皆さんこんにちは、梅雨が明けたのは嬉しいのですが、今年も猛暑が続きそうですね(日中に外に出ると暑くて倒れそうですよね)。体調を崩さないように上手に休みを取って乗り切るようにしましょう。
今回は、第20回の続きとして、性能の向上に重要なパラレル実行についてもう少し説明します。パラレル実行は、パラレル度やデータの偏りなどの難しい部分もあり、効果的に使用できていない場合も多いように思います。そして、Oracle Database 12cからパラレル実行が少し拡張されていますので、今回から2回に分けてパラレル実行について説明しようと思います。まず今回は、データ分散処理について説明しますので、参考にしてください。
1. データ分散処理について
まずは、第20回で説明したデータ分散処理についてもう少し説明しましょう。
パラレル処理では、処理する列(結合列など)が異なれば、データの再分散(再分配)が必要になります。基本はハッシュの分散が最も偏りが少ない方法ですが、データの格納順などによってデータ分散が偏ることもあります。そのため、表結合するときはパーティション・ワイズ結合を行う方がより効果的になりますが、重複データなどによって偏る場合はブロードキャストにしないと改善できなくなります。このように表結合では、分散方法を効果的に使用することが重要になります。Oracle Database 10gからは、実行計画にパラレル実行の情報が多く出力されるようになったので、どのような処理を行っているか調べやすくなっています。ただし、表結合については、まだ分かりづらいものも多いので、以下のハッシュ以外のデータ分散処理についてもう少し説明しようと思います。
- パーティション・ワイズ結合
- データ分散なしとブロードキャスト
(1)パーティション・ワイズ結合
パーティション・ワイズ結合(PWJ)については、以下の実行計画の違いなどは説明していなかったので、実行計画を見ながらデータ分散処理の注意する点などを説明します。
- フルPWJ
- パーシャルPWJ(内部表側がパーティション)
- パーシャルPWJ(外部表側がパーティション)
まずは、フルPWJからです。フルPWJは、結合するテーブルのデータを分散する必要がないので(パー ティションで分散されるので)、パラレル表結合では最も効果的な処理になります。そのため、第10回で説明したコンポジット・パーティションなどを活用して、できるだけこれで行うように検討してください。以下の実行計画のようにプロセス間通信がないので、データの偏りが少なくオーバーヘッドも少ない処理になります。
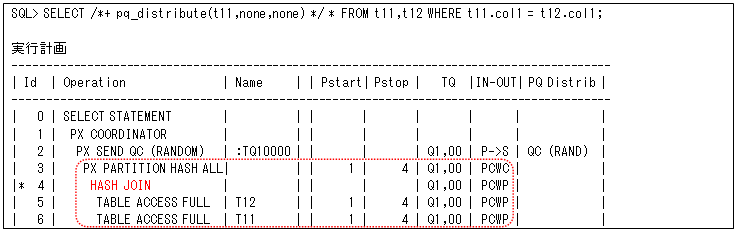
次に、どうしても結合列を同じパーティションにできない場合にはパーシャルPWJを検討しますが、内部表側(後からアクセスするテーブル)のパーティションを使用するパーシャルPWJから説明します(説明が分かりやすいように、以下の実行計画はフルPWJと同じテーブルにPQ_DISTRIBUTEヒントを使用して行っています)。
外部表側(テーブル’T12’)はスキャンと結合でパーティション分割’PX SEND PARTITION (KEY)’になりますが、 内部表側(テーブル’T11’)はデータを分散する必要がないので(スキャンと結合が同じPQプロセスになるので)、結合の次の処理も同時に行うことが可能になっています(つまり、結合結果を退避する必要がありません)。また、結合時にパーティションをフィルタリングするために、第22回で説明したブルーム・フィルタリング’PX PARTITION HASH JOIN-FILTER’も行っています。

最後に、外部表側(最初にアクセスするテーブル)のパーティションを使用するパーシャルPWJです(以下の実行計画も同じように、PQ_DISTRIBUTEヒントを使用して行っています)。
この場合は、内部表側がスキャンと結合でパーティション分割’PX SEND PARTITION (KEY)’をする必要があるので、結合結果を退避するために’HASH JOIN BUFFERED’となっています。これは、同時に処理するのが最大2セットまでになるので、結合結果を格納する必要があることを意味します(これは、Oracle Database 10gから出力されていますが、それ以前からも内部的には動作していた処理です)。これによって使用する作業領域が増加してTEMP領域を使用する場合もあるので注意してください。
実行計画
———————————————————————————————-
| Id | Operation | Name | | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
———————————————————————————————-
| 0 | SELECT STATEMENT | | | | | | | |
| 1 | PX COORDINATOR | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | | | | Q1,01 | P->S | QC (RAND) |
|* 3 | HASH JOIN BUFFERED | | | | | Q1,01 | PCWP | |
| 4 | PX PARTITION HASH ALL | | | 1 | 4 | Q1,01 | PCWC | |
| 5 | TABLE ACCESS FULL | T12 | | 1 | 4 | Q1,01 | PCWP | |
| 6 | PX RECEIVE | | | | | Q1,01 | PCWP | |
| 7 | PX SEND PARTITION (KEY)| :TQ10000 | | | | Q1,00 | P->P | PART (KEY) |
| 8 | PX BLOCK ITERATOR | | | 1 | 4 | Q1,00 | PCWC | |
| 9 | TABLE ACCESS FULL | T11 | | 1 | 4 | Q1,00 | PCWP | |
このようにパーシャルPWJでは、どちらのテーブルがパーティション化されているかは重要になりますが、ハッシュ結合では小さいテーブルが外部表になる方が効果的なのは忘れないでください。
(2)データ分散なしとブロードキャスト
表結合をパラレル実行している場合に、データ分散処理を行っていない(’PX SEND XXXX’が存在しない)以下のような実行計画をたまに見かけます。パーティション化していないのに、どうしてデータを再分散する必要がないか分かりますか。ここでは、そのようなことを少し説明しようと思います。

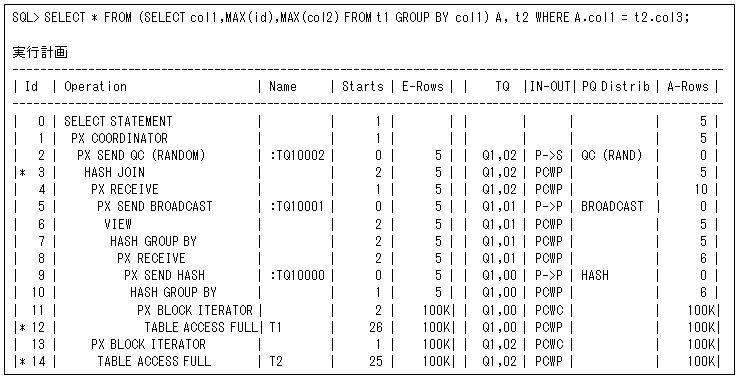
これは、外部表側のテーブルをそれぞれのPQプロセスでスキャンすることで、データの再分散を 行わないようにします(全表スキャンの分割を引き継ぎます)。そのため、片方のテーブルの行数が非常に少ない表結合の場合に効果的な方法です。この例は、テーブル’T3’(5行)に対してパラレル度を4で結合を行っているので、テーブル’T3’を4つのPQプロセスで全表スキャンしています。そのため、A-Rowsは20(5行×4パラレル)となっています。つまり、物理読込みは増加しますが、分散処理のオーバーヘッドがなくデータを均等にできるというメリットがあります。そのため、ブロードキャストしていないからと慌てないでください。
これに対してブロードキャストは、全表スキャンするデータ量が多いが転送する(結合する)行数が少ないような場合に効果的です。以下の例では、10万行のテーブル’T1’をGROUP BYで5行にしているので、結合する行数は少なくなっています。このような場合にはブロードキャストの方が効果的といえます。データ分散なしやブロードキャストの方法は、内部表側のデータを再分散する必要がないので、データによる偏りは発生しないというメリットがあります。
このようなことはオプティマイザが行うので、気にしなくても良いと言えますが、知っておくとチューニング時に役に立つと思います。また、実行計画を見るときでも処理の分析がしやすくなります。
2. Oracle Database 12c の拡張について
次に、Oracle Database 12c(Oracle12c)で拡張になった以下のデータ分散処理の機能について説明しましょう。
- ハイブリッド・ハッシュ
- PQ_SKEWヒント
- PQ_FILTERヒント
(1)ハイブリッド・ハッシュ
オプティマイザ統計の正しさによっては最適な分散方法を決定できない場合があります。そのため、Oracle12cから実行時に決定するハイブリッド・ハッシュ分散方法が追加されています。これは、第33回で説明したOracle12cからの適応計画(Adaptive Plans)が実行されたときの表結合のデータ分散方法です。この分散方法では、実行時の統計を基に決定するので、オプティマイザ統計の問題などで見積もりが正しくないような場合でも最適な分散方法を決定することが可能です。外部表側に対して実際の行数がしきい値(その操作で選択されたパラレル度の2倍)以上の場合にはハッシュで行い、小さい場合にはハッシュからブロードキャストに切り替えて行います。
実行計画には、以下のように’PX SEND HYBRID HASH’が出力されます。外部表側には、その前に行数を求める統計コレクタ’STATISTICS COLLECTOR’も出力されます。以下の例は、5行のテーブル’T3’を結合する処理に対してパラレル2とパラレル4で行ったときの実行計画で、比較するために実行時の行数’A-Rows’を並べて載せています(この例では、PQ_DISTRIBUTEヒントを使用してハイブリット・ハッシュにしています)。
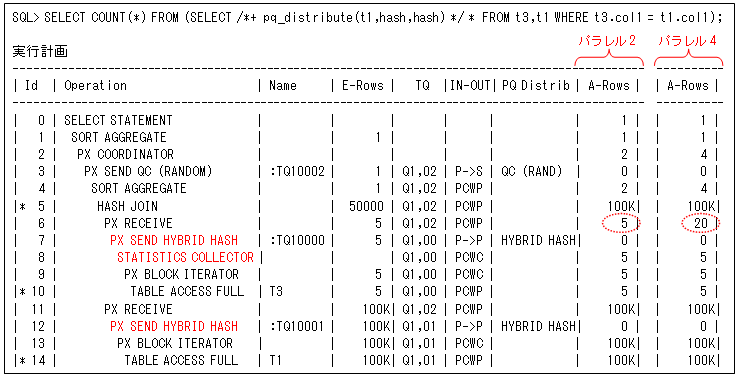
パラレル2のときは行数がしきい値より大きいのでハッシュで行っていますが、パラレル4のときは行数がしきい値より小さいので、ブロードキャストとなってA-Rowsが20(5行×4パラレル)になっています。
以下のように動的パフォーマンス・ビュー’v$pq_tqstat’を見ると、どのようにデータが分割されたかを確認することができます。左側がパラレル度を2にした場合、右側がパラレル度を4にした場合です。右側がそれぞれのPQプロセスで5行を処理しているのが分かります。そして、内部表側のデータがほぼ均等になっています。ただし、通常のブロードキャスト(「(2)データ分散なしとブロードキャスト」の二つ目の実行計画を参照)とは異なり、内部表側のデータはランドロビンで再分散されます(ハッシュ分散の実行計画を実行時にブロードキャストに変換するため仕方ないといえます)。

(2)PQ_SKEWヒント
ハイブリッド・ハッシュ時のもう一つの有効な機能は、重複データによる偏りを調整することです。
大量のデータを分割するにはハッシュ方法が効果的ですが、これには重複データを分割できないという欠点があります。そのため、重複データの割合が大きいと偏ってしまうので、そのようなデータでハッシュ分散を改善するための機能がこれになります。これは、結合の内部表側のテーブルの偏りを改善しますが、オプティマイザが重複を判断する必要があるので、ヒストグラムがないと動作することができません。ただし、PQ_SKEWヒントを使用することで、強制的に実行させることが可能になります(私は、この機能の効果の方が大きいと思います)。
この機能は、ハッシュで分散するとき重複が多い値を分割できるように、複数のPQプロセスに転送する必要があります。例えば、以下のテーブル’T1’と’T3’を等価結合する場合に、重複値’100’によって偏ってしまうので、値’100’を分割しないと均等にできません。そのため、テーブル’T3’の値’100’をすべての結合PQプロセスに転送するようにします(つまり、その値だけブロードキャストします)。
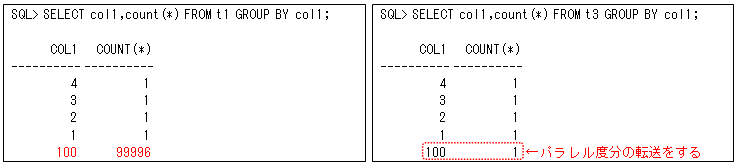
これを実際の実行計画で見てみると以下のようになります(これが動作すると内部表側に操作’PX SEND HYBRID HASH (SKEW)’と出力されます)。この例では、外部表側(テーブル’T3’)の受信’PX RECEIVE’のA-Rowsが6になっています(パラレル度が2なので値’100’を2つのPQプロセスに転送しているからです)。

これもビュー’v$pq_tqstat’を参照して、どのように分割されたかを確認してみます。左側が通常のハイブリッド・ハッシュの場合、右側がPQ_SKEWヒントを使用した場合です。右側は偏りがなくなっているのが分かります。

このようにハッシュ分散で偏ってしまう場合でも、この機能で重複データによる偏りは改善することができるようになります。
(3)PQ_FILTERヒント
相関副問合せは、第29回で説明した「ネストした副問合せの解除」機能によってセミ結合などに変換されますが、以下のようなSQL(NO_UNNESTヒントなど)では変換しないので、’FILTER’操作を使用して行います。この’FILTER’操作のパラレル実行がOracle12cから拡張されているので、使用する機会は少ないと思いますが、参考程度で載せておきます。
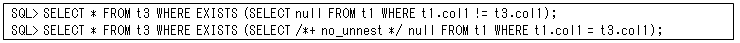
これは、主問合せテーブル(この例のSQLではテーブル’T3’です)のフィルタリングを’FILTER’操作で行うので、パラレル実行ではその’FILTER’操作にどのようにデータ分散するかが重要になります。この動作を明示的に指定するのがPQ_FILTERヒントになり、以下の4つの動作を指定することが可能です。それぞれの動作についての実行計画も載せておきます。
- SERIAL:’FILTER’操作をシリアル処理で行います(これがOracle Database 11gR2までの動作です)
スキャンはパラレルで処理しますが、’FILTER’操作はシリアルで行うので、主問合せのテーブルが非常に小さい場合に行います。 - NONE:データ分散しない(データ転送しない)でパラレル処理を行います
主問合せのアクセスと’FILTER’操作を同一PQプロセスで行うので、主問合せのテーブルが大きい場合にデータ転送のオーバーヘッドを削減できます。殆どの場合はこれが最適ですが、高負荷で主問合せのテーブルがあまり大きくない場合などはHASHやRANDOMの方が最適になります。 - HASH:主問合せテーブルをハッシュ分散してパラレル処理を行います
主問合せのアクセスと’FILTER’操作をハッシュ分散してパラレルで行うので、主問合せのテーブルがあまり大きくない場合などに行います。 - RANDOM:主問合せテーブルをランダム分散してパラレル処理を行います
主問合せのアクセスと’FILTER’操作をランダム(ランドロビン)分散してパラレルで行うので、主問合せのテーブルがあまり大きくなくデータ分散に偏りがある場合などに行います。
|
SQL> SELECT /*+ pq_filter(serial) */ * FROM t3 2 WHERE EXISTS (SELECT /*+ no_unnest */ null 3 FROM t1 WHERE t1.col1 = t3.col1); ———————————————————- | Id | Operation | Name || TQ |IN-OUT| ———————————————————- | 0 | SELECT STATEMENT | || | | |* 1 | FILTER | || | | | 2 | PX COORDINATOR | || | | | 3 | PX SEND QC (RANDOM)| :TQ20000 || Q2,00 | P->S | | 4 | PX BLOCK ITERATOR | || Q2,00 | PCWC | | 5 | TABLE ACCESS FULL| T3 || Q2,00 | PCWP | | 6 | PX COORDINATOR | || | | | 7 | PX SEND QC (RANDOM)| :TQ10000 || Q1,00 | P->S | | 8 | PX BLOCK ITERATOR | || Q1,00 | PCWC | |* 9 | TABLE ACCESS FULL| T1 || Q1,00 | PCWP | |
SQL> SELECT /*+ pq_filter(none) */ * FROM t3 2 WHERE EXISTS (SELECT /*+ no_unnest */ null 3 FROM t1 WHERE t1.col1 = t3.col1); ———————————————————- | Id | Operation | Name || TQ |IN-OUT| ———————————————————- | 0 | SELECT STATEMENT | || | | | 1 | PX COORDINATOR | || | | | 2 | PX SEND QC (RANDOM) | :TQ10000 || Q1,00 | P->S | |* 3 | FILTER | || Q1,00 | PCWC | | 4 | PX BLOCK ITERATOR | || Q1,00 | PCWC | | 5 | TABLE ACCESS FULL| T3 || Q1,00 | PCWP | |* 6 | TABLE ACCESS FULL | T1 || | | ———————————————————- |
|
SQL> SELECT /*+ pq_filter(hash) */ * FROM t3 2 WHERE EXISTS (SELECT /*+ no_unnest */ null 3 FROM t1 WHERE t1.col1 = t3.col1); ———————————————————— | Id | Operation | Name || TQ |IN-OUT| ———————————————————— | 0 | SELECT STATEMENT | || | | | 1 | PX COORDINATOR | || | | | 2 | PX SEND QC (RANDOM) | :TQ10001 || Q1,01 | P->S | | 3 | BUFFER SORT | || Q1,01 | PCWP | |* 4 | FILTER | || Q1,01 | PCWP | | 5 | PX RECEIVE | || Q1,01 | PCWP | | 6 | PX SEND HASH | :TQ10000 || Q1,00 | P->P | | 7 | PX BLOCK ITERATOR | || Q1,00 | PCWC | | 8 | TABLE ACCESS FULL| T3 || Q1,00 | PCWP | |* 9 | TABLE ACCESS FULL | T1 || | | |
SQL> SELECT /*+ pq_filter(random) */ * FROM t3 2 WHERE EXISTS (SELECT /*+ no_unnest */ null 3 FROM t1 WHERE t1.col1 = t3.col1); ———————————————————— | Id | Operation | Name || TQ |IN-OUT| ———————————————————— | 0 | SELECT STATEMENT | || | | | 1 | PX COORDINATOR | || | | | 2 | PX SEND QC (RANDOM) | :TQ10001 || Q1,01 | P->S | | 3 | BUFFER SORT | || Q1,01 | PCWP | |* 4 | FILTER | || Q1,01 | PCWP | | 5 | PX RECEIVE | || Q1,01 | PCWP | | 6 | PX SEND ROUND-ROBIN| :TQ10000 || Q1,00 | P->P | | 7 | PX BLOCK ITERATOR | || Q1,00 | PCWC | | 8 | TABLE ACCESS FULL| T3 || Q1,00 | PCWP | |* 9 | TABLE ACCESS FULL | T1 || | | |
HASHとRANDOMには、’PX SEND QC (RANDOM)’の前に’BUFFER SORT’が出力されていますが、これも’HASH JOIN BUFFERED’と同じように処理結果を格納するためのものです。
3. おわりに
今回はパラレル実行のデータ分散処理について説明しましたが、少しは参考になりましたでしょうか。また機会があれば他のことについても説明したいと思います。これからもよろしくお願いします。 それでは、次回まで、ごきげんよう。
