皆さんこんにちは、今年の3月、4月は少し寒かったため桜の開花も遅かったですが、やっと過ごしやすい気候になりましたね。花粉症の方は大変ですが頑張ってください。
今回は、パラレル実行でOracle Database 12c(Oracle12c)から拡張されてまだ説明していない機能や注意点をいくつか説明しようと思います。後半に、パラレル実行でも問題になる集合演算子のMINUSやINTERSECTについても説明していますので、参考にしてください。
1. パラレル実行の注意点
これまで、様々なパラレル実行の注意点(ソート処理、OR条件、再帰的問合せなど)やOracle12cで改善された機能(ハイブリッド・ハッシュ分散、FILTER操作、自動並列度、分析ファンクションなど)を説明してきましたが、まだ説明していないものがいくつかあるので、そのような以下の動作や注意点について説明します。
- 相関副問合せ
- ランキング検索(上位N検索)
- DBMS_XPLAN.DISPLAY_CURSORファンクションのA-Rows
(1)相関副問合せ
まずは、第29回で説明した相関副問合せのパラレル実行について説明します。
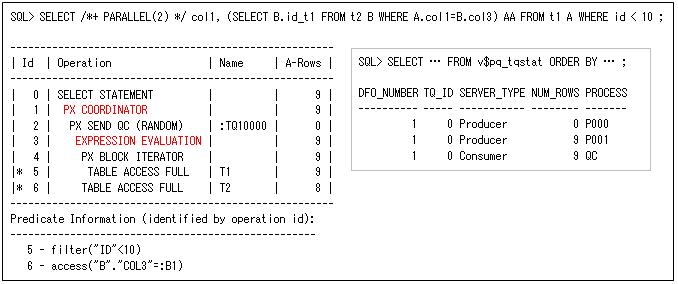
相関副問合せは、フィルター条件(EXISTS条件など)や式(スカラー副問合せ)で使用されますが、Oracle Database 11gR2(Oracle11gR2)まではネスト解除されないと、以下のスカラー副問合せのように二つの”PX COORDINATOR”が動作して、PQスレーブ・プロセスも多く使用され効果的ではありませんでした。これは主問合せと副問合せを、別々にQC(Query Coordinator)からパラレル実行され、副問合せは主問合せの個別値だけ実行します(この例では、結合列’col1’の個別値が1,2,3,100になるので、4回実行されているのがビュー’v$pq_tqstat’から分かります)。

このスカラー副問合せは、第42回で説明したように、Oracle12cからネスト解除(外部結合に変換)を行いますが、ネスト解除しないときでも一つの”PX COORDINATOR”だけで行うようになります(このとき実行計画には、以下のように”EXPRESSION EVALUATION”と出力されます)。どちらが動作するかは、オプティマイザが判断しますが、ネスト解除が遅いときはNO_UNNESTヒントで回避することもできます。
また、スカラー副問合せは、単一行を返す必要があるので、複数行を集計関数で一行にする場合が多いですが、対象行数が多いときにはネスト解除の方が効果的になります(以下のSQLの実行計画のように、右側は”SORT AGGREGATE”が主問合せの各行ごとに実行されていますが、左側のネスト解除は”HASH GROUP BY”とブルーム・フィルターが動作して効果的になっています)。
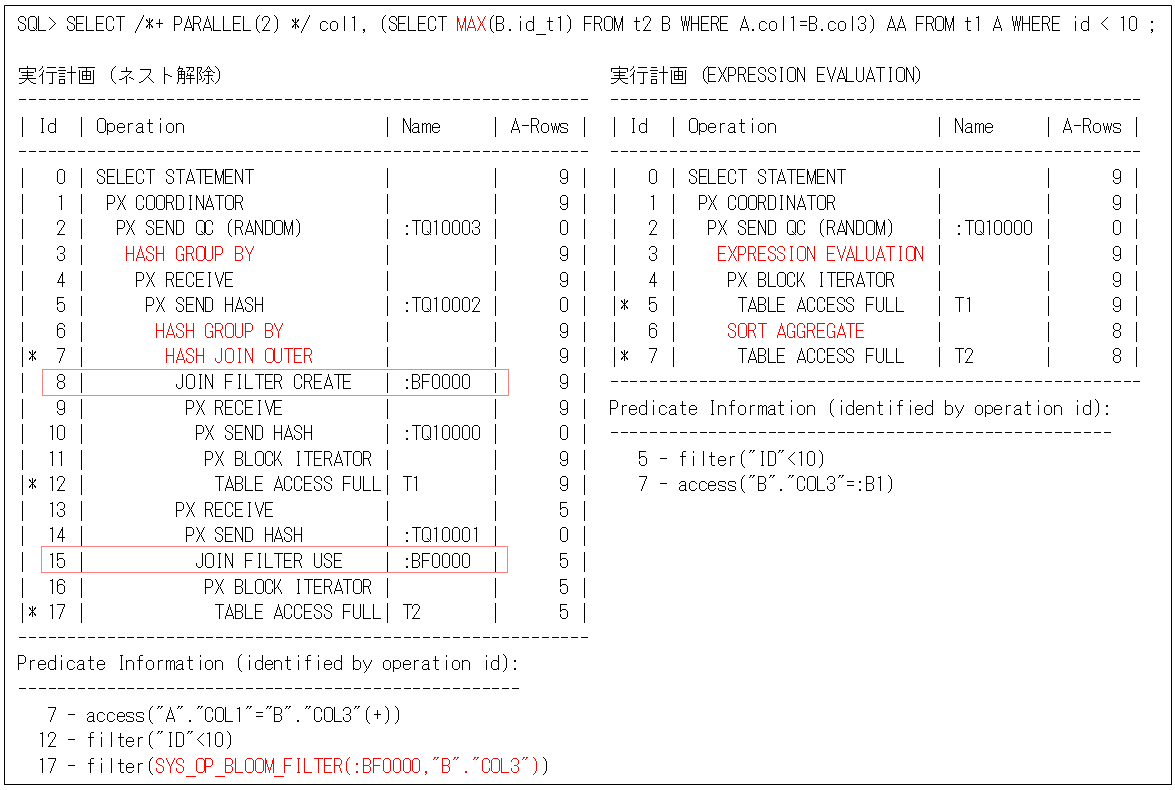
そのため、集計関数を使用した対象行数が多いスカラー副問合せはネスト解除を使用し、それ以外は”EXPRESSION EVALUATION”を使用した方が効果的と言えます。フィルター条件については、第39回のPQ_FILTERヒントで説明しているので、そちらを参照してください。
( 2)ランキング検索(上位N検索)
次に、第24回や第37回で説明したランキング検索のパラレル実行について説明します。
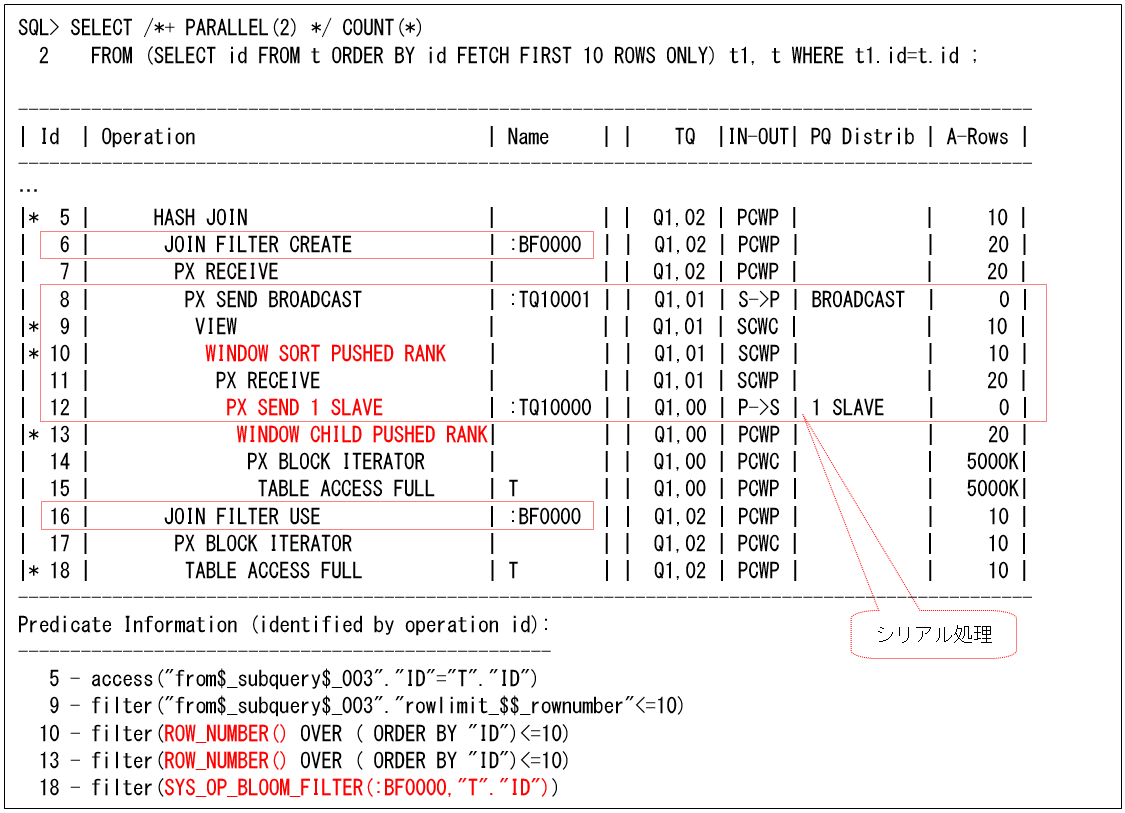
ランキング検索では、ROWNUM疑似列などで行う件数の制御を、QCプロセスでシリアル実行しますが、これはQCプロセスが調整ではない処理を行うため、パフォーマンスに影響を与える可能性がありました。そのため、Oracle12cから一つのPQスレーブ・プロセスで実行するようになっています(これを1スレーブ分散”1 SLAVE distribution”と呼びます)。
以下は、Oracle11gR2とOracle12cで行ったときの実行計画です(右側のOracle12cには、1スレーブ分散の”PX SEND 1 SLAVE (ORDER)”が出力されています)。また、シリアル実行の前にPushDown処理により、PQスレーブ・プロセス(スキャン・プロセス)でも行を削減できるようになっています。この例では、各スキャン・プロセスで10行(パラレル度×10行)にしてから、最終的に10行にするように動作します。
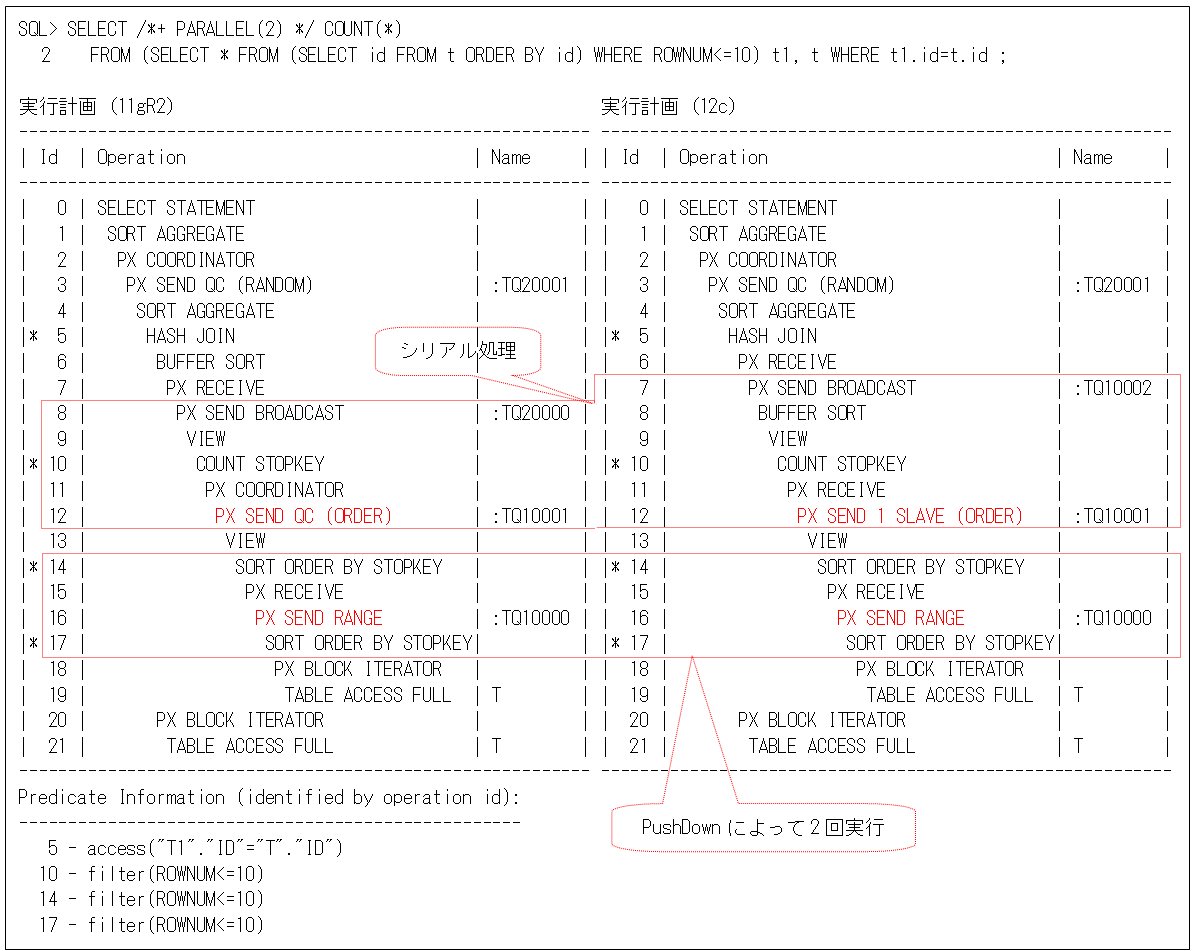
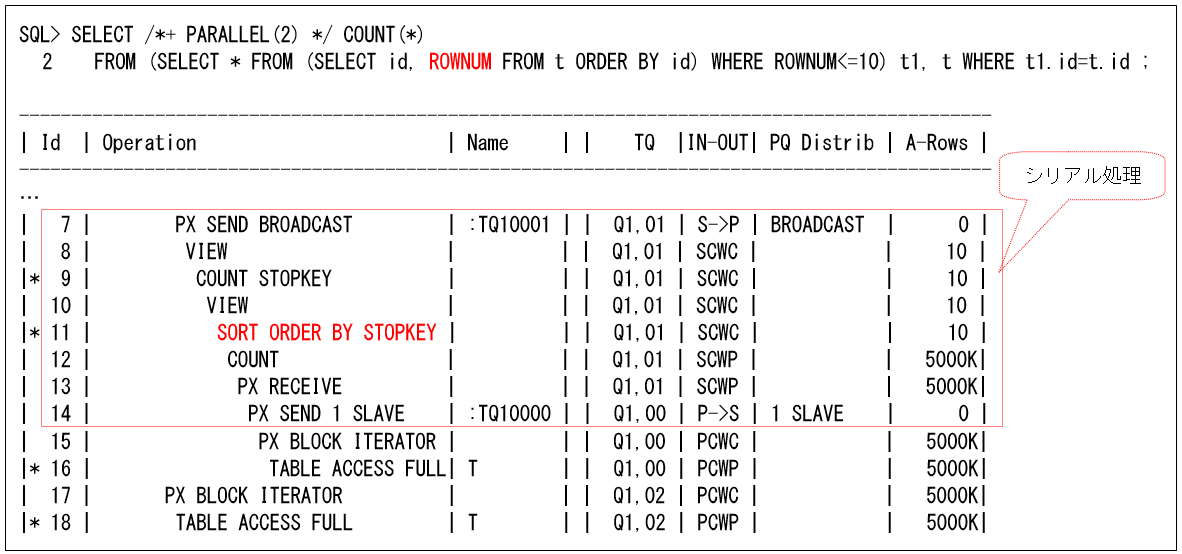
ただし、SELECTリストにROWNUM疑似列を入れると、以下のようにPushDown処理されなくなるので、シリアル実行で多くの行数を処理することになります。このような処理では、SELECTリストにROWNUM疑似列を入れる必要がないので、間違わないように注意してください。
また、第37回で説明したFETCH FIRST句についても、以下のように1スレーブ分散とPushDown処理(”WINDOW SORT PUSHED RANK”と”WINDOW CHILD PUSHED RANK”)が動作します(このSQLは、ROW_NUMBERファンクションを使用したときと同じ動作になります)。ROWNUM疑似列を使用したときのように、RANGE再分散や”COUNT STOPKEY”がないので、処理ステップが少なくなっています。また、ブルーム・フィルターも使用しているので、こちらの方が効果的と言えます。
(3)DBMS_XPLAN.DISPLAY_CURSORファンクションのA-Rows
最後に、Oracle12cからではありませんが、第32回で説明したDBMS_XPLAN.DISPLAY_CURSORファンクションを使用して、パラレル実行時にA-Rowsを出力するときの注意点について説明します。
パラレル実行したときには、第32回で説明したFORMATパラメータ’TYPICAL ALLSTATS LAST’ではA-Rowsが正しく出力されません。これはパラレル実行時にQCプロセスの統計だけが表示対象となり、PX(Parallel eXecution)サーバー・プロセスの統計が含まれないためです(PQスレーブ・プロセスは、PXサーバー・プロセスと言う場合も多いので、覚えておきましょう)。そのため、パラレル実行のときには、以下のようにFORMATパラメータを’TYPICAL ALLSTATS’にして出力してください。このときメモリ統計については、Used-MemとUsed-Tmpの代わりに、O/1/MとMax-Tmpが出力されます。
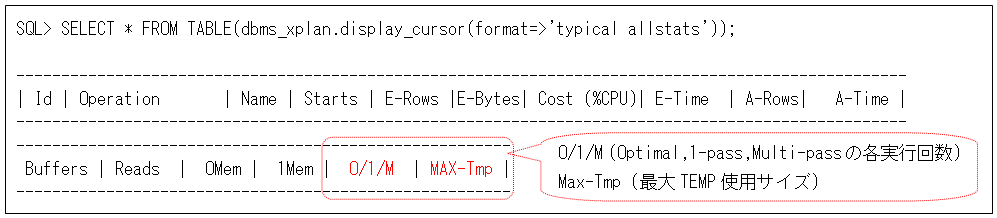
ただし、同じSQL文(共有カーソル)を実行した統計が複数存在する場合は、LAST指定をしないとA-Rowsは全実行の合計になります。そのため、パラレル実行の場合は、複数回実行分から最後の1回分だけを正しく表示できないので注意してください(出力するには「ALTER SYSTEM FLUSH SHARED_POOL」の実行やSQLにコメントを入れるなどを行ってください)。
2. 集合演算子
ここからは、まだ説明していない集合演算子(主にMINUSとIMTERSECT)の動作とチューニングについて説明します。これもパラレル実行に影響するので一緒に説明しています。
集合演算子は、二つ以上の問合せ結果に対する処理で、以下の三つの処理タイプがあります。この中で一般的によく使用するのがUNIONだと思いますが、それ以外もたまに見かけることがあるので、これを参考に効果的に使用してください。
- UNION(和集合)
それぞれの問合せブランチのすべての行を求めます。UNION ALLにすると重複値を排除しないので、ソート処理を行わなくなります。 - MINUS(差集合)
問合せブランチ間の差分(最初の問合せにだけに存在するデータ)を求めます。これにはUNION ALLのように重複値を排除しない指定はないので、必ずソート処理を行う必要があります。 - INTERSECT(積集合)
すべての問合せブランチに含むデータだけを求めます。これも重複値を排除しない指定はありません。
それでは、以下のデータ(tab1.c1が1~10、tab2.c1が6~15)を使用して、何度か取り上げているUNIONは省略して、MINUSとINTERSECTについてもう少し説明していきます。
SQL> CREATE TABLE tab1 AS SELECT LEVEL c1 FROM dual CONNECT BY LEVEL <= 10; -- 1~10 SQL> CREATE TABLE tab2 AS SELECT LEVEL+5 c1 FROM dual CONNECT BY LEVEL <= 10; -- 6~15
このデータにそれぞれのSQLを実行すると、実行結果は以下のようになります。MINUSは最初の問合せだけに存在するデータなので1~5、INTERSECTは両方に存在するデータなので6~10になっています。
SQL> SELECT c1 FROM tab1 MINUS SELECT c1 FROM tab2;
C1
----------
1
2
3
4
5
|
SQL> SELECT * FROM tab1 INTERSECT SELECT c1 FROM tab2;
C1
----------
6
7
8
9
10
|
この実行計画は、以下のように重複値を排除するため必ずソート処理(SORT UNIQUE)を行ってしまい、効果的に実行することができません(特に、パラレル実行では、データ分散の偏りが発生しやすくなります)。
|
SQL> SELECT c1 FROM tab1 MINUS SELECT c1 FROM tab2; ———————————— | Id | Operation | Name | ———————————— | 0 | SELECT STATEMENT | | | 1 | MINUS | | | 2 | SORT UNIQUE | | | 3 | TABLE ACCESS FULL| TAB1 | | 4 | SORT UNIQUE | | | 5 | TABLE ACCESS FULL| TAB2 | |
SQL> SELECT c1 FROM tab1 INTERSECT SELECT c1 FROM tab2; ———————————— | Id | Operation | Name | ———————————— | 0 | SELECT STATEMENT | | | 1 | INTERSECTION | | | 2 | SORT UNIQUE | | | 3 | TABLE ACCESS FULL| TAB1 | | 4 | SORT UNIQUE | | | 5 | TABLE ACCESS FULL| TAB2 | |
そのような場合には、以下について検討することになるので、SQLチューニングのために覚えておきましょう。
- 他のSQLに変換
- ヒント文の使用
(1)他のSQLに変換
まずは、最適な実行計画にするためのSQLの書き換え方法について説明します。
SQLには、同じ処理を異なる方法で行うことができるものが多くあるので、どの方法が効果的かを知っておくのはSQLチューニングで重要になります。このMINUSやINTERSECTも以下のように変換することができます。
- MINUS
NOT EXISTS条件(アンチ結合)とDISTINCT句に変換できます - INTERSECT
等価結合(ハッシュ結合)とDISTINCT句に変換できます(Oracle12cからは、第42回で説明した「Partial Join Evaluation」が実行されてセミ結合になります)
以下は、そのSQLと実行計画になりますが、こちらの方が効果的な実行計画なのが分かります(”SORT UNIQUE”ではなく”HASH UNIQUE”になるので、パラレル実行でも効果的にデータ分散が行われます)。また、重複値を排除する必要がないときには、DISTINCT句を削除すれば更に効果的に実行することができます(このとき等価結合は、セミ結合に変換されなくなります)。
|
SQL> SELECT DISTINCT c1 FROM tab1 WHERE NOT EXISTS 2 (SELECT 0 FROM tab2 WHERE tab1.c1=tab2.c1); ———————————— | Id | Operation | Name | ———————————— | 0 | SELECT STATEMENT | | | 1 | HASH UNIQUE | | |* 2 | HASH JOIN ANTI | | | 3 | TABLE ACCESS FULL| TAB1 | | 4 | TABLE ACCESS FULL| TAB2 | |
SQL> SELECT DISTINCT tab1.c1 FROM tab1, tab2 2 WHERE tab1.c1=tab2.c1; ———————————— | Id | Operation | Name | ———————————— | 0 | SELECT STATEMENT | | | 1 | HASH UNIQUE | | |* 2 | HASH JOIN SEMI | | | 3 | TABLE ACCESS FULL| TAB1 | | 4 | TABLE ACCESS FULL| TAB2 | |
ただし、SQLを結合に変換していますが、実際には結合ではないので、NULL値が存在するときには結果が異なるので注意してください。もう少し分かりやすいように、今度は以下のようにNULL値も含めて実行してみます。
SQL> UPDATE tab1 SET c1=NULL WHERE c1=1; -- NULL,2~10 SQL> UPDATE tab2 SET c1=NULL WHERE c1=15; -- 6~14,NULL
このデータにそれぞれを実行すると、以下のように結果が異なってしまいます。MINUSは、どちらにもNULLが存在すると対象になりませんが、アンチ結合にすると結果に含まれてしまいます(NULLはアンチ結合の対象にならないからです)。
SQL> SELECT c1 FROM tab1 MINUS SELECT c1 FROM tab2;
C1
----------
2
3
4
5
|
SQL> SELECT DISTINCT c1 FROM tab1 WHERE NOT EXISTS
2 (SELECT 0 FROM tab2 WHERE tab1.c1=tab2.c1);
C1
----------
NULL
2
4
5
3
|
また、INTERSECTは、どちらにもNULLが存在すると対象になりますが、等価結合では含まれていません(これもNULLは等価結合の対象ではないからです)。
SQL> SELECT c1 FROM tab1 INTERSECT SELECT c1 FROM tab2;
C1
----------
6
7
8
9
10
NULL
|
SQL> SELECT DISTINCT tab1.c1 FROM tab1, tab2
2 WHERE tab1.c1=tab2.c1;
C1
----------
6
8
7
9
10
|
これは結合列にNOT NULL制約が付いていれば問題ないので、付いていないときには使用するのに注意してください。
(2)ヒント文の使用
次に、簡単にSQLを変更できない場合もあるので、ヒント文による実行計画の変換について説明します。
SET_TO_JOINヒントを使用すると、以下のように「(1)他のSQLに変換」で説明したSQLに変換されます(このとき'(@SET$1)’の指定を忘れないでください)。ただし、INTERSECTは、Oracle12cでもセミ結合に変換されないので注意してください。
|
SQL> SELECT /*+ SET_TO_JOIN(@SET$1) */ c1 2 FROM tab1 MINUS SELECT c1 FROM tab2; ———————————— | Id | Operation | Name | ———————————— | 0 | SELECT STATEMENT | | | 1 | HASH UNIQUE | | |* 2 | HASH JOIN ANTI | | | 3 | TABLE ACCESS FULL| TAB1 | | 4 | TABLE ACCESS FULL| TAB2 | ———————————— Predicate Information (identified by operation id): ————————————————— 2 – access(SYS_OP_MAP_NONNULL(“C1”)= SYS_OP_MAP_NONNULL(“C1”)) |
SQL> SELECT /*+ SET_TO_JOIN(@SET$1) */ c1 2 FROM tab1 INTERSECT SELECT c1 FROM tab2; ———————————— | Id | Operation | Name | ———————————— | 0 | SELECT STATEMENT | | | 1 | HASH UNIQUE | | |* 2 | HASH JOIN | | | 3 | TABLE ACCESS FULL| TAB1 | | 4 | TABLE ACCESS FULL| TAB2 | ———————————— Predicate Information (identified by operation id): ————————————————— 2 – access(SYS_OP_MAP_NONNULL(“C1”)= SYS_OP_MAP_NONNULL(“C1”)) |
先程説明したように、NULL値が存在すると結果が異なるので、SYS_OP_MAP_NONNULLファンクションを使用してNULLも結合できるようにしています(このファンクションは、NULLをRAWデータ’FF’に変換します)。そのため、SYS_OP_MAP_NONNULLファンクションは、結合列がNOT NULL制約であれば使用されません。他のSQLに変更するときも、このように行うと問題がなくなります。また、このヒントでは、HASH UNIQUEを削除できないので、必要なく対象行数が多いときにはSQLの書き換えの方が効果的と言えます。
アウトラインの出力について
アウトラインの出力は、ヒント文を使用するときに便利なので、ここで紹介しておきます(これはマニュアルに載っている標準機能ではないので、それを認識して使用してください)。
アウトライン情報は、第5回で少し触れた実行計画を固定化するヒント文の集まりになるので、これをそのまま指定すると、他の環境でも同じ実行計画にすることができます。また、慣れない方はヒントを指定するのが大変だと思うので、SQLチューニングで指定方法の参考としても使用できると思います(第55回でオプティマイザ・ヒントを説明しましたが、指定方法が分からないときなどはこれを出力して参考にすると良いでしょう)。
このアウトライン情報は、実行計画の出力に含めることができます。指定方法は、以下のようにDBMS_XPLAN.DISPLAY_CURSORのFORMATパラメータに’ADVANCED’を指定すると、第55回に説明した’ALIAS’指定の出力に’Outline Data’情報が追加されます。’OUTLINE’を指定することで、アウトライン情報だけの出力も可能になります。
…<実行計画>…
Query Block Name / Object Alias (identified by operation id):
————————————————————-
1 – SEL$F5BB74E1
6 – SEL$F5BB74E1 / T3@SEL$2
8 – SEL$F5BB74E1 / T1@SEL$2
Outline Data
————-
/*+
BEGIN_OUTLINE_DATA
IGNORE_OPTIM_EMBEDDED_HINTS
OPTIMIZER_FEATURES_ENABLE(‘12.1.0.2’)
DB_VERSION(‘12.1.0.2’)
ALL_ROWS
FULL(@”SEL$F5BB74E1″ “T3″@”SEL$2”)
FULL(@”SEL$F5BB74E1″ “T1″@”SEL$2”)
LEADING(@”SEL$F5BB74E1″ “T3″@”SEL$2” “T1″@”SEL$2”)
…
END_OUTLINE_DATA
*/
3. おわりに
今回はパラレル実行の注意点と集合演算子について説明しましたが、少しは参考になりましたでしょうか。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
