The In-Memory column store (IM column store) is a store and not a cache. We’ve talked about this in various blog posts:
- In-Memory Column Store versus the Buffer Cache
- Memory Usage with Oracle Database In-Memory
- Ask TOM Office Hours Demo – Why Are Column Store Scans Faster Than Row Store Scans
- Oracle Database In-Memory Population
This topic came up again recently when a colleague was speaking with a potential customer. I know from personal experience that many times when I’m speaking with customers, or at a conference, I find that people think that Database In-Memory is similar to the buffer cache. I have even heard other speakers refer to the IM column store as a cache, and I always cringe since I think we’ve worked hard at trying to convey that the IM column store is not a cache. I’m sure part of the problem is the idea of “in-memory” in general. I think most people think of in-memory computing as being another way to “cache” an entire working set.
What do I mean when I say that the IM column store is not a cache? Database In-Memory will populate an entire segment, assuming there is enough space, in the IM column store and that object won’t be removed unless the instance goes down, an ALTER TABLE … NO INMEMORY command is issued, an ADO policy acts on it, or AIM decides to evict it. This is fundamentally different than how a cache works, a good example being the database buffer cache.
As Maria described in her In-Memory Column Store versus the Buffer Cache post, “Standard caches such as a buffer cache rely on non-uniform access patterns that are common in OLTP applications. Some rows within a table are accessed much more frequently than other rows. That is why you can have a buffer cache that is 10% the size of a table but that captures 95% of the random (OLTP) accesses to the table.”
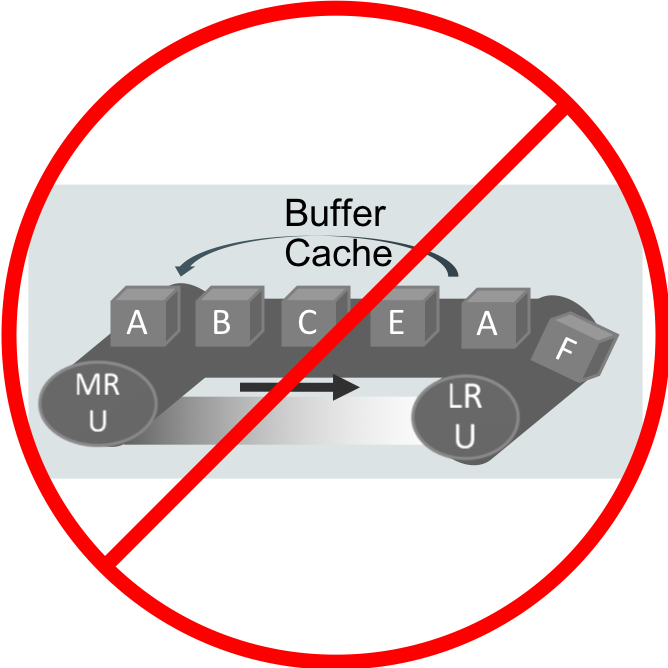
However, that’s not how Database In-Memory works. With Database In-Memory an entire object is populated into the IM column store. It is possible that the object being populated won’t fit, in which case subsequent queries will access the data that has been populated in the IM column store and then the rest of the data from the row store. But the intent is that the entire object will be populated and will stay populated.
The reason for this is that Database In-Memory is targeted at analytic queries and analytic queries need to access all of the values in the columns accessed by the query in order to look for patterns or trends in that data. Since all of the column values will be accessed it makes sense that the best performance will be obtained by having all of the data in-memory. This is fundamentally different than how a cache works.
When an object is populated into the IM column store it is changed from a row format into a columnar format, it is compressed for optimized scan performance and In-Memory storage indexes are created. This allows access to the object in the IM column store to take full advantage of all of the features of Database In-Memory like predicate push down and aggregations, SIMD vector processing, hash joins with Bloom filters, In-Memory Aggregation, In-Memory Expressions, Join Groups, and all of the other great features that have been added to speed up analytic queries in Database In-Memory.
Original publish date: July 31, 2018
