Introduction
I am often asked, “How does Oracle choose which columns need a histogram?” Also, “Why have I got a histogram on my primary key column?” Jonathan Lewis posted an explanation in response to the latter question some while ago, but I thought I’d cover a little bit more on this topic and focus on how Oracle chooses which columns should have histograms. In particular, I want to clarify how the database determines what histograms to create if you use the recommended (default) method for gathering statistics, which is where the DBMS_STATS.GATHER…STATS parameter METHOD_OPT is set to ’FOR ALL COLUMNS SIZE AUTO’.
The Oracle Database can create a variety of different types of histogram (hybrid, top frequency, frequency) and I will mention them briefly below. However, for the purposes of this post it is not necessary to dwell on the differences between them. I want instead to concentrate on the circumstances that lead to histogram creation in general.
This post is aimed at Oracle Database 12c Release 1 onwards.
You will probably know already that histograms are useful for improving cardinality estimates, particularly if the data in a column is skewed. As you will see, this is not the full story, but I will start by covering what is meant by skew.
What is Skew?
There are two types of skew considered by the database. For most of us, there is one type that springs to mind. Here is a chart representing how many order entries a pet shop has for each type of fish it sells:
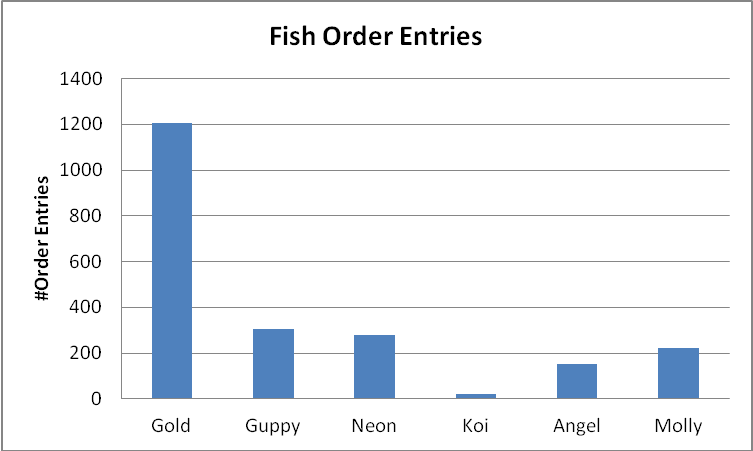
The shop gets a lot of orders for goldfish; they are cheap and common. On the other hand, Koi carp are highly valued and expensive so it’s not surprising that fewer are sold. Technically speaking, there is a non-uniformity in the repetitions of values or value skew. In other words, some fish names appear significantly more often than others. Let’s take a look at a couple of simple queries:
select sum(order_amount) from fish_sales where fish = 'Gold'; [1200 rows match] select sum(order_amount) from fish_sales where fish = 'Koi'; [22 rows match]
For the above queries, the number of rows matching the WHERE clause are very different so it would be useful to give the optimizer a way to figure this out. That is what a histogram is for of course.
There is another type of skew, and I will illustrate it with a few examples.
Example 1
Imagine a small but fast-growing company that is hiring new people over time. Employee information is stored in a STAFF table, which includes a HIRE_DATE column. Back in the days when the company started up it was common for a number of weeks to pass between each new hire, but gradually the rate of arrival increased. For any given day we can plot the number of people hired like this:
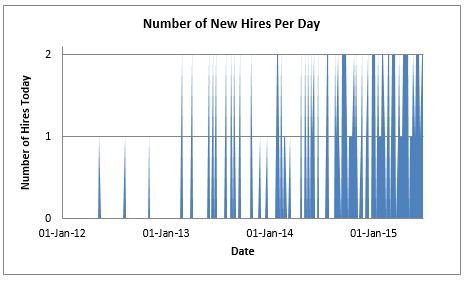
I generated the plot above using a query like this:
select trunc(hire_date) "Date" ,count(*) "Number of Hires Today" from staff group by trunc(hire_date) order by trunc(hire_date);
You will see that a large number of days passed in 2012 with no hires, but in 2015 there were multiple people joining almost every day. There is a wide variation in the number of rows the database will match in the STAFF table for a given range of hire dates. Technically speaking, there is a non-uniformity in range or range skew. To clarify what I mean, consider the following queries:
select avg(salary) from staff where hire_date
between to_date('01-mar-2012') and to_date('30-apr-2012');
select avg(salary) from staff where hire_date
between to_date('01-mar-2014') and to_date('30-apr-2014');
The first query will match a small number of rows and the second will match a large number of rows even though the size of the range is the same in both cases (I was careful to avoid including February since 2012 is a leap year!). We need to help the optimizer figure out that if a query filters rows over a given range of HIRE_DATE values, then it can expect to see a wide variation in the number of rows it will match. We are going to need a histogram.
There is value skew in this example too. I mention this fact because I want to point out that range and value skews are not mutually exclusive: column values can sometimes exhibit both types of skew to varying degrees.
Example 2
Perhaps the simplest way to see range skew is to consider a column containing unique numeric values like this:
1, 100, 200, 300, 301, 302, 303, 304,…, 998, 999, 1000
Each value happens only once but the numbers of values falling into the range of (1,100) is very different from those falling into range of (300, 400) and (400, 500). This is similar to Jonathan’s example mentioned above.
Example 3
When considering numeric or date columns, it is easy to visualize range skew in terms of missing values or days. For character-based fields it is not so intuitive. Personally, I like to think of range skew in terms of how many rows will match a range predicate if we take a fixed range and ‘slide it up and down’ the dataset. Consider the following (real) example: a table containing a list of US surnames. Range skew is easily revealed like this:
select count(*) from us_surnames where surname between 'A' and 'C'; [19281 rows] select count(*) from us_surnames where surname between 'H' and 'J'; [9635 rows] select count(*) from us_surnames where surname between 'X' and 'Z'; [1020 rows]
Example 4
Finally, it is not always quite as obvious as example 3 implies. Consider a dataset like this:
AA, AB, AC, AD,…,AZ, BA, BB, BC,…, ZX, ZY, ZZ
It doesn’t look like there are any gaps at all, but remember that there are non-alphabet characters and we could use longer and shorter strings in the range predicates. Both of the following queries return a count of zero:
select count(*) from the_table where column_value between 'B1' and 'B9';
select count(*) from the_table where column_value between 'AZB' and 'B';
A histogram will yield better cardinality estimates because it will make the optimizer aware of these gaps. The database encodes column values and uses statistical techniques to characterize the degree of variation in cardinality estimates when a range-based query predicate is used. Once this analysis is complete, internal thresholds are used to decide whether or not a histogram will be useful.
The net result is that text-based columns will often acquire histograms if they are used in range-based query predicates.
Automatic Histogram Creation
Histograms are created automatically when statistics are gathered using the SKEWONLY and AUTO options in METHOD_OPT. For example:
EXEC DBMS_STATS.GATHER_TABLE_STATS( … METHOD_OPT=>'FOR ALL COLUMNS SIZE SKEWONLY' …)
If you choose to use FOR ALL COLUMNS SKEWONLY, then all columns will need to be tested to see if they require a histogram (excluding columns with datatypes such as LONG and CLOB). This is not the best choice for day-to-day statistics collection because there is a more efficient option (which also happens to be the default):
EXEC DBMS_STATS.GATHER_TABLE_STATS( … METHOD_OPT=>'FOR ALL COLUMNS SIZE AUTO' …)
AUTO uses column usage information to identify which columns are used in query predicates and joins, making them potential candidates for a histogram. When statistics are gathered, the candidate columns are tested further to identify skew and calculate the number of distinct column values. Restricting these tests to an initial list of candidates will, in many cases, make AUTO much more efficient than SKEWONLY.
For the remainder of this post you can assume that ‘FOR ALL COLUMNS SIZE AUTO’ is used. In addition, remember that some column datatypes are not eligible for histograms (such as LONG and CLOB).
Column Usage
How does the Oracle Database know that a particular column is used in a query predicate or join? This information is gathered by the Oracle Optimizer at parse time and ultimately stored in the Oracle data dictionary in a table called SYS.COL_USAGE$.
We can get a user-friendly view of column usage data using the DBMS_STATS API. In the following example, the report tells us that the HIRE_DATE column in STAFF was used in a range predicate:
set long 10000 select dbms_stats.report_col_usage(user, 'staff') from dual;
DBMS_STATS.REPORT_COL_USAGE(USER,'STAFF') -------------------------------------------------------------------------------- LEGEND: ....... EQ : Used in single table EQuality predicate RANGE : Used in single table RANGE predicate LIKE : Used in single table LIKE predicate NULL : Used in single table is (not) NULL predicate EQ_JOIN : Used in EQuality JOIN predicate NONEQ_JOIN : Used in NON EQuality JOIN predicate FILTER : Used in single table FILTER predicate JOIN : Used in JOIN predicate GROUP_BY : Used in GROUP BY expression ............................................................................... ############################################################################### COLUMN USAGE REPORT FOR ADHOC.STAFF ................................... 1. HIRE_DATE : RANGE ###############################################################################
If you want to test this for yourself, then note that column usage data is flushed to the data dictionary periodically, so if you are using a test script then you might not see the data immediately. If you are in a hurry, you can initiate a manual flush like this:
execute dbms_stats.flush_database_monitoring_info()
Identifying Candidate Columns
We have established that the database has a way of determining how individual columns are used in queries. A column is considered a candidate for a histogram if it is used in joins or query predicates. For example, the following queries will make col1 and txtcol potential candidates for histograms:
Query: Column usage: select sum(amount) from sales where col1 = 10; [EQ] select sum(amount) from sales where col1 != 10; [recorded as EQ] select sum(amount) from sales where col1 > 10; [RANGE] select sum(amount) from sales s, customers c where s.col1 = c.col1; [EQ_JOIN] select sum(amount) from sales s, customers c where s.col1 != c.col1; [EQ_JOIN NONEQ_JOIN] select sum(amount) from sales where txtcol like 'ALA%'; [LIKE]
Once column usage information has been used to identify candidate columns, the database needs to examine the data in those columns to establish whether a histogram will be useful for improving cardinality estimates. This happens when statistics are gathered (e.g. when using DBMS_STATS.GATHER_TABLE_STATS), but what principles does the database use to finally decide? I will cover that next.
Beneficial Histograms
The database applies some principles to decide whether a histogram will be of benefit. A histogram will be deemed beneficial if:
- The column has value skew and column usage indicates RANGE, LIKE, EQ or EQ_JOIN.
- The column has range skew and column usage indicates LIKE or RANGE.
- The column has a low number of distinct values (with some repeated values) and column usage indicates RANGE, LIKE, EQ or EQ_JOIN.
- When incremental statistics are used, and even though a column might not have value/range skew in a partition, a histogram may be created. The database will use partition-level histograms to derive global histograms. Histograms created for non-skewed data are ignored by optimizer stats.
You will see that there is overlap between principles 1 and 3, and there is no mention of skew in number 3. The reason is that Oracle considers histograms useful for low number of distinct value (NDV) columns even if there is no significant range or value skew (provided that there are some repeated values). A typical benefit of doing this is in the case where a data distribution is quite uniform in both value and range but there are nevertheless some “holes” in values. The cost of building histograms on low cardinality columns is small, so if a column is used in joins or predicates then there is little reason not to create one. In practice this means that a column with usage RANGE, LIKE, EQ or EQ_JOIN columns and an NDV of less than or equal to 254 will be given a frequency histogram (or even a top frequency histogram if the NDV is a little over 254).
The number 254 is significant because it is the default histogram bucket count and is one of the factors taken into account when choosing the type of histogram used. There is more on this here.
There is some additional complexity I have not covered. For example, histograms may be created from a partial or full sample of the data (depending on how and when statistics are gathered). Datatypes can be important. For example, if you use a LIKE predicate on a numeric column, then this type of usage will not be recorded in column usage. The boundary between “skewed” and “non-skewed” is a statistical construct (or, if you prefer, a “fuzzy” construct) and column values can have both range skew and value skew. Nevertheless, I hope that you now appreciate the general principles at work.
Comments welcome.
