しばちょう先生の試して納得!DBAへの道 indexページ▶▶
みなさん、こんにちは。”しばちょう”こと柴田長(しばた つかさ)です。そして、ごめんなさい。前回の11月の記事公開から長らく休載させて頂きました。50回で終わりじゃありませんよ。
まずは御礼として、先日3月8日に開催されましたOracle Database Connect 2017にご来場頂きました皆様、本当にありがとうございました!今回は自身のセッションだけではなくイベント全体の企画・運営に携わらせて頂き、如何に技術者の皆様に楽しんでいただけるのか?有益な情報をお届けできるのか?にフォーカスさせて頂き、メンバー一同がいつも以上に本気で準備していました。その結果、「最高のイベントだった!」、「パフォーマンスチューニングの楽しさを再認識した」等の大変ありがたいご感想が社内外から聴こえてくることが本当に嬉しくて、次のイベントも盛り上げていきたいなと思っておりますので、引き続きよろしくお願いします!なお、残念ながら当日ご都合が合わなくてご参加できなかった方へは、全セッション分ではないですがスライドや動画等を公開したいと考えておりますので、是非ご活用のほどよろしくお願いします!!

今回は上記イベントにて、お馴染みの津島博士とJapan Oracle User GroupのOracle ACEメンバー(関口 裕士さん、渡部 亮太さん、諸橋 渉さん)+ 日本オラクルのデータベース・コンサルの畔勝さんと言う超豪華な方々と共に、私がファシリテーターで講演させて頂いたパネルディスカッション形式のセッション「エキスパートはどう考えるか? 体感!パフォーマンスチューニング」で取り上げさせて頂いた、一つ目のパフォーマンス問題について解説させて頂きたいと思います。問題発生時のAWRレポートの何処を見て何を推測し、どのように分析して適切な対処を行うのかを、当日のセッションの流れに沿って皆様も体験して頂けると嬉しいです!
1. A社のパフォーマンス問題:
A社では、基幹業務としてCシステムを運用している。
順調に業績を伸ばしてデータ量も年々増加しているが、これまで問題なく動作していた。
ところが最近になって、性能が影響して業務をこなすのが難しくなってきているため、早急に改善して欲しいとのことである。
ここ最近のトランザクション性能を調べてもらったところ、以下のようになっていることが分かった。
そこで、このシステムの性能が低下した原因の特定と改善方法を、皆さんに様々な情報を使用して考えて頂きたい。
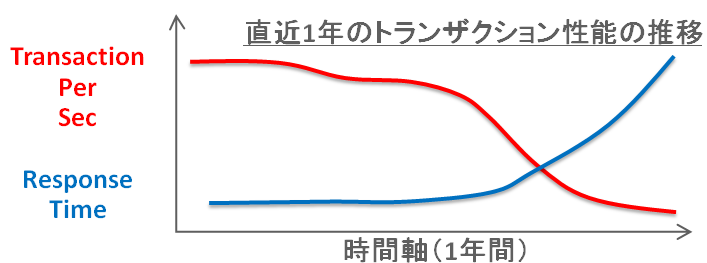
上記のグラフの赤線が秒間のトランザクション量を表す「Transaction Per Sec(TPS)= スループットとも呼ぶ」であり、右に時間が経過するにつれて低下してきていることが確認できます。もう一つの青線はそのトランザクションの「平均レスポンスタイム」を表しており、TPSの低下と共に劣化(より時間を要する=上昇)してきていることも確認できます。
ユーザー数(処理をリクエストする人)が一定である条件下では、分かり易くたとえれば、ユーザー数が一人だけであれば、レスポンスタイムが劣化すれば次のトランザクションをリクエストするまでに時間を要することになるので、単位時間(今回の例では一秒間)当たりのトランザクション量は低下することは理解できるでしょう。つまり、TPSの低下は平均レスポンスタイムの劣化によって引き起こされていると推測するのが基本的には正しいですね。
もちろん、ユーザー数が時間と共に増えたケースでは、もう少し複雑になります。平均レスポンスタイムは同様に劣化しますが、TPSが一定を推移するケースも可能性としては起こり得るからです。
2. 残念ながら異常時のAWRレポートしか手元にありません。と言う前提のもとで、まずは、異常時のAWRレポートの先頭にある H/W構成、Snapshot期間、DB Time、Load Profile辺りを確認してきましょう。
WORKLOAD REPOSITORY report for DB Name DB Id Instance Inst Num Startup Time Release RAC ------------ ----------- ------------ -------- --------------- ----------- --- HDD 1283245756 hdd 1 10-3-09 07:03 11.1.0.7.0 NO Host Name Platform CPUs Cores Sockets Memory(GB) ---------------- -------------------------------- ---- ----- ------- ---------- d02-65.gridcente Linux x86 64-bit 24 24 4 125.97 Snap Id Snap Time Sessions Curs/Sess --------- ------------------- -------- --------- Begin Snap: 111 10-3-09 07:05:34 834 3.3 End Snap: 112 10-3-09 07:13:26 30 1.0 Elapsed: 7.87 (mins) DB Time: 4,501.98 (mins) Cache Sizes Begin End ~~~~~~~~~~~ ---------- ---------- Buffer Cache: 1,856M 1,856M Std Block Size: 8K Shared Pool Size: 1,280M 1,280M Log Buffer: 40,008K Load Profile Per Second Per Transaction Per Exec Per Call ~~~~~~~~~~~~ --------------- --------------- ---------- ---------- DB Time(s): 572.3 4.9 0.09 0.03 DB CPU(s): 2.4 0.0 0.00 0.00 Redo size: 296,187.6 2,555.3 Logical reads: 47,243.0 407.6 Block changes: 1,682.0 14.5 Physical reads: 4,818.6 41.6 Physical writes: 155.3 1.3 User calls: 17,575.9 151.6 Parses: 6,363.1 54.9 Hard parses: 0.7 0.0 W/A MB processed: 148,440.3 1,280.6 Logons: 0.0 0.0 Executes: 6,371.1 55.0 Rollbacks: 0.0 0.0 Transactions: 115.9
以前の記事「第39回 AWRレポートを読むステップ1. バッファ・キャッシュ関連の待機イベントと統計情報」でも解説させて頂いておりますが、上記のAWRレポートの先頭部分は、必ず全てに目を通すようにしてください。トラブル・シューティング時はスピード解決が求められますが、「急がば回れ」「灯台下暗し」を意識して対応しましょう。
これは私の苦い経験から言えることなのです。その苦い経験とは、5ノードで構成されるRACデータベース環境において性能試験を実施していましたが、ある一つのノードだけ性能(処理しているトランザクション量)が他の4ノードと比較して半分でした。その原因を探ろうと、待機イベントやら統計情報、初期化パラメータ等を一通り時間をかけて分析しましたが答えは出ませんでした。そのような窮地を救ってくれたのが、他のメンバーからの次の一言でした。
「CPUコア数が違う!」はい、その通りでした。5ノード中、性能が半分なノードだけ、なぜかCPUコア数が他のノードよりも半分になっていたのです。半分の性能しか出ないわけですね。私は全ノードが同じ構成だと思い込んでしまい、時間を無駄に浪費していただけで、初めにきちんと目を通していれば1分間で答えにたどり着けたわけですね。という事なので、繰り返しになりますが、「急がば回れ」「灯台下暗し」を意識して先ずはAWRレポートの先頭部分には目を通すようにしましょうね。
さて、前置きが長くなりましたが先が長いので急ぎましょう。(結局、急ぐのかい!!)今回の環境は、データベースのバージョンが「11.1.0.7.0」で非RAC構成です。Linux OSでCPUコア数が24コアで物理メモリは125GBですね。
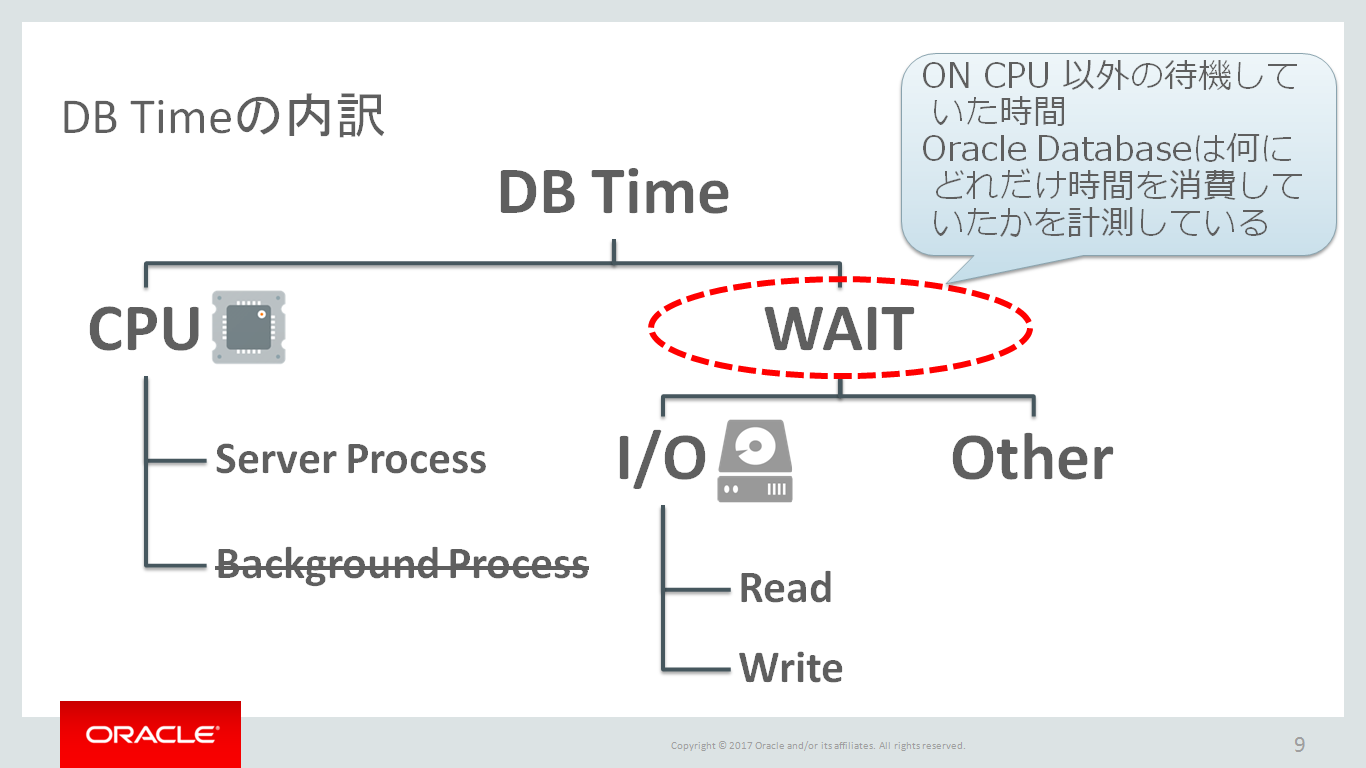
次に、このAWRレポートが記録されたスナップショットのタイムスタンプが2010年なのは驚きですが、(そこは置いておいて)Elapsedが7.87(mins)であることから、およそ8分間のワークロードが記録されているAWRレポートであることが分かります。ここで必ず頭の中に記憶しておくべき大切な数字としては、もし仮に約8分間で全CPUコア24個を100%で使い続けたら、8分間 × 24CPUコア = 192分間です。なぜならば、(もちろん、全てのAWRレポートで言えることではないですが)「Elapsed」の下に記述されている「DB Time」の値が、この192分間とどれだけ乖離しているのかと言う点が、「CPU使用率が100%に張り付いてしまっていてなかなかCPUを使える番が回ってこずに待機した時間」 or 「CPU処理以外で待機してしまった時間」を感覚的に把握するのに役立つからです。今回のAWRレポートではDB Timeの値が4501分間ですよね?圧倒的にCPUを使えていなかった時間が長いと推測できるわけです。ちなみに、CPU処理以外の待機とは、I/O待機時間、Network待機時間、Oracle Database内のロック獲得待機時間があげられますね。
続いて、Load Profileセクションを眺めていきますが、ここの値は正常時のAWRレポートのものと比較すると、どの処理がどれだけ変化しているのかを確認することができます。今回は異常時のAWRレポートしか無いという前提ですから、説明は割愛させて頂きます。強いて一点だけ補足しておくと、Redo Size (Per Second)の値について私なりの指標をお伝えしておくと、1MB以下は全く更新負荷が低い。10MB前後でまあまあ更新負荷があるね。40MB前後でかなり更新負荷があるね。と言う感覚です。もちろん、一つのデータベース・インスタンスとして。ちなみに、200MB/secを超えるRedo生成量のAWRレポートを見たことがありますが、その場合は凄い更新量ですね!でした。
という事で、解説が長くなってしまいましたが、ここではCPU処理以外で待機していそうな予想ができましたね。
3. 次に「Foreground Wait Class」セクションで、待機クラス全体の内訳を確認してみましょう。
Foreground Wait Class DB/Inst: HDD/hdd Snaps: 111-112
-> s - second, ms - millisecond - 1000th of a second
-> ordered by wait time desc, waits desc
-> %Timeouts: value of 0 indicates value was < .5%. Value of null is truly 0
-> Captured Time accounts for 101.3% of Total DB time 270,119.00 (s)
-> Total FG Wait Time: 272,445.37 (s) DB CPU time: 1,141.70 (s)
Avg
%Time Total Wait wait
Wait Class Waits -outs Time (s) (ms) %DB time
-------------------- ---------------- ----- ---------------- -------- ---------
User I/O 2,274,862 0 270,982 119 100.3
DB CPU 1,142 0.4
Commit 55,985 0 1,048 19 0.4
Other 2,665 66 159 60 0.1
Concurrency 5,662 57 140 25 0.1
Configuration 223 0 102 459 0.0
System I/O 700 0 8 11 0.0
Network 5,351,212 0 6 0 0.0
Application 1 0 0 1 0.0
Administrative 0 0 0.0
-------------------------------------------------------------
いきなり、「Top n Timed Foreground Events」を確認しても良いのですが、各待機イベントについて詳しくなければ少し難しい気がしますので、待機イベントをグルーピングした待機クラス毎の待機時間でざっくりと待機の傾向を把握することをお勧めします。それが、上記の「Foreground Wait Class」セクションですね。
はい、一目瞭然です!!上記の赤文字で示した行により、User I/O待機クラスがDB time(270,119秒=4,501分)のほぼ100%(%DB time列を参照)を占めていることが理解できます。つまりは、I/O時間による待機時間が今回の性能劣化に関係していそうな予感がしてきます。
4. 「User I/O」待機クラスでの待機時間が、全DB Timeに占める割合がほぼ100%であったので、具体的にどのI/O関連の待機イベントで待機している時間が長いのかを「Top n Timed Foreground Events」セクションで確認してみましょう。
Top 5 Timed Foreground Events
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Avg
wait % DB
Event Waits Time(s) (ms) time Wait Class
------------------------------ ------------ ----------- ------ ------ ----------
db file sequential read 2,247,220 269,640 120 99.8 User I/O
DB CPU 1,142 .4
log file sync 55,985 1,048 19 .4 Commit
db file scattered read 21,259 716 34 .3 User I/O
read by other session 6,382 626 98 .2 User I/O
そして、いよいよ「Top n Timed Foreground Events」を見ていくわけですが、これも非常に分かり易い現象が発生していますね。
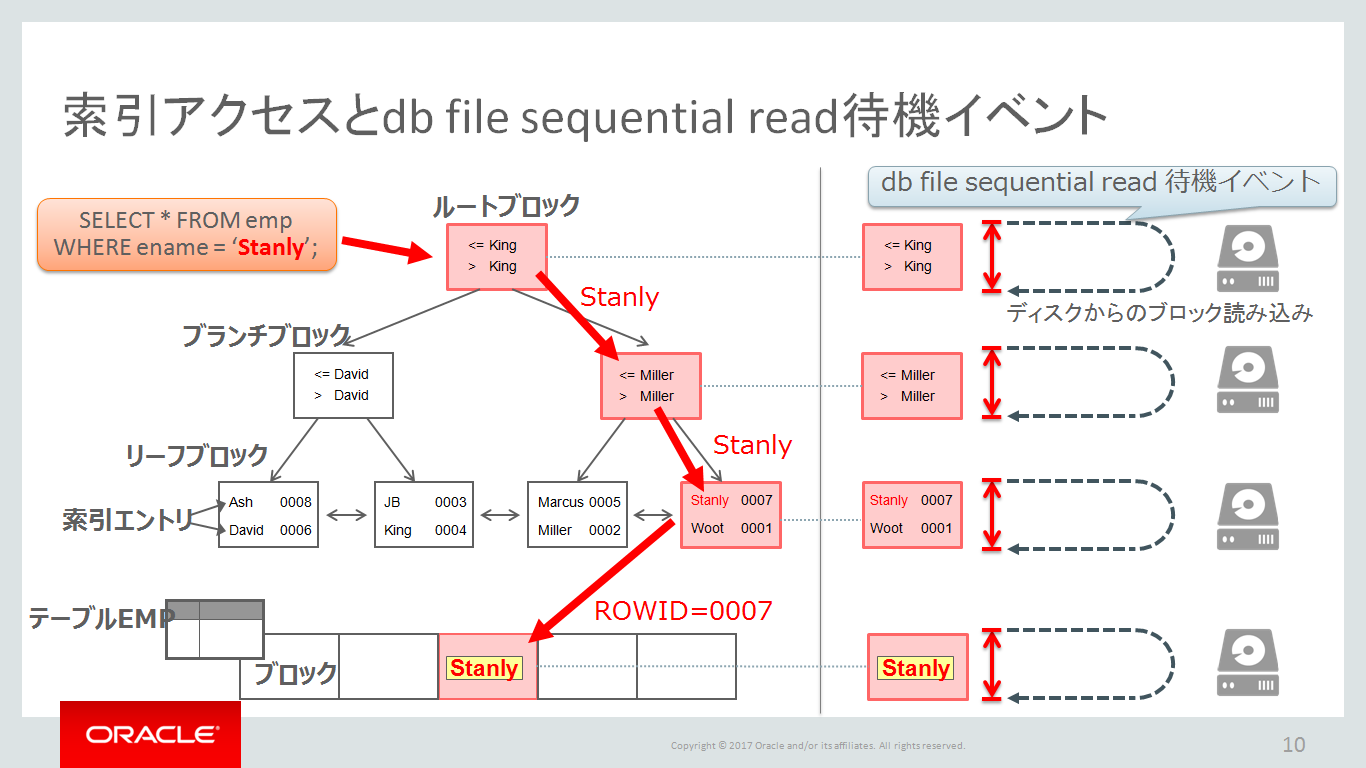
待機イベント「db file sequential read」の待機時間だけで、DB timeの99.8%(% DB time)を占めています。その待機回数(Waits)は2,247,220回と多く、合計待機時間(Time(s))は269,640秒で平均待機時間(Avg wait(ms)=一回の待機で待機した時間)は120ミリ秒です。
ちなみに、「待機回数が多い」ことが完全に悪ではないケースがあることを覚えておいてください。Oracle Databaseでは、CPU処理以外の何かしらの処理をすればほとんどのケースで待機イベントは発生(カウントアップ)します。大切なのはその総待機時間と平均待機時間が大きいか否かです。例えば、今回の待機イベント「db file sequential read」は、クエリ実行時にBツリー索引を利用して目的のレコードへアクセスする際に、ディスクからSingle Block Readを行う際に発生します。例えFlashのような高速なデバイスでも、一回は一回なのです。もちろんBuffer Cache上に必要なブロックがキャッシュされていれば、待機イベント「db file sequential read」は発生しませんね。(おっと答えのヒントになってしまう・・・)
繰り返しになりますが、大切なのはその総待機時間と平均待機時間が大きいか否かですので、各待機イベントの平均待機時間はどの程度が正常なのだろうか?という指標が欲しくなるわけですが、全ての待機イベントの指標を覚えている人は居ないのではないかと思います。やはり正常時のAWRレポートとの比較が大切になってくるわけですから、異常時だけではなく、常日頃からAWRレポートを補完する運用を組み込むべきですね。
とはいえ、この「db file sequential read」待機イベントの平均待機時間については覚えておくべきだとも思います。この待機イベントは、一つのブロックをデバイスからBuffer Cacheへ読み込む際に発生し、それに要した時間が平均待機時間となります。Hard Disk Driveの環境であれば、10~20msec、Flash Deviceであれば数ミリ秒が正常ラインですね。1msec未満であれば、ストレージ筐体のコントローラーキャッシュ(メモリ)から読み込まれている可能性が高いです。
今回は平均待機時間が120ミリ秒であり、仮に低速なHard Disk Drive環境であったとしても正常ラインの10~20msecの6~12倍の遅さに劣化していることが理解できます。つまり、ざっくりと平常時のトランザクションのレスポンスタイムが最悪6~12倍まで遅くなっていると推測できるわけですね。
5. db file sequential read待機イベントの総待機時間と平均待機時間が非常に大きい事実が分かりましたが、その理由として何を疑いますか?
上記の問いをセッション中にJPOUGメンバー(Oracle ACEの3名)に尋ねてみたところ、次の3つを候補として挙げて頂きました。ちなみにセッション当日のやり取りは、綿密な事前打ち合わせを繰り返し行い、想定のシナリオ通りであったことは今となってはネタバレしても良いですよね(笑)
理由候補1 – 関口 裕士さん) データ量が増加することで、Index Range Scanでアクセスするブロック数が増加したのではないか?
理由候補2 – 渡部 亮太さん) バッファキャッシュ・ヒット率が低下したのではないか?
理由候補3 – 諸橋 渉さん) ストレージの性能の問題だ!!
6. 理由候補1)Index Range Scanでアクセスするブロック数が増加?について分析してみましょう。
今回のパフォーマンス・トラブルはトランザクションのレスポンスタイムが劣化していることなので、一番実行時間が長いSQLから順番に分析をしていく手法です。実行時間が長い順にSQLが並べられているのは「SQL ordered by Elapsed Time」セクションですね。
SQL ordered by Elapsed Time DB/Inst: HDD/hdd Snaps: 111-112
-> Resources reported for PL/SQL code includes the resources used by all SQL
statements called by the code.
-> % Total DB Time is the Elapsed Time of the SQL statement divided
into the Total Database Time multiplied by 100
-> Total DB Time (s): 270,119
-> Captured SQL account for 76.3% of Total
-> Total DB Time (s): 270,119
-> Captured PL/SQL account for 0.1% of Total
Elapsed CPU Elap per % Total
Time (s) Time (s) Executions Exec (s) DB Time SQL Id
---------- ---------- ------------ ---------- ------- -------------
176,851 304 417,901 0.4 65.5 6nc8pzf4u00v0
Module: java@in10-65 (TNS V1-V3)
select i.itemid, listprice, unitcost, supplier, i.productid, name, descn, catego
ry, status, attr1, attr2, attr3, attr4, attr5, qty from item i, inventory v, pr
oduct p where p.productid = i.productid and i.itemid = v.itemid and i.itemid = u
pper(:1)
27,970 93 417,766 0.1 10.4 ak73zgvjq6mj6
Module: java@in10-6b (TNS V1-V3)
select productid, name, descn, category from product where(lower(name) like :1)
はい、説明不要なぐらい、圧倒的にSQL ID =「6nc8pzf4u00v0」であるSELECT文が一番実行時間(Elapsed Time(s))を要していることが理解できます。注意点は、ここで言っている実行時間とは一回の実行辺りではなく、そのSQL文が実行された総回数の合計実行時間です。なので、Executions列を見て頂くと「417,901」回実行していて、一回当たりの実行時間(Elap per Exec(s))は「0.4」秒であることが分かります。また、総実行時間(Elapsed Time(s))の「176,851」秒は、全DB timeに対して「65.5」%という高い割合を示していることから、このSQLの実行時間を短縮することが重要そうだと感じられますね。逆に、例えば、全DB timeに対して「0.1」%の割合しか占めないSQL文をチューニングしても全体からすると意味が無いですものね。
さらにここで知っておいてもらいたいのは「CPU Time(s)」列であり、このSQLでは「304」秒と記録されていますが、これは総実行時間(Elapsed Time(s))の「176,851」秒の内、CPUを使用した処理時間は「304」秒と言うことになります。ここからも、CPU処理以外の部分での時間が非常に多い状況であると認識できます。このようにパズルのように状況証拠が揃って行くのは面白いですね。
さて戻りましょう。ちょっと問題がありそうなSQLが特定できたので、このSQLが理由候補1)で挙げて頂いた「Index Range Scanでアクセスするブロック数が多くなっているのでは?」に該当しているのかを確認していきましょう。つまり、このSQLを一回実行する為にどれだけのブロックにアクセスしたのかを確認できれば良いという事ですから、「SQL ordered by Gets」セクションで対象のSQL IDのSQLを確認してみます。
SQL ordered by Gets DB/Inst: HDD/hdd Snaps: 111-112
-> Resources reported for PL/SQL code includes the resources used by all SQL
statements called by the code.
-> Total Buffer Gets: 22,299,452
-> Captured SQL account for 76.4% of Total
Gets CPU Elapsed
Buffer Gets Executions per Exec %Total Time (s) Time (s) SQL Id
-------------- ------------ ------------ ------ -------- --------- -------------
5,857,598 417,901 14.0 26.3 304.02 1.8E+05 6nc8pzf4u00v0
Module: java@in10-65 (TNS V1-V3)
select i.itemid, listprice, unitcost, supplier, i.productid, name, descn, catego
ry, status, attr1, attr2, attr3, attr4, attr5, qty from item i, inventory v, pr
oduct p where p.productid = i.productid and i.itemid = v.itemid and i.itemid = u
pper(:1)
如何でしょうか?このSQLを一回実行するためにアクセスしたブロック数は「Gets per Exec」列の「14.0」であることが分かりました。14ブロックかー・・・微妙です。少ないわけではないですが、異常に多いわけでもないです。やはり、パフォーマンスが正常時のAWRレポートと比較しなければ何とも言えないのが現実ですね。
7. 理由候補2)バッファキャッシュ・ヒット率が低下?について分析してみましょう。
Instance Efficiency Percentages (Target 100%)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Buffer Nowait %: 99.97 Redo NoWait %: 100.00
Buffer Hit %: 89.80 In-memory Sort %: 100.00
Library Hit %: 99.97 Soft Parse %: 99.99
Execute to Parse %: 0.12 Latch Hit %: 99.93
Parse CPU to Parse Elapsd %: 0.00 % Non-Parse CPU: 96.15
始めから見なさいよ!!って怒られそうですよね。はい、ごめんなさい。もちろん、演習2でLoad Profileセクションを確認していますが、その流れで一気に目を通しておくことをお勧めします。
でもって、今回の異常時のAWRレポートでは上記の通り90%を下回る値が表示されています。この値については、以前の記事「第39回 AWRレポートを読むステップ1. バッファ・キャッシュ関連の待機イベントと統計情報」でも紹介させて頂いているように、
「「99.00%」という数字は「100%」に非常に近い値ですが、「高い」とか「低い」という表現は非常に曖昧なものであり、厳密に何%以上だから高くて十分だ。という指標は無いのです。そもそもキャッシュ・ヒット率は何を示していたのか思い出して下さいね。簡単に言えば、バッファ・キャッシュを経由するブロック読込み総回数に対して、ディスクから読まずバッファ・キャッシュにヒットした回数の割合ですね。つまりは、100%からヒット率を引いた値はディスクから読み込むことになるわけで、今回のAWRレポートでは1%がディスクから読んでいます。そして、この1%分のIOPSをディスクが捌けるのか否かと言う点が、キャッシュ・ヒット率が高いか低いかを判断する際に最も重要なことなのです。バッファ・キャッシュを経由するブロック読込み総回数が100回であれば1回のディスクI/Oで済みますが、総回数が100万回であれば1万回のディスクI/Oが発生するわけであり・・・」です。指標な無いです。ただし、90%を切るようなキャッシュ・ヒット率は低すぎる!と断言はできます。
とはいえ、これもパフォーマンスが正常時のAWRレポートと比較しなければ何とも言えないですね。
8. 理由候補3)ストレージ性能の問題?について分析してみましょう。
はい、これはAWRレポートだけで分析するのは非常に難しいです。ストレージ構成やASMディスク・グループの構成が把握できていれば推測することはできますが、可能であればOS側の統計であるiostatやdstatの出力結果が欲しいところですね。これについては別途ご紹介する機会を設けたいと思います。
ここで覚えておいて欲しいことは、パフォーマンスを分析する際にはOracle Database内の情報(例えば、AWRレポート)だけでは十分ではなく、OS側のシステム統計もきちんと取得しておくことが大切です。そのために、OSWatcherなるツールがMy Oracle Supportで公開されておりますので、是非活用してみてくださいね。
9. キャッシュ・ヒット率の低下が問題の原因になりそうですが、これをもう少し深堀りする情報は無いでしょうか?
と言う問いに対して、津島博士から解説して頂いたのが次の「SQL ordered by Gets」と「SQL ordered by Reads」セクションの情報を用いたSQL単位でのキャッシュ・ヒット率の確認方法です。
SQL ordered by Gets DB/Inst: HDD/hdd Snaps: 111-112
Gets CPU Elapsed
Buffer Gets Executions per Exec %Total Time (s) Time (s) SQL Id
-------------- ------------ ------------ ------ -------- --------- -------------
5,857,598 417,901 14.0 26.3 304.02 1.8E+05 6nc8pzf4u00v0
SQL ordered by Reads DB/Inst: HDD/hdd Snaps: 111-112
Reads CPU Elapsed
Physical Reads Executions per Exec %Total Time (s) Time (s) SQL Id
-------------- ----------- ------------- ------ -------- --------- -------------
1,452,977 417,901 3.5 63.9 304.02 1.8E+05 6nc8pzf4u00v0
上記は総実行時間が一番長いSQLを抜粋したものですが、一回の実行辺りにアクセスした平均ブロック数(バッファ・キャッシュ上 or ディスクからの読み込み問わず)は「14.0」で、一回の実行辺りにディスクから読み込んだ平均ブロック数は「3.5」という事が確認できますよね。この二つの数字を利用して、このSQLを実行する際のキャッシュ・ヒット率を計算できるのです。
使用した14ブロックの内、3.5ブロックはディスクから読んだという事は、14 – 3.5 = 10.5個はキャッシュ・ヒットしたという事ですから、 (14 – 3.5) / 14 * 100 = (1 – 3.5 / 14) * 100 = 75% であり、SQL単位でも非常に低いキャッシュ・ヒット率であることが理解できますね。
10. 突然ですが、パフォーマンスが正常時のAWRレポートが見つかりました(笑)という事で、おさらいしてみましょう。
先ずは、理由候補1)のIndex Range Scanでのアクセス範囲が広がっているのか?ですが、以下の通り「SQL ordered by Gets」セクションの「Gets per Exec」を比較する限り、「14.0」から変化していないことが確認できました。
(正常時のAWRレポートから抜粋) SQL ordered by Gets DB/Inst: HDD/hdd Snaps: 79-80 Gets CPU Elapsed Buffer Gets Executions per Exec %Total Time (s) Time (s) SQL Id -------------- ------------ ------------ ------ -------- --------- ------------- 30,205,061 2,163,767 14.0 34.1 253.02 323.74 6nc8pzf4u00v0
(異常時のAWRレポートから抜粋) SQL ordered by Gets DB/Inst: HDD/hdd Snaps: 111-112 Gets CPU Elapsed Buffer Gets Executions per Exec %Total Time (s) Time (s) SQL Id -------------- ------------ ------------ ------ -------- --------- ------------- 5,857,598 417,901 14.0 26.3 304.02 1.8E+05 6nc8pzf4u00v0
次に、バッファキャッシュ・ヒット率が低下?ですが、以下の通り明確に低下してしまっていることが確認できました。
(正常時のAWRレポートから抜粋)
Instance Efficiency Percentages (Target 100%)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Buffer Nowait %: 100.00 Redo NoWait %: 100.00
Buffer Hit %: 99.97 In-memory Sort %: 100.00
Library Hit %: 100.12 Soft Parse %: 99.99
Execute to Parse %: 0.03 Latch Hit %: 99.58
Parse CPU to Parse Elapsd %: 0.01 % Non-Parse CPU: 92.68
(異常時のAWRレポートから抜粋)
Instance Efficiency Percentages (Target 100%)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Buffer Nowait %: 99.97 Redo NoWait %: 100.00
Buffer Hit %: 89.80 In-memory Sort %: 100.00
Library Hit %: 99.97 Soft Parse %: 99.99
Execute to Parse %: 0.12 Latch Hit %: 99.93
Parse CPU to Parse Elapsd %: 0.00 % Non-Parse CPU: 96.15
何よりも正常時の「Foreground Wait Class」セクションを見て頂くと、異常時のAWRレポートではUser I/O待機クラスの%DB timeがほぼ100%に達していたのに対して、以下のように3.3%の割合であったことが理解できます。
Foreground Wait Class DB/Inst: HDD/hdd Snaps: 79-80
-> s - second, ms - millisecond - 1000th of a second
-> ordered by wait time desc, waits desc
-> %Timeouts: value of 0 indicates value was < .5%. Value of null is truly 0
-> Captured Time accounts for 115.0% of Total DB time 3,196.81 (s)
-> Total FG Wait Time: 953.75 (s) DB CPU time: 2,721.14 (s)
Avg
%Time Total Wait wait
Wait Class Waits -outs Time (s) (ms) %DB time
-------------------- ---------------- ----- ---------------- -------- ---------
DB CPU 2,721 85.1
Concurrency 47,458 89 575 12 18.0
Commit 217,159 0 149 1 4.7
User I/O 16,236 0 106 7 3.3
Other 80,991 92 105 1 3.3
Network 21,051,742 0 18 0 0.6
Configuration 57 0 1 19 0.0
System I/O 700 0 0 0 0.0
Application 1 0 0 1 0.0
Administrative 0 0 0.0
-------------------------------------------------------------
今回のパフォーマンス・トラブルの原因としては、時間の経過と共にデータ量が増加してバッファ・キャッシュへデータをキャッシュし切れなくなった為に、ディスクI/Oが頻発することとなり、トランザクションのレスポンスタイムの遅延とスループットの低下を招いたのだと結論付けることができそうですね。
そして、対処策としては、これまたいくつか候補があるとは思いますが、先ずはキャッシュ・ヒット率を向上させるために可能であればバッファ・キャッシュのサイズを増加させる策を検討するべきでしょう。演習2で確認済みなように、今回のデータベース・サーバーは125GBと非常に大きな物理メモリが搭載されていますが、実は・・・バッファ・キャッシュのサイズが「1,865MB」しか割り当てていないのですよ。これも演習2で掲載済みだったのですが、お気付きでしたでしょうか?もし気付かれていた方がいらっしゃったら、私の連載を読んでいる時間がもったいない人だと思います。「急がば回れ」「灯台下暗し」を実践されている方で、本当に素晴らしいです。
ちなみに、弊社データベース・コンサルの畔勝さんからのおすすめとしては、10分間に一度のAWRのSnapshotを取得し、一カ月間は保持する設定・運用がお勧めとのガイドも頂きました。また、この設定は秒間1万回のSQLが実行されるデータベース環境においても問題なく動作しているとのことで安心して設定変更ができそうですね。もちろん、保持するデータ量が多くなるのでSYSAUX表領域のサイジングには十分にご注意くださいね。また、定期的なディクショナリ統計情報の収集も忘れずに!!
さてさて、いかがでしたでしょうか?イベント当日さながらの臨場感あふれる文章を書こうと思いましたが、私の文章能力では無理でした。ごめんなさい。でも、我々がセッションで伝えたかったことはもれなく記載させて頂いたと思っています。動画も公開されると聞いておりますので、本記事と合わせてご活用頂けると幸いです。なお、最後の対処策の部分はほとんど解説できませんでしたが、ここまでご理解いただけた皆様であれば問題なくチューニングしてくれることでしょう。是非、津島博士の連載の方で、自動メモリ管理や自動共有メモリ管理について学んでみてください。イベント当日には、この辺りを津島博士に解説して頂いています。
という事で、今回も最後までお付き合い頂きまして、ありがとうございました。次回もご愛読のほど、よろしくお願いします!
