Introduction
It’s common to have multi-terabyte partitioned tables in an Oracle database these days. If you are not there yet but you’re heading that way, then you need to know about how to maintain statistics on large tables. I will cover this in a series of posts as follows:
- Part 1 (this post) – Concepts and implementation
- Part 2 – Incremental statistics and partition exchange loading
- Part 3 – New to Oracle Database 12c Release 2
There are some additional details and some overlap with an earlier Optimizer blog post, so you should check that out too.
Concepts
What statistics are there on partitioned tables?
Consider a partitioned table called SALES that has date-range partitions for financial quarters 1 and 2 (Q1 and Q2). The partition key is on the column QUARTER. The database gathers statistics for individual partitions so that cardinality can be estimated for queries that are pruned to a single partition. These are called partition-level statistics. To illustrate this with an example, I’m going to consider just a couple of statistics and ignore the others. The number of rows in Q1 and Q2 are 600 and 550 respectively. The number of distinct values (NDVs) for SALE_TYPE in Q1 is 30 and Q2 it’s 50:
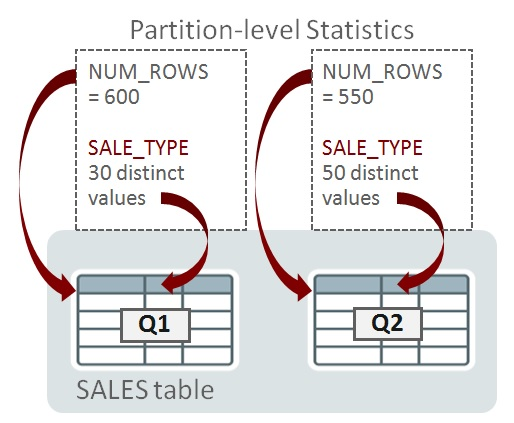
When a query is compiled, if the Oracle Optimizer determines that it will need to access a single partition (using partition pruning, for example) then the statistics at the partition-level will be enough to help determine the execution plan. Here’s a query that reads Q1 only:
SELECT SUM(amount) FROM sales WHERE quarter = 'Q1' AND sale_type = 'DIRECT';
If the Optimizer determines at compile-time that a query has the potential to access more than one partition, then individual partition statistics are not enough. In the next example, the query needs to access more than one partition:
SELECT SUM(amount) FROM sales WHERE sale_type = 'DIRECT';
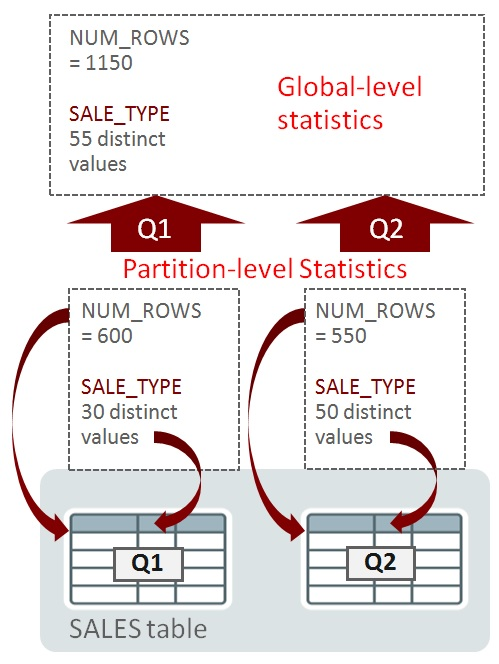
For queries that might access multiple partitions, the Optimizer must consider statistics at the table level. These statistics are known as global-level statistics:
You will know that the Oracle database can further subdivide partitions into subpartitions; a feature known as composite partitioning. For now I’m only going to talk about partitions, and later on I’ll say something about subpartition statistics.
How does Oracle manage statistics information at the partition and table level?
Now that we have established the need for both partition and table level statistics, how does Oracle collect them? Can the table-level statistics be derived from partition-level statistics?
It is very easy to derive NUM_ROWS at the global level from individual partitions; simply sum NUM_ROWS for each partition (e.g. 600+550=1150 in the example). Unfortunately, it isn’t that simple for the number of distinct values (denoted as NDVs). In the example above, the NDV for SALE_TYPE at the global level (55) can’t be calculated using the values 30 and 50 at the partition-level. There’s insufficient information: the basic values 30 and 50 don’t tell us anything about the overlap of SALE_TYPE values in Q1 and Q2. Consider two identical tables, TAB1 and TAB2 that contain difference SALE_TYPE values in Q1 and Q2 partitions:
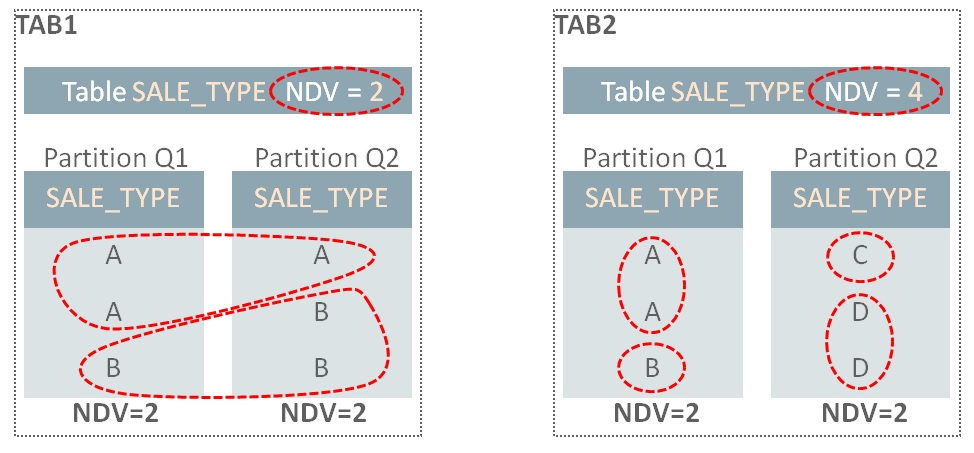
In TAB1, the Q1 partition has SALE_TYPE values A and B, so the NDV is 2. Q2 has the same values, A and B, so the overall table NDV is 2. In the TAB2 case, there is no overlap in values between Q1 and Q1, so even though the partition NDV values are also 2, the overall NDV is 4.
To calculate the global-level NDV value, the database must examine all table partitions (assuming that we don’t have some additional information at our disposal). This can become very time-consuming as tables grow large, especially if there are hundreds or thousands of partitions.
Synopses to the rescue
How does the Oracle Database resolve this problem? Tables can be configured to instruct the statistics gathering procedures to store additional information about each individual partition. Each table partition has a new data structure called a synopsis. Collectively, these structures are called synopses.
If data changes in one partition, there is no need to read to contents of all other partitions when recalculating the global-level NDV values. In the following example, change has been made to the data in Q2 (the star symbols indicate where change is occurring). When statistics are re-gathered, there is no need to read the contents of the Q1 partition because the information contained in the Q1 and Q2 synopses can be used instead:
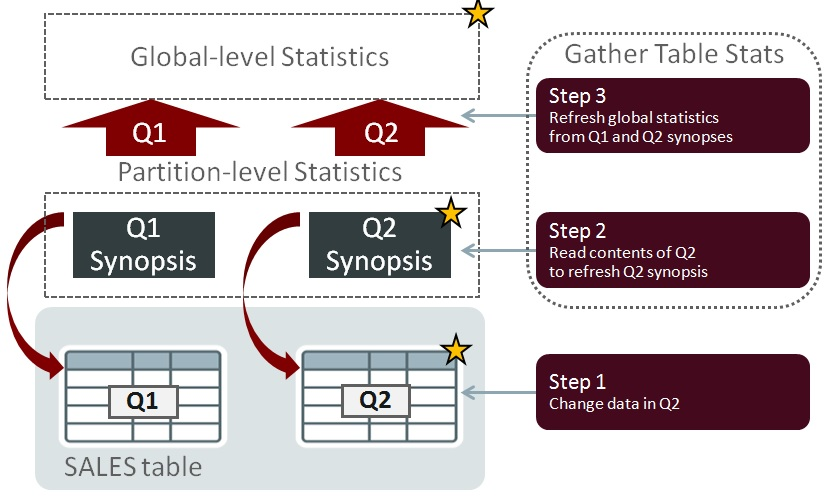
Synopses allow the database to maintain accurate table statistics in a scalable manner: as tables grow in size and the number of partitions increases, the performance benefit of this feature will become more apparent.
Synopses storage
Synopses are maintained automatically by the database. They store additional information in the SYSAUX tablespace about the data stored in every table partition. For tables with large numbers of columns and high NDVs, the amount of data can become large so space usage in SYSAUX should be monitored. Statistics gathering procedures must maintain the synopsis information so this can add a performance overhead for some operations. I will return to this topic in Part 3 of this series.
Staleness and DML Change
If statistics are not gathered periodically and if the data in the database changes over time, then statistics will be out of date and potentially stale and inaccurate. Statistics need to be accurate to generate good SQL execution plans so the database must detect when they are stale. It does this by tracking the number of DML row insert, update and delete operations for tables, partitions and sub-partitions. Once the number of DML operations exceeds a certain threshold the statistics status for the table, partition or sub-partition is changed to stale.
By default, incremental maintenance does not use the staleness status to decide when to update statistics. This scenario is covered in an earlier blog post for Oracle Database 11g. If a partition or sub-partition is subject to even a single DML operation, statistics will be re-gathered, the appropriate synopsis will be updated and the global-level statistics will be re-calculated from the synopses. This behavior can be changed in Oracle Database 12c, allowing you to use the staleness threshold to define when incremental statistics will be re-calculated. This is covered in Staleness and DML thresholds, below.
Implementation
Enabling synopses
To enable the creation of synopses, a table must be configured to use incremental maintenance. This feature is switched on using a DBMS_STATS preference called ‘INCREMENTAL’, and you might need to set ‘INCREMENTAL_LEVEL’ too. For example, for a table called SALES:
EXEC dbms_stats.set_table_prefs(null,'SALES','INCREMENTAL','TRUE')-- The default INCREMENTAL_LEVEL in non-Autonomous databases is PARTITION,
-- but you can check your database like this
select dbms_stats.get_prefs(pname=>'INCREMENTAL_LEVEL') from dual;-- If the query above returns an INCREMENTAL_LEVEL that is not
-- PARTITION, configure your table like this
EXEC dbms_stats.set_table_prefs(null,'SALES','INCREMENTAL_LEVEL','PARTITION')The value of the DBMS_STATS preferences can be checked as follows:
SELECT dbms_stats.get_prefs(pname=>'INCREMENTAL', tabname=>'SALES'),
dbms_stats.get_prefs(pname=>'INCREMENTAL_LEVEL', tabname=>'SALES')
FROM dual;As mentioned above, Optimizer statistics are considered stale when the number of changes made to data exceeds a certain threshold. This threshold is expressed as a percentage of row changes for a table, partition or subpartition and is set using a DBMS_STATS preference called STALE_PERCENT. The default value for stale percent is 10 so, for example, a partition containing 100 rows would be marked stale if more than 10 rows are updated, added or deleted. Here is an example of setting and inspecting the preference:
EXEC dbms_stats.set_table_prefs(null, 'SALES', 'STALE_PERCENT','5')
select dbms_stats.get_prefs('STALE_PERCENT',null,'SALES') from dual;
It is easy to check if a table or partition has been marked as stale:
select partition_name, subpartition_name, stale_stats /* YES or NO */ from dba_tab_statistics where table_name = 'SALES';
The database tracks DML operations to measure when data change has caused a table to exceed its staleness threshold. If you want to take a look at this information, bear in mind that the statistics are approximate and they are autmatically flushed to disk periodically. If you want to see the figures change immediately during your tests then you will need to flush them manually (you must have ‘ANALYZE ANY’ system privilege), like this:
EXEC dbms_stats.flush_database_monitoring_info
select *
from dba_tab_modifications
where table_name = 'SALES';
Remember that if you are using incremental statistics in Oracle Database 11g, a single DML operation on a partition or sub-partition will make it a target for a statistics refresh – even if it is not marked stale. In other words, we might update one row in a partition containing 1 million rows. The partition won’t be marked state (if we assume a 10% staleness threshold) but fresh statistics will be gathered. Oracle Database 12c exhibits the same behavior by default, but this release gives you the option to allow multiple DML changes to occur against a partition or sub-partition before it is a target for incremental refresh. You can enable this behavior by changing the DBMS_STATS preference INCREMENTAL_STALENESS from its default value (NULL) to ‘USE_STALE_PERCENT’. For example:
exec dbms_stats.set_global_prefs('INCREMENTAL_STALENESS', 'USE_STALE_PERCENT')
Once this preference is set, a table’s STALE_PERCENT value will be used to define the threshold of DML change in the context of incremental maintenance. In other words, statistics will not be re-gathered for a partition if the number of DML changes is below the STALE_PERCENT threshold.
Locking statistics
Incremental statistics does work with locked partitions statistics as long as no DML occurs on the locked partitions. However, if DML does occurs on the locked partitions then we can no longer guarantee that the global statistics built from the locked statistics will be accurate so the database will fall back to using the non-incremental approach when gathering global statistics. However, if for some reason you must lock the partition level statistics and still want to take advantage of incremental statistics gathering, you can set the ‘INCREMENTAL_STALENESS’ preference to include ‘USE_LOCKED_STATS’. Once set, the locked partitions/subpartitions stats are NOT considered as stale as long as they have synopses, regardless of DML changes.
Note that ‘INCREMENTAL_STALENESS’ accepts multiple values, such as:
BEGIN
dbms_stats.set_table_prefs(
ownname=>null,
tabname=>'SALES',
pname =>'INCREMENTAL_STALENESS',
pvalue=>'USE_STALE_PERCENT, USE_LOCKED_STATS');
END;
/
Checking for staleness
You can check for table/partition/subpartition staleness very easily using the statistics views. For example:
EXEC dbms_stats.flush_database_monitoring_info
select partition_name,subpartition_name,stale_stats from dba_tab_statistics where table_name = 'SALES' order by partition_position, subpartition_position;
Database monitoring information is used identify stale statistics, so you’ll need to call FLUSH_DATABASE_MONITORING_INFO if you’re testing this out and you want to see immediately how the staleness status is affected by data change.
Checking for Synopses
Oracle Support maintains Note 1953961.1 which includes a query that lists objects with synopses.
Gathering statistics
How do you gather statistics on a table using incremental maintenance? Keep things simple! Let the Oracle Database work out how best to do it. Use these procedures:
EXEC dbms_stats.gather_table_stats(null,'SALES') or EXEC dbms_stats.gather_schema_stats(…) or, even better EXEC dbms_stats.gather_database_stats()
For the DBMS_STATS.GATHER… procedures you must use ESTIMATE_PERCENT set to AUTO_SAMPLE_SIZE. Since this is the default, then that is what will be used in the examples above unless you have overriden it. If you use a percentage value for ESTIMATE_PERCENT, incremental maintenance will not kick in.
Regathering statistics when data hasn’t changed
From time-to-time you might notice that statistics are gathered on partitions that have not been subject to any DML changes. Why is this? There are a number of reasons:
- Statistics have been unlocked.
- Table column usage has changed (this is explained below).
- New columns are added. This includes hidden columns created from statistics extensions such as column groups, column expressions.
- Synopses are not in sync with the column statistics. It is possible that you have gathered statistics in incremental mode at time T1. Then you disable incremental and regather statistics at time T2. Then the synopses’ timestamp T1 is out of sync with the basic column statistics’ timestamp T2.
- Unusual cases such as column statistics have been deleted using delete_column_statistics.
Bullet point “2” has some implications. The database tracks how columns are used in query predicates and stores this information in the data dictionary (sys.col_usage$). It uses this information to help it figure out which columns will benefit from a histogram to improve query cardinality estimates and, as a result, improve SQL execution plans. If column usage changes and you are using METHOD_OPT with ‘SIZE AUTO’, then the database might choose to re-gather statistics and create a new histogram. It will be rare event and will eventually cease, but I know that some customers like to prevent this possibility by specifying histograms fully:
dbms_stats.set_table_prefs (null, 'SALES', 'METHOD_OPT','FOR ALL COLUMNS SIZE 1 FOR COLUMNS SIZE 254 CUST_ID'); dbms_stats.set_table_prefs (null, 'SALES', 'METHOD_OPT','FOR ALL COLUMNS SIZE 1');
If you do this, then you should request and apply patch 31464691 for your platform. This is necessary to ensure that the histogram check operates reliably when METHOD_OPT is set via a DBMS_STATS table preference (otherwise partition statistics may be regathered too frequently).The patch is not required if you are not using a table preference for the relevant table, but have instead disabled histograms using a global DBMS_STATS METHOD_OPT setting.
Locally partitioned index statistics
For locally partitioned index statistics, we first check their corresponding table partitions (or subpartitions). If the table (sub)partitions have fresh statistics and the index statistics have been gathered after the table (sub)partition-level statistics, then they are considered fresh and their statistics are not regathered.
Composite partitioned tables
Statistics at the subpartition level are gathered and stored by the database, but note that synopses are created at the partition level only. This means that if the statistics for a subpartition become stale due to data changes, then the statistics (and synopsis) for the parent partition will be refreshed by examining all of its subpartitions. The database only regathers subpartition-level statistics on subpartitions that are stale.
More information
There is more on this topic in the Database SQL Tuning Guide.
Please feel free to post questions and comments.
