バッファキャッシュは、Oracleデータベースの起動直後などには何も格納されていないため、索引スキャンなどのデータアクセスを行うと最初は性能があまり良くありません。これは、バッファキャッシュにデータが載るまでに多少時間が掛るからです。そのため、できるだけ多くのデータをはやくキャッシュに載せたい訳ですから、Oracle Database 10gからはPre-Warming機能が提供されています。
バッファキャッシュにデータが載っていないときに索引スキャンを行うとアクセスされるブロックの前後をマルチ・ブロック・リードを行い多くのブロックをキャッシュします。索引スキャンなのにマルチ・ブロック・リード(db file scattered read)を行いますので、フル・スキャンを行っていると間違わないようにして下さい。手動でバッファキャッシュに載せるなどをあまり気にする必要がありませんので知っておくと便利かと思います。
(2)バッファキャッシュのバイパス機能
フル・スキャンした時にバッファキャッシュに載せるかどうかの判断をテーブルのサイズとバッファキャッシュのサイズを使用して行われます。具体的には、バッファキャッシュ・サイズの2%より大きいテーブルはLong tables、2%以下のテーブルはShort tablesと区別されて、バッファキャッシュに載せるかを判断します(以前は初期化パラメータで調整することも可能でしたが、この値を調整するのは簡単ではないためパラメータはなくなりました)。
Long tablesは、大きなテーブルをフル・スキャンでバッファキャッシュに読込むと、多くの再利用される予定のデータが追い出される可能性があるため、それを防ぐためにバッファキャッシュに載せないように動作します(正しくは、バッファキャッシュのマルチ・ブロック・リード分の領域に上書きします。フル・スキャンは、ある特定のデータしか必要としない場合や頻繁に使用しない場合でもすべてのデータを読込むので、それをバッファキャッシュに載せるのは効率が悪いからです)。そのため、フル・スキャンのときはShort tablesだけキャッシュに載せるようにしています(Statspackなどの統計情報には「table scans (long tables)、 table scans (short tables)」として出力されるので識別することができます)。このLong tablesのときにパラレル・フル・スキャンを行うとダイレクト・リードが動作します。これは、バッファキャッシュを経由しないでアクセスするI/Oです(このとき非同期I/Oを使用した先読みをすることで、更に高速にI/Oを行っています)ので、バッファキャッシュの競合も発生しないようになります。このダイレクトI/Oはパラレル・フル・スキャンやダイレクト・パス・インサートの場合に動作します。これによりバッファ・キャッシュから頻繁にアクセスするブロックを追い出さないようにしています。Oracle Database 11gR2からはIn-Memory PX(In-Memory Parallel Execution)が提供されていますので、この機能が動作するときはメモリに載せる閾値は異なりますので、注意して下さい。これについての説明は別の機会とさせていただきます。
(3)マルチ・バッファプール
バッファキャッシュは、効率良く再利用されるようなメカニズムになっていますが、すべてが完璧に行える訳ではありませんので、最後はこのマルチ・バッファプールを使用して手動で制御することができるようになっています。
何度も言っているように、再利用性の高いブロックはバッファキャッシュから追い出されないようにする必要があります。そのため、明示的に再利用させたいオブジェクト(テーブルなど)とそうでないオブジェクトを分けることで効率的に管理します。
Oracleデータベースは頻繁にアクセスされるデータはキャッシュされるよう自動的に動作しますが、バッファキャッシュに読込む時に再利用性が高いかどうかは判断できません。そのために、再利用性が低くてもデータをバッファキャッシュに読み込むことにより追い出してしまう可能性がありますので、手動でキャッシュから追い出したくないテーブルなどを指定する必要がある訳です(ただし、キャッシュサイズが十分に大きければ直ぐに追い出されることはないため、再度利用することで追い出されなくなりますので気にする必要はあまりないと思います)。
具体的には、以下の図のようにDEFAULT、KEEP、RECYCLEの3つのバッファプールがあり、できるだけバッファキャッシュ上に置いておきたいテーブルはKEEPを使用して、再利用性の少ないテーブルはRECYCLEに指定します。それ以外にもデフォルト・ブロックサイズ(標準ブロックサイズ)以外のバッファキャッシュも作成できます。例えば、デフォルトのブロックサイズが8Kだとすると、それ以外のブロックサイズのバッファプールを初期化パラメータDB_nK_CACHE_SIZEで指定できます(16Kの場合はDB_16K_CACHE_SIZEとなります)。これは、上手く使用できると効果大ですが、なかなか難しいと思いますので、明確にテーブルを特定できる時だけ使用するようにして下さい。

- KEEP
常に頻繁に使用するような小さなテーブルがある場合などは、それをKEEPプールに指定すると良いと思います。このときにオブジェクトのサイズよりプールサイズが大きくないと意味がありませんので注意して下さい。これは、すべて載らないと再度アクセスしたら読込みし直してしまうからです。そのため、あまり大きいテーブルを指定するのは現実的ではないと思います。 - RECYCLE
あまり利用されないテーブルで、フル・スキャンされるようなテーブルはRECYCLEプールに指定すると良いと思います。このときのサイズはあまり大きくなくても良いです(再利用しないデータになるので大きくする必要がないからです)。 - DEFAULT
これはKEEPやRECYCLEなど以外の残りのテーブル用として必ず存在します。これが一番大きな領域になります。
(4)圧縮機能
バッファキャッシュを増やすことが最も効果的ですが出来なければデータを削減することを検討しましょう。格納データを減らすことは難しいと思いますので、圧縮機能を使用してデータ量を削減するのが良いと思います。データを圧縮することでバッファキャッシュの増加と同じような効果になります。Oracleデータベースの圧縮機能は、ブロック内の同一データを削除するようになっていますので、1ブロックに格納できるデータ量が多くなりキャッシュ・ヒット率を向上させることができます。ただし、すべてのSQL(DML)文に対応した圧縮機能を使用したい場合はAdvanced Compression オプションが必要になりますので注意して下さい(標準で使用できるのはCREATE TABLE <テーブル名> AS SELECTやINSERT INTO <テーブル名> SELECTなどのダイレクト・パス・インサートの時だけになります)。
(5)Data Block Prefetching機能
これはバッファキャッシュを効果的に使用するという機能ではありませんが、バッファキャッシュのアクセス方法も効率良くなるように改善していますという意味でここで説明します。バッファキャッシュを使用する索引スキャンでは、(2)のダイレクトI/Oで説明した先読みは基本は行いませんが、Oracle9iからはこの機能を使用することで先読みを使って効率良くアクセスを行ってくれます。
これは、索引スキャンは事前にどのデータを読込む必要があるか分からないため(フルスキャンと違ってすべて読み込む訳ではありませんので)先読みを行うことができないからです。ただし、索引範囲スキャンを行う時だけは、リーフ・ブロックを横方向にアクセスするため、先読みが可能です。以下の図の例のように、最初に条件の100を検索してリーフ・ブロックの開始位置を決め、左の方向にブロックをアクセスします。このとき、リーフ・ブロックに格納されているROWIDを使用してデータ・ブロックの先読みを行うことができます。以下の図ですと、キー値が100, 11, 10, 3, 2, 1のデータ・ブロックを先読みします。これによりCPU処理と並列にI/Oを行うことができ、I/O待ちが減少します。

■2. その他のキャッシュについて
やはりI/Oを少なくするのは、キャッシュのサイズを大きくするのが最も最適です。ただし、メモリ搭載サイズやコスト的な限界があるため、これを代用する機能をOracleデータベースでは提供しています。ここからは、そのような機能(DB Smart Flash cacheとインメモリデータベース)について説明しようと思います。
(1)DB Smart Flash Cache
まずは、DB Smart Flash Cache機能について説明します。これは、第4回で少し説明したように安価なSSD(Solid State Device/Drive)をバッファキャッシュの二次キャッシュとして利用できるため、メモリ増設よりも簡単に物理I/Oを削減することができます。ただし、SSDはランダムアクセスの読込み性能には優れていますが書込みについてはあまり得意ではありませんので(書込みについては、それほど速くならないので効果が低いということです)、効果的に使用するには多少の注意が必要です。例えば、DB Smart Flash Cacheに載せるテーブルなどを特定して、あまり効果がないテーブルは載せないようにするなどが必要です。
どのように使用するかというと、初期化パラメータ(db_flash_cache_file:SSDのパス、db_flash_cache_size:割り当てサイズ)を指定するだけで、自動的に使用してくれます。また、Flash Cache属性をDEFAULT以外(優先的にキャッする、キャッシュしない)にする場合は、以下のSQL文ようにSTORAGE句でFLASH_CACHE属性{DEFAULT(デフォルト指定)|KEEP(優先的にキャッシュする)|NONE(キャッシュしない)}を指定できます。これはパーティション単位にも指定できますので、上手く使用すると更に効果的に使用できます。
SQL> ALTER TABLE <テーブル名> STORAGE (FLASH_CACHE KEEP); SQL> ALTER TABLE <テーブル名> MODIFY PARTITION <パーティション名> STORAGE (FLASH_CACHE NONE);
このFLASH_CACHE属性は、以下のSQL文などで確認することができます。
SQL> SELECT table_name,flash_cache FROM user_tables WHERE table_name = 'TAB1'; TABLE_NAME FLASH_C ------------------------------ ------- TAB1 DEFAULT
パーティションの場合は以下のSQL文などで確認できます。
SQL> SELECT partition_name,flash_cache FROM user_tab_patitions WHERE table_name = 'TAB1';
(2)インメモリデータベース(TimesTen)
次に、インメモリデータベースであるTimesTenについて説明します。
これは、Oracleデータベースの負荷をインメモリデータベースへオフロードする機能になり(そのため、キャッシュ以外の効果もあります)、TimesTen単独で動作するOracle TimesTen In-Memory Database(Oracle TimesTen IMDB)とOracleデータベースと連携して動作するOracle In-Memory Database Cache(Oracle IMDB Cache)があります。
Oracle TimesTen IMDBも特定のテーブルだけをTimesTenに入れてアクセスすることで高速化することができます(ただし、テーブル毎にアクセスするデータベースをTimesTenかOracleデータベースかを意識する必要があるという複雑さはあります)。それに対してOracle IMDB Cacheはアプリケーション側で意識する必要がないというメリットがありますので、キャッシュとして簡単に使用できると思います。
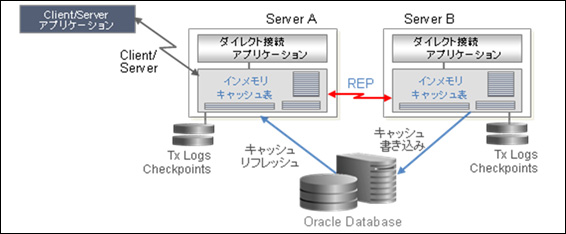
ここでは、Oracleデータベースのキャッシュとして使用できるOracle IMDB Cacheについて説明します。これは、Oracle IMDB Cacheを使用して以下の図のようにOracleデータベースのキャッシュとして使用することができるため、物理I/Oを削減することができます。インメモリキャッシュ上に指定したテーブルはそのデータが使用され、指定されていないテーブルはパススルー機能によりOracleデータベースにアクセスしてくれます。アプリケーションサーバー上に構築することによりネックワークのオーバーヘッドも軽減することができます(これのメリットも大きかったりすると思います)。このようなことを行うために作り込んだりするシステムもあると思いますが、この機能を使用することで実現できますので、知っておくと便利です。
■3. おわりに
今回はOracleデータベースのキャッシュについて説明しました。また機会があれば他のことについても説明したいと思います。次回はこの流れでメモリ・チューニングについて説明しようかと思いますのでお楽しみにして下さい。これが今年最後の連載ですので、皆さん良いお年をお迎え下さい。来年も頑張りますのでよろしくお願いします。それでは、次回まで、ごきげんよう。
