皆さんこんにちは、寒い日が続きますが、そろそろ暖かくなって欲しいですね。インフルエンザが流行っているので気を付けてください。
今回は、Oracle Database In-Memory(DBIM)の続きとして、Oracle Real Application Clusters(RAC)環境について説明しようと思います。RAC環境では、複数のインスタンスをどのように効果的に使用するかが重要になります。そのため今回は、耐障害性やチューニングなども含めて説明していますので、参考にしてください。
1. RAC環境のDBIM
まずは、RAC環境でのDBIMの特徴と注意点について説明します(RACの概要については第2回を参照してください)。
RAC環境では、すべてのインスタンスを効果的に使用するために、以下のようにそれぞれのインスタンスにデータを分散して、インメモリ列ストア(IM列ストア)領域に格納するので、どのように分散するかを意識して使用する必要があります(以下の図は、パーティション単位で分散している場合です)。
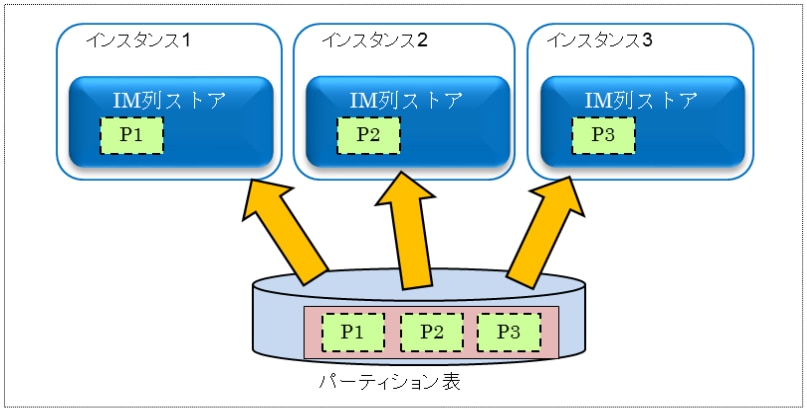
このときインメモリ領域(INMEMORY_SIZE初期化パラメータ)は、それぞれのインスタンスで指定できますが、すべてのインスタンスで同じ値にするのが推奨になります。INMEMORY_SIZEを0に設定することで、IM列ストアを使用しないインスタンスを作成することもできます。データの分散方法は、以下のようにINMEMORY属性のRACオプションDISTRIBUTE句とDUPLICATE句で指定します。
ALTER TABLE <表名> INMMEMORY … [<DISTRIBUTE句>] [<DUPLICATE句>]
(1)DISTRIBUTE句
RAC環境では、各インスタンスでデータ量を均等に分散することが効果的な使用になります。その分散方法を指定するのがこれになり、以下のように指定することが可能です。デフォルトは”DISTRIBUTE AUTO”になります。
- DISTRIBUTE AUTO(自動的に3つの中の最適な分散方法が選択される)
- DISTRIBUTE BY ROWID RANGE(ROWIDの範囲ごとにデータが分散される)
- DISTRIBUTE BY PARTITION(パーティション単位でデータが分散される)
- DISTRIBUTE BY SUBPARTITION(サブ・パーティション単位でデータが分散される)
この分散は、データ構造と起動インスタンス数で決まるため、ポピュレートするインスタンスをユーザーが指定することはできません。基本は、AUTOで問題ありませんが、偏るような場合は手動で行うようにしてください。各インスタンスのIM列ストアのサイズの確認方法は以下になります。SEGMENT_TYPEがTABLE、TABLE_PARTITION、TABLE_SUBPARTITIONになるので、これでどのように分割されているか分かります。
SQL> SELECT inst_id, segment_name name, partition_name, segment_type, populate_status status,
2 inmemory_size/1024/1024 im_mb, bytes_not_populated
3 FROM gv$im_segments ORDER BY 1, 2, 3;
INST_ID NAME PARTITION_NAME SEGMENT_TYPE STATUS IM_MB BYTES_NOT_POPULATED
---------- ------------- ------------------ --------------- --------- ------------- -------------------
1 <表名> <パーティション名> TABLE_PARTITION COMPLETED <IM内サイズ> <未完了のバイト数>
インスタンスがダウンした場合は、インスタンス数が安定したとき(インスタンス数が一定時間変わらないとき)に、新たなインスタンス数で分散方法が再計算されます。その後のポピュレート(または再ポピュレート)時に、新たに決定した分散方法で実行されます。このときの再配置では、差分だけがポピュレートされるので、最小限のポピュレートで復旧できます(パーティション分割では、なくなったパーティションだけをポピュレートします)。
(2)DUPLICATE句
DUPLICATE句は、分散されたデータのコピーの持ち方を指定するもので、以下のように指定することが可能です。デフォルトは”NO DUPLICATE”になります。これはOracle Engineered System(Exadata、SuperCluster、ODAなど)だけが有効で、Engineered System以外では無視されます(常に”NO DUPLICATE”になります)。
- NO DUPLICATE(1インスタンスのIM列ストアにのみデータを保持)
- DUPLICATE(2インスタンスのIM列ストアにデータを保持)
- DUPLICATE ALL(全インスタンスのIM列ストアにデータを保持)
これは耐障害性(インスタンス障害時のデータ保持)を向上するために指定しますが、シリアル実行などの1インスタンスだけにアクセスする場合にも影響します。このときローカル・インスタンスのIM列ストアだけにアクセスして、残りは行型データにアクセスするので、”DUPLICATE ALL”でないとすべてをIM列ストアからスキャンできません。ただし、”DUPLICATE ALL”にすると、各インスタンスのIM列ストアに保持するデータ量が増えるので、更新時のオーバーヘッドが増えてしまいます。そのため、シリアル実行する場合には、1インスタンスだけのIM列ストアに格納するのも選択の一つと言えます。このように、何を重視するかを意識して決める必要があります。
(3)RAC環境での自動並列度
自動並列度(自動DOP)は、第40回で説明したように、SQLによって自動的に並列度を調整しますが、RAC環境のDBIMでは効果的にパラレル実行することも可能になります。
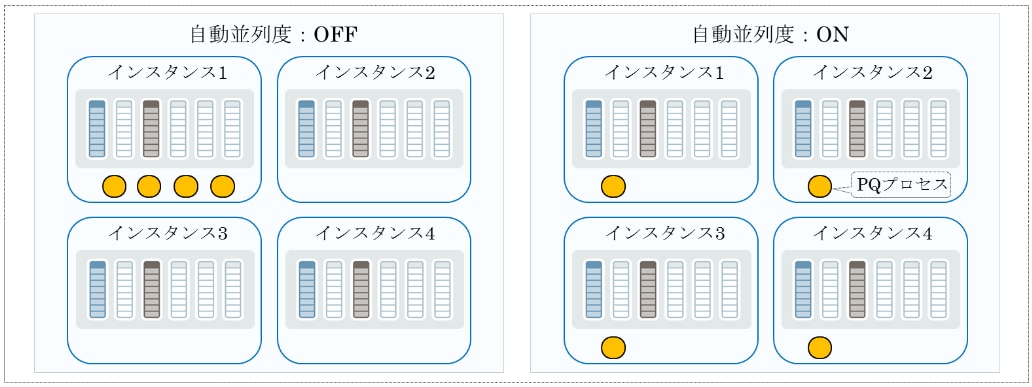
パラレル実行したときに、どのインスタンスでPQプロセス(パラレル・スレーブ・プロセス)を起動するか制御できません。通常は、パラレル度が少ないと効果的に動作するために、1インスタンス内で動作するようになります(以下の図の左側です)。ただし、DBIMでは、各インスタンスにデータが分散されているので、効果的に動作することができません。そのため、自動並列度(PARALLEL_DEGREE_POLICY初期化パラメータをAUTOなどに設定)を使用してパラレル実行すると、各インスタンスでPQプロセスが動作するように調整します(以下の図の右側です)。このときIM列ストアが存在するインスタンスを認識して調整します。つまり、”DUPLICATE ALL”にしなくても効果的にパラレル実行することが可能です。
これが動作しているかは、実行計画のNote部で確認できます(以下のように”parallel scans affinitized for inmemory”と出力されます)。パラレル度がインスタンス数以上になっていないと動作しないので注意してください(その場合には手動でパラレル度を設定してください)。
—–
– automatic DOP: Computed Degree of Parallelism is 4
– parallel scans affinitized for inmemory
(4)RAC環境でのSGAサイズ
インメモリ領域は、SGA(System Global Area)内に静的な領域として確保されます。これは自動調整されないので、領域不足にならないようにOracle Compression Advisor(DBMS_COMPRESSIONパッケージ)などを使用してサイズを決めます。RAC環境では、これ以外に共有プールの追加も必要になります。これはIM列ストアに対するRAC関連のロック情報で、ポピュレート時に不足するとORA-4031エラー(共有プールの割当てができない)が発生するので、十分なサイズを指定してください(RAC環境のSGAサイズは、”SGAサイズ×1.1″が推奨となります)。
2. DBIMのチューニング
次に、DBIMのチューニングについて説明します。
DBIMのチューニング項目はそんなにありませんが、問合せ性能に問題があるときに、以下の確認を行います。
- 物理I/O
- ポピュレートのオーバーヘッド
(1)物理I/O
DBIMは、効果的に動作しているときには物理I/Oは発生しないので、まずは物理I/Oの確認を行ってください。実行計画の”TABLE ACCESS INMEMORY FULL”で”physical reads”が発生していないかを確認します(以下のようにSQL*PlusのAUTOTRACEコマンドで統計を出力すると簡単に確認できます)。
———————————————
| Id | Operation | Name |
———————————————
| 0 | SELECT STATEMENT | |
| 1 | SORT AGGREGATE | |
| *2 | TABLE ACCESS INMEMORY FULL| SALES |
…
統計
———————————————————-
1 recursive calls
0 db block gets
474 consistent gets
0 physical reads
…
物理I/Oが発生している場合は、以下の項目をチェックして発生しないようにしてください。
- ポピュレートが完了していない(ポピュレート実行中、インメモリ領域不足)
ポピュレートされていないデータは行型データにアクセスするので、以下のSQLでPOPULATE_STATUSを確認してください(”OUT OF MEMORY”:領域不足、POPULATING:実行中)。オブジェクトごとは「(1)DISTRIBURE句」で説明したSQLで確認します(POPULATE_STATUSがCOMPLETED以外では完了していません)。
POOL ALLOC_BYTES USED_BYTES POPULATE_STATUS
—————- ———– ———- —————-
1MB POOL <割当領域> <使用領域> OUT OF MEMORY <-IMCUプール(列書式のデータ)
64KB POOL <割当領域> <使用領域> DONE <-SMUプール(メタデータなど)
- Temp領域を使用している(PGA領域不足)
DBIMでもハッシュ結合や集計処理などでPGA領域を使用するので、小さいとTEMP領域へのI/Oが発生します(第14回のメモリ・チューニングを参考にSGAとPGAを調整してください)。 - RAC環境で”DUPLICATE ALL”でない(インターノード・パラレル実行でない)
「(2)DUPLICATE句」と「(3)RAC環境での自動並列度」を参考に調整してください。
(2)ポピュレートのオーバーヘッド
ポピュレートは、圧縮のためにCPUリソースを使用するので、オーバーヘッドが大きいと問合せ性能にも影響します。このオーバーヘッドは、AWRの”Active Session History (ASH) Report”を確認します(以下のCPU待機クラスのIM関連イベントから割合を確認できます)。
- CPU:IM Populate(優先順位レベルNONEのセグメントのオン・デマンド・ポピュレーション)
- CPU:IM Prepopulate(優先順位レベルNONE以外のセグメントのポピュレーション)
- CPU:IM Repopulate(再ポピュレーション)
- CPU:IM QUERY(IM問合せ)
オーバーヘッドが大きいときには、圧縮タイプやワーカー・プロセス数の調整、優先順位レベルの変更などを検討してください。また、AWRのインメモリ・セグメント統計で、以下の値が多いセグメントを特定することができます。これを参考に圧縮タイプを検討します。
- In-Memory Segments by Scans(スキャンが多いインメモリ・セグメント)
- In-Memory Segments by DB Block Changes(変更が多いインメモリ・セグメント)
- In-Memory Segments by Populate CUs(ポピュレートが多いインメモリ・セグメント)
- In-Memory Segments by Repopulate CUs(再ポピュレートが多いインメモリ・セグメント)
3. DBIMのパフォーマンス統計の確認
最後に、DBIMのパフォーマンス統計やIM列ストアの確認方法について紹介します。RAC環境でインスタンス全体を確認するときには、GV$ビュー(v$im_segmentsはgv$im_segmentsとして)を使用してください。
(1)DBIMのパフォーマンス統計
パフォーマンス統計は、AWRの”Instance Activity Stats”からIM関係の統計を確認します(以下のようなSQLで、カレント・セッション統計を出力して確認することもできます)。
SQL> SELECT display_name, value FROM v$mystat m, v$statname n 2 WHERE m.statistic#=n.statistic# AND display_name LIKE 'IM scan %' ORDER BY 1;
問合せに関係する主なものには、以下のようなIM関連の統計があります。例えば、”IM scan CUs predicates optimized”と”IM scan CUs pruned”を見るとストレージ索引の効果が分かりますが、効率が悪いときは実際のCU(カラム・ユニット)のストレージ索引の状態を確認します。また、”IM scan bytes in-memory”と”IM scan bytes uncompressed”でIMの圧縮効率が確認できますが、効果が少ないときにはオブジェクトごとの圧縮率を確認します。
統計名 |
説明 |
| IM scan CUs columns accessed | 問合せでアクセスしたCU(カラム・ユニット)数 |
| IM scan CUs predicates optimized | ストレージ索引によってアクセスしたCU数 |
| IM scan CUs pruned | ストレージ索引によって読み飛ばされたCU数 |
| IM scan rows | IMスキャンで論理的な読み込み対象となる行数 |
| IM scan rows optimized | IMスキャンで実際に読み飛ばされた行数 |
| IM scan rows projected | 検索結果の処理対象行数(結果出力のための行数) |
| IM scan bytes in-memory | IM列ストアから読み込んだバイト数 |
| IM scan bytes uncompressed | 読み込まれたデータのディスク上でのバイト数 |
(2)メモリ圧縮ユニット(IMCU)とオブジェクトの状態
IM列ストアのIMCUとオブジェクトの圧縮率を確認するSQLをいくつか紹介します。
- 各オブジェクトのIMCU
以下のSQLで、IM列ストア内のIMCU数やサイズなどを確認できます。行数とサイズ(数十万行または数百Mバイト)によって分割されるので、どのように作成されているか分かります(行長が小さいときは行数で分割されます)。
-- IMCU数 SQL> SELECT object_name, COUNT(*) num_imcu FROM v$im_header i, dba_objects o 2 WHERE i.objd = o.object_id GROUP BY object_name ORDER BY 1; OBJECT_NAME NUM_IMCU -------------------- ---------- <オブジェクト名> <IMCU数> -- IMCUのリスト SQL> SELECT object_name, allocated_len/1024/1024 alloc_mb, num_rows, num_cols 2 FROM v$im_header i, dba_objects o WHERE i.objd = o.object_id ORDER BY 1; OBJECT_NAME ALLOC_MB NUM_ROWS NUM_COLS -------------------- ------------ ------------ ---------- <オブジェクト名> <IMCUサイズ> <IMCU内行数> <列数>
- IMCU内のCU
以下のSQLで、CUのストレージ索引(最小値と最大値)の効果を確認できます(UTL_RAW.CAST_TO_VARCHAR2ファンクションは列がVARCHAR2データ型のときで、NUMBERデータ型にはUTL_RAW.CAST_TO_NUMBERファンクション、DATEデータ型にはDBMS_STATS.CONVERT_RAW_VALUEプロシージャを使用します。第37回で説明したWITHのPL/SQLファンクションを使用しています)。
-- VARCHAR2データ型(NUMBERデータ型はUTL_RAW.CAST_TO_NUMBERファンクション)
SQL> SELECT object_name, column_name, dictionary_entries dict_entries,
2 UTL_RAW.CAST_TO_VARCHAR2(minimum_value) min_value,
3 UTL_RAW.CAST_TO_VARCHAR2(maximum_value) max_value
4 FROM v$im_col_cu i, dba_objects o , dba_tab_cols c
5 WHERE i.objd = o.data_object_id AND o.object_name = c.table_name
6 AND i.column_number = column_id and o.object_name = '<表名>'
7 AND c.column_name IN ('<列名>',…) ORDER BY 2;
OBJECT_NAME COLUMN_NAME DICT_ENTRIES MIN_VALUE MAX_VALUE
---------------- ------------- ------------ ------------------------- ----------------------------
<オブジェクト名> <列名> <値の種類数> <最小値> <最大値>
-- DATEデータ型(DBMS_STATS.CONVERT_RAW_VALUEプロシージャを使用)
SQL> WITH FUNCTION row2date(x raw) RETURN DATE AS n DATE;
2 BEGIN dbms_stats.convert_raw_value(x,n); RETURN n; END;
3 SELECT object_name, column_name, dictionary_entries dict_entries,
4 row2date(minimum_value) min_value, row2date(maximum_value) max_value
5 …
効率が悪い(同じ値が含まれているIMCUが多い)ときは再作成を検討してください。効果的にしたい列でソートして格納することで改善できます(これは行型フォーマットの格納方法から変更する必要があります)。属性クラスタリングを使用しても改善することが可能です。ただし、すべてのSQLで最適にはできないので、パーティションも同時に使用することで、さらに効果的にすることが可能になります。
属性クラスタリング(Attribute Clustering)について
ご存知ない方のために、ここでOracle Database 12cからの属性クラスタリングについて簡単に説明します。 属性クラスタリングは、ダイレクト・パス・インサートやALTER TABLE MOVEを行うときに、指定した列の順序によってデータを格納します。そのため、明示的にソート処理を行わなくても、Oracle ExadataやDBIMのストレージ索引を効果的に作成することができます。これには以下の2つのタイプが用意されているので、用途によって使い分けることができるようになっています。
- Clustering by Linear order(線形順序の属性クラスタリング) 指定した列の順序に基づいて格納するので、複数列のときに先頭列がWHERE句に指定されていないと効果がありません。
- Clustering by Interleaved order(インターリーブ順序クラスタリング) 多次元クラスタリング(Z-orderカーブ・フィッティング)を使用して格納するので、複数列のときに先頭列がWHERE句に指定されていなくても効果があります。
- オブジェクトの圧縮率
圧縮を改善するときには、以下のSQLでオブジェクトの圧縮率や各列の圧縮レベルを確認します。
-- 圧縮率の確認 SQL> SELECT segment_name name, partition_name, bytes/1024/1024 orig_mb, 2 inmemory_size/1024/1024 in_mem_mb, bytes/inmemory_size comp_ratio 3 FROM v$im_segments WHERE v.owner = '<所有者>' ORDER BY 4; NAME PARTITIO_NAME ORIG_MB IN_MEM_MB COMP_RATIO -------------------- ------------- ---------- ---------- ---------- CUSTOMER 256 240.4375 1.06472576 … -- 列の圧縮レベル SQL> SELECT column_name, inmemory_compress FROM v$im_column_level WHERE table_name = 'CUSTOMER'; COLUMN_NAME INMEMORY_COMPRESSION -------------------- -------------------- CUSTOMER_NAME FOR QUERY LOW …
4. おわりに
今回はRAC環境のDBIMについて説明しましたが、少しは参考になりましたでしょうか。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
