皆さんこんにちは、今年も2月になって寒さがさらに厳しくなってきましたね。全国的に大雪で大変そうですので、皆さんも気を付けてください(都心近郊については、今年はあまり積らずに終わりそうですね)。
今回は、最近少し気になったSQLについて説明しようと思います。今ではSQL自動変換などが効果的に機能して、最適な実行計画になるのが多くなったと思いますが、SQLの書き方によっては効果的にならない場合もあります。そこで今回は、そのようなSQLを効果的に使用するための注意点についてまとめてみました。後半に、Oracle Database 11gR2(Oracle11gR2)で少し変更になったダイレクト・リードについても説明していますので、参考にしてください。
1. SQL自動変換されないSQL
まずは、SQL自動変換されないSQLについて説明しましょう。
これまで、様々なオプティマイザのSQL自動変換(問合せトランスフォーマ)について説明してきましたが、SQLの書き方によっては最適にSQL自動変換を行わない場合があることも知っておく必要があります。基本は、複雑なSQLなどを使用すると効果的に行わない場合が多いですが、それ以外にもSQLによっては発生しやすいものがあります。そのため、SQL自動変換で注意が必要なSQLとして、最近目にした以下の二つについて説明します。
(1)Full Outer Join(完全外部結合)
(2)OR条件
(1)Full Outer Join
Full Outer Joinは、使用する機会は少ないと思いますが、最も複雑な結合を行う処理になるので、効果的な実行計画にならない場合があります。そのため、使用するときは注意が必要ですが、動的SQLなどでは影響がないと思って、通常は行わない方法で使用する場合があります。ただし、それが性能問題になることもあるので注意が必要です。
例えば、以下のように結合する必要がないのに、Full Outer JoinをするようなSQLなどです(動的SQLでは、すべてFull Outer Joinにするために行ったりします)。このSQLは、副問合せ’B’の結果が“レコードが選択されませんでした。”になるので、影響がないとFull Outer Joinを使用していると思いますが、以下のようにテーブル’tab2’を全表スキャンしてしまうので、大きなテーブルでは性能問題になってしまいます。

このSQLは、列リストの最後にNULLを出力することになるので、以下のSQLにすることで最適になりますが、残念ですがこのように変換はしません。そのため、できればこのSQLを実行してください。
SQL> SELECT A.*, NULL c1,NULL c2 FROM tab1 A;
ただし、Oracle Database 12cからのLeft Outer Joinは、以下のようにテーブル’tab2’にアクセスしない実行計画に変換します。そのため、注意するのはFull Outer Joinだけになります。
SQL> SELECT * FROM tab1 A LEFT OUTER JOIN (SELECT c1,c2 FROM tab2 WHERE (1=2)) B ON A.c1=B.c1; 実行計画 ---------------------------------- | Id | Operation | Name | ---------------------------------- | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS FULL| TAB1 |
このように書き換えるのが難しい場合は、以下のようにダミーテーブル’dual’を使用するだけでも効果的です。このようなテーブルをアクセスしない場合は、このダミーテーブルを知っておくと便利です。

もう一つの注意点は、第34回で説明したNative Full Outer Joinが、使い方によっては動作しないことです。 例えば、以下のSQLのように’ON (1=1)’を使用する場合には、Native Full Outer Joinが動作しません(これは、「動的SQLの注意点について」で使用しているSQLです)。そのため、左外部結合とNOT EXISTSが動作しますが、NOT EXISTSでアンチ結合が動作していないので、更に効率の悪い動作になります。このSQLは、副問合せ’B’の結果が1行になるので、これも影響がないとFull Outer Joinを使用していると思いますが、このような効率の悪い実行計画になってしまいます。
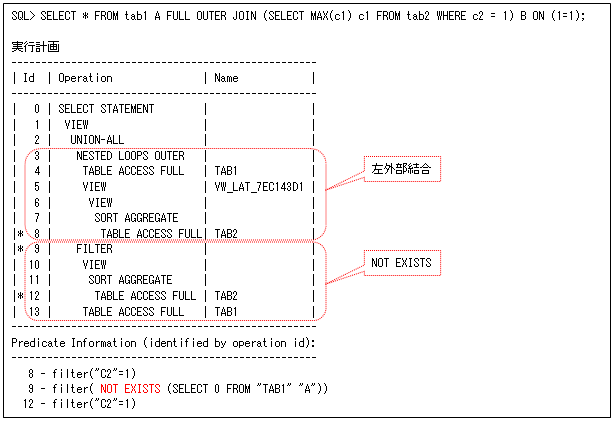
このSQLは、Full Outer Join以外に変更することでも実行計画を改善(NOT EXISTSしないように)できますが、副問合せ’B’の結果をすべての行の列リストに追加するだけなので、以下のSQL(スカラー副問合せ)にすることで更に効果的な実行ができます。ただし、残念ですがこれについても変換はしません。
SQL> SELECT A.*, (SELECT MAX(c1) FROM tab2 WHERE c2 = 1) c1 FROM tab1 A; 実行計画 ----------------------------------- | Id | Operation | Name | ----------------------------------- | 0 | SELECT STATEMENT | | | 1 | SORT AGGREGATE | | | 2 | TABLE ACCESS FULL| TAB2 | | 3 | TABLE ACCESS FULL | TAB1 |
このような単純な処理でも、複雑な実行計画になってしまう場合があるので、動的SQLを使用するような場合でも注意してSQLを実行するようにしてください。また、今回の例は、特殊なSQLのように思われるかもしれませんが、知らずに使うような方もいると思うので注意してください。
動的SQLの注意点について
ご存知ない方のために、ここで動的SQLの注意点について簡単に説明します。
動的SQLは、実行時にSQL文を生成して実行することができるので、様々な検索条件でSQLを実行するときには非常に便利な機能です(パッケージ・アプリケーンなどで使用しているのが多いと思います)。ただし、使い方を間違えると非常に効率の悪い(無駄な処理を含んだ)実行計画になってしまいます。これは、動的SQLのプログラムでは、様々な検索条件のSQLを作成するのが複雑になりやすいので、SQLのパターンを少なくするようなことが多いからです。つまり、プログラミングを重視(効率化)すると性能問題になりやすいので、注意する必要があるということです。
例えば、以下のPL/SQLプログラムのように、基本はテーブル’tab1’とFull Outer Joinをする処理になるので、すべてをFull Outer Joinにする場合などです(条件が’01’の場合は、副問合せ’B’の結果をすべての行に追加するために、’ON (1=1)’でFull Outer Joinを行っています)。
この動的SQLは、変数’tab3_rec’に検索する列数と属性が合っていれば、どのようなSQLでも(結合するテーブルが異なっても)変数’v_stmt_str’に格納して実行できるので、様々なSQLが使用できるようになっています。
TYPE tab3CurTyp IS REF CURSOR;
v_tab3_cursor tab3CurTyp;
tab3_rec tab3%ROWTYPE;
v_stmt_str VARCHAR2(200);
v_from VARCHAR2(50);
BEGIN
— Dynamic SQL statement
IF xxx = ’01’ THEN
v_from := ‘(SELECT MAX(c1) c1 FROM tab2 WHERE c2 = 1) B ON (1=1)’;
ELSE
v_from := ‘tab2 B ON A.c1 = B.c1’;
END IF
v_stmt_str := ‘SELECT … FROM tab1 A FULL OUTER JOIN ‘ || v_from;
OPEN v_tab3_cursor FOR v_stmt_str;
LOOP
FETCH v_tab3_cursor INTO tab3_rec;
EXIT WHEN v_tab3_cursor%NOTFOUND;
… ⟨Fetch後の処理は省略⟩ …
END LOOP;
CLOSE v_tab3_cursor;
END;
/
(2)OR条件
OR条件については、索引スキャンと全表スキャンのどちらが効果的かで、UNION ALLと使い分けて使用するようにと第9回のOR拡張で説明しましたが、それ以外にSQL自動変換についても注意する必要があります。第42回で説明したNull Accepting Semi-Joinは、このOR条件を改善して自動変換するようにした機能ですが、IS NULLだけが可能になったものなので、その他の条件ではセミ結合に変換しません。そのため、以下のSQLのようにfilter操作になってしまい、パラレル実行することもできない効率の悪い実行になります(第39回で説明したpq_filterヒントを使用してもパラレルで行うことができません)。
実行計画
————————————————————————-
| Id | Operation | Name | | TQ |IN-OUT| PQ Distrib |
————————————————————————-
| 0 | SELECT STATEMENT | | | | | |
|* 1 | FILTER | | | | | |
| 2 | PX COORDINATOR | | | | | |
| 3 | PX SEND QC (RANDOM)| :TQ20000 | | Q2,00 | P->S | QC (RAND) |
| 4 | PX BLOCK ITERATOR | | | Q2,00 | PCWC | |
| 5 | TABLE ACCESS FULL| TAB1 | | Q2,00 | PCWP | |
| 6 | PX COORDINATOR | | | | | |
| 7 | PX SEND QC (RANDOM)| :TQ10000 | | Q1,00 | P->S | QC (RAND) |
| 8 | PX BLOCK ITERATOR | | | Q1,00 | PCWC | |
|* 9 | TABLE ACCESS FULL| TAB2 | | Q1,00 | PCWP | |
————————————————————————-
Predicate Information (identified by operation id):
—————————————————
1 – filter(“A”.”C1″=1 OR EXISTS (SELECT 0 FROM “TAB2” “B” WHERE “B”.”C2″=:B1))
9 – filter(“B”.”C2″=:B1)
このようにOR条件を使用しているSQLでは、SQL自動変換しないときにUNION ALLを使用することで、最適な実行計画になる場合があるので、SQLチューニングするときには行ってみてください。以下は、上記のSQLをUNION ALLに変更したSQLの実行計画ですが、セミ結合をパラレル実行しています(LNNVL関数は、最初のブランチの’c1=1’と同じ結果を検索しないための条件です)。

ただし、第24回で説明したようにUNION ALLでは、ブランチごとにテーブル・アクセスするので、それが非効率にならないように注意する必要があります。ただし、そうであってもパラレル実行する方が効果的ということもあるので、それも考慮するようにしてください。この例の場合は、テーブル’tab1’の全表スキャンを2回実行していますが、それでもセミ結合の方がパラレル実行できるので効果的ということです。これは、以下のようにアンチ結合(NOT EXISTSなど)でも同じようになるので、このようなSQLには注意してください。
実行計画
———————————–
| Id | Operation | Name |
———————————–
| 0 | SELECT STATEMENT | |
|* 1 | FILTER | |
| 2 | TABLE ACCESS FULL| TAB1 |
|* 3 | TABLE ACCESS FULL| TAB2 |
OR条件は、使用する機会が多いと思うので、このようなことにも注意して使用するようにしてください。
2. ダイレクト・リード
最後に、Oracle11gR2から少し変更されているダイレクト・リードについて説明しましょう。
Oracleデータベースは、バッファ・キャッシュを効果的に使用することで高速にしています。そのため、第13回で説明したように「大きいテーブル(Long Tables)」をスキャンする場合に、バッファ・キャッシュを経由しないダイレクト・リードを使用します。このときバッファ・キャッシュに載せるオーバーヘッドがないので、I/O性能が向上するという効果もあります(Exadataでは、Smart Scanが動作することで更に向上します)。ただし、ダイレクト・ライトのように、APPENDヒントなどで明示的に指定することができません。そのため、効果的に使用するには少し注意が必要になりますが、Oracle11gR2からの変更も含めて知らない方が多いようなので、以下について少し説明します。
- (1)シリアル・フル・スキャン
- (2)パーティション表
- (3)オプティマイザ統計
(1)シリアル・フル・スキャン
ダイレクト・リードは、「大きいテーブル」をパラレル・フル・スキャンする場合に、効果的なI/Oをするための機能になるので、シリアル・フル・スキャンでは「大きいテーブル」でも使用しません。そのため、Oracle11gR2からExadataが出たこともあり、ダイレクト・リードを行うように拡張されましたが、以下のようにパラレル・フル・スキャンとは少し異なっているので注意してください。
- バッファ・キャッシュにデータが存在しない場合
パラレル・フル・スキャンと同じように、「大きいテーブル」はダイレクト・リードを行います。 - バッファ・キャッシュにデータが存在する場合
「大きいテーブル」でもキャッシュされている割合(ダーティ・ブロックの割合も関係する)で、ダイレクト・リードが動作しなくなります。
シリアル・フル・スキャンの場合には、同時実行などを考慮してパラレルにしていない場合もあるので、バッファ・キャッシュのアクセスの方を優先するようになっています。そのため、検証などで確実にダイレクト・リードを行うには、以下のようなバッファ・キャッシュのフラッシュなどが必要になります。
SQL> ALTER SYSTEM FLUSH BUFFER_CACHE;
ただし、Oracle11gR2から「非常に大きいテーブル」と判断されると、無条件にダイレクト・リードを行うようにはなっています。
(2)パーティション表
パーティション表のダイレクト・リードは、テーブル・サイズやそれぞれのパーティション・サイズごとに決定するのではなく、アクセスするすべてのパーティションの合計サイズによって決定します。そのため、同じテーブルでも(同じパーティションにアクセスしても)パーティション・プルーニングによってアクセスするサイズが異なることで、ダイレクト・リードと非ダイレクト・リード(フル・スキャン、索引スキャン)が変化する場合があるので注意してください。例えば、パーティション’p01’だけのアクセスはダイレクト・リードにならないのに、パーティション’p01’と’p02’のアクセスではダイレクト・リードになる場合があります。
(3)オプティマイザ統計
ダイレクト・リードは、オプティマイザ統計を使用して決定すると思っている方も多いかもしれませんが、これまではセグメント・ヘッダー内のセグメント・サイズを使用して行っているので、実行計画と同じように決定される訳ではありませんでした。そのため、Oracle11gR2からオプティマイザ統計を使用するように変更されているので、オプティマイザ統計を更新するまでは変化しなくなっています。例えば、大量のデータをインサートすることで、セグメント・サイズがしきい値より大きくなった場合に、動作が異なってくるので注意してください(Oracle11gR2より前はダイレクト・リードになりますが、Oracle11gR2からはダイレクト・リードになりません)。これもそんなに気にする必要はないと思いますが、たまにこのようなことで問題になる場合があるので、参考レベルで載せておきました。
3. おわりに
今回はSQL自動変換の注意点とダイレクト・リードについて説明しましたが、少しは参考になりましたでしょうか。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
