皆さんこんにちは、もう梅雨入りしましたね。ジメジメした嫌な時期が続きますが、体調に気をつけて頑張りましょう。
今回は、第5回の続きとして、オプティマイザ統計と実行計画について説明します。オプティマイザ統計の収集が複雑になっていますので、少し情報を整理したいと思いまとめてみましたので、参考にしてください。
1. オプティマイザ統計と実行計画
まずは、オプティマイザ統計(統計)と実行計画について説明しましょう。
実行計画の管理が難しいことから、コストベース・オプティマイザ(CBO)よりルールベース・オプティマイザ(RBO)の方が、使い易いというようなことを聞きます。これは、RBOがSQLの構文によって実行計画を作成するため、経験のある方には管理し易いからだと思います。ただし、複雑なSQL文のときや経験の少ない方でも効果的に使用できるという意味では、統計からコスト計算して、実行計画を作成するCBOの方が優れています。ただし、正確な統計を必要とするのがCBOの問題点です。また、統計の変化によって実行計画が変化する可能性もあります。これは、データの傾向が変化すれば、実行計画も変化する可能性があるのはCBOの正しい動作です(これは皆さんも知っていることですよね)。そのときに、性能アップするように変化する以外に、性能ダウンする場合もあるのが問題となる訳です。そのため、変化することを前提に運用する必要があります。
CBOのコストについて
ご存知ない方のために、ここでCBOのコスト計算について簡単に説明します。今まで、実行計画のコストに関係する項目(Rows,Bytes,Cost)について説明していなかったので、ここでCBOのコスト計算を含めて説明します。
実行計画のCost列は、CBOによる見積もりコストで、このコストが最小になるように実行計画が作成されます。このコストを計算するための基になるのがRows列とBytes列で、それぞれは以下のように求めます。
Rowsは、Operationによって返される行数になります(WHERE句が指定されている場合は、列統計から条件に一致する行数を算出します)。Bytesは、その行数に対象の平均列サイズ(ディクショナリ・ビュー”dba_tab_columns”の列”avg_col_len”)の合計を掛けた値です(以下の例の平均列サイズの合計は、189/21=9バイトになります)。つまり、実行計画を見たときに、このRowsとBytesが実際の値とかけ離れていたら、統計の精度が正しくないということです(以下の例では、”レコードが選択されませんでした”の場合でもRowsが21行になっているので、あまり精度は良くないです)。そのような場合は、ヒストグラムなどを作成しないと正確になりません。

dbms_xplan.display_cursor関数を以下のように実行して(GATHER_PLAN_STATISTICSヒント文のSQL文に対して)、”E-Rows”(見積もり件数)と”A-Rows”(実際の処理件数)を比較することで、Rowsについては簡単に調べることができます(リアルタイムSQL監視の”Rows(Estim)”と”Rows(Actual)” の比較でも可能です)。

Costは、このRowsとBytesからI/Oブロック数を求めて、それにシステム統計(CPUコストとI/Oコスト)を加えることで求めます。
性能ダウンする要因として、統計(表統計、列統計、索引統計など)を限られた情報に格納しているため、完全なデータの傾向を表現できない場合があるからです。そのため、SQL文によっては影響が多きくなる場合があります。以下のような複雑な(実行計画の候補が多いような)SQL文などは注意が必要です。
- 結合するテーブルが多い(副問合せが多い)
- WHERE句の述語が多い(結合列が多い)
- 範囲条件(<,>)である
このようなSQL文にならないように、データベース設計できれば良いのですが、簡単ではないと思いますので、テスト時に十分な確認を行うようにしてください(つまり、性能ダウンしないようにするには、テストしていない統計を使用しないことです)。これを本番システムに影響を与えないようにするには、テストできる環境を用意することが重要になります(テスト環境があるといろいろと便利ですので、用意していないシステムでは検討してみてください)。この運用は、以下のどちらかで行うことになります。
a. テスト後は統計を収集せずに性能ダウンしたらそれのみを収集する
統計を収集しないことにより性能ダウンする可能性があるため、そのときは関係する統計の収集を行います(改善しない場合は、SQLチューニングが必要になります)。
b. 統計を収集して性能ダウンするものは使用しない
運用中に(または確認したSQL文で)性能ダウンした場合は、そのSQL文に関係する統計を使用しない(または元に戻す)ようにします。
これについては、a.のように行っているシステムも多いようですが、b.の方が性能ダウンしたときの影響が少なくなります。このb.のための機能が、第5回で説明したSPMや「オプティマイザ統計の保留」などになりますので、これを上手く使用して運用するようにしてください(SPMなどの運用の詳細は、別の機会に説明します)。
オプティマイザ統計の保留について
ご存知ない方のために(説明していなかったので)、ここでオプティマイザ統計の保留について説明します。
統計をある時点に戻すには、履歴からリストアする必要がありましたが、Oracle Database 11gからは統計を保留中として保存することが可能です(収集しても実行計画に使用しないようにできます)。これを使用することで、事前にテストを行ってから、実際に使用するかを判断することが可能です。以下のように行うと、これ以降で表”TAB01”の統計が実行計画に使用されないようになります。これは、データベース(set_database_prefs)やスキーマ(set_schema_prefs)のレベルでも行うことができます。

事前テストなどで保留中の統計を使用する場合には、ALTER SESSION文などで初期化パラメータOPTIMIZER_USE_PENDING_STATISTICSを”TRUE” にすることで可能です。そして、保留中の統計をテスト後に公開(実行計画に使用)または削除する場合は、以下のように行います。

保留中の統計については、ディクショナリ・ビュー”user_tab_pending_stats”、”user_ind_pending_stats”で確認することが可能です。
2. 実行計画の変化について
ここでは、なぜ実行計画が変化するのかについて説明しましょう。
よく実行計画が変化して遅くなったということを聞きますが、すべてを実行計画の変化によるものと思い込んでいる方が多い気がします。これは、多くのSQLを使用しているシステムでは、すべてのSQLの実行計画を調査できないからです(テストで性能が遅くなったSQLの実行計画だけを確認するのが一般的だと思います)。 データの傾向が変化した統計を収集すると、実行計画が変化する可能性はありますが、常に変化する訳ではありません。これは、知っているようで知らないことも多いと思いますので、変化する可能性のあることを以下に挙げてみました。これは、統計とSQL文の問題によって発生しますので、このようなことを知っておくことも運用時に有効になります。
- オプティマイザ統計が不正確
- バインド変数の値が異なる
- 共有カーソルのINVALID
- システム統計の変化
- オプティマイザ統計の失効
(1)オプティマイザ統計が不正確
統計が正確でないため、これで実行計画が変化する場合が最も多いです。 統計の精度を上げると収集時間が長くなるため、簡単にサンプルサイズなどを増やすことはできません。そのため、数日間に別けて収集するなどして、必要最低限の収集を行う必要があります。正確でない理由としては、以下のことが考えられます
- 収集するデータの精度(サンプルサイズ、列統計)
収集時間を短くするために、収集するサンプルサイズを少なくするや列統計のヒストグラムを取得しないなどを行います。それにより、統計の内容が正しく収集できていないため、実行計画が変化する可能性が高くなるということです(統計に格納する情報の限界によって正しくない場合もあります)。このような統計の精度と収集時間を調整するのは簡単ではありませんが、Oracle Database 11g(Oracle11g)からのDBMS_STATS.AUTO_SAMPLE_SIZEを使用することで、収集時間をそんなに長くせずに100%に近い収集をすることが可能です。 - 収集するタイミング(統計が古い)
データの傾向が変化しているのに収集していないので、正しい統計になっていないということです。これは、実行計画が最適になっていないために、性能ダウンする問題になります。ただし、多くの方は実行計画の変化による性能ダウンに、これも含めて同じ問題と取らえているため、問題を複雑化している場合があります。
統計が正確でない場合は、Oracle11gR2からのカーディナリティ・フィードバックが動作する場合もあります。これは、実際のカーディナリティ(異なる値の数)が統計と異なっていると、実際のカーディナリティ値を次回以降で使用することで、実行計画が変化する場合です(このような統計が正確でないときでも、実行計画を最適にするような機能が、今後も増えていくと思います)。また、動的サンプリングが動作した場合も変化する場合があります(初期化パラメータOPTIMIZER_DYNAMIC_SAMPLINGを変更すると、動作するタイミングが変化します)。カーディナリティ・フィードバックや動的サンプリングが行われた場合は、実行計画のNote部で確認することができます。
列統計について
ご存知ない方のために、ここでオプティマイザ統計の列統計について簡単に説明します。
列統計は、第5回でも少し説明したように、列データのNUM_DISTINCT(異なる値の数)や分布などの統計です。この統計を使用して、WHERE句の条件に一致する件数を求めます。そのため、この統計の精度によって効果的な実行計画になるか決まると言っても過言ではありません。ただし、この統計の情報には、列データ長の上限が32バイトまでとヒストグラム(データ分布情報)の限界などで常に正確になるとは限りません。特にデータ分布については、ヒストグラムを作成しない場合はもちろんですが(最大値と最小値を使用してデータが均等に分布しているとするため、偏っていなければ問題ないです)、作成してもNUM_DISTINCTが多くなると精度が低下していきます。ヒストグラムは、異なる値をバケット(ヒストグラムの格納単位)に格納して分布を表現していますが、そのバケットの数には制限(最大254まで)があるからです。そのため、ヒストグラムには以下の2種類が存在します(パラメータMETHOD=”FOR ALL COLUMNS SIZE AUTO”にすると、Oracleデータベースがデータ配分とワークロードに基づいて、ヒストグラムの収集する列が判断されます)。
- 頻度ヒストグラム(FREQUENCY)
バケット毎に異なる値を格納するので、正確に値の件数を把握することが可能ですが、NUM_DISTINCTを最大254までしか格納できません。これはパケット数の制限により、異なる値をそれぞれのパケットに格納できないからです。バケットは、列値と行数(正確には列値以下の値の行数)で管理されます。 - 高さ調整済ヒストグラム(HEIGHT BALANCED)
NUM_DISTINCTが255以上の場合には、このヒストグラムになります。これは、バケットにデータ行数を均等に格納するため、それぞれの異なる値の数を正確に把握することはできません(一つのバケットに複数の値が入るため、それぞれの値の正確な件数は不明だからです)。バケットは、バケット番号とバケット内の最大値で管理されます。
列に作成されているヒストグラムは、以下のように”HISTOGRAM”列を参照することで確認できます。

(2)バンド変数の値が異なる
バインド変数を使用するとカーソルを共有できますので、実行計画が変化することはありませんが、バインド変数内のデータ値を確認して実行計画を作成する場合は、値によって変化する場合があります(第7回で説明した「バインド変数の先読み(bind peek)」や「優れたカーソル共有」などが動作した場合です)。つまり、SQL文に異なるリテラル値を使用しているのと同じようになり、別の実行計画が子カーソルとして作成されます。これは、以下のようなSQL文で、異なる件数を見積もったときに動作します。
- 範囲条件(<,>など)
- 等価条件でヒストグラムが存在する(ヒストグラムがないと均等になるので動作しない)
SQL> EXEC dbms_stats.delete_column_stats(NULL,'TAB02','C01',col_stat_type=>'HISTOGRAM');
(3)共有カーソルのINVALID
これは第7回でも説明しましたが、気がつかずに操作を行ってしまう場合が多いような気がします。Ageout(共有プールからの溢れ)のときと異なり、ハードパース時に必ず実行計画が変更する可能性があります(このハードパースによる性能ダウンも発生します)。これは、以下に関係するSQLの共有カーソルがINVALID(無効化)になりますので、注意してください。できれば頻繁に行わないようにしてください(まとめて行うなどしてください)。
- 表の変更(削除/TRUNCATE/ALTER TABLE文/RENAME)
- 索引の変更(作成/削除/ALTER INDEX文)
- オプティマイザ統計の収集(NO_INVALIDパラメータがFALSEのとき)/削除
- アウトラインの変更(変更/削除)
- その他のオブジェクト(ビュー, 順序, シノニム,ファンクション)の変更(変更/削除)
(4)システム統計の変化
統計には、オブジェクトの統計以外に、システムハードウェア情報の統計があります(これにはCPU性能やI/O性能が含みます)。SQL文のWHERE句の条件に一致する件数が同じでも、システム統計が異なるとコストが変わります(実行計画のRows,Bytesが同じでもCostが変わります)。それによって、実行計画が変わる場合もあります。ただし、システム統計が変化しても共有カーソルはINVALIDになりませんので、次回ハードパースするときに変わる可能性があります。このシステム統計は、自動オプティマイザ統計収集では収集されませんので、以下のように手動で収集しない限り変化しません(以下は非作業負荷統計を収集する場合です)。
SQL> EXEC dbms_stats.gather_system_stats();
(5)オプティマイザ統計の失効
統計の失効とは、以下のようにオブジェクトの変更が多いため、統計収集の対象になるということです。このとき、共有カーソルがINVALIDになる訳ではありませんので、自動オプティマイザ統計収集などを行うまで実行計画は変化しません。Oracle10gR2から多少変更されていますので少し説明しておきます。
- 表統計の失効は、ディクショナリ・ビュー”dba_tab_statistics”のSTALE_STATS=’YES’になるときです。これは、統計プリファレンス・パラメータSTALE_PERCENT(デフォルト10%)の割合の変更が発生した場合になります。ディクショナリ・ビュー”dba_tab_modifications”の変更合計件数(INSERT + UPDATE + DELETE)と”dba_tables”のnum_rows(行数)から確認できます。
- 索引統計の失効は、ディクショナリ・ビュー”dba_ind_statistics”のSTALE_STATS=’YES’になるときです。これは、索引のLAST_ANALYZEDの値が表のLAST_ANALYZEDより前になっている場合です。ただし、Oracle10gR2からパラメータcascadeのデフォルトがDBMS_STATS.AUTO_CASCADEになっています(索引統計を収集するかどうかをOracleデータベースが決定しますので、索引も更新されるようになっています)
このディクショナリー・ビューは、Oracle10gまでは15分おきに反映されますが、Oracle10gR2からは統計収集時(自動および手動)などのときのみ反映されます。そのため、明示的に更新する場合は、以下のように実行する必要があります。
SQL> EXEC dbms_stats.flush_database_monitoring_info();
つまり、統計収集やflush_database_monitoring_infoを行わないと失効しないということです。パラメータoptionsに”GATHER STALE”(または”GATHER AUTO”)を指定して統計の収集(gather_schema_statsまたはgather_database_stats)をすると、失効したオブジェクトだけの統計を収集します(自動オプティマイザ統計収集は、”GATHER AUTO”で行っています)。
システム統計について
ご存知ない方のために、ここでシステム統計について簡単に説明します。
システム統計とは、Oracle9iからのCPU性能とI/O性能の統計で、作業負荷統計と非作業負荷統計があります。非作業負荷統計は、Oracle Database 10g(Oracle10g)から追加されたデータベース・アクティビティ(作業負荷)がない状態の統計です(内部的にデータファイルにランダムI/Oを行って収集します)。これは、最初のインスタンス起動時に以下のように初期化されます(Oracle10g以前ではデフォルト値が使用されていました)。
- ioseektim(シークタイム + OSオーバーヘッドの時間):10ミリ秒
- iotrfspeed(1ブロックの平均転送速度):4096バイト/ミリ秒
- cpuspeedNW(非作業負荷CPU速度):インスタンス起動時のCPU速度(MHz)
I/O性能は、システムによって異なりますので、使用しているシステムが上記の値と大きく異なる場合には、システムに負荷がないときなどに実行して収集することをお薦めします。この値は、get_system_statsプロシージャーを使用して確認できます(以下に簡単な例を示します)。
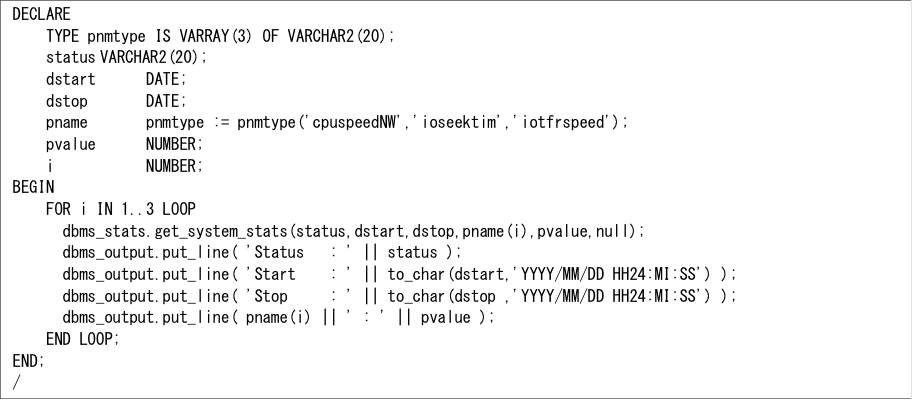
作業負荷統計は、明示的に収集しないと設定されませんが、取得されると非作業負荷統計は無視されます。これは、収集したときのデータベース・アクティビティに対して、以下のような詳細な情報になります(索引アクセス、全表アクセス、パラレル実行などの判断を詳細に行うようにします)。そのため、データベース・アクティビティが異なると正しい実行計画になりませんので、扱いに気を付ける必要があります。
- 1ブロックおよびマルチ・ブロックの平均リードタイム(ミリ秒)
- 指定したタスクを実行したCPU速度(MHz)
- MBRC(マルチ・ブロック・リードの平均ブロック数)
- 最大I/Oスループット(バイト/秒)
- スレーブ単位での平均I/Oスループット(バイト/秒)
作業負荷が異なる時間帯では、I/O性能などは異なってきますので、それぞれの時間帯で正確な実行計画にするようなときに使用します。例えば、日中はOLTPトランザクションを処理し、夜間はバッチ処理を行う場合、日中と夜間の作業負荷統計をそれぞれ取得しておいて(識別子を付けてユーザ表に格納)、時間帯に応じて作業負荷統計をアクティブ(システム統計情報をディクショナリにインポート)するように行います。
3. 自動オプティマイザ統計収集の補足
最後に、第5回でも説明した自動オプティマイザ統計収集についてもう少し説明しましょう。
オプティマイザ統計の収集には様々な難しさがありますので、Oracleデータベースも進化してきています(これからも進化して行くと思います)。ただし、現在のベストな方法は自動オプティマイザ統計収集ですので、できるだけ多くの方に効果的に使用して欲しいと思っています(特に経験の少ない方に最適な機能だと思います)。確かに、複雑なところもありますが、これは様々なことに対応できるようになっているからです。自動的に起動することができないのであれば、手動で自動オプティマイザ統計収集と同じように収集することをお薦めします。 ここでは、補足としてデフォルトでは収集しないものやスケジュール・ジョブについて説明します。
(1)デフォルトでは収集しない
自動オプティマイザ統計収集でもデフォルトでは収集しないものがありますので、それについて説明します。
すべてをデフォルトで最適に統計収集する訳ではありませんので、どのような問題になる可能性があるかを知っておく必要があります。以下の統計がデフォルトでは収集しませんので、必要な場合は設定する必要があります。これは、「いつ収集する必要があるか」や「何を収集する必要があるか」はシステムよって異なりますので、デフォルトでは収集しないようになっています。性能問題が発生した場合には、実行計画のコストを見て収集を検討してください。
- 拡張統計(列グループ、式に対する統計)
列統計の拡張になりますので、WHERE句に一つの表の複数の列で条件を指定している場合には列グループ統計(第5回で説明した複数列の統計)、WHERE句に式(ファンクション索引など)を使用するような場合には式に対する統計を検討してください(以下は列グループ統計のエントリを作成する例です。これで自動オプティマイザ統計収集などで収集されるようになります)。SQL> SELECT dbms_stats.create_extended_stats(NULL,'TAB02','(c1,c2)') FROM dual'; DBMS_STATS.CREATE_EXTENDED_STATS(NULL,'TAB02','(C1,C2)') -------------------------------------------------------------------------------- SYS_STUF3GLKIOP5F4B0BTTCFTMX0W
- システム統計
CPU性能やI/O性能に関する統計ですが、デフォルト値が使用されます。これを収集すると正しく実行計画を作成することができますが、上手く運用しないと逆効果になりますので注意してください。 - 固定オブジェクト
これは、自動パフォーマンス・ビュー(v$ビュー)の実表(x$表)になりますので、アプリケーションの変更やデータベース構成の変更などのワークロードが変わるときは、以下のように収集する必要があります(AWRやStatspackでも使用されていますので、取得に時間が掛かるようなときも収集してください)。SQL> EXEC dbms_stats.gather_fixed_objects_stats;
(2)スケジューラ・ジョブ
自動オプティマイザ統計収集で使用しているスケジューラ・ジョブについて説明します。
オプティマイザ統計収集で難しいことの一つは、すべてを1回で(1日の決まった時間内で)収集できないようなときに、どのように行うかです。サンプルサイズを小さくして収集時間を短くするという方法もありますが、実行計画に影響する場合は変更することはできません。そのような場合は、自動オプティマイザ統計収集を使用するか、または参考にするのが良いと思います。
自動オプティマイザ統計収集は、スケジュール・ジョブを使用して動作しますので、それのSTOP_ON_WINDOW_CLOSE属性の設定によって、ウィンドウ時間内にすべてを収集できない場合の動作が決まります。自動オプティマイザ統計収集は、デフォルトで”TRUE”(キャンセルするよう)になっています。そのため、次の日に実行されたときに、収集されていないオブジェクトが収集されます。数日間ですべてを収集することになりますので、1日で終了させたい場合には”FALSE”にする必要があります。ただし、Oracle11gからは、変更することができませんので注意してください(起動時に”ORA$AT_OS_OPT_SY_XXXX”のジョブ名で自動的に実行されるため、毎回同じジョブ名では実行されないからです)。そのため、すべて終了させるようにする場合は、ウィンドウ時間を変更する必要があります。ジョブの確認もジョブ起動中に以下のように行う必要があります(Oracle10gのジョブ名は”GATHER_STATS_JOB”固定です)。
SQL> SELECT job_name,program_name,schedule_name,stop_on_window_close 2 FROM dba_scheduler_jobs WHERE job_name LIKE 'ORA$AT_OS_OPT_SY_%';
4. おわりに
今回はオプティマイザ統計と実行計画について説明しました。また機会があれば他のオプティマイザ統計についても説明しようと思います。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
