しばちょう先生の試して納得!DBAへの道 indexページ▶▶
みなさん、こんにちは。 “しばちょう”こと柴田長(しばた つかさ)です。
昨年11月下旬のイベント「Oracle DBA & Developer Day 2012」の私が講演させて頂いたセッション「高可用性システムに適した管理性と性能を向上させる ASM と RMANの魅力」が、アンケート集計の結果、全30近くのセッションの中で講演内容と講師説明の評価においてトップのご評価を頂くことができました。イベントにご来場頂きました皆様に、この場を借りて御礼申し上げます。ありがとうございました。そして、この度、東京以外の各支社で開催されるイベント「Oracle Technology Day」においても同内容のセッションをお届けすることが決定いたしました。大阪(2/19)、名古屋(2/26)、福岡(2/28)には自ら登壇させて頂く予定ですので、よろしくお願い致します。

ということで、ASMやRMANをご紹介しようとも考えたのでが、それは後に取っておくことにして、今回は圧縮機能についてご紹介をしていきたいと思います。
Oracle Databaseには様々な圧縮機能が実装されていますが、今回扱うのは表データを圧縮する「基本圧縮」になります。「表データを圧縮する」=「ディスクスペースの節約」と言うように、容易に想像可能かと思います。圧縮率は格納データの特徴に依存しますが、例えば100GBの表データを圧縮することで30~40GBにまで小さくすることが可能です。これだけでもDBAとしては魅力的な機能に見えますよね。ちなみに、いつもの概要マニュアルの「表の圧縮」の項では次にように紹介されています。
「データベースでは、表の圧縮を使用して、表に必要な記憶域を削減します。圧縮によりディスク領域を節約し、データベース・バッファ・キャッシュでのメモリー使用量を減らすことができ、場合によっては問合せ実行時間も短縮できます。」
そうです。今回注目して頂きたいのは、データ量の縮小だけではなく、検索処理性能の向上になります。もちろん、圧縮表に対する基本オペレーションも含みますが、何故、圧縮で検索処理が高速化するのか?を体験して頂くことで、少しだけSQLの処理時間とH/Wリソースの消費傾向の相関関係についての感覚を身につけて頂きたいと考えています。
ちなみに、管理者ガイドの「表圧縮の使用」の項では、次のような断言した表現に変化しており、さらにオーバーヘッドについても言及しているので、この違いがマニュアルを読む上で面白いところです。
「データベースが大きくなるにつれて、表圧縮の使用を検討してください。圧縮を使用すると、ディスク領域が節約され、データベース・バッファ・キャッシュのメモリー使用が削減されて、読込み中の問合せ実行速度が大幅に向上します。圧縮には、データのロードやDMLのためのCPUオーバーヘッドがかかります。ただし、この負荷はI/O要件の削減によって相殺される可能性があります。」
この「オーバーヘッド」の詳細については、次回以降にご紹介する予定です。
以下の演習をこれまでの演習で使用したOracle Database 11g Release 2 Enterprise Editionのデータベースで試してみてください。
【今回ご紹介するネタ一覧(逆引き)】
- 基本圧縮表の新規作成(演習3)
- DBMS_COMPRESSIONパッケージを使用した圧縮効果の見積もり(演習2)
- SQL監視レポートの取得と作成(演習5)
- sqlplusにおけるバインド変数の使用例(演習5)
- 直積SELECT文によるカーディナリティを意識した大量レコードの生成方法(演習1)
- LAG分析ファンクションを利用した圧縮効果の確認(演習4)
■1. 次のSQLを用いて、TRYスキーマ上に1GBの非圧縮表を作成してください。
sqlplus TRY/TRY
SQL>
create table TBL14 (COL1 number, COL2 date, COL3 varchar2(80), COL4 varchar2(80), COL5 varchar2(80));
create sequence SEQ14 start with 1 increment by 1 cache 10000;
insert /*+APPEND */ into TBL14
select SEQ14.nextval,
sysdate+SEQ14.currval/24,
rpad(to_char(mod(SEQ14.currval, 10)), 80, 'A'),
rpad(to_char(mod(SEQ14.currval, 20)), 80, 'B'),
rpad(to_char(mod(SEQ14.currval, 30)), 80, 'C')
from (select 0 from all_catalog where rownum <= 350),
(select 0 from all_catalog where rownum <= 100),
(select 0 from all_catalog where rownum <= 100);
commit;
はい、大枠としては第3回の記事においてご紹介させて頂いた、直積使用して大量レコードを作成するSQL文の復習となります。
特徴としては、mod関数(第一引数を第二引数で割り算した余りを戻す)を使用して列のカーディナリティを実現している点です。例えば、COL2列の値を作成する中で「mod(SEQ14.currval, 10)」としていますが、この結果として10種類(0~9)の値を作り出しています。
Oracle Databaseの基本表圧縮は「圧縮」という表現を使用はしていますが、具体的な圧縮手法は「重複排除」となっています。(これについては概要マニュアルの「データ・ブロックの圧縮」の項で説明されています。また、Oracle Database 11g Release 1から登場したOracle Advanced Compression Optionに含まれる「OLTP表圧縮」も重複排除の仕組みであることがOracleホワイトペーパー「Oracle Advanced Compression」でも解説されています。)つまり、同じ値の列データが1つにまとめられる為、圧縮表を使用した検証をする際には全レコードの列データが同一な値にならないようにカーディナリティを意識したレコードの準備が不可欠です。ちなみに、現実のお客様のデータベースにおいては、元のデータ量を100%とした場合、良いケースで30%前後の圧縮率となるのが私の経験です。
この演習1では非圧縮の表に対するデータ・ロードですが、以降の演習において同じレコードが格納された圧縮表を作成する為、この段階でカーディナリティを意識しています。さらに、今回扱う基本圧縮表は「ダイレクト・パス・ロードによって挿入されたデータのみを圧縮」という仕様が存在しているため、INSERT文には「APPENDヒント句」を追加してあります。この制限を排除したのが上記でも登場したOracle Advanced Compression Optionに含まれる「OLTP表圧縮」です。これについても、次回以降にご紹介していく予定です。
※ その他の表の圧縮機能と特徴については、管理者ガイドの「表20-2 表の圧縮の特徴」をご参照ください。
■2. Compress Advisor(DBMS_COMPRESSパッケージのGET_COMPRESSION_RATIO)を使用して、表「TBL14」のデータに基本圧縮を適用した際の圧縮率を見積もってください。
sqlplus / as sysdba
SQL> grant execute on DBMS_COMPRESSION to TRY;
SQL> connect TRY/TRY
set serveroutput on
declare
SCRATCHTBSNAME VARCHAR2(30) :='USERS';
OWNNAME VARCHAR2(30) :='TRY';
TABNAME VARCHAR2(30) :='TBL14';
PARTNAME VARCHAR2(30) :='';
COMPTYPE_FLG NUMBER :=2;
SAMPLE_BLKCNT_CMP BINARY_INTEGER;
SAMPLE_BLKCNT_UNCMP BINARY_INTEGER;
SAMPLE_ROWNUM_PER_BLK_CMP BINARY_INTEGER;
SAMPLE_ROWNUM_PER_BLK_UNCMP BINARY_INTEGER;
CMP_RATIO NUMBER;
COMPTYPE_STR VARCHAR2(100);
begin
DBMS_COMPRESSION.GET_COMPRESSION_RATIO
(SCRATCHTBSNAME,OWNNAME,TABNAME,PARTNAME,COMPTYPE_FLG,
SAMPLE_BLKCNT_CMP,SAMPLE_BLKCNT_UNCMP,SAMPLE_ROWNUM_PER_BLK_CMP,
SAMPLE_ROWNUM_PER_BLK_UNCMP,CMP_RATIO,COMPTYPE_STR);
dbms_output.put_line('--------------------------------------------------------');
dbms_output.put_line('OBJECT_NAME => '|| OWNNAME ||'.'|| TABNAME || ' (PARTITION='|| PARTNAME ||')');
dbms_output.put_line('COMPRESS_RATIO => '|| CMP_RATIO);
dbms_output.put_line('--------------------------------------------------------');
dbms_output.put_line('COMPRESSED_TYPE = '||COMPTYPE_STR);
dbms_output.put_line('SAMPLE_UNCOMPRESSED_BLOCKS = '||SAMPLE_BLKCNT_UNCMP);
dbms_output.put_line('SAMPLE_COMPRESSED_BLOCKS = '||SAMPLE_BLKCNT_CMP);
dbms_output.put_line('SAMPLE_UNCOMPRESSED_ROWS_PER_BLK = '||SAMPLE_ROWNUM_PER_BLK_UNCMP);
dbms_output.put_line('SAMPLE_COMPRESSED_ROWS_PER_BLK = '||SAMPLE_ROWNUM_PER_BLK_CMP);
end;
/
--------------------------------------------------------
OBJECT_NAME => TRY.TBL14 (PARTITION=)
COMPRESS_RATIO => 3.2
--------------------------------------------------------
COMPRESSED_TYPE = "Compress For OLTP"
SAMPLE_UNCOMPRESSED_BLOCKS = 2121
SAMPLE_COMPRESSED_BLOCKS = 659
SAMPLE_UNCOMPRESSED_ROWS_PER_BLK = 27
SAMPLE_COMPRESSED_ROWS_PER_BLK = 87
演習問題は簡単にも関わらず、このDBMS_COMPRESSION.GET_COMPRESSION_RATIOプロシージャを使いこなすのは少々難しいですね。という印象を抱かせてしまうようなPL/SQLになってしまっています。これは入力引数の意味と出力結果を重要視しているので、見た目が複雑化してしまっています。もし、シンプルに書き上げるとすれば、次のようになります。
sqlplus TRY/TRY
SQL> connect TRY/TRY
set serveroutput on
declare
SAMPLE_BLKCNT_CMP BINARY_INTEGER;
SAMPLE_BLKCNT_UNCMP BINARY_INTEGER;
SAMPLE_ROWNUM_PER_BLK_CMP BINARY_INTEGER;
SAMPLE_ROWNUM_PER_BLK_UNCMP BINARY_INTEGER;
CMP_RATIO NUMBER;
COMPTYPE_STR VARCHAR2(100);
begin
DBMS_COMPRESSION.GET_COMPRESSION_RATIO
('USERS', 'TRY', 'TBL14', '', 2,
SAMPLE_BLKCNT_CMP,SAMPLE_BLKCNT_UNCMP,SAMPLE_ROWNUM_PER_BLK_CMP,
SAMPLE_ROWNUM_PER_BLK_UNCMP,CMP_RATIO,COMPTYPE_STR);
dbms_output.put_line('COMPRESS_RATIO => '|| CMP_RATIO);
end;
/
DBMS_COMPRESSION.GET_COMPRESSION_RATIOプロシージャの各引数の説明はPL/SQLパッケージ・プロシージャおよびタイプ・リファレンスをご参照ください。一点だけ補足しておくと、第5引数である「comptype」には分析を実行する対象の圧縮タイプ(圧縮機能の種類)を数字で指定する形になりますが、このマトリックスは「表36-1 DBMS_COMPRESSIONの定数: 圧縮タイプ」に記載されています。また、この表には「基本圧縮表」が含まれていませんので、同じ重複排除の仕組みで圧縮する「OLTP表圧縮」を代用して今回は「2」を指定しています。
また、このプロシージャはOracle Database 11g Release 2以降に登場しましたが、実はそれ以前のバージョン(Oracle 9i Database ~ Oracle Database 11g Release 1)においても実行できるようOracle Technology Netowrkからダウンロードすることが可能です。ただし、このプロシージャを実行した際に一時的に圧縮属性の表が作成される為、基本圧縮表の機能を提供しているEnterprise Editionでのみ動作することにご注意ください。
前置きが長くなりましたが、表「TBL14」のデータに基本圧縮を適用した場合には「3.2倍」の格納効率になることが確認できましたね。3.2倍という表現を私好みの「元データを100%とした場合に何%のデータサイズになるのか?」に置き換えてみると、「31.25%」(=100 / 3.2)となりますね。
■3. 演習1と同じINSERT文を使用して、実際に基本圧縮表を作成してください。
sqlplus TRY/TRY
SQL>
create table TBL14_COMP (COL1 number, COL2 date, COL3 varchar2(80), COL4 varchar2(80), COL5 varchar2(80)) PCTFREE 10 COMPRESS;
create sequence SEQ14_COMP start with 1 increment by 1 cache 10000;
insert /*+APPEND */ into TBL14_COMP
select SEQ14.nextval,
sysdate+SEQ14.currval/24,
rpad(to_char(mod(SEQ14.currval, 10)), 80, 'A'),
rpad(to_char(mod(SEQ14.currval, 20)), 80, 'B'),
rpad(to_char(mod(SEQ14.currval, 30)), 80, 'C')
from (select 0 from all_catalog where rownum <= 350),
(select 0 from all_catalog where rownum <= 100),
(select 0 from all_catalog where rownum <= 100);
commit;
さて、基本圧縮表「TBL14_COMP」を作成して非圧縮表「TBL14」と同じレコードをデータ・ロードしてみます。それほど難しくはないと思います。違いはCREATE TABLE文で「COMPRESS句」が含まれているか否かだけですね。と行きたいところなのですが、「PCTFREE 10」も追加しています。
この理由としては、「COMPRESS句」を指定した場合、PCTFREEが「0」に上書きされる仕様があるからです。先にも述べましたが、基本圧縮表は「ダイレクト・パス・ロードによって挿入されたデータのみを圧縮」という仕様があります。これはデータウェアハウス等の参照系データベースでの採用を前提に提供された機能であり、データの更新が考慮されていません。更新できないわけではないですが、格納効率を最大限効率化する目的でPCTFREE=0に上書きするものだと推測しています。よって、PCTFREE=0で全く問題ないのですが、今回は演習の都合上、Compression Advisorとの比較も行いたいので、非圧縮表と同じくPCTFREE=10に明示的に変更しています。
この演習問題では基本圧縮表をゼロから作成していますが、現実のシステムでは非圧縮表を圧縮表へ変更するケースが多いかと思います。この手順に関しても次回以降に解説させて頂きますので、しばしお待ちください。
■4. 演習1と3で作成した各表のセグメントサイズを比較し、圧縮率を計算してください。
sqlplus TRY/TRY
SQL>
select SEGMENT_NAME, sum(BYTES)/1024/1024 as MB
from USER_SEGMENTS
where SEGMENT_NAME like 'TBL14%'
group by segment_name;
SEGMENT_NAME MB
---------------- ----------
TBL14 1024
TBL14_COMP 320
いかがですか?見事にセグメントのサイズが圧縮されていれば成功です。圧縮率は「31.25%」(=320/1024*100)となり、正に演習2で実行して頂いたCompression Advisorと同じ結果となりましたね。と言うことで、どれだけCompression Advisorが正確であるかを体験して頂けたかと思います。そして、圧縮の一つ目のメリットである「データサイズの縮小」も本当に可能であることも確認できたこともDBAとして経験としても大きいのではないでしょうか。
また、少し複雑なSQL文となってしまいましたが、LAG分析関数を使用して圧縮率を計算した結果も同時に出力するSELECET文を書いてみました。もう少しシンプルに書けないか奮闘中ですけど共有しておきまね。
sqlplus TRY/TRY
SQL>
select SEGMENT_NAME, MB, MB/decode(NOCOMP_SIZE, 0, MB, NOCOMP_SIZE)*100 as RATIO
from (select SEGMENT_NAME, MB, (lag(MB, 1, 0) over (order by MB DESC)) NOCOMP_SIZE
from (select SEGMENT_NAME, sum(BYTES)/1024/1024 MB
from USER_SEGMENTS
where SEGMENT_NAME like 'TBL14%'
group by SEGMENT_NAME
)
);
SEGMENT_NAME MB RATIO
---------------- ---------- ----------
TBL14 1024 100
TBL14_COMP 320 31.25
■5. 各表に対して、全表検索を実施し、その処理時間を計測してください。その際、SQL監視レポートも作成してください。
sqlplus / as sysdba
SQL>
alter system flush buffer_cache ;
alter system flush shared_pool ;
SQL> connect TRY/TRY
set timing on
select /*+ FULL(TBL14) NO_PARALLEL MONITOR */ count(*) from TBL14 ;
経過: 00:00:11.53
SQL> connect / as sysdba
set trimspool on trim on pages 0 linesize 1000 long 1000000 longchunksize 1000000
variable my_sql CLOB;
variable my_rept CLOB;
BEGIN
select sql_id into :my_sql from v$sql where sql_text like 'select /*+ FULL(TBL14)%' and rownum <=1;
:my_rept :=DBMS_SQLTUNE.REPORT_SQL_MONITOR(sql_id=>:my_sql,report_level=>'ALL',type=>'active');
END;
/
spool sqlmon_active_nocomp.html
print :my_rept
spool off
sqlplus / as sysdba
SQL>
alter system flush buffer_cache ;
alter system flush shared_pool ;
SQL> connect TRY/TRY
set timing on
select /*+ FULL(TBL14_COMP) NO_PARALLEL MONITOR */ count(*) from TBL14_COMP ;
経過: 00:00:05.64
SQL> connect / as sysdba
set trimspool on trim on pages 0 linesize 1000 long 1000000 longchunksize 1000000
variable my_sql CLOB;
variable my_rept CLOB;
BEGIN
select sql_id into :my_sql from v$sql where sql_text like 'select /*+ FULL(TBL14_COMP)%' and rownum <=1;
:my_rept :=DBMS_SQLTUNE.REPORT_SQL_MONITOR(sql_id=>:my_sql,report_level=>'ALL',type=>'active');
END;
/
spool sqlmon_active_comp.html
print :my_rept
spool off
まったく同じSELECT文を実行しましたが、非圧縮表では11.53秒に対して、圧縮表では5.64秒と高速化していることが確認できましたね。非常に高性能なストレージを使用して検証していなければ、多分確認できていると思います。
元の非圧縮の表に対する処理時間を100%とすると、圧縮することで約48%(つまり2倍の性能)まで高速化できたことを意味しますね。この差は非常に大きいですよね。演習では秒単位の比較なのでイメージしづらい所もありますが、例えば1時間を要する検索処理が圧縮するだけで30分まで高速化できる可能性があるということですから、夜間バッチの処理時間に課題があるデータベースでは直ぐにでも採用したい気がしてきますよね。とは言え、今回の連載ではメリット部分しか紹介できていないので、デメリットもきちんと理解しておきましょう。と言う部分は書ききれないので次回以降でお願いします。
また、処理時間を計測するだけではなく、合わせてSQL監視レポートも取得して頂きました。取得する為のSQL文は参考になると思いますので、皆さんのローカルPC上にでも保管して使いまくって頂けると嬉しい限りです。
■6. 各表における全表検索時のSQL監視レポートを比較し、CPUとI/O消費量の傾向変化を考えてみてください。
では、演習5で取得したSQL監視レポートから圧縮の有無によって、CPUとI/O消費量がどのように変化したのかを簡単に見てみましょう
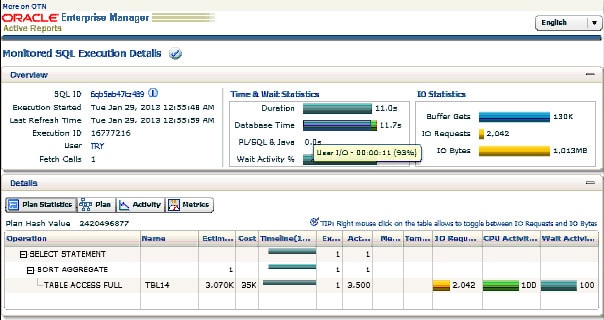
【非圧縮表(TBL14)に対するSELECT】
(画像をクリックすると拡大表示になります。)
【基本圧縮表(TBL14_COMP)に対するSELECT】
(画像をクリックすると拡大表示になります。)
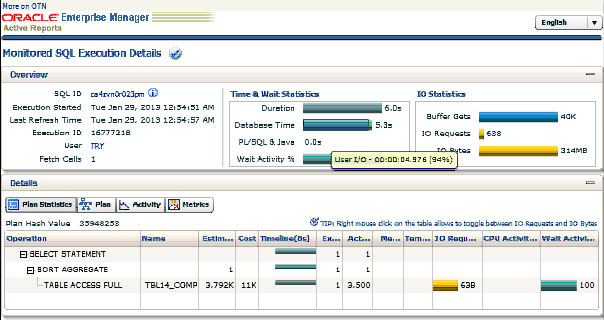
色々な情報が満載なSQL監視レポートですが、今回見るべきポイントは「IO Bytes」と「Database Time」となります。
まず、「IO Bytes」に関しては、上段右の「IO Statistics」枠内に記されています。これは、このSQL文を処理する為にディスクから読み込んだデータ量を示しています。つまり、非圧縮表では1013MBのデータをディスクから読み込んだのに対し、圧縮表ではセグメントサイズが小さくなっている(= 一つのデータ・ブロックにより多くのレコードが詰まっている状態)ので、314MBの読み込みで済んでいることが一目で確認できます。
次に「Database Time」に関してですが、上段中央の「Time & Wait Statistics」枠内に記されています。これはこのSQL文を処理する際に「User I/O」「CPU」「Application」の各部分で要した時間の割合を確認することができます。マウスをポイントすることで上記のようにポップアップで各内訳の時間と割合が表示されます。今回のケースでは、User I/Oに要した時間が非圧縮では11秒に対して圧縮表は約5秒であり半分以下に削減されたことを確認できますね。
ということで、基本圧縮を施すことでSELECT文を実行した際に、ディスクから読み込むデータ量が少なくて済む為にディスクI/Oに要する時間が削減される。その結果、SELECT文の処理時間が高速化する。という仕組みをご理解して頂けたかと思います。
さて、いかがでしたでしょうか?Oracle Databaseの圧縮機能はデータのサイズを縮小することで、ディスク領域の節約を実現するだけではなく、同時に検索処理性能の高速化も実現することが可能です。また、今回はシンプルな全表検索処理であり、CPUよりもI/Oに要する時間の割合が長い(I/OバウンドなSQLと呼ぶ)為に、圧縮率と同じ程度の処理時間の短縮が確認できています。逆に、CPUバウンドなSQL(例えば、関数の多用、複雑な表結合等が含まれるSQL)では、圧縮を適用してディスクI/O時間を削減できたとしても、SELECT文そのものの処理時間の短縮は極微小なケースもあります。そのような場合の一つのチューニング方法は、パラレル実行となりますね。この辺りはタイミングを見てご紹介していきたいと考えています。
次回以降への持ち越しが多い回となってしまいましたが、ありがとうございました。次回も頑張りますので、どうぞよろしくお願いします。
