Introduction
Should you gather system statistics? If you deploy Oracle Databases then you will have an opinion on the answer, but what does Oracle recommend? Before I get to that, I’ll present a brief survey of existing Oracle collateral and then cover how systems statistics affect SQL execution plans. If you want to skip directly to the point, then check out the recommendation section, below.
A Brief Survey of Existing Recommendations
Oracle white papers and documentation include some recommendations, but there are some differences and there has been some variation over time. Oracle introduced DBMS_STATS.GATHER_SYSTEM_STATS back in 2001 with Oracle Database 9i and in the Database Performance Guide and Reference it clearly states that gathering system statistics is highly recommended. Later versions of the documentation have been, until recently, a little more equivocal. Oracle added an EXADATA option to take into account the characteristics of Oracle Exadata Database Machines.
Oracle Optimizer white papers, on the other hand, recommend using system statistics defaults and not gathering them manually. Recent updates to the documentation have aligned with this message. If systems statistics are not gathered, the optimizer measures CPU speed when the database starts and IO costing is calculated using default metrics.
How System Statistics Affect SQL Execution Plans
The concept behind system statistics is to measure the performance of system CPU and the storage subsystem (such as NAS, SAN, JBOD or flash) and use this information when costing alternative SQL execution plans.
A query consumes CPU and (in many cases) storage resources when it executes. A typical query will have many potential SQL execution plans and each plan may consume a different proportion of CPU versus storage IO. The Oracle Optimizer’s job is (broadly speaking) to find the plan that is estimated to take the least amount of time to execute. In reality, it compares alternative plans using an internal metric called cost. The optimizer chooses the plan with the lowest estimated cost (out of all the plans it considers). If the database knows how fast storage and CPU actually is, then it can make finer judgements about the cost of each alternative plan.
Consider a query that has three possible plans. Each plan uses a different amount of CPU and IO. The diagram below illustrates that Plan 1 is expected to use a large amount of CPU and very little IO. For the sake of this example, we will assume that Plan 1 is deemed to have the lowest estimated cost and has duly been chosen by the optimizer.
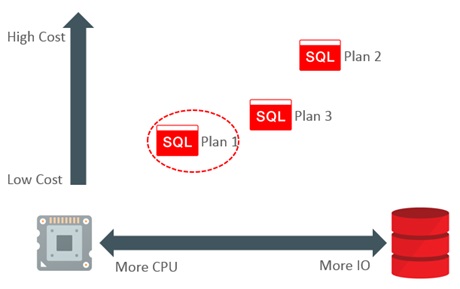
Consider now a system that has a particularly high performance storage infrastructure. It has the potential to shift the relative performance balance between the CPU and IO. Gathering system statistics will allow the optimizer to take this into account. In our example, the presence of high performance storage lowers the relative cost of Plan 2 and Plan 3 significantly, and Plan 1 by a small amount (because it uses less IO). This shift is enough to make Plan 3 the best choice; it now has the lowest estimated cost.
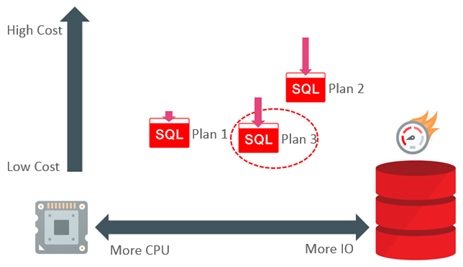
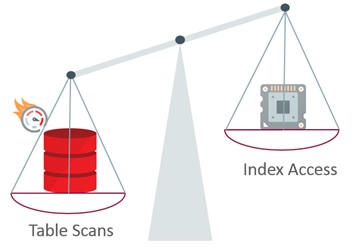
On systems with fast IO infrastructure, we can expect the use of system statistics to tip the balance a little towards using table scans in preference to indexes.
Recommendation
If gathering system statistics benefits your workload and you are happy to manage them, then you have no reason to change. Alternatively, if you are at a decision point and you need to choose whether to gather them or not, then in most cases you should use the defaults and not gather system statistics.
There is an exceptional case to consider. Databases supporting a pure data warehouse workload on an Oracle Exadata Database Machine can benefit from system statistics gathered using the EXADATA option. It will make table scans more likely and, of course, this plays directly into one of the architecture’s major strengths. Nevertheless, if the workload is mixed or you are not in a position to test the effect of using EXADATA system statistics, then stick to the defaults even on this platform.
It is important to remember that if you change the way you use system statistics, then this can affect SQL execution plans. For this reason, you should only make a change if you are at a decision point and you are able to test the effect of the change (or at least in a position to mitigate the risk of undesirable changes in workload performance).
Justifying the Recommendation
The recommendation is always going to be controversial. I am well aware that some DBAs and architects are very happy using system statistics and consider them highly beneficial. There is nothing wrong with this position and there are undoubtedly cases where system statistics have tipped the balance and improved the performance of some queries. However, this tipping-point is not in the same place for all queries, so it is quite possible that it will not work out well for some. It is also possible that a particular set of system statistics will not benefit all workloads handled by the database (such as ETL/ELT and OLTP). The net result is that gathering system statistics is unlikely to be the silver bullet that delivers ideal performance across the board in a consistent manner: you might still have to tune some queries. Of course, you probably never expected system statistics to be a silver bullet, but there is at least some management or procedural overhead required to maintain them and, depending on how you use them, they can introduce some variability in SQL execution plans (between different systems or over time on a single system). The recommendation allows you to avoid potential plan variability and management overhead.
If you are testing a workload where gathering system statistics has improved performance, it is worth spending some time to find out why. It is unlikely that there has been an across-the-board improvement. It is more likely that the performance of a small number of significant queries has improved or there are perhaps there are a group of queries with a common pattern (maybe accessing a particular set of tables or using a particular combination of predicates). You might find that it is better to free yourself from managing system statistics and, instead, use the tools that Oracle provides you with to tune the queries that are not performing as well as you want.
To the best of my knowledge, relevant MOS notes and the docs have been aligned with this message. If you spot anything contradicting this, then please post a comment.
All comments welcome!
