Accessibility Policy
Skip to content
Oracle
Oracle Technology Network Japan Blog
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
.NET
Always Free
Autonomous Database
CLOUD INFRASTRUCTURE SECURITY
Cloud Security
Data Safe
Database
Database Security
Developer Tools
Developers
Identity Cloud Service
Java
Java Magazine
JavaScript
JSON
Kubernetes
Linux
Maximum Security Zones
Microsoft Azure
Middleware
OCI
Oracle全般
OTN
Solaris
VMware
イベント&セミナー
ハードウエア
新着資料
開発ツール
Blogs Home
RSS
Oracle Technology Network Japan Blog
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Recent Posts
津島博士のパフォーマンス講座 第80回 Oracle Database 21cの機能強化について
Hiroki Tsushima
5 minute read
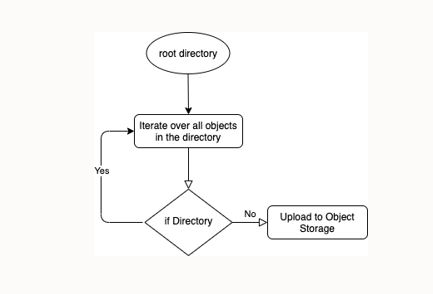
ディレクトリ全体をOracle Object Storageへアップロード
Guest Author
4 minute read
SQLclでOracle Databaseの移行を容易に
Guest Author
8 minute read
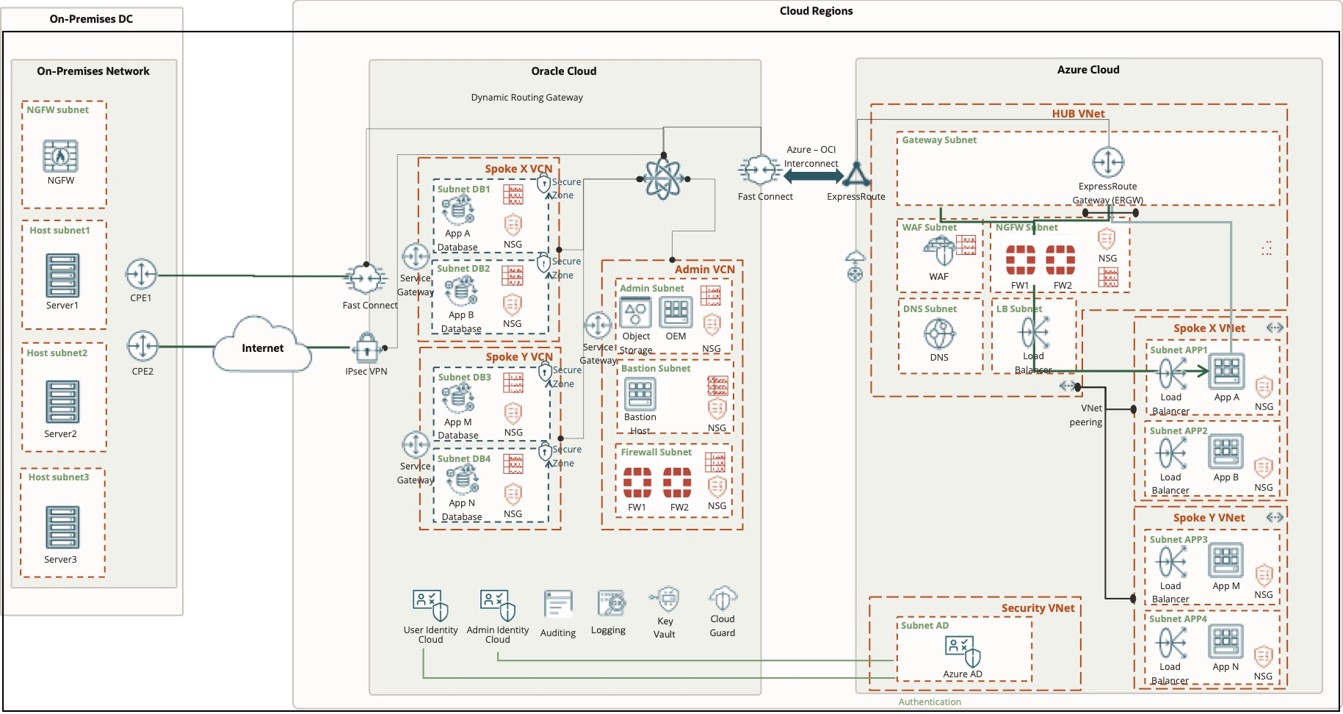
OCI-Azure ...
Guest Author
7 minute read
サステナビリティの目標を達成するためにクラウドコンピューティングを活用する3つの方法
Guest Author
2 minute read
Java を使った IAM トークンによる Autonomous Database へのアクセス
Guest Author
2 minute read
Oracle Autonomous Database における APEX および ORDS の Vanity URL 導入
Guest Author
6 minute read
Oracle Autonomous Database Vanity URL パート2: 開発者ツールと管理者ツールのブロック
Guest Author
6 minute read
Oracle Advanced Queuing(AQ)を使用してNode.JSでメッセージを作成および転送する
Guest Author
2 minute read
コマンドライン・インタフェース(CLI)を使用したOracle Advanced Queuingの素早い公開/サブスクライブのテスト
Guest Author
2 minute read
Coherence Community Editionが登場(パート3):Javaによるパッケージ化、デプロイ、スケーリング、永続化、運用
Guest Author
7 minute read
世界最速のスパコン「富岳」が「Society 5.0」に向けて舵を切る
Guest Author
1 minute read
View more
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers