※本記事は、Nigel Bayliss による”Oracle Optimizer Glossary” を翻訳したものです。
2026年5月6日
これは、私がクイック・リファレンスとしてまとめた Oracleオプティマイザの「生きた」用語集です。SQLチューニング・ガイド の用語集をベースに、いくつかの追加項目と補足リンクを加えています。
以下のセクションに分けています。
オプティマイザ機能
適応カーソル共有(ACS)
適応カーソル共有(ACS)により、Oracle Database はバインド変数を使用する単一の SQL 文に対して、実行時のバインド値とその選択性に基づき、複数の実行計画を生成できます。
カーソルの状態:
- バインド非依存: その計画がすべてのバインド値に適しています。
- バインド依存: Oracle は、異なるバインド値での動作の監視を開始します。
- バインド認識: Oracle は、観測されたバインド値の選択性に基づいて、異なる計画を作成して使用します。
動的パフォーマンス・ビュー V$SQL には、適応カーソル共有に関連付けられたカーソルの状態を確認するための列 IS_BIND_AWARE および IS_BIND_SENSITIVE があります。
例:
SELECT * FROM orders WHERE customer_id = :b1;
:b1 が多くの場合は非常に選択性の高い値(少数行)であり、ときにはそうでない値(多数行)になる場合、適応カーソル共有は「選択性が高い」計画(索引アクセス)と「選択性が低い」計画(全表スキャン)の両方を保持できます。
有用なビュー: V$SQL、列 IS_BIND_AWARE および IS_BIND_SENSITIVE
詳細情報:
適応動的サンプリング
動的統計のレベルを自動的に調整できるようにする、適応オプティマイザの機能です。これは オプティマイザ適応統計 および動的サンプリング・レベル 11(OPTIMIZER_DYNAMIC_SAMPLING 初期化パラメータで設定)に関連しています。
詳細情報:
適応計画
適応計画(またはオプティマイザ適応計画)により、オプティマイザは SQL 文について、解析完了後かつ実行中に計画上の判断を行えます。これにより、オプティマイザは実行時にいくつかの種類の問題を修正できます。
- 結合方法: ハッシュ結合とネステッド・ループ結合
- ビットマップ索引の使用
- パラレル分散方式
適応計画は、初期化パラメータ OPTIMIZER_ADAPTIVE_PLANS によってデフォルトで有効化されています。
関連項目: 適応問合せ計画
詳細情報:
適応統計
適応統計(またはオプティマイザ適応統計)は、適応問合せ最適化フレームワーク内の一連の機能です。オプティマイザが実行時に実行計画を調整し、より良い統計につながる追加情報を検出できるようにします。
この機能では、SQL計画ディレクティブ、統計フィードバック、適応動的サンプリングが使用されます。
この機能は OPTIMIZER_ADAPTIVE_STATISTICS 初期化パラメータで制御され、Oracle Database 12c Release 2 以降では、初期化パラメータ OPTIMIZER_ADAPTIVE_STATISTICS によりデフォルトで無効になっています。
詳細情報:
バインド認識カーソル
異なるバインド値に対して異なる計画を使用できる バインド依存カーソル です。カーソルがバインド認識になると、オプティマイザは以後の実行について、バインド値とそのカーディナリティ見積りに基づいて計画を選択します。
例:
SELECT * FROM sales WHERE region_id = :r;
:r の値について選択性の異なる実行が数回行われると、カーソルはバインド認識になります。そして、小さいリージョンでは region_id 列に対する索引アクセス計画を使用し、大きいリージョンでは SALES 表に対する全表スキャンを使用します。
適応カーソル共有 も参照してください。
バインド非依存カーソル
最適な計画がバインド変数の値に依存しないカーソルです。
例:
SELECT COUNT(*) FROM big_table WHERE status = :s;
:s のどの値に対しても索引が有効でない場合、1 つの計画(全表スキャン)で十分です。
適応カーソル共有 も参照してください。
バインド依存カーソル
最適な計画がバインド変数の値に依存する可能性があるカーソルです。データベースは、異なるバインド値を使用するバインド依存カーソルの動作を監視し、別の計画が有益かどうかを判断します。バインド依存カーソルは、数回の実行後にバインド認識になる場合があります。
例:
SELECT * FROM accounts WHERE acct_type = :t;
:t の値の選択性が異なると、Oracle は監視を行い、必要に応じて個別の計画を作成します。
適応カーソル共有 も参照してください。
バインド変数ピーク
ハード解析中に、オプティマイザがバインド変数内の値を参照する機能です。バインド値を参照することで、オプティマイザはリテラルが使用された場合と同様に WHERE 句条件の選択性を判断でき、計画を改善できます。これは適応カーソル共有と連携して動作します。
例:
SELECT * FROM customers WHERE cust_type = :b;
初回実行で :b = 'VIP' という非常に選択性の高い値が見えると、索引計画が生成されます。その後、選択性の低い値で実行されると、適応カーソル共有が 2 つ目の計画を追加するきっかけになる場合があります。
適応カーソル共有 も参照してください。
カーディナリティ・フィードバック
統計フィードバック を参照してください。
コストベース最適化
Oracle Database で使用される主要な最適化方式です。SQL 文に対して最も効率的な実行計画を選択するための戦略であり、主にオプティマイザ統計と見積りコストに基づいています。
例:
- orders と customers の結合では、オプティマイザは行数とコストに基づき、索引を使うネステッド・ループ結合と、全表スキャンを使うハッシュ結合を比較評価します。
詳細情報:
コストベース・オプティマイザ(CBO)
Oracleオプティマイザの従来の名称です。以前のリリースでは、コストベース・オプティマイザはルールベース・オプティマイザ(RBO)の代替でした。CBO はさまざまな実行計画の「コスト」を計算し、最も低いコストの計画を選択します。コストは、推定リソース消費量(CPU、I/O)に基づく相対的な指標です。
動的サンプリング
動的サンプリングは、Oracle Database 12c Release 1(12.1)以降では 動的統計 とも呼ばれる最適化技法です。データベースが内部 SQL 文を実行し、表ブロックの小さなランダム・サンプルをスキャンして述語の選択性を見積ります。これにより、より正確なカーディナリティ見積りが可能になります。
動的統計
データベースが内部(再帰)SQL 文を実行し、表ブロックの小さなランダム・サンプルをスキャンして述語の選択性を見積る最適化技法です。これにより、より正確なカーディナリティ見積りが可能になります。
詳細情報:
動的統計レベル
データベースが動的統計を収集するタイミングと、オプティマイザが統計を収集する際に使用するサンプル・サイズの両方を制御するレベルです。動的統計レベルは、OPTIMIZER_DYNAMIC_SAMPLING 初期化パラメータ、または文ヒント(DYNAMIC_SAMPLING)を使用して設定します。
詳細情報:
ヒント
SQL 文内に埋め込まれる指示であり、開発者がオプティマイザの選択に影響を与えるために使用できます。強力な機能ですが、慎重に検討しないと最適な動作を上書きしてしまう可能性があるため、注意して使用する必要があります。
例:
/*+ USE_INDEX(table_name index_name) *//*+ FULL(table_name) */
詳細情報:
論理オプティマイザ
論理オプティマイザは、Oracleオプティマイザ全体の一部です。
論理オプティマイザ(問合せ変換フェーズとも呼ばれます)は、SQL 問合せを再構成して、実行効率が高くなる可能性のある論理的に等価な問合せを生成することに重点を置きます。
物理オプティマイザ も参照してください。
詳細情報:
最適化
SQL 文を実行するための最も効率的な方法を選択する全体的なプロセスです。
オプティマイザ
SQL 文で参照されるオブジェクトおよび文で指定された条件に関連する要素を考慮し、SQL 文を実行する最も効率的な方法を決定する、データベースに組み込まれたソフトウェアです。
アウトライン
実行計画を完全に指定する特殊なタイプのオプティマイザ・ヒントです。アウトライン・ヒントは、特定の実行計画を再作成するために Oracle によって内部的に使用されます。
SQL 文のアウトラインは、DBMS_XPLAN の format で “OUTLINE” キーワードを使用して確認できます。例:
SELECT FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(format=>'typical +outline'));
パフォーマンス・フィードバック
この自動再最適化の形式は、繰り返し実行される SQL 文について、自動的に選択されるパラレル度を改善するのに役立ちます。これは自動パラレル度とともに有効になり、したがって PARALLEL_DEGREE_POLICY が ADAPTIVE に設定されている場合にアクティブになります。
物理オプティマイザ
物理オプティマイザは、Oracleオプティマイザ全体の一部です。
物理オプティマイザは、変換済みの論理問合せを受け取り、統計、アクセス・パス、利用可能な操作に基づいて最適な実行計画を決定します。
論理オプティマイザ も参照してください。
パイプライン表ファンクション
複数行を 1 行ずつ、またはバッチ単位で戻す PL/SQL ファンクションです。SELECT 文の FROM リストで TABLE 演算子のオペランドとして使用される場合に呼び出すことができます。
例:
SELECT * FROM TABLE(stream_orders_fn(:batch_id));
行は生成されるたびに呼び出し側へ「ストリーム」されます。
計画生成機能
指定された問合せブロックについて、異なるアクセス・パス、結合方法、結合順序を試し、最もコストの低い計画を見つけるオプティマイザの構成要素です。
再帰SQL
ユーザーが発行した SQL 文を実行するために、データベースが発行しなければならない追加の SQL 文です。再帰 SQL の生成は再帰コールと呼ばれます。たとえば、データ・ディクショナリ情報がメモリー内に存在せず、ディスクから取得する必要がある場合、データベースは再帰コールを生成します。
SQL計画ディレクティブ
より最適な計画を生成するためにオプティマイザが使用できる追加情報および指示です。たとえば、SQL計画ディレクティブは、不足している統計を収集するように、または動的統計を収集するようにオプティマイザへ指示する場合があります。これらは DBA_SQL_PLAN_DIRECTIVES ビューで確認できます。
オプティマイザは、OPTIMIZER_ADAPTIVE_STATISTICS がデフォルト以外の値 TRUE に設定されている場合に SQL計画ディレクティブを使用します。
詳細情報:
統計フィードバック
以前は カーディナリティ・フィードバック と呼ばれていました。
カーディナリティの見積り誤りがある実行計画を改善するため、SQL を自動的に再解析する自動再最適化の形式です。特に、複雑な述語が多い問合せでは、オプティマイザがカーディナリティを誤って見積ることがあります。統計フィードバックは、再解析を行い、カーディナリティ見積りを反復的に改善することで、この問題に対処することを目的としています。これにより、オプティマイザは初期見積りの不正確さに対応できます。
動的パフォーマンス・ビュー V$SQL には、再最適化の状態を示す IS_REOPTIMIZABLE という列があります。V$SQL_REOPTIMIZATION_HINTS ビューには、再最適化プロセスに関連する追加情報が含まれています。
コスト計算と最適化
ベース・カーディナリティ
表におけるベース・カーディナリティは、述語によるフィルタリングが適用される前の表内の総行数です。
例:
- EMPLOYEES 表に 100,000 行がある場合、そのベース・カーディナリティは 100,000 です。
カーディナリティ
特定の操作(フィルタや結合など)が返すと見積られる行数です。正確なカーディナリティ見積りは、オプティマイザが最適な計画を選択するうえで非常に重要です。以下の EXPLAIN PLAN では、すべての操作のカーディナリティは 105 です。
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Pstart| Pstop |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 105 | 13965 | 2 | | |
| 1 | PARTITION RANGE ALL| | 105 | 13965 | 2 | 1 | 5 |
| 2 | TABLE ACCESS FULL | EMP_RANGE | 105 | 13965 | 2 | 1 | 5 |
---------------------------------------------------------------------------------
詳細情報:
コスト
実行計画について、見積られたリソース使用量を表す内部的な数値指標です。コストが低いほど、より効率的な計画です。以下の EXPLAIN PLAN では、SELECT 文全体(Id = 0 の行)の総コストは 2 です。
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Pstart| Pstop |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 105 | 13965 | 2 | | |
| 1 | PARTITION RANGE ALL| | 105 | 13965 | 2 | 1 | 5 |
| 2 | TABLE ACCESS FULL | EMP_RANGE | 105 | 13965 | 2 | 1 | 5 |
---------------------------------------------------------------------------------
コストは相対的な単位であり、CPU 回数や I/O 回数をそのまま表すものではありません。同一のオプティマイザ環境でない限り、複数の文のコストを直接比較することはできません。
詳細情報:
コスト・モデル
オプティマイザが実行計画のコストを計算するために使用する数学的モデルです。I/O 操作や CPU 使用量などの要素を考慮します。
密度
列の選択性を測定する 0 から 1 までの小数値です。1 に近い値は、その列の選択性が低いことを示し、0 に近い値は、その列の選択性がより高いことを示します。
たとえば、1 から 10 までの値(NULL 値なし)を含む列(COL1)を持つ表(TAB1)を考えます。COL1 の密度は 1/10、つまり 0.1 です。
見積り機能
指定された実行計画の全体コストを決定するオプティマイザの構成要素です。
予想カーディナリティ
表について、すべてのフィルタ述語が適用された後に表が持つとオプティマイザが見積る行数です。
ヒューリスティック
ヒューリスティックは、オプティマイザが問合せ最適化を進める際に使用するルールベースの判断です。オプティマイザは、実行計画を生成するために、ヒューリスティックとコストベースの判断の両方を使用します。ヒューリスティックは通常、コストベースの判断が行われる前に適用されます。
索引クラスタリング係数
従業員の姓のような索引値に対して、行の順序がどの程度まとまっているかを示す指標です。行がデータ・ブロック全体に分散しているほど、クラスタリング係数は高くなります。索引を使用して表から複数行を取得する場合、クラスタリング係数が低いと、クラスタリング係数が高い場合に比べて、表の列値を取得するためにアクセスする必要がある表ブロック数が少なくなります。
オプティマイザ環境
ワークエリア・サイズやオプティマイザ設定(たとえば optimizer mode)など、実行計画の生成に影響する可能性があるセッション設定全体です。
例:
- ALTER SESSION SET optimizer_mode=first_rows(10); により、選択される結合方法やアクセス・パスが変わる場合があります。
詳細情報:
オプティマイザ目標
オプティマイザによるリソース使用の優先順位付けです。OPTIMIZER_MODE 初期化パラメータを使用して、目標を「最高のスループット」または「最高のレスポンス時間」に設定できます。
- ALL_ROWS: 最高のスループットを目標に最適化し、すべての行をできるだけ速く取得することを目指します。これがデフォルトです。
- FIRST_ROWS および FIRST_ROWS(n): 最高のレスポンス時間を目標に最適化し、最初の
n行をできるだけ速く取得することを目指します。
選択性
選択性は、問合せ述語(WHERE 句条件など)に一致すると想定される、表内の行の割合(またはパーセント)を指します。
例:
SELECT * FROM employees WHERE dept_id= 10;
- 従業員が 1000 人いて、そのうち 100 人が部門 10 に所属しているとします。
- 選択性 = 100 / 1000 = 0.1(10%)
選択性の式は次のとおりです。
選択性 = 返される行数 / ベース・カーディナリティ
選択性が低い
行セットから比較的大きな割合の行が返される場合に使用される非公式な用語です。選択性が 1 に近づくほど、問合せはより選択性が低くなります。
たとえば、100 万行の表から 999,999 行を返す問合せは選択性が低い問合せです。同じ表から 1 行を返す問合せは選択性が高い問合せです。
実行計画
承認済み計画
SQL計画管理の文脈では、SQL 文の SQL計画ベースラインに含まれており、したがってオプティマイザが使用可能な計画です。
詳細情報:
アクセス・パス
SQL 文の文脈では、データベースがデータベースからデータを取得する方法です。たとえば、索引を使用する問合せと全表スキャンを使用する問合せは、異なるアクセス・パスを使用します。
詳細情報:
適応計画
適応問合せ計画 を参照してください。
適応問合せ計画
実行時条件によってオプティマイザの見積りが不正確であることが示されたため、最適化後に変化する実行計画です。適応問合せ計画には、組み込みの複数の計画オプションがあります。初回実行時、特定のサブプランがアクティブになる前に、オプティマイザはどのオプションを使用するかについて最終判断を行います。オプティマイザは、この時点までの実行中に観測された情報に基づいて選択します。したがって、適応問合せ計画により、文の最終計画がデフォルト計画と異なることがあります。
詳細情報:
共通表式(CTE)
副問合せファクタリング を参照してください。
条件
1 つ以上の式と論理演算子の組合せであり、TRUE、FALSE、または UNKNOWN の値を返します。
相関副問合せ
外側の問合せの値に依存する副問合せの一種です。通常の(非相関)副問合せとは異なり、外側の問合せの行にある列を参照するため、単独では実行できません。
例:
SELECT e.*FROM emp eWHERE e.salary >
(SELECT AVG(salary) FROM emp WHERE deptno = e.deptno);
カーソル期間一時表
問合せ実行中にインスタンス化され、カーソルの存続期間中、問合せ結果を格納する一時表です。WITH 句問合せやスター型変換などの複雑な操作では、この最適化により、繰り返し使用される副問合せの中間結果のマテリアライズが強化されます。このように、カーソル期間一時表はパフォーマンスを改善し、I/O を最適化します。
例:
- 文の中で複数回実行される複雑な WITH 問合せは、再計算を避けるためにカーソル期間一時表にマテリアライズされる場合があります。
デフォルト計画
適応問合せ計画 において、データ・ディクショナリの統計を使用してオプティマイザが最初に選択した実行計画です。デフォルト計画は最終計画と異なる場合があります。
動的計画
最適化中に 適応問合せ計画 が適切であると判断された場合、問合せに対して複数のサブプランが選択される場合があります。実行時に使用される最終サブプランは、オプティマイザ統計コレクタ によって取得された統計に依存します。
実行計画
データベースが SQL 文を実行するために使用する一連のステップです。各ステップは、データベースから行データを物理的に取得するか、その文を発行したセッションに向けて行を準備します。実行計画は、操作の順序、アクセス・パス、結合方法、その他の詳細を定義します。通常は DBMS_XPLAN または SQL Monitor を使用して確認します。
実行ツリー
実行計画内で、あるステップから別のステップへ行ソースがどのように流れるかを示すツリー図です。
EXPLAIN PLAN
指定された SQL 文を実際には実行せずに、その実行計画を表示する SQL ユーティリティ(EXPLAIN PLAN FOR 文)です。
例:
EXPLAIN PLAN FOR SELECT * FROM emp WHERE empno = 10;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
詳細情報:
式
1 つ以上の値、演算子、SQL ファンクションの組合せであり、値として評価されます。たとえば、式 2*2 は 4 と評価されます。一般に、式はその構成要素のデータ型を引き継ぎます。
詳細情報:
フィルタ条件
SQL 文で参照される単一オブジェクトから行を除外する WHERE 句の構成要素です。
例:
WHERE hire_date >= DATE '2024-01-01'
最終計画
適応計画において、最後まで実行される計画です。デフォルト計画は最終計画と異なる場合があります。
インライン・ビュー
インライン・ビューは、SELECT 文の FROM 句内に配置される副問合せです。実質的には一時的な名前付き結果セットを作成し、外側の問合せがそれを表として扱えるようにします。インライン・ビューは WITH 句を使用して作成することもでき、複雑な問合せの可読性と保守性を高められます。
例:
SELECT *
FROM (
SELECT deptno, AVG(sal) avg_sal
FROM emp
GROUP BY deptno) v
WHERE v.avg_sal > 10000;
非相関副問合せ
非相関副問合せ を参照してください。
パーティション・プルーニング
データベースが問合せの実行計画から不要なパーティションを自動的に除外する最適化技法です。たとえば、問合せのフィルタ条件に基づいて、特定の索引セグメントにアクセスしたり、関連するパーティションのみをスキャンしたりします。
関連するパーティションを最適化中に判別できる場合、静的パーティション・プルーニングは解析時に発生します。そうでない場合、実行時に特定のパーティションが識別されるものを動的プルーニングと呼びます。
例:
WHERE order_date BETWEEN DATE '2025-01-01' AND DATE '2025-01-31'
月単位の範囲パーティション表では、データベースは 2025 年 1 月のパーティションのみをスキャンします。
パーティション表 も参照してください。
詳細情報:
述語
WHERE 句、JOIN 句、または HAVING 句で行をフィルタするために使用される条件です。
例:
- t1.cust_id = t2.cust_id(結合述語)
- amount > 1000(フィルタ述語)
プライベート一時表
データとメタデータがセッション・プライベートである、メモリー専用の一時表です。
問合せブロック
トップレベルの SELECT 文、副問合せ、またはマージされていないビューです。
サブプラン
適応計画の一部であり、オプティマイザが実行時に代替として切り替えることができる部分です。サブプランは、計画内の複数の操作で構成される場合があります。たとえば、オプティマイザは実行時に計画を変更するかどうかを判断する際、結合方法と対応するアクセス・パスを 1 つの単位として扱うことができます。
サブプラン・グループ
適応問合せ計画 内のサブプランの集合です。
副問合せ
別の SQL 文の内部にネストされた問合せです。
相関副問合せ も参照してください。
例:
SELECT *
FROM emp
WHERE deptno IN
(SELECT deptno FROM dept WHERE location = 'BOSTON');
副問合せファクタリング
副問合せファクタリング句は、SQL 文における WITH 句と同義です。複雑な問合せを論理的に分割し、単純化して、再利用しやすく、読みやすくするために使用されます。
例:
WITH high_sal AS
(SELECT empno FROM emp WHERE sal > 10000)
SELECT *
FROM emp e JOIN high_sal h ON e.empno = h.empno;
非相関副問合せ
外側の問合せの値に依存しない副問合せの一種です。
相関副問合せ も参照してください。
例:
SELECT * FROM emp WHERE sal > (SELECT AVG(sal) FROM emp);
オプティマイザ統計
列グループ
問合せ最適化中に行数(カーディナリティ)と選択性をより適切に見積るため、Oracle が組合せ統計を保持する 2 つ以上の列の集合です。
例:
BEGIN
DBMS_STATS.CREATE_EXTENDED_STATS(
ownname => 'HR',
tabname => 'EMPLOYEES',
extension => '(DEPARTMENT_ID, JOB_ID)'
);
END;
/
データ・ディクショナリ・ビュー ALL_STAT_EXTENSIONS では、列グループが公開されています。
拡張統計 も参照してください。
詳細情報:
列統計
オプティマイザが最適な実行計画を決定するために使用する列に関する統計です。列統計には、個別列値の数、最小値、最大値、NULL 数が含まれます。これらは ALL_TAB_COL_STATISTICS ディクショナリ・ビューで確認できます。
データの偏り
列内の値のデータ分布に大きな偏りがあることです。
- 範囲の偏りは、列の値範囲にわたるデータ値の非一様分布を指します。たとえば、ある列に 1 から 1000 までの値の範囲があるものの、500 から 900 の間の値が欠落している場合、それは範囲の偏りです。
- 値の偏りは、列内の特定値の出現頻度が不均一であることを指します。たとえば、ある列に 1 から 2 までの値が含まれており、値 1 の行が 1 行、値 2 の行が 1000 行ある場合、それは値の偏りです。
ヒストグラムは、範囲の偏りと値の偏りを特徴付けるために使用されます。
詳細情報:
エンドポイント番号
ヒストグラム内のバケットを一意に識別する番号です。頻度ヒストグラムおよびハイブリッド・ヒストグラムでは、エンドポイント番号はエンドポイントの累積頻度です。高さ調整済ヒストグラムでは、エンドポイント番号はバケット番号です。
詳細情報:
エンドポイント繰返し回数
ハイブリッド・ヒストグラムにおいて、ヒストグラム内の各エンドポイント(バケット)について、エンドポイント値が繰り返される回数です。繰返し回数を使用することで、オプティマイザはポピュラー値について正確な見積りを取得できます。
詳細情報:
エンドポイント値
エンドポイント値は、ヒストグラム・バケット内の値範囲における最大値です。
詳細情報:
式統計
WHERE 句に式を使用する述語が含まれている場合に、オプティマイザの見積りを改善する 拡張統計 の一種です。
拡張統計
複数の述語が存在する場合、または述語に式が含まれる場合に、カーディナリティ見積りを改善するオプティマイザ統計の一種です。
詳細情報:
拡張
列グループ または 式統計 です。
拡張は、DBMS_STATS.CREATE_EXTENDED_STATS で作成される列グループと式統計の両方を対象とします。
列グループと式に対して収集される統計は、拡張統計と呼ばれます。
固定オブジェクト統計
固定オブジェクト統計は、固定オブジェクト上で収集されるオプティマイザ統計です。固定オブジェクトとは、動的パフォーマンス表およびその関連索引のことです。これらのオブジェクトは現在のデータベース活動を記録し、ユーザー SYS によって所有されます。これらは DBMS_STATS.GATHER_FIXED_OBJECT_STATS で収集できます。
頻度ヒストグラム
個別の列値ごとに 1 つのバケットが対応するヒストグラムの一種です。たとえで言えば、硬貨を分類するようなものです。すべての 1 セント硬貨はバケット 1、すべての 5 セント硬貨はバケット 2、という具合です。
詳細情報:
高さ調整済ヒストグラム
各バケットにほぼ同じ数の行が含まれるように、列値をバケットに分割したヒストグラムです。
詳細情報:
ヒストグラム
表の列におけるデータ分布について、より詳細な情報を提供する特殊な列統計です。
ヒストグラムは、列値が一様に分布していない場合に、オプティマイザがより正確なカーディナリティ見積りを行うのに役立ちます。
詳細情報:
ハイブリッド・ヒストグラム
サンプル内の各エンドポイントの正確な頻度を格納し、1 つの値が複数のバケットに格納されないことを保証する、拡張された高さ調整済ヒストグラムです。
詳細情報:
増分統計メンテナンス
パーティション・レベルの統計を集約することで、パーティション表のグローバル統計を生成するデータベースの機能です。
パーティション表 も参照してください。
詳細情報:
索引統計
全表スキャンを実行するか索引スキャンを実行するかをオプティマイザが判断するために使用する、索引に関する統計です。索引統計には、Bツリー・レベル、リーフ・ブロック数、索引クラスタリング係数、個別キー、索引内の行数が含まれます。これらは ALL_IND_STATISTICS で確認できます。
個別値数(NDV)
列内の一意値の数です。NDV は、カーディナリティ見積りの生成において重要です。
非ポピュラー値
ヒストグラム において、2 つ以上のエンドポイントにまたがらない任意の値です。非ポピュラーでない値はポピュラー値です。
詳細情報:
非ワークロード統計
データベースがワークロードをシミュレートする際に収集されるオプティマイザ・システム統計です。
ワークロード・システム統計は、実際のデータベース・ワークロードを観測しながら収集されます。
例:
EXEC DBMS_STATS.GATHER_SYSTEM_STATS('NOWORKLOAD')
オプティマイザ統計
各 SQL 文に最適な実行計画を選択するためにオプティマイザが使用する、データベース・オブジェクトに関する統計情報です。カテゴリには、行数などの表統計、Bツリー・レベルなどの索引統計、CPU および I/O パフォーマンスなどのシステム統計、NULL 数などの列統計が含まれます。
表および索引内のデータに関するメタデータであり、行数、個別値数、平均行長、データ分布(ヒストグラム)などが含まれます。正確で最新の統計は、CBO にとって非常に重要です。
詳細情報:
オプティマイザ統計アドバイザ
統計収集の実施方法を検査し、それらの実施方法に関する問題を自動的に診断し、検出事項と推奨事項のレポートを生成するツールです。
詳細情報:
オプティマイザ統計アドバイザ・ルール
オプティマイザ統計アドバイザ がチェックを実行する際に使用する、システム提供の標準です。
オプティマイザ統計の収集
オプティマイザ統計の収集は、データベース・オブジェクトに関する統計情報を収集・作成するプロセスです。データベースはこれらの統計を自動的に収集できます。また、システム提供の DBMS_STATS パッケージを使用して手動で収集することもできます。
詳細情報:
オプティマイザ統計コレクタ
適応計画で使用する実行時統計を収集するため、実行計画内の重要なポイントに挿入される行ソースです。統計コレクタは、適応計画が有効な場合にのみ使用されます。
適応計画 も参照してください。
オプティマイザ統計収集
バルク・データ・ロード中にオンラインでオプティマイザ統計を収集するために使用される計画操作です。
例:
insert /*+ append */ into t1 select * from t2;

詳細情報:
オプティマイザ統計プリファレンス
自動統計収集および DBMS_STATS 統計収集プロシージャで使用されるパラメータのデフォルト値です。
詳細情報:
保留統計
公開されていないオプティマイザ統計です。デフォルトでは、オプティマイザは公開済み統計を使用し、保留統計は使用しません。
例:
- PUBLISH を FALSE に設定して収集します。
- ALTER SESSION SET optimizer_use_pending_statistics=TRUE; を使用してセッション内でテストします。
ポピュラー値
ヒストグラム において、2 つ以上のエンドポイントにまたがる任意の値です。ポピュラーでない値は非ポピュラー値です。
詳細情報:
リアルタイム統計
従来型 DML 操作中に自動的に収集される補足統計です。これらは、収集済みのオプティマイザ統計の必要性を置き換えるものではない点に注意してください。
詳細情報:
シノプシス
INCREMENTAL 値が true に設定されている場合に、パーティション表で収集される補助統計の集合です。
システム統計
オプティマイザが CPU および I/O の特性を使用できるようにする統計です。これらは、コスト・モデルがコスト計算を調整するために使用されます。
詳細情報:
表統計
表アクセス・コスト、結合カーディナリティ、結合順序などを判断するためにオプティマイザが使用する、表に関する統計です。表統計には、行数、ブロック数、空ブロック、ブロックあたりの平均空き領域、連鎖行の数、平均行長、表の統計の失効状態が含まれます。これらは ALL_TAB_STATISTICS ディクショナリ・ビューで確認できます。
上位頻度ヒストグラム
統計的に重要でない非ポピュラー値を無視する頻度ヒストグラムの一種であり、ポピュラー値に対してより良いヒストグラムを生成します。
詳細情報:
SQL計画管理
自動取得フィルタ
DBMS_SPM.CONFIGURE を使用して、自動初期計画取得の対象条件を指定できる SQL計画管理の機能です。初期化パラメータ optimizer_capture_sql_plan_baselines と組み合わせて使用します。
詳細情報:
自動初期計画取得
データベースで実行される反復可能な SQL 文について、データベースが SQL計画ベースラインを自動的に作成する仕組みです。自動初期計画取得を有効にするには、optimizer_capture_sql_plan_baselines 初期化パラメータを true に設定します(デフォルトは false)。
自動SQL計画管理
Oracle Database が SQL計画ベースラインを自動的に取得し、SQL 計画のパフォーマンス・リグレッションを防止できるようにする機能です。計画のパフォーマンス検証は、バックグラウンド・タスクを使用して実行することも、リアルタイムSPMを使用してフォアグラウンドで実行することもできます。
詳細情報:
自動SQLチューニング・セット
自動SQLチューニング・セット(ASTS または Auto STS)は、SYS_AUTO_STS というシステム管理の SQLチューニング・セットです。自動索引付けや自動SQL計画管理などの自動機能をサポートするため、ワークロードの SQL 文を取得する目的で使用されます。
詳細情報:
無効な計画
SQL計画管理の文脈では、データベース管理者が手動でオプティマイザの使用対象外としてマークした計画です。
例:
BEGIN
DBMS_SPM.ALTER_SQL_PLAN_BASELINE(..., attribute_name=>'ENABLED',
attribute_value=>'NO')
END;
/
有効な計画
SQL計画管理において、オプティマイザが使用可能な計画です。
固定計画
優先計画としてマークされた承認済み計画です。この場合、オプティマイザは SQL計画ベースライン内の固定計画のみを考慮します。固定計画を使用すると、オプティマイザの計画選択プロセスに影響を与えることができます。
計画を固定するには、DBMS_SPM.ALTER_SQL_PLAN_BASELINE を使用します。
手動計画取得
既存の計画をユーザー主導で SQL計画ベースラインにロードすることです。たとえば次のように実行します。exec DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE
計画展開
SQL計画履歴内の未承認計画が、SQL計画ベースライン内の承認済み計画へ変わることです。
詳細情報:
計画選択
文のハード解析を実行した後、その文に一致する計画を SQL計画ベースライン内で検索する処理です。一致する計画ベースラインがない場合、オプティマイザは通常どおりオプティマイザが選択した計画を使用します。
計画安定性
データや環境が変化しても、SQL 文が長期にわたって同じ実行計画、または「承認済み」の実行計画を一貫して使用するようにすることです。
計画検証
未承認計画のパフォーマンスを、SQL計画ベースライン内の計画と比較することです。
リアルタイムSQL計画管理
自動SQL計画管理のサブコンポーネントです。Oracle Database が SQL計画ベースラインを自動的に取得し、SQL 計画のパフォーマンス・リグレッションを防止できるようにします。計画のパフォーマンス検証は、バックグラウンドではなくフォアグラウンド(クライアント)プロセスで実行されます。
詳細情報:
反復可能なSQL文
反復可能な SQL 文とは、SQL シグネチャが変化せず、つまり空白や大文字・小文字の違いを考慮したうえで SQL テキストが同じままであり、かつデータベースが複数回ハード解析する SQL 文です。SQL 文は SQL文ログで追跡され、反復性が監視されます。
例:
SELECT * FROM sales WHERE sale_id = :bind1;
SQLハンドル
数値の SQL シグネチャから導出される文字列値です。シグネチャと同様に、ハンドルは SQL 文を一意に識別します。ユーザー API では SQL 検索キーとして機能します。SQLハンドルは DBA_SQL_PLAN_BASELINES で確認できます。
SQL管理ベース(SMB)
文ログ、計画履歴、SQL計画ベースライン、SQLプロファイルを格納する論理リポジトリです。SMB はデータ・ディクショナリの一部であり、SYSAUX 表領域に存在します。
SQL管理オブジェクト(SMO)
個々の SQL 文の実行計画を安定化する機能です。例として、SQLプロファイル、SQL計画ベースライン、SQLパッチがあります。
SQLパッチ
SQLパッチは、SQL 文の動作を変更または修正するために使用される SQL管理オブジェクトです。
詳細情報:
SQL計画履歴
SQL計画管理によって取得されたものの、「承認済み」になっておらず、したがって SQL計画ベースラインに追加されていない SQL 実行計画です。これは「未承認の SQL計画ベースライン」と考えることができます。これらは DBA_SQL_PLAN_BASELINES ビューに表示され、ACCEPTED 列の値は NO になります。
詳細情報:
SQL計画ベースライン
反復可能な SQL 文に対する 1 つ以上の承認済み計画の集合です。計画ベースラインにより、オプティマイザは SQL 文の既知の実行計画を取得し、どの計画を使用できるかを指定できます。一般に、ベースライン内の「承認済み」計画のみが使用可能であり、これにより計画の安定性を確保し、パフォーマンス低下を防止します。データベース・ビュー DBA_SQL_PLAN_BASELINES に表示される未承認計画は、SQL計画ベースラインではなく SQL計画履歴の一部です。
詳細情報:
SQL計画取得
一連の SQL 文について、計画に関する関連情報を SQL管理ベース(SMB)に取得して格納する技法です。計画を取得するとは、SQL計画管理がその計画を認識できるようにすることを意味します。
詳細情報:
SQL計画管理(SPM)
SQL計画管理は、SQL 文の実行計画を時間の経過とともに記録し、評価する仕組みです。SQL計画管理は、新しいオプティマイザ・バージョン、オプティマイザ統計の変更、システム設定など、環境変化によって発生する SQL 計画のリグレッションを防止できます。
主な機能とコンポーネントは次のとおりです。
- SQL計画ベースライン: 特定の SQL 文に対する 1 つ以上の承認済み実行計画の集合です。これらの計画のみがオプティマイザによる使用対象になります。
- 計画取得: カーソル・キャッシュまたは SQLチューニング・セットから実行計画を記録するプロセスです。自動または手動で実行できます。
- 計画選択: オプティマイザはベースライン内の有効かつ承認済みの計画のみを使用します。ベースラインが存在しない場合、通常のコストベース最適化を続行します。
- 計画展開: 新しい計画を評価し、より良いパフォーマンスを示す場合にのみベースラインに受け入れるプロセスです。展開は自動または手動で実行できます。
詳細情報:
SQLプロファイル
SQLチューニング・アドバイザ によって作成される SQL管理オブジェクトであり、オプティマイザがより良い実行計画を生成するのに役立ちます。追加の統計および補正情報を提供し、オプティマイザがより適切な判断を行えるようにします。
SQLシグネチャ
大文字・小文字を区別しないようにし、空白を正規化した SQL 文テキストを使用して計算される数値ハッシュ値です。SQL 文を一意に識別します。データベースはこのシグネチャをキーとして使用し、SQLプロファイル、SQL計画ベースライン、SQLパッチなどの SQL管理オブジェクトを管理します。たとえば、DBA_SQL_PLAN_BASELINES ビューには SIGNATURE 列が含まれます。
SQL文ログ
自動SQL計画取得が有効な場合に、オプティマイザが時間の経過とともに評価した SQL 文の SQL ID を含むログです。文がログに存在している場合、その文は追跡されています。
SQLチューニング・アドバイザ
SQL 文を分析し、パフォーマンスを改善するためのチューニング推奨事項を提供する自動化ツールです。SQL 実行計画を改善するために、SQLプロファイルの作成を推奨する場合があります。
詳細情報:
ストアド・アウトライン
SQL 文に関連付けられたヒントを格納するための非推奨機能であり、SQL計画管理に置き換えられています。ストアド・アウトライン内のヒントは、オプティマイザにその文の特定計画を選択するよう指示します。
未承認計画
SQL計画履歴内に存在するものの、SQL計画ベースラインには追加されていない文の計画です。
結合タイプと結合方法
アンチ結合
右側の副問合せと一致しない行を返す結合タイプです。たとえば、アンチ結合を使用すると、従業員がいない部門を一覧できます。アンチ結合では NOT EXISTS または NOT IN 構文を使用します。
例:
SELECT d.deptno
FROM dept d
WHERE NOT EXISTS (
SELECT 1 FROM emp e WHERE e.deptno = d.deptno);
バンド結合
非等価結合の特殊な結合タイプであり、一方のデータセットのキー値が、もう一方のデータセットで指定された範囲(「バンド」)内に収まる必要があります。通常、時間範囲の相関に使用されます。
例:
WHERE e.event_ts BETWEEN w.start_ts AND w.end_ts;
ブッシー結合ツリー
内部ノードの左側または右側の子が結合ノードになり得る結合ツリーです。
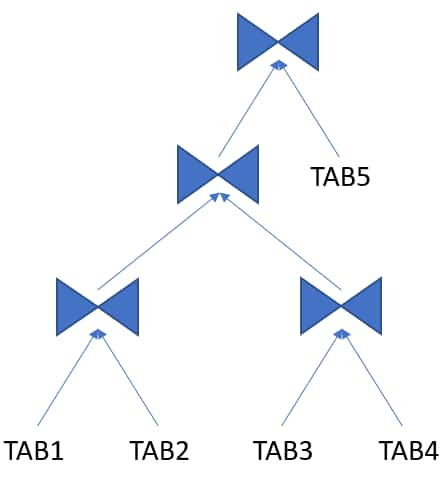
詳細情報:
クロス結合
すべての行の組合せを返す結合タイプ、つまりデカルト結合です。
例:
SELECT * FROM t1 CROSS JOIN t2;
デカルト結合
文内の 1 つ以上の表が、他のどの表とも結合条件を持たない結合タイプです。オプティマイザは、一方のデータソースのすべての行を、もう一方のデータソースのすべての行と結合し、2 つの集合のデカルト積を作成します。
- 一方の表のすべての行を、もう一方の表のすべての行と結合します(結合条件なし)。
- 特殊なケースでは意図的に使用されることがありますが、それ以外では SQL 文に結合述語が欠落していることを示している場合があります。
例:
SELECT * FROM t1, t2;
デカルト積
結合内の両方の表から、すべての行の組合せを返す結合タイプです。
駆動表
他の表が結合される基準となる表です。プログラミングでたとえると、別の for ループを含む for ループです。外側の for ループが駆動表に相当します。
等価結合
結合条件に等価演算子が含まれる結合タイプです。
例:
SELECT t1.surname, t2.department_name
FROM staff t1
JOIN departments t2 ON t1.deptno = t2.deptno;
完全外部結合
左外部結合と右外部結合を組み合わせたものです。内部結合に加えて、データベースは内部結合の結果に返されなかった両方の表の行を保持するために NULL を使用します。つまり、完全外部結合は表を結合しつつ、結合先の表に対応する行がない行も表示します。
例:
SELECT … FROM t1 FULL OUTER JOIN t2 ON t1.id = t2.id;
ハッシュ結合
大規模なデータセットを結合するための方式です。データベースは 2 つのデータセットのうち小さい方を使用して、結合キーに基づくハッシュ表をメモリー内に作成します。その後、大きい方のデータセットをスキャンし、ハッシュ表をプローブして結合行を見つけます。
内部結合
2 つ以上の表の結合タイプであり、結合条件を満たす行のみを返します。
内部表
ネステッド・ループ結合において、外部表(駆動表)ではない表です。外部表の各行に対して、データベースは内部表の行にアクセスします。
結合
SQL 文の FROM 句で指定された複数の表からデータを取得する文です。結合タイプには、内部結合、外部結合、デカルト結合があります。
詳細情報:
結合条件
式を使用して 2 つの行ソースを比較する条件です。データベースは、結合条件が true と評価される各行ソースの行を結合します。
例:
SELECT t1.name, t2.street_name
FROM customers t1, addresses t2
WHER t1.cust_id = t2.cust_id;
結合グループ
結合に参加する列のグループを指定する、ユーザー作成のデータベース・オブジェクトです。結合グループはインメモリー列ストアでのみサポートされます。
結合方法
一対の行ソースを結合する方式です。たとえば、ネステッド・ループ結合、ソート・マージ結合、ハッシュ結合があります。
詳細情報:
結合ツリー
結合ツリーは結合グラフまたは結合順序ツリーとも呼ばれます。SQL 問合せ内で複数の表がどのように結合されるかを表し、ツリーの下から上への結合順序を示します。
詳細情報:
結合タイプ
SQL 文で指定される結合のタイプです。たとえば、内部結合、左外部結合があります。
詳細情報:
結合順序
複数の表が結合される順序です。たとえば、employees 表の各行について、データベースが departments 表の各行を読み取ることがあります。別の結合順序では、departments 表の各行について、データベースが employees 表の各行を読み取ります。
2 つを超える表を結合する文を実行するために、Oracle は 2 つの表を結合し、その結果の行ソースを次の表に結合します。この処理は、すべての表が結果に結合されるまで続きます。
表が結合される順序はパフォーマンスに大きく影響する可能性があるため、オプティマイザは最も効率的な順序を見つけることを目指します。
詳細情報:
結合述語
結合内の 2 つの表の列を組み合わせる、WHERE 句または JOIN 句内の述語です。
例:
SELECT t1.name, t2.street_name
FROM customers t1, addresses t2
WHERE t1.cust_id = t2.cust_id;
左深さ結合ツリー
すべての結合において、左側の入力が前の結合結果である結合ツリーです(例の最初の表 TAB1 を除きます)。
例:
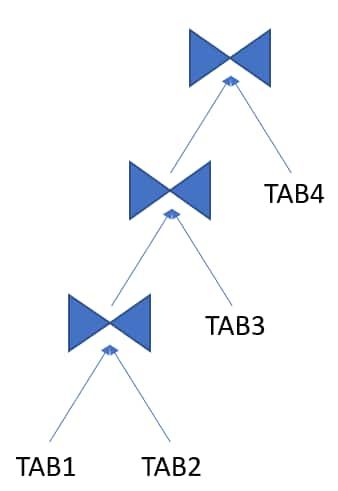
詳細情報:
左外部結合
左側の表のすべての行と、右側の表の一致する行を含む結合タイプです。
左側表
外部結合において、OUTER JOIN キーワードの左側に指定される表です(ANSI SQL 構文の場合)。結合ツリーでは左側に表示されます。
ネステッド・ループ結合
結合方法の一種であり、少数行の結合に最適です。ネステッド・ループ結合は、結合を駆動する外部表を決定し、外部表の各行について内部表の各行をプローブします。外側のループは外部表の各行に対するもので、内側のループは内部表の各行に対するものです。プログラミングでたとえると、for ループの中に別の for ループがある形です。
非等価結合
結合条件に等価演算子が含まれない結合タイプです。
例:
SELECT t1.surname, t2.department_name
FROM staff t1
JOIN departments t2 ON t1.deptno <> t2.deptno;
非結合列
1 つの表のみを参照する WHERE 句内の述語です。
外部結合
表の 1 つ以上の列に対して、外部結合演算子(+)または ANSI OUTER JOIN 構文を使用する結合タイプです。データベースは結合条件を満たすすべての行を返し、一致しない行については NULL 値を補って返します。
詳細情報:
外部表
駆動表 を参照してください。
パーティション・ワイズ結合
2 つの表の大規模な結合を、複数の小さな結合に分割する結合最適化です。2 つの表のうち一方は、結合キーでパーティション化されている必要があります。
パーティション表 も参照してください。
詳細情報:
右外部結合
右側の表のすべての行と、左側の表の一致する行を含む結合タイプです。
右深さ結合ツリー
すべての結合において、右側の入力が前の結合結果である結合ツリーです(例の最初の表 TAB1 を除きます)。
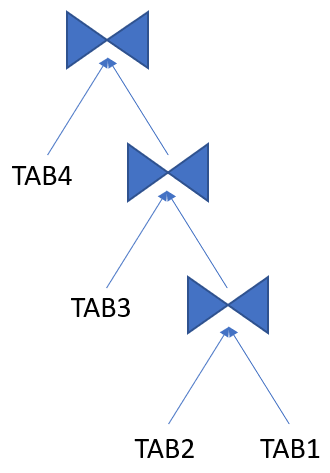
詳細情報:
右側表
結合の右側にある表を指します(結合ツリーでも右側にあります)。
自己結合
表をそれ自身に結合することです。通常は表別名を使用します。
例:
SELECT e.empno emp, m.empno manager
FROM emp e JOIN emp m ON e.mgr = m.empno;
詳細情報:
セミ結合
別の表に一致する行が存在する場合に一方の表から行を返しますが、2 番目の(一致した)表の列は返さない結合タイプです。IN または EXISTS を使用する副問合せを最適化します。
詳細情報:
ソート・マージ結合
結合方法の一種です。この結合は、両方の入力を結合キーでソートするソート結合と、そのソート済みリストをマージするマージ結合で構成されます。
詳細情報:
変換と拡張
複合ビュー・マージ(CVM)
複合ビュー・マージ(CVM)は、従来はマージできなかった複雑なビュー(GROUP BY、DISTINCT、HAVING などの構成要素があるため)を、外側の問合せへマージする変換です。
通常のビュー・マージを拡張し、より高度なビューをサポートすることで、より強力な最適化戦略を可能にします。
詳細情報:
コストベースOR拡張変換(CBOR)
OR 条件を UNION ALL または複数の分岐へ展開し、索引をより効果的に使用できるようにします。この変換を使用するかどうかの判断はコストベースです。これは、ヒューリスティックを使用していた従来の OR 変換とは対照的です。
拡張
拡張は、通常 OR 条件や集合演算(UNION ALL など)において、問合せの一部を複製し、各部分を個別に最適化して結果を結合するものです。
GROUP BY配置
可能な場合、オプティマイザは GROUP BY 句を再配置して早期に集計を行います。実行計画内でできるだけ早く行をグループ化することで、後続の結合で処理される行数を減らせるため、有利になる場合があります。
結合の交換法則/結合法則
オプティマイザが結合を入れ替え(結合の左入力と右入力を交換)、結合の連鎖を再グループ化できるようにします。これにより、より多くの結合順序を評価し、最もコストの低いものを選択できます。
結合変換
安全かつ有益な場合に、外部結合を内部結合へ、またはその逆へ変換します。
結合削除
問合せから冗長な表を削除することです。ある表の列が結合述語でのみ参照され、その結合が結果行をフィルタすることも増やすこともないことが保証されている場合、その表は冗長です。
たとえば、外部キー表の主キーへ結合しており、そのキーのみが参照されている場合、その結合は削除できます。
結合因数分解
UNION ALL 問合せの分岐から共通計算を因数分解できる、コストベースの変換です。結合因数分解がない場合、オプティマイザは UNION ALL 問合せの各分岐を個別に評価します。その結果、データ・アクセスや結合を含む反復処理が発生します。大きなベース表の余分なスキャンを避けることで、大幅なパフォーマンス改善につながる場合があります。
結合述語プッシュダウン(JPPD)
Oracle における結合述語プッシュダウン(JPPD)は、結合条件(または関連する述語)を副問合せやビューの中へ押し込む、コストベースの問合せ変換です。これにより、Oracle はより早い段階で行をフィルタし、中間行数を削減し、場合によってはより良いアクセス・パス(索引レンジ・スキャンやパーティション・プルーニングなど)を可能にします。
例:
SELECT o.order_id, o.order_date
FROM orders o
JOIN ( SELECT customer_id
FROM customers
WHERE region = 'US'
) c
ON c.customer_id = o.customer_id
WHERE o.status = 'SHIPPED';
次のように変換できます。
SELECT o.order_id, o.order_date
FROM orders o
WHERE o.status = 'SHIPPED'
AND EXISTS (
SELECT 1
FROM customers c
WHERE c.region = 'US'
AND c.customer_id = o.customer_id
);
これは、インライン・ビューが通常なら多くの行(たとえばすべての US 顧客)を返すものの、駆動表の述語(o.status=’SHIPPED’)の選択性が高い場合に役立ちます。
述語のプッシュ
オプティマイザが、包含する問合せブロックから関連する述語をビュー問合せブロックへ「押し込む」変換技法です。マージされないビューでは、この技法により、データベースが押し込まれた述語を使用して索引へアクセスしたり、フィルタとして使用したりできるため、マージされないビューのサブプランが改善されます。
詳細情報:
述語プッシュダウン
パフォーマンス向上のため、フィルタ述語を可能な限りデータソースの近くへ移動することです。
詳細情報:
射影ビュー
DISTINCT ビューがマージされた問合せ、または GROUP BY ビューが GROUP BY、HAVING、集計を含む外側の問合せブロックへマージされた問合せに現れる、オプティマイザ生成のビューです。
問合せリライト
ユーザーの問合せを、通常はマテリアライズド・ビューを使用してパフォーマンスを改善するため、意味的に等価な別の問合せへ自動的に変換するオプティマイザ機能です。
詳細情報:
単純ビュー・マージ
選択・射影・結合ビューをマージすることです。たとえば、ある問合せが employees 表を、departments 表と locations 表を結合する副問合せへ結合する場合です。
詳細情報:
スター型変換
パフォーマンス向上のため、スター・スキーマ結合をビットマップ索引ベースのフィルタリングへ書き換えます。ディメンション・キーにビットマップ索引が必要であり、初期化パラメータ star_transformation_enabled を TRUE に設定する必要があります。
詳細情報:
副問合せのネスト解除
オプティマイザがネストされた問合せを等価な結合文へ変換し、その結合を最適化する変換技法です。
詳細情報:
表拡張
パーティション表の読取り中心部分では索引を使用し、アクティブな部分では索引を使用しない計画を、オプティマイザが生成できるようにする変換技法です。
詳細情報:
変換
オプティマイザが SQL 文を、等価でありながらより効率的な形式へ書き換えるプロセスです。例として、ビュー・マージ、副問合せのネスト解除、述語プッシュダウンがあります。
詳細情報:
推移閉包
既存の述語に基づいて追加の述語を推論するために、オプティマイザが使用する問合せ変換技法です。
たとえば、A = B かつ B = C である場合、オプティマイザは A = C を推論できます。
この推論された条件は、特に結合削除、索引使用、パーティション・プルーニングにおいて、問合せパフォーマンスの最適化に使用できます。
ビュー・マージ
ビューを表す問合せブロックを、それを含む問合せブロックへマージすることです。ビュー・マージにより、オプティマイザは追加の結合順序、アクセス方式、その他の変換を考慮できるようになり、計画が改善される場合があります。
ビューをメイン問合せにマージすると、オプティマイザはそのビューを外側の問合せの一部として扱えるようになり、さらなる最適化が可能になります。
詳細情報:
ビュー包含
ビュー包含は、複数の表アクセスと結合を削減することで問合せパフォーマンスを改善することを目的とした、ヒューリスティックな問合せ変換技法です。可能かつ安全な場合に、複数のビュー内の計算を 1 つのインライン・ビューへ統合することで実現します。
データ処理とアクセスの最適化
アクセス・パス
Oracleオプティマイザが表からデータを取得するために使用する方法です。一般的なアクセス・パスには、全表スキャン、索引スキャン(一意、レンジ、スキップ)、クラスタ・スキャンなどがあります。
詳細情報:
ビットマップ索引
低カーディナリティの列向けに最適化された索引タイプです。
詳細情報:
ビットマップ結合索引
2 つ以上の表の結合に対するビットマップ索引です。
ビットマップ・ピース
単一のビットマップ索引エントリのサブコンポーネントです。索引付けされた各列値には、1 つ以上のビットマップ・ピースが含まれる場合があります。データベースはビットマップ・ピースを使用して、ブロックのサイズに対して大きい索引エントリを分割します。
近似問合せ処理
許容可能な誤差範囲内で結果を計算することにより、分析問合せを高速化する一連の最適化技法です。
詳細情報:
ブルーム・フィルタ
ブルーム・フィルタは、集合に要素が含まれるかどうかをテストするために使用される、メモリー使用量の少ないデータ構造です。ある要素が集合に含まれない場合は正しく判定できますが、集合に含まれると誤って判定する場合があります。したがって、偽陰性は発生しませんが、偽陽性は発生する可能性があります。ブルーム・フィルタは、フィルタを格納するために必要なメモリーがデータセット・サイズに比べて小さく、かつ大半のデータがメンバーシップ・テストに失敗すると想定される場合に特に有効です。
詳細情報:
Bツリー索引
上下逆さまの木のように編成された索引です。Bツリー索引には、検索のためのブランチ・ブロックと、値を格納するリーフ・ブロックという 2 種類のブロックがあります。リーフ・ブロックには、索引付けされたすべてのデータ値と、実際の行を特定するために使用される対応する rowid が含まれます。「B」は「balanced」を表します。すべてのリーフ・ブロックが自動的に同じ深さに保たれるためです。
詳細情報:
クラスタ・スキャン
表クラスタに対するアクセス・パスです。索引付き表クラスタでは、Oracle Database はまずクラスタ索引をスキャンして、選択された行の 1 つの rowid を取得します。その後、この rowid に基づいて行を特定します。
ダイレクト・パス読取り
単一ブロックまたはマルチブロック読取りを、プログラム・グローバル領域(PGA: クライアント・プロセスにローカルなメモリー領域)で直接処理するパフォーマンス最適化です。システム・グローバル領域(SGA)をバイパスすることで、データベース・ブロック処理の効率を高めます。
詳細情報:
外部キー
外部キーは、一方の表の列(または列グループ)と、別の表の主キーとの関係を宣言または強制することで、2 つの表を関連付ける制約です。
全表スキャン
データベースが表からすべての行を順次読み取り、選択条件を満たさない行を除外する表データのスキャンです。最高水位標より下にあるすべてのデータ・ブロックがスキャンされます。
使用可能な索引がない場合、または問合せ述語が表(または表パーティション)内の大きな割合の行に一致する場合に使用されます。
詳細情報:
ハッシュ・クラスタ
索引付きクラスタに似た表クラスタの一種ですが、索引キーがハッシュ関数に置き換えられています。個別のクラスタ索引は存在しません。ハッシュ・クラスタでは、データ自体が索引です。
ハッシュ・スキャン
表クラスタに対するアクセス・パスです。データベースはハッシュ・スキャンを使用して、ハッシュ値に基づいてハッシュ・クラスタ内の行を特定します。ハッシュ・クラスタでは、同じハッシュ値を持つすべての行が同じデータ・ブロックに格納されます。ハッシュ・スキャンを実行するために、Oracle Database はまず、文で指定されたクラスタ・キー値にハッシュ関数を適用してハッシュ値を取得し、その後、そのハッシュ値を持つ行を含むデータ・ブロックをスキャンします。
詳細情報:
索引
非クラスタ表、表パーティション、または表クラスタに関連付けられる任意のスキーマ・オブジェクトです。場合によって、索引はデータ・アクセスを高速化します。
索引は、1 つ以上の列の値に基づいて、表内の行へ高速にアクセスできるようにします。Oracle には、Bツリー索引、ビットマップ索引、ファンクション索引があります。
索引アクセス・パス
行を効率的に取得するために索引を使用して、データベースからデータを取得します。
詳細情報:
索引クラスタ
データを特定するために索引を使用する表クラスタです。クラスタ索引は、クラスタ・キー上の Bツリー索引です。
索引高速全スキャン
ディスク上に存在する順序のまま、未ソートで索引ブロックをスキャンすることです。このスキャンでは、表ではなく索引を読み取ります。
詳細情報:
索引フル・スキャン
索引全体をキー順にスキャンすることです。
詳細情報:
索引構成表
主 Bツリー索引の変種として編成される表です。ヒープ構成表とは異なり、データは主キー順に格納されます。
索引レンジ・スキャン
値の範囲について索引をスキャンすることです。不等号条件や範囲条件で一般的に使用されます。
詳細情報:
降順索引レンジ・スキャン
データベースが行を降順で返す索引レンジ・スキャンです。
索引スキップ・スキャン
複合索引の先頭列が「スキップ」される、または問合せで指定されていない場合に発生する索引スキャンです。たとえば、複合索引キーが (cust_gender,cust_email) であり、問合せ述語が cust_gender 列を参照していない場合です。
詳細情報:
索引一意スキャン
0 または 1 つの rowid を返す索引スキャンです。
詳細情報:
マルチブロック読取り
複数のデータベース・ブロックを読み取る I/O コールです。マルチブロック読取りは、全表スキャンを大幅に高速化できます。たとえば、データ・ブロックが 8 KB であっても、オペレーティング・システムは 1 回の I/O で 1024 KB を読み取れる場合があります。一部の問合せでは、オプティマイザが、128 個のデータ・ブロックを 128 回の連続 I/O で読み取るよりも、1 回の I/O で読み取る方がコスト効率が高いと判断する場合があります。
パラレル実行
単一のデータベース操作の実行に、複数の CPU および I/O リソースを適用することです。
詳細情報:
パラレル問合せ
複数のプロセスが同時に協調して単一の SQL 問合せを実行する問合せです。作業を複数のプロセスに分割することで、Oracle Database は文をより高速に実行できます。たとえば、1 つのプロセスが 1 年の 4 四半期すべてを処理する代わりに、4 つのプロセスがそれぞれ異なる四半期の行を取得します。
パフォーマンスを改善するために、問合せの一部を同時に実行します。
詳細情報:
主キー
表内の各行を一意に識別する列または列の組合せです。Oracle では、一意性は一意索引を使用して強制されます。
表クラスタ
1 つ以上の共通列を持つ 1 つ以上の表のデータを含むスキーマ・オブジェクトです。表クラスタでは、データベースは同じクラスタ・キーを共有するすべての表のすべての行をまとめて格納します。
一意索引
一意索引は、索引付けされた列(または列群)に対して一意性を強制する索引の一種です。
一般用語
バインド変数
SQL 文内のプレースホルダであり、その文を正常に実行するには、有効な値または値のアドレスで置き換える必要があります。バインド変数を使用すると、実行時に入力またはパラメータを受け取る SQL 文を記述できます。次の問合せでは、v_empid をバインド変数として使用しています。
SELECT * FROM employees WHERE employee_id = :v_empid;
子カーソル
親カーソルにテキストが格納されている文について、計画、コンパイル環境、その他の情報を含むカーソルです。親カーソルは番号 0、最初の子カーソルは番号 1、以降も同様です。子カーソルは親カーソルと同じ SQL テキストを参照しますが、別のものです。たとえば、“SELECT * FROM t” というテキストを持つ 2 つの問合せは、それぞれ異なる “t” という名前の表を参照している場合、異なるカーソルを使用します。
詳細情報:
カーソル
プログラム・グローバル領域(PGA: クライアント・プロセスにローカルなメモリー領域)内のプライベートSQL領域に対するハンドルまたは名前です。カーソルはプライベートSQL領域と密接に関連しているため、これらの用語は同義で使われることがあります。
共有SQL領域 を参照してください。
詳細情報:
カーソル・キャッシュ
共有SQL領域 を参照してください。
カーソル・マージ
共有SQL領域 の領域を節約するために、カーソルを結合することです。2 つの子カーソルが同一の計画とメタデータを共有している場合に、子カーソルの増加を抑え、同じ子カーソルを再利用します。
データ・ディクショナリ
表、索引、列、およびそれらの統計に関する情報を含む、データベースのメタデータを格納する表とビューの集合です。オプティマイザは、計画生成のための情報を収集する際にデータ・ディクショナリを問い合せます。
データ・フロー演算子(DFO)
パラレル問合せにおける、データ再分散ステージ間の作業単位です。
パラレル度(DOP)
単一の操作に関連付けられるパラレル実行サーバーの数です。パラレル実行は、複数の CPU を効果的に使用するように設計されています。Oracle Database のパラレル実行フレームワークでは、特定のパラレル度を明示的に選択することも、Oracle Database に自動制御を任せることもできます。
詳細情報:
動的パフォーマンス・ビュー
動的パフォーマンス表に基づいて作成されるビューです。動的パフォーマンス表は、現在のデータベース活動を記録する仮想表です。動的パフォーマンス・ビューは、データベース管理者が変更または削除できないため固定ビューとも呼ばれます。また、V$(Oracle Real Application Clusters では GV$)で始まるため、V$ビューとも呼ばれます。
詳細情報:
拡張可能オプティマイザ
ユーザー定義ファンクションやユーザー定義索引の作成者が、統計収集、選択性、コストの各ファンクションを作成できるようにするオプティマイザ機能です。オプティマイザは、実行計画を選択する際にこれらのファンクションを使用します。ユーザーから提供された情報を統合して CPU および I/O コストを評価できるよう、オプティマイザのコスト・モデルが拡張されます。
外部表
メタデータはデータベース内に格納されますが、データはデータベース外部のファイルに格納される読取り専用の表です。データベースは、外部表を記述するメタデータを使用して、そのデータをリレーショナル表であるかのように公開します。
詳細情報:
固定オブジェクト
動的パフォーマンス表またはその索引です。固定オブジェクトは SYS によって所有されます。固定オブジェクト表の名前は X$ で始まり、V$ビューのベース表です。
グローバル一時表(GTT)
特定の期間にわたって、セッション・プライベートな中間データを格納する特殊な一時表です。
ハード解析
アプリケーション・コードの新しい実行可能バージョンを構築するためにデータベースが実行するステップです。送信された文の解析済み表現が共有SQL領域に存在しない場合、データベースはソフト解析ではなくハード解析を実行する必要があります。
共有SQL領域 および ソフト解析 も参照してください。
ハッシュ衝突
複数の入力値が同じ出力値にハッシュ化されることです。
ハッシュ関数
任意長の入力値に対して処理を行い、固定長のハッシュ値を返すファンクションです。
ハッシュ表
ハッシュ結合において、結合キーと行を関連付けるメモリー内データ構造です。たとえば、employees 表と departments 表の結合では、結合キーは department ID である場合があります。ハッシュ関数は結合キーを使用してハッシュ値を生成します。このハッシュ値は、ハッシュ表である配列内のインデックスになります。
ハッシュ値
ハッシュ・クラスタにおいて、バケットを識別する一意の数値 ID です。Oracle Database は、無限個のハッシュ・キー値を入力として受け取り、それらを有限個のバケットへ分類するハッシュ関数を使用します。各ハッシュ値は、そのハッシュ・キー値(部門 10、20、30 など)に対応する行を格納するブロックのデータベース・ブロック・アドレスへマップされます。
ハッシュ処理
入力値の無限集合を、ハッシュ値と呼ばれる出力値の有限集合へマップする数学的技法です。ハッシュ処理は、ハッシュ表内のデータを高速に検索する場合に有用です。
ヒープ構成表
データ行がストレージ上で特定の順序を持たずに格納される表です。デフォルトでは、CREATE TABLE はヒープ構成表を作成します。
最高水位標
最高水位標(HWM)は、表、パーティション、索引などのセグメント内で、データ格納のためにこれまで使用または割り当てられた最も高い位置(またはブロック)を示すマーカーです。HWM は delete 操作では下がりませんが、SHRINK SEGMENT や TRUNCATE コマンドを使用すると下がる場合があります。
ハイブリッド・ハッシュ分散技法
最終的なデータ分散方式を実行時まで決定しない、適応型のパラレル・データ分散です。
暗黙問合せ
副問合せを使用せずにデータを取得する DML 文の構成要素です。明示的な SELECT 文を含まない UPDATE、DELETE、または MERGE 文は、変更対象の行を取得するために暗黙問合せを使用します。
インメモリー・スキャン
インメモリー列ストア(IM列ストア)から行を取得する表スキャンです。
キー・ベクトル
密な結合キーと密なグループ化キーの間をマップするデータ構造です。
ラッチ
システム・グローバル領域内の共有データ構造を同時アクセスから保護するために使用される、低レベルの直列化制御メカニズムです。
ライブラリ・キャッシュ
共有プール内のメモリー領域です。このキャッシュには、共有SQL領域、共有サーバー構成におけるプライベートSQL領域、PL/SQL プロシージャおよびパッケージ、ロックやライブラリ・キャッシュ・ハンドルなどの制御構造が含まれます。
詳細情報:
ライブラリ・キャッシュ・ヒット
ライブラリ・キャッシュ 内に見つかった SQL 文コードを再利用することです。
ライブラリ・キャッシュ・ミス
SQL 処理中に、ライブラリ・キャッシュ 内で使用可能な計画を検索したものの、それが見つからないことです。
親カーソル
SQL 文の SQL テキストおよびその他の最小限の情報を格納するカーソルです。子カーソルには、計画、コンパイル環境、その他の情報が含まれます。文が初めて実行されると、データベースは共有プール内に親カーソルと子カーソルの両方を作成します。
解析コール
SQL 文を実行できるように準備するための Oracle へのコールです。このコールには、SQL 文の構文チェック、最適化、その文の実行可能形式の構築または検索が含まれます。
解析
SQL 文を構成要素に分解し、構文とセマンティクスをチェックしたうえで、実行計画を生成するプロセスです。
パーティション索引
複数のセグメント(パーティション)に分割された索引です。各パーティションは、パーティション表の 1 つ以上のパーティションに対応します。
パーティション表 も参照してください。
パーティション表
パーティションと呼ばれる、より小さく管理しやすい単位に論理的に分割された表です。これらのパーティションにより、特に非常に大きな表において、問合せパフォーマンス、保守性、管理性を向上できます。
パーティション索引 も参照してください。
詳細情報:
パーティション・メンテナンス操作(PMOP)
表パーティションの追加、交換、マージ、分割などのパーティション関連操作です。
パーティション表 も参照してください。
プライベートSQL領域
解析済みの文および処理に必要なその他の情報を保持するメモリー領域です。プライベートSQL領域には、バインド変数値、問合せ実行状態情報、問合せ実行ワークエリアなどのデータが含まれます。
プロアクティブSQLチューニング
ユーザーがパフォーマンス問題を訴える前に、SQL チューニング・ツールを使用して、チューニング候補となる SQL 文を特定することです。
問合せ
表またはビューからデータを取得する操作です。たとえば、SELECT * FROM employees は問合せです。
問合せオプティマイザ
オプティマイザ を参照してください。
レスポンス時間
1 つの作業単位を完了するために必要な時間です。
結果セット
問合せにおいて、カーソルの実行によって生成される行の集合です。
Rowid
表内の行に対するグローバルに一意なアドレスです。
詳細情報:
行セット
実行計画内の 1 つのステップによって返される行の集合です。
行ソース
行の集合を反復的に処理し、行セットを生成する反復制御構造です。
行ソース・ジェネレータ
オプティマイザから最適計画を受け取り、SQL 文の実行計画を出力するソフトウェアです。
行ソース・ツリー
行ソース・ジェネレータによって生成される行ソースの集合です。SQL 文の行ソース・ツリーは、表の順序、アクセス方式、結合方法、フィルタやソートなどのデータ操作に関する情報を示します。
ルールベース・オプティマイザ(RBO)
データ特性に関係なく、事前定義された一連のルールに依存して実行計画を選択していた古い最適化方式です。CBO を優先する形で、ほぼ非推奨となっています。
サンプル表スキャン
単純な表、または結合やビューを含む文などの複雑な SELECT 文から、ランダム・サンプルのデータを取得するスキャンです。
サンプリング
表内の行のランダムなサブセットから統計を収集することです。
選択性
述語または述語の組合せによって取得される行セットの割合を示す値です。たとえば、WHERE last_name = ‘Smith’ などです。
「選択的」という形容詞は、おおよそ「選び抜く」という意味です。したがって、非常に選択性の高い問合せは低い割合の行を返し(選択性は 0 に近い)、選択性の低い問合せは高い割合の行を返します(選択性は 1 に近い)。
共有カーソル
複数の SQL 文で使用される 共有SQL領域 です。
共有プール
共有SQL領域などの共有メモリー構造を含む SGA の一部です。
詳細情報:
共有SQL領域
SQL 文の解析ツリーと実行計画を含む共有プール内の領域です。一意な文に対して共有SQL領域は 1 つだけ存在します。共有SQL領域はカーソル・キャッシュと呼ばれることもあります。
詳細情報:
スノーフレーク・スキーマ
ディメンション表が他の表を参照するスター・スキーマです。
スノーストーム・スキーマ
複数のスノーフレーク・スキーマを組み合わせたものです。
ソフト解析
ハード解析ではないすべての解析です。送信された SQL 文が共有プール内の再利用可能な SQL 文と同じである場合、Oracle Database は既存のコードを再利用します。このコードの再利用はライブラリ・キャッシュ・ヒットとも呼ばれます。
ソフト解析はハード解析よりも大幅に高速であり、システム CPU および I/O リソースの消費も少なくなります。
ハード解析 も参照してください。
SQLコンパイル
Oracle SQL 処理の文脈では、この用語は解析、最適化、計画生成の各フェーズを総称します。
SQL ID
特定の SQL 文について、ライブラリ・キャッシュ内の親カーソルを一意に識別する識別子です。SQL 文のテキストにハッシュ関数を適用することで SQL ID が生成されます。V$SQL.SQL_ID 列には SQL ID が表示されます。
SQLインシデント
Oracle Database の障害診断インフラストラクチャにおける、SQL 関連問題の 1 回の発生です。問題(重大エラー)が複数回発生すると、データベースは各発生についてインシデントを作成します。インシデントにはタイムスタンプが付与され、自動診断リポジトリ(ADR)で追跡されます。
SQL処理
SQL 文の解析、最適化、行ソース生成、実行の各段階です。
SQLテスト・ケース
一般的な問題や実行計画の問題を別の環境で再現できるようにする SQL 文および関連情報です。
SQLテスト・ケース・ビルダー も参照してください。
SQLテスト・ケース・ビルダー
SQL 文に関連する情報を収集し、ユーザーが別のデータベースで問題を再現できるようにパッケージ化するデータベース機能です。DBMS_SQLDIAG パッケージは、SQLテスト・ケース・ビルダーのインタフェースです。
詳細情報:
SQLトレース・ファイル
個々の SQL 文に関するパフォーマンス情報を提供する、サーバー生成のファイルです。たとえば、トレース・ファイルには parse、execute、fetch の回数、CPU 時間と経過時間、物理読取りと論理読取り、ライブラリ・キャッシュでのミスなどが含まれます。
詳細情報:
SQLチューニング
測定可能な目標を満たすように SQL 文の効率を改善するプロセスです。
SQLチューニング・アドバイザ
Oracle 内の診断ツールであり、SQL 文を分析してパフォーマンスを改善するための推奨事項を提供します。多くの場合、新しい索引、SQL の書換え、または統計の更新を提案します。
詳細情報:
SQLチューニング・セット(STS)
1 つ以上の SQL 文と、それらの実行統計および実行コンテキストを含むデータベース・オブジェクトです。
詳細情報:
スター・スキーマ
ディメンショナル・データ・モデルを表す設計のリレーショナル・スキーマです。スター・スキーマは、1 つ以上のファクト表と、外部キーを通じて関連付けられる 1 つ以上のディメンション表で構成されます。
スループット
システムが一定時間内に実行できる作業量です。通常、1 秒あたりのトランザクション数または 1 秒あたりの SQL 文数で測定されます。