皆さんこんにちは、今年は天候の変化が激しい(豪雨だったり、猛暑だったり、そして雹が降ったりと)変な梅雨ですね。もう少し梅雨が続きそうですが、災害や体調に気を付けて頑張りましょう。
これまでSQLの実行計画を最適にすることをいろいろ説明してきましたが、パフォーマンス問題が発生した場合に、どのようにチューニングするかはまだ説明していませんでした。そこで今回は、SQLチューニングの手順やツールの使い方などについて説明しますので、参考にしてください。
1. SQLチューニングとは
それでは、SQLチューニングとはから説明しましょう。
SQLチューニングとは、性能の悪いSQLを見つけて改善することですが、基本は非効率な実行計画のものになります(多重実行による競合などはSQLだけでは改善できないからです)。特に、複雑なSQL(多くの条件またはテーブルにアクセスするSQL)などはアクセス・パスが多くなり、オプティマイザ統計の影響などで実行計画の問題になりやすくなります。また、最適な索引を作成するのも難しくなります。第32回では問題のSQLを特定するまでの内容でしたので、続きとして問題のSQLをどのようにチューニングするかについて説明します。
SQL(実行計画)のチューニングは、以下のような検討を行いますが、基本は最初の三つを上から順番に行っていきます。
- オプティマイザ統計の再収集(オプティマイザ統計が正しくない)
- 索引の作成(効果的な索引が作成されていない)
- SQLの変更/ヒントの挿入(複雑なSQLなどで効果的な実行計画にならない)
- SQL計画ベースラインの設定(ヒントで効果的にできるがSQLを変更できない)
- SQLチューニング・アドバイザ(どのようにチューニングするか判断できない)
(1)オプティマイザ統計の再収集
まずは、オプティマイザ統計から確認します。
オプティマイザ統計については、何度か説明したように正確とは限らないので、最適な実行計画にならない場合があります。特に、対象になるオブジェクトのオプティマイザ統計が失効(行の10%以上が変更された)や欠落になっている場合、これが原因になる可能性が高くなります。そのため、第27回の「CBOのコストについて」のように、問題のSQLの見積もり行数と実際の処理行数を比較して、大きく異なる場合は対象のオブジェクトのオプティマイザ統計を再収集することを検討してください。カーディナリティ・フィードバック(統計フィードバック)や動的サンプリング(動的統計)などでも補正しますが、これは限定的な効果ということを忘れないでください。また、第27回で説明したように、パラメータoptionsに”GATHER AUTO”を指定して統計の収集をすると、そのようなオブジェクトをすべて収集することができます。
(2)索引の作成
次に、効果的な索引が作成されているか確認します。
索引についても何度か説明したように、検索条件列の組合せごとに作成するのが最も効果的ですが、索引の数が多くなり更新時のオーバーヘッドが大きくなってしまうので、最低限の索引で効果的に動作するようにします。ただし、データの内容が異なってくると効果的なアクセスができない場合があるので、問題のSQLに最適な索引が存在するか(索引の作成によって改善できるか)を、実行計画のアクセス・パスなどを見ながら分析します。このとき最も効果的な索引(WHERE句に指定されている列すべての索引または高速全索引スキャンする索引)から検討します。この索引で改善しない(または既に作成されている)のであれば、新たな索引を作成しても意味がないということです。索引を作成する列や順番については、第21回を参考に決定してください。ただし、あまり作り過ぎないように注意することも必要なので、効果がなくなった索引は削除するようにしてください(第6回の「未使用索引の削除」のように調べることができます)。索引以外に、アクセスするデータを削減させるために、第22回を参考にパーティション構造やマテリアライズド・ビューなどを検討するのも良い方法です。
(3)SQLの変更/ヒントの挿入
統計や索引でも改善しない場合には、ヒント文またはSQLの変更を検討します。
オプティマイザ(CBO)は、基本は最適な実行計画を作成しますが、複雑なSQLになると効果的な実行計画にするのが難しくなります。そのような場合には、効果的になるようにヒント文を入れるやSQLを変更するのも必要になります。例えば、あまりにも複雑なSQLになっている場合には、中間テーブルを作成してSQLを分割するのも良い方法です。これは、「良いSQLについて」などで説明したことを参考に、アクセス効率を最適にするように行ってください。アクセス方法(索引スキャン、全表スキャン)、結合順序、結合方法(ネステッドループ結合、ハッシュ結合)などの単純な変更であれば、ヒント文を使用するので問題ありません。
(4)SQL計画ベースラインの設定
ヒント文で解決できることは分かったが、SQLを変更できないような場合などに行います。
SPMは、実行計画履歴の中からSQL計画ベースラインだけを使用することができるので、それをSQLチューニングにも使用します。以下のように問題のSQLに対して、ヒント文でチューニングした実行計画をSQL計画ベースラインとすることで、その実行計画だけを実行するようにします。
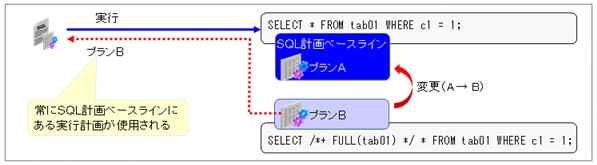
特に、パッケージ・アプリケーションやOracle Real Application Testing(RAT)などのテストツールでは、SQLを変更することができないので、パフォーマンス問題に対するSQLチューニングに限界があります。そのような場合に、このSQL計画ベースラインを使用することで、簡単にSQLチューニングすることが可能です(これを知らないため、チューニングを諦めている方も多いように思います)。ただし、実行計画がベースラインで固定化されるので、最適なのかを定期的にチェックする必要はあります。
(5)SQLチューニング・アドバイザ
問題のSQLをどのようにチューニングするか判断できない場合などに行います。
第32回を参考に問題のSQLを特定したが、チューニング方法が不明な方はSQLチューニング・アドバイザを使用して、Oracleデータベースに任せます。問題のSQLを特定するのも難しい方は、ADDM(自動データベース診断モニター)を使用すると良いです(ADDMの説明は別の機会とします)。
SQLチューニング・アドバイザは、遅いSQLの実行計画を最適にするために、以下のような分析を行いアドバイス(推奨事項とパフォーマンス向上率など)を出力します。これにはTuning Packオプションが必要になりますが、あまりSQLチューニングに慣れていない方やSQLの数が多くてチューニングが大変な方などには良いツールだと思います。
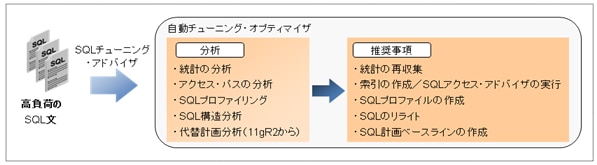
オプティマイザ統計やアクセス・パスの分析以外に、実行計画を改善するために以下のような分析も行います。
- SQL構造分析
SQLのパフォーマンスが低下する要因(UNIONやNOT INを効率良いUNION ALLやNOT EXISTSに、比較するデータ型が一致しない、結合条件がないなど)をSQLのリライトとしてアドバイスします。 - SQLプロファイリング
見積りが正しくないときにSQLプロファイルの作成をアドバイスします(SQLプロファイルについては後で説明します)。 - 代替計画分析(Oracle Database 11gR2から)
パフォーマンスが優れている既存の実行計画(カーソル・キャッシュまたはAWR)を検索して、存在する場合にSQL計画ベースラインの作成をアドバイスします。
Oracle Database 11gからは、毎日自動的に実行される自動SQLチューニング・アドバイザが追加されています(これについても後から説明します)。
2. SQL計画ベースラインについて
SQL計画ベースライン(ベースライン)についてもう少し説明しましょう。
SPM(SQL Plan Management)は、第5回で説明したように実行計画の履歴を管理して、承認済みの実行計画を使用することで、最適な実行計画にする機能になります。このときの承認済みの実行計画がSQL計画ベースラインです。
SQL計画ベースラインは、2回以上実行するSQLの実行計画を自動的に取得することも、一連の実行計画を手動でロードすることも可能です。そのため、いろいろな使い方ができるようになっています。
(1)自動取得
初期化パラメータoptimizer_capture_sql_plan_baselinesを’TRUE’にすることで、SQLが2回以上実行されると自動的に実行計画を履歴管理します(デフォルトは’FALSE’です)。このとき最初に生成された実行計画だけがSQL計画ベースラインとして承認されます(これは、第35回で説明したように、Oracle Database 12cからのSPM展開アドバイザを使用することで、それ以外も自動的に承認できるようになります)。
また、SQL計画ベースラインを使用するには、初期化パラメータoptimizer_use_sql_plan_baselinesを’TRUE’にします(デフォルトは’TRUE’です)。これでハードパースするときに、SQL計画ベースラインの中で最もコストが低い実行計画を使用します。このときハードパースした実行計画は、SQL計画ベースラインに存在しないと実行計画履歴に追加します(一つもベースラインが存在しない場合には追加しません)。これは、初期化パラメータoptimizer_capture_sql_plan_baselinesとは関係なく(’FALSE’でも)行います。
(2)手動ロード
もう一つの方法は、既存の実行計画をSQL計画ベースラインとして手動でロードする方法です。
以下のようにカーソル・キャッシュまたはSQLチューニング・セット(STS)から実行計画を手動でロードすることができます。このときの実行計画は、常にSQL計画ベースライン(承認済み)になります。
- カーソル・キャッシュからロード(DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE)
SQLチューニングなどで直近に実行された実行計画をベースラインとして登録するような場合に使用します。 - SQLチューニング・セット(STS)からロード(DBMS_SPM.LOAD_PLANS_FROM_SQLSET)
AWR(過去の実行計画)からロードする場合にこれを使用します(AWRに保存された実行計画をSTSにロードする必要があります)。
(3)サンプルプログラム
参考までに、SQL計画ベースラインを設定するサンプルプログラムを載せます。
以下のサンプルプログラムは、SQL*Plusの事前定義変数’sql1’と’sql2’に指定されているSQL文によって、SQL計画ベースラインを設定するPL/SQLプロシージャー’set_baseline.sql’です(事前定義変数’sql1’のSQL文のベースラインに、事前定義変数’sql2’のSQL文の実行計画を設定します)。
SET SERVEROUTPUT ON;
SET VERIFY OFF;
SET FEEDBACK OFF;
DEFINE sql1 = 'SELECT * FROM tab01%';
DEFINE sql2 = 'SELECT /*+ FULL(tab01) */ * FROM tab01%';
VARIABLE cnt1 NUMBER;
VARIABLE cnt2 NUMBER;
-- ...<v$sqlとdba_sql_plan_baselinesのチェックは省略>...
BEGIN :cnt1 := 1; :cnt2 := 0; END;
/
DECLARE
w_sql_id VARCHAR2(13);
w_hash_value NUMBER;
w_handle VARCHAR2(128);
w_pname VARCHAR2(128);
wcnt PLS_INTEGER;
BEGIN
IF :cnt1 != 1 OR -- v$sql(カーソル・キャッシュ)に対象SQLレコードが存在しない又は複数行存在する。
:cnt2 > 0 THEN -- 対象SQLのベースラインが既に存在している。
RETURN;
END IF;
-- オリジナルの実行計画をカーソル・キャッシュからベースラインにロード
SELECT sql_id, plan_hash_value INTO w_sql_id, w_hash_value FROM v$sql WHERE sql_text LIKE '&&sql1';
wcnt := DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE(sql_id => w_sql_id, plan_hash_value => w_hash_value);
SELECT sql_handle, plan_name INTO w_handle, w_pname FROM dba_sql_plan_baselines WHERE sql_text LIKE '&&sql1';
-- ヒントありの実行計画をカーソル・キャッシュからSQL_HANDLE(オリジナルのSQL)のベースラインにロード
SELECT sql_id, plan_hash_value INTO w_sql_id, w_hash_value FROM v$sql WHERE sql_text LIKE '&&sql2';
wcnt := DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE
(sql_id => w_sql_id, plan_hash_value => w_hash_value, sql_handle => w_handle);
-- オリジナルのベースラインを削除
wcnt := DBMS_SPM.DROP_SQL_PLAN_BASELINE(w_handle, w_pname);
-- 作成したベースライン(SQL_HANDLE PLAN_NAME)を出力
SELECT sql_handle, plan_name INTO w_handle, w_pname FROM dba_sql_plan_baselines WHERE sql_text LIKE '&&sql1';
DBMS_OUTPUT.PUT_LINE('ベースライン(SQL_HANDLE='''||w_handle||''' PLAN_NAME='''||w_pname||''')を作成しました。');
END;
/
UNDEFINE sql1 sql2;
SET FEEDBACK ON;
SET VERIFY ON;
SET SERVEROUTPUT OFF;
ここでは、以下の左側の索引スキャンが最適なSQLに対して、右側の全表スキャンを実行するように設定します。
SQL> SELECT * FROM tab01 WHERE c1 = 1; 実行計画 ------------------------------------------------- | Id | Operation | Name | ------------------------------------------------- | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS BY INDEX ROWID| TAB01 | |* 2 | INDEX RANGE SCAN | TAB01_IX1 | |
SQL> SELECT /*+ FULL(tab01) */ * FROM tab01 2 WHERE c1 = 1; 実行計画 ---------------------------------------- | Id | Operation | Name | ---------------------------------------- | 0 | SELECT STATEMENT | | |* 1 | TABLE ACCESS FULL | TAB01 | |
このサンプルプログラム’set_baseline.sql’を実行することで、以下のように全表スキャンを行うようになります(SQL計画ベースラインが使用されると、Note部にそのプラン名が’SQL plan baseline ” <plan_name>” used for this statement’と出力されます)。
SQL> @set_baseline ... ベースライン(SQL_HANDLE='SQL_d41f29e56978e606' PLAN_NAME='SQL_PLAN_d87t9wpnrjth633f47f0e')を作成しました。 SQL> ALTER SESSION SET optimizer_use_sql_plan_baselines=TRUE; SQL> SELECT * FROM tab01 WHERE c1 = 1; 実行計画 ---------------------------------------- | Id | Operation | Name | ---------------------------------------- | 0 | SELECT STATEMENT | | |* 1 | TABLE ACCESS FULL | TAB01 | ... Note ----- - SQL plan baseline "SQL_PLAN_d87t9wpnrjth633f47f0e" used for this statement
3. SQLチューニング・アドバイザについて
最後に、機能名だけは何度か出てきていたSQLチューニング・アドバイザについて説明しましょう。
SQLチューニング・アドバイザは、1つ以上のSQLに対して自動チューニング・オプティマイザを起動してSQLチューニングを行います(オプティマイザには、実行計画を作成する標準モードと標準モードで作成された実行計画をさらに改善できるか分析するチューニング・モードがあり、このチューニング・モードを自動チューニング・オプティマイザと呼びます)。この結果レポートには、実行計画を最適化するように提案された推奨事項ごとに、その実装に必要なSQLコマンド、理論的根拠およびメリット(推定パフォーマンス向上率など)が含まれます。SQLチューニング・アドバイザを実行するときには、問題のSQLを以下のように指定することが可能です。
- カーソル・キャッシュ(v$sqlのsql_id)
- AWR(開始と終了のスナップショット識別子とその中のsql_id)
- SQLテキスト(SQLテキストを直接指定)
- SQLチューニング・セット(複数のSQLを行うときにSQLチューニング・セット名を指定)
(1) SQLチューニング・アドバイザの実行
基本はOracle Enterprise Managerを使用しますが、ここではDBMS_SQLTUNEパッケージでの実行について説明します。
SQLチューニング・アドバイザの実行は、以下のようにSQLチューニング・アドバイザ・タスクの作成と実行が必要になります。この例は、SQLテキストを直接指定しているタスク’test_sql_tuning_task’を作成しています(索引スキャンが最適なSQLに対して、ヒント文で全表スキャンするようにしたSQLを使用してアドバイザを行います)。
DECLARE
w_task_name VARCHAR2(30);
w_sqltext CLOB;
BEGIN
w_sqltext := 'SELECT /*+ FULL(tab01) */ * FROM tab01 WHERE c1 = 1';
w_task_name := DBMS_SQLTUNE.CREATE_TUNING_TASK(sql_text => w_sqltext, scope => 'comprehensive',
time_limit => 60, task_name =>'test_sql_tuning_task',
description => 'Test SQL Tuning Task');
DBMS_SQLTUNE.EXECUTE_TUNING_TASK(task_name => w_task_name);
END;
/
実行後に、以下のようにSQLチューニング・アドバイザ・タスクのレポートを出力します。この例ではSQLプロファイルが推奨されているので、推奨されたSQLコマンドを実行することでSQLプロファイルが作成されます(ただし、リテラル値をバインド変数に変換する場合は、パラメータforce_matchを’TRUE’にする必要があります)。

(2)SQLプロファイル
SQLプロファイルは、より適切な実行計画が生成できるSQLの補助統計情報として、SQL チューニング・アドバイザによって作成されます。SQL計画ベースラインと同じように、内部的にヒント文を使用しているので、SQLを変更せずにチューニングすることができます。ただし、SQL計画ベースラインは特定の実行計画を再現するのに対して、SQLプロファイルは以下のようにオプティマイザのコスト計算(カーディナリティなどの見積り)を調整することで実現します(例えば、テーブル統計値を指定するTABLE_STATSヒントやCOLUMN_STATSヒントなどです)。そのため、実行計画の固定化とは少し異なり、オプティマイザ統計が変われば実行計画も変化する場合があります。
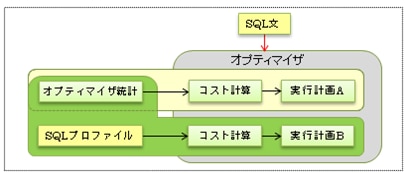
SQLチューニング・アドバイザを実行すると、データのサンプリングやSQLの一部の実行などを行って、コスト、選択性、カーディナリティを検証します。このとき差異が大きい場合に、SQLプロファイルの作成をアドバイスします。ただし、SQLプロファイルを作成するには、DBMS_SQLTUNE.CREATE_TUNING_TASKファンクションのパラメータscope を’comprehensive’(包括モード)にする必要があります。包括モードでは、単一のSQLのチューニングに数分掛るので、使用するときには注意が必要です。そのため、パラメータTIME_LIMITを使用して、時間制限(タスクが実行できる時間)を指定することができます(デフォルトは30分です)。
実行時に使用するSQLプロファイルは、初期化パラメータSQLTUNE_CATEGORYで指定するので、以下のようにセッションごとに使用するSQLプロファイルを設定することも可能です(デフォルトのカテゴリ名は’DEFAULT’ですが、この例では’TEST’にしています)。SQLプロファイルが使用されると、Note部にそのSQLプロファイル名が’SQL profile “<SQLプロファイル名>”used for this statement’と出力されます。
SQL> SELECT a.name, a.category, a.task_exec_name, a.type, a.status
2 FROM dba_sql_profiles a, dba_advisor_log b
3 WHERE a.task_id = b.task_id AND b.task_name = 'test_sql_tuning_task';
NAME CATEGORY TASK_EXEC_NAME TYPE STATUS
------------------------------ ---------- ------------------ ------- --------
SYS_SQLPROF_0146f4d0f6f20000 DEFAULT EXEC_783 MANUAL ENABLED
SQL> EXEC DBMS_SQLTUNE.ALTER_SQL_PROFILE(name => 'SYS_SQLPROF_0146f4d0f6f20000',
2 attribute_name => 'CATEGORY', value => 'TEST');
SQL> ALTER SESSION SET sqltune_category='TEST';
SQL> SELECT /*+ FULL(tab01) */ * FROM tab01 WHERE c1 = 1;
実行計画
-------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| TAB01 |
|* 2 | INDEX RANGE SCAN | TAB01_IX1 |
...
Note
-----
- SQL profile "SYS_SQLPROF_0146f4d0f6f20000" used for this statement
SQLプロファイルを手動で作成することもできますが、SQLチューニング・アドバイザを使用する場合には必要ないと思うので、ここでは説明を省略します。
(3)自動SQLチューニング・アドバイザ
Oracle Database 11gから自動SQLチューニング・アドバイザが提供されています。これは、第5回の「自動オプティマイザ統計収集」と同じように、自動メンテナンス・タスクとして構成されます(デフォルトでは、1時間を限度に動作します)。
自動SQLチューニング・アドバイザは、AWRを分析してチューニング候補のSQLリストを作成します。候補のSQLは、パフォーマンスの影響(CPU時間とI/O時間から計算)に基づいて順序付けを行い、それぞれにSQLチューニング・アドバイザを実行します(時間制限によっては後のSQLは実行されなくなります)。これは、改善の可能性が高い実行計画を持つSQLだけが候補になります(再帰的SQL、パラレル問合せ、DML、DDL、同時実行の問題によって遅いSQL、1ヶ月以内にチューニングされたSQLなどは対象外です)。
このとき、自動的に実装するのは、SQLプロファイルだけになります。SQLプロファイルが推奨されると、パフォーマンス向上基準(3倍以上の改善)を満たしている場合に、そのSQLプロファイルを実装します(ただし、以下のようにタスク・パラメータACCEPT_SQL_PROFILESが’TRUE’に設定されている場合だけです)。それ以外はSQLプロファイルのアドバイスが、自動SQLチューニング・レポートに出力されるだけです。
SQL> EXEC DBMS_SQLTUNE.SET_TUNING_TASK_PARAMETER(task_name => 'SYS_AUTO_SQL_TUNING_TASK', 2 parameter => 'ACCEPT_SQL_PROFILES', value => 'TRUE');
自動SQLチューニング・アドバイザで自動作成されたSQLプロファイルは、以下のようにTYPEが’AUTO’になります。
SQL> SELECT name, task_exec_name, type, status FROM dba_sql_profiles; NAME TASK_EXEC_NAME TYPE STATUS ------------------------------ ------------------------------ ------- -------- SYS_SQLPROF_0128236ba63f0000 EXEC_2746 AUTO ENABLED
以下のように自動SQLチューニング・アドバイザを手動で実行することも可能です(ただし、SYSユーザだけです)。
SQL> EXEC DBMS_AUTO_SQLTUNE.EXECUTE_AUTO_TUNING_TASK();
多くのSQLを手動でチューニングするのは大変な作業になるので、このようなツールを上手く利用することで効果的に行うことが可能になります。苦労されている方は使用するのを検討してみてください(ただし、限界もあることは忘れないでください)。
4. おわりに
今回はSQLチューニングについて説明しましたが、少しは参考になりましたでしょうか。また機会があれば他のことについても説明したいと思います。これからもよろしくお願いします。それでは、次回まで、ごきげんよう。
