皆さんこんにちは、今年の冬は非常に寒かったですが、やっと暖かくなってきましたね。
これからは花粉の季節ですので、大変ですが頑張りましょう。
今回は、「パフォーマンスの良いSQL文について」の続きとしてバッチ処理で役立ちそうなテーブル・ファンクションについて説明しようと思いますので、参考にして下さい。
1. テーブル・ファンクションとは
まずは、Oracle9iからのテーブル・ファンクションについて簡単に説明しましょう。
通常のファンクションは列に対する処理になりますが(結果を列として返しますが)、様々な条件判断で複数の列を処理する必要がある場合には効率良くありません(第24回ではUNION ALLやインライン・ビューなどを使用しましょうと説明しましたが、それにも限界があります)。そこで以下のように1行のすべての列(テーブル)に対するファンクションがあると嬉しいので、そのようなファンクションをOracle9iからテーブル・ファンクション(表関数)として提供しています。このテーブル・ファンクションは、仮想テーブルのように扱うことが可能な(通常のテーブルと同じように問合せできる行を生成する)ユーザー定義のPL/SQLファンクションです。
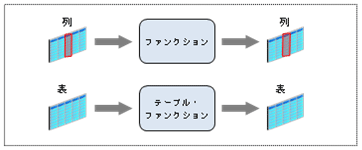
特に、バッチ処理などは多くの列を処理する必要があるので、SQL文を作成するにはSQL文が長く複雑になってしまいます。そのような場合には、テーブル・ファンクションを使用することを検討すると良いでしょう。バッチ処理などのパフォーマンス問題はパラレル化できないことによる問題が多いので、上手く使用することで改善することが可能です。このような複雑な処理は、PL/SQLプロシージャーでも可能ですが、パラレル化するにはアクセスするデータを手動で分割する必要があるため(または第11回で説明したDBMS_PARALLEL_EXECUTEを使用するなどが必要になるため)、簡単に変更できなかったりする場合が多いと思います。
テーブル・ファンクションは、SELECT文のFROM句のTABLE(<コレクション式>)を使用することで、コレクション型(ネストした表またはVARRAY)をテーブルとして扱えるようにします。このコレクション式にPL/SQLコレクション型を戻り値とするファンクションを指定することで、ファンクションの結果を普通のテーブルと同じように扱います。そのため、パラレル化も簡単に行うことができます(第20回で説明したパラレル実行も使用できます)。また、以下のようにテーブル結合やINSERT INTO SELECT文を使用して1度に行うことも可能ですので、汎用性も高いです。
SQL> SELECT * FROM TABLE(<ファンクション>) JOIN tab01 USING(c1);
ただし、入力パラメータと戻り値にPL/SQLコレクション型などを使用する必要がありますので、PL/SQLに慣れないと少し難しく感じると思いますが、便利な機能ですので是非とも慣れて使用してみて下さい。
テーブル・ファンクションには、以下の二つがありますが、基本は使い易いパイプライン・テーブル・ファンクションを使用します。
・ テーブル・ファンクション(非パイプライン表関数)
・ パイプライン・テーブル・ファンクション(パイプライン表関数)
それでは、それぞれについて説明していきます。
PL/SQLコレクション型について
ご存知ない方のために、ここでPL/SQLコレクション型について簡単に説明します。
PL/SQLのデータ変数は、スカラー型(単一のデータを保持できる)やレコード型(異なるデータを複数保持できる)を使用してテーブルの列データなどを格納して処理しますが、それ以外に他のプログラム言語と同じようにコレクション(同じデータの集まり)を扱うことができます。PL/SQLコレクション型には、VARRAY、ネストした表、連想配列の3つの型があります(これ以外にSQLオブジェクト型もSQLスカラー型と同様に使用できます)。このデータ型の組合せで様々なユーザー定義のデータ型を作成することができます。ただし、テーブル・ファンクションのRETURNデータ型に指定できるのはネストした表とVARRAYになります(つまり、一般的にはコレクション型内にレコード型やSQLオブジェクト型などを指定してテーブルのように使用します)。このPL/SQLコレクション型の違いは、以下のような添字の仕様と初期化方法になります。
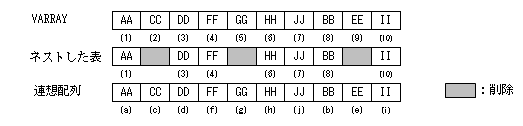
・ VARRAY(可変サイズの配列)は、宣言されている最大サイズまで要素の数を変更できる配列です。EXTENDコレクション・メソッドで最大サイズまで追加することができます(これが可変サイズという理由です)。SQLオブジェクト型と同様にコンストラクタ・メソッドを使用して初期化や代入を行いますが、それぞれの要素には”<変数名>(<添字>)”として参照します。
・ ネストした表は、数が指定されていない(最大値が決まっていない)行を格納する列型です。PL/SQL変数では配列と同じように連続した添字で管理されますので、操作はVARRAYと同じになります(VARRAYと異なるのはDELETEコレクション・メソッドで要素を削除できることです。削除した場合は添字が連続しなくなります)。
・ 連想配列(旧PL/SQL表または索引付き表)は、添字を文字列などで使用することができる配列のため、キーは連続する必要はありません。これはPL/SQLデータ型になりますので、PL/SQLブロックまたはパッケージ内で作成する必要があります(コンストラクタ・メソッドもありません)。
SQLオブジェクト型とPL/SQLレコード型の違いは、以下のような作成とアクセス方法になります。
・ PL/SQLレコード型は、テーブルのすべてまたは一部の行などを格納するためのデータ型です。ユーザー定義のレコード型や%ROWTYPE属性を使用したレコード型などの変数を作成して、”<変数名>.<フィールド名>”でアクセスします。作成はPL/SQLブロックまたはパッケージ内で行う必要があります。
・ SQLオブジェクト型は、オブジェクト表(名前、属性、メソッド)で使用するユーザー定義データ型ですので、コンストラクタ・メソッド(SQLオブジェクト型を作成すると自動的に作成されるSQLオブジェクト型と同じ名前のシステム定義メソッドです)を使用して初期化や代入を行います(初期化を行うと”<変数名>.<属性名>”として参照できます)。作成はスキーマ・レベル(CREATE TYPE文)で行う必要があります(オブジェクト表を使用しない場合は、コンストラクタ・メソッドで初期化が必要なレコード型のようなものと知っておくレベルで問題ないと思います)。
(1)RETURNデータ型の作成
まずは、戻り値のためのコレクションのタイプを作成する必要がありますので、簡単な例(テーブル”tab02”のNULL以外の値を結果として受け取る処理)を使用して説明しましょう。
入力パラメータとしては、通常のデータ型、レコード型、コレクション型、REFカーソル型などの変数が指定できるため、様々な方法でSQL文から呼び出すことが可能ですが、REFカーソル型を使用するのが最も効果的だと思います(ファンクション呼び出しの入力データとして、CURSOR式でSELECT文を自由に変更できるからです)。ここでは、以下のようにCURSOR式を入力パラメータとして実行するテーブル・ファンクション”func01”を作成してみましょう。
以下のようにファンクションの戻り値”tab02_tbl_type”としてPL/SQLコレクション型を作成します。この例ではSQLオブジェクト型のネストした表型をスキーマ・レベル(CREATE TYPE文)で作成して使用します。CURSOR式を使用するため、テーブル・ファンクションの入力パラメータには、REFカーソロ型を使用する必要があります(以下の例は、事前定義カーソル型”SYS_REFCURSOR”を使用しています)。
/
CREATE OR REPLACE TYPE tab02_tbl_type AS TABLE OF tab02_type;
/
CREATE OR REPLACE FUNCTION func01(p1 SYS_REFCURSOR) RETURN tab02_tbl_type
IS
…..
(2)非パイプライン表関数
次に、テーブル・ファンクション”func01”を非パイプライン表関数として作成します。
これが基本的なテーブル・ファンクションになりますが、通常のファンクションのように結果をRETURN文で返しますので、複数行を格納できるネストした表型またはVARRAY型の変数を作成する必要があります(この例では、戻り値用としてネストした表型変数”out_rec”を、FETCHしたデータの格納用としてレコード型変数”in_rec”を作成しています)。以下の例では、テーブル”tab02”のNULL以外のデータをそのまま返していますが、1行に対して複数行を返すようにすることも可能です(データを格納するときには、EXTENDコレクション・メソッドを行って要素を追加する必要がありますので、条件によって追加する数を変更すれば可能です)。SQLオブジェクト型とネストした表型は、コンストラクタ・メソッドを使用して初期化または代入する必要があります(この例の場合はtab02_type()とtab02_tbl_type()になります)。
out_rec tab02_tbl_type := tab02_tbl_type(); — ネストした表の初期化
in_rec tab02%ROWTYPE; — tab02用レコード型変数
i BINARY_INTEGER := 1;
BEGIN
loop
FETCH p1 INTO in_rec;
EXIT WHEN p1%NOTFOUND;
IF in_rec.c1 IS NOT NULL OR in_rec.c2 IS NOT NULL THEN
out_rec.EXTEND; — 要素の追加
out_rec(i) := tab02_type(in_rec.c1,in_rec.c2); — SQLオブジェクト型を代入
i := i + 1;
END IF;
end loop;
RETURN out_rec;
END func01;
/
show errors
エラーはありません。
最後に「show errors」を入れていますが、これはSQL*PlusでPL/SQLのコンパイル・エラーを表示するコマンドです。PL/SQLは、作成(コンパイル)時にエラーになっても詳細を出力しませんので、エラーを調べるために「show errors」コマンドを使用します。SQL Developer(SQL*PlusのGUI版)を使用すれば簡単に開発が行えますので、難しいと思われる方は使用してみて下さい。
(3)パイプライン表関数
次に、同じ例のパイプライン表関数を作成します。
パイプライン表関数を使用するとファンクションの結果をパイプライン化する(行をその生成時に反復的に戻す)ことが可能になります。そのため、以下のように結果をRETURN文で返すのではなく、PIPE ROW文で返します(ただし、コレクション型変数を作成する必要はありませんが、コレクション型をRETURNデータ型として定義する必要はありますので注意して下さい)。パイプライン表関数を使用するにはPIPELINEDオプションを指定します。
パイプライン化するとコレクション全体がメモリにステージングされるのを待つ必要がないため、非パイプライン表関数に比べて応答時間が速く、メモリ使用量を削減することができます。非パイプライン表関数は、すべてのデータが終了しないと返さないため、同一行以外に対しても(変数に格納済みのデータも)変更できるというメリットはあります。また、グループ集計のような処理(すべてのデータが終了しないと結果を作成できない)などもパイプラインは使用できません。そのような必要がない場合は、パイプライン表関数を使用するようにして下さい。
in_rec tab02%ROWTYPE;
BEGIN
loop
FETCH p1 INTO in_rec;
EXIT WHEN p1%NOTFOUND;
IF in_rec.c1 IS NOT NULL OR in_rec.c2 IS NOT NULL THEN
PIPE ROW(tab02_type(in_rec.c1,in_rec.c2));
END IF;
end loop;
RETURN;
END func01;
/
2. パラレル・テーブル・ファンクション
ここからは、パラレル・テーブル・ファンクションについて説明します。
やはり、パフォーマンス向上のためにはパラレル化する必要がありますので、テーブル・ファンクションを使用するときはこれが一般的になると思います。パラレル化するためには、以下のようなPARALLEL_ENABLE句を使用しますが、ここには入力データをスレーブ・プロセス間で分割する方法も指定します。このときの入力パラメータには、カーソル変数を指定する必要があります(このためにも基本はカーソル変数を使用するようにしましょう)。そのカーソル変数に対してPARTITION BY句でANY、HASH、RANGEを指定することができます(ただし、事前定義カーソル型”SYS_REFCURSOR”では”HASH”と”RANGE”を指定できませんので、使用するにはREFカーソル型を作成する必要があります)。また、データの順番を制御するCLUSTER BY句やORDER BY句を指定することもできます(同じデータだけが連続する必要がある場合はCLUSTER BY句を、すべてのデータが順番になっている必要がある場合はORDER BY句を使用します)。
PARALLEL_ENABLE(PARTITION p1 BY [ANY | [HASH | RANGE] (<列リスト>)])
{[ORDER | CLUSTER] p1 BY (<列リスト>)}
IS
BEGIN …. END func01;
/
(1)パラレル・パイプライン表関数
パラレル化は、非パイプライン表関数でも行うことが可能ですが、第20回で説明したようにパラレル実行は2つの処理を同時に実行できるので、パイプライン表関数を使用した方が、テーブル・ファンクション処理と次の処理を同時に行うことができるようになり効果的に行えます。これについてテーブル・ファンクションとテーブルを結合する例を使用して説明しましょう。
以下のテーブル・ファンクションは、事前定義カーソル型”SYS_REFCURSOR”の変数”p1”を使用して、パラレルの分割方法を”ANY”に指定しています(”ANY”を指定するとスレーブ・プロセス間でランダムに分割が行われます)。これとテーブル”tab01”を結合するとどうなるか見ていきましょう。
RETURN tab02_tbl_type PIPELINED PARALLEL_ENABLE(PARTITION p1 BY ANY) IS
in_rec tab02%ROWTYPE;
BEGIN …. END func01;
/
このテーブル・ファンクションを実行すると実行計画は以下のようになります(テーブル・ファンクション処理はCOLLECTION ITERATOR PICKLER FETCHと出力されます)。この実行計画(赤い点線の部分)からテーブル・スキャンとテーブル・ファンクションが同一スレーブ・プロセスで行われていることが分かります(不明な方は第20回のパラレル実行を参照して下さい)。つまり、パイプライン表関数では、テーブル・ファンクション処理と結合を同時に行うことができます(非パイプライン表関数は、テーブル・ファンクションが終了してからデータを返しますので、実行計画は同じですが結合と同時に行うことはできません)。
実行計画

(2)パラレルの分割方法について
パラレル処理で大事なパラレルの分割方法についてもう少し説明しましょう。
パラレル処理を効果的に動作させるには、データ分割を正しく指定する必要があります。これを自動的に設定できれば良いのですが、ファンクション処理のプログラミングによって分割方法が決まる場合もあるため、自動的に設定することはできません。例えば、ある列の値が同じものは同一プロセスで処理する必要がある場合などは、データ分割をランダムで行う”ANY”にすることはできません(同一レコード内のデータだけを使用するファンクション処理であれば、分割方法を”ANY”にしても問題ありません)。そのため、テーブル・ファンクションを作成するときに、意識する必要があることを覚えておいて下さい(このようなことが後からパラレル化するときの問題になる訳です)。また、指定方法によっては、以下のようなオーバーヘッドが発生することも覚えておきましょう。
・ PARTITION BY句にHASHまたはRANGEを指定すると、スキャン処理とテーブル・ファンクション処理が別スレーブ・プロセスで行う。
・ CLUSTER BY句またはORDER BY句を指定すると、テーブル・ファンクション処理前にソート処理を行う。
これについてもテーブル・ファンクションの例と実行計画を使用して説明しましょう。
以下の例では、HASH分割するためにユーザー定義REFカーソル型”refcur”と戻り値用のレコード型”outrec_type”を作成しています。この2つはスキーマ・レベルでは作成できないので、PL/SQLパッケージ”test_pkg”を作成しています。戻り値にはレコード型変数”out_rec”を使用しているので、代入にはコンストラクタ・メソッドは使用していません。
TYPE outrec_type IS RECORD (c1 number,c2 number);
TYPE tab02_tbl_type IS TABLE OF outrec_type;
TYPE refcur IS REF CURSOR RETURN tab02%ROWTYPE;
FUNCTION func02(p1 refcur) RETURN tab02_tbl_type PIPELINED PARALLEL_ENABLE(PARTITION p1 by HASH (c2));
END test_pkg;
/
CREATE OR REPLACE PACKAGE BODY test_pkg AS
FUNCTION func02(p1 refcur) RETURN tab02_tbl_type PIPELINED PARALLEL_ENABLE(PARTITION p1 by HASH (c2)) IS
out_rec outrec_type; — 戻り値用レコード型変数
in_rec p1%ROWTYPE; — カーソルp1用レコード型変数
BEGIN
loop
FETCH p1 INTO in_rec;
EXIT WHEN p1%NOTFOUND;
IF in_rec.c1 IS NOT NULL OR in_rec.c2 IS NOT NULL THEN
out_rec.c1 := in_rec.c1;
out_rec.c2 := in_rec.c2;
PIPE ROW(out_rec);
END IF;
end loop;
RETURN;
END func02;
END test_pkg;
/
このテーブル・ファンクションを「(1)パラレル・パイプライン表関数」と同じように実行すると実行計画は以下のようになります。この実行計画(赤い点線の部分)から分割方法をHASHにしていることで、テーブル・ファンクションへ渡すデータを分割するために、テーブル・スキャンとテーブル・ファンクションは別スレーブ・プロセスで動作していることが分かります(①で全表スキャン”TABLE ACCESS FULL”後にHASH分割”PX SEND HASH”をしています)。そのため、パイプライン表関数を使用しても結合などを同時に行うことができなくなります(つまり、処理時間が長くなってしまいます)。
実行計画

更に、以下のようにCLUSTER BY句を指定してみましょう。
FUNCTION func02(p1 refcur) RETURN tab02_tbl_type PIPELINED
PARALLEL_ENABLE(PARTITION p1 by HASH (c2)) CLUSTER p1 BY (c2) IS
out_rec outrec_type;
in_rec tab02%ROWTYPE;
BEGIN …. END func02;
END test_pkg;
/
これも同じように実行すると実行計画は以下のようになります。この実行計画(赤い点線の部分)からCLUSTER BY句を使用していることで、データを指定列の順番に制御するためにソート処理を行っているのが分かります(テーブル・ファンクション”COLLECTION ITERATOR PICKLER FETCH”の前にソート処理”SORT ORDER BY”を行っています)。これは、それぞれのスレーブ・プロセス内でソート処理を行うため、PARTITION BY句の指定によって結果が異なりますので注意して下さい。ORDER BY句を指定して全体をソートする必要がある場合には、RANGEを使用しないと意味がありません(HASHは同じ値は同一プロセスに分割しますが、それ以外のデータについてはパラレル度などで異なるからです)。また、CLUSTER BY句を指定した場合には、同じ値のすべてが同じスレーブ・プロセスになれば良いだけなので、HASHとRANGEのどちらでも問題ないですが、スレープ・プロセス間の偏りが少ないHASHを使用する方が効果的になります。更に処理時間が長くなってしまいますので、このような指定を行わなくても良いファンクションを作成するようにして下さい。
実行計画

3. おわりに
今回は第24回に続きSQL文のノウハウについて説明しました。また機会があれば他のことについても説明したいと思います。2月と3月はOracle Technology Day 2013で大阪、名古屋、福岡、仙台に行かせていただきました。博士として初めての東京以外での講演になりますが、聞いてくれた方はありがとうございました。そのため、少し時間が空いてしまいましたが、これからも頑張りますのでよろしくお願いします。それでは、次回まで、ごきげんよう。
