It’s been a while since I’ve had an opportunity to share a technical blog post but now that OpenWorld has wrapped up for another year it’s time to get back to the techie details of Oracle Database In-Memory.
Up until now, we’ve focused on queries that scan only one table. Let’s broaden the scope of our investigation to include joins and parallel execution. In this post I’ll show a series of queries that begin with a single join between a fact table, LINEORDER, and a dimension table DATE_DIM and work up to a multi-table join.
Let’s begin with the simplest join query, a join between the fact table LINEORDER and the dimension table DATE_DIM. This is a “What if” style query that calculates the amount of revenue increase that would have resulted from eliminating certain company-wide discounts in a given percentage range for products shipped on a given day (Christmas eve).
SELECT /*+ PARALLEL(2) */ p.p_name, SUM(l.lo_revenue)
FROM lineorder l,
date_dim d,
part p
WHERE l.lo_orderdate = d.d_datekey
AND l.lo_partkey = p.p_partkey
AND p.p_name = ‘hot lavender’
AND d.d_year = 1996
AND d.d_month = ‘December’
GROUP BY p.p_name;
If you examine the execution plan for this SQL statement (below) you will see that two bloom filters were created. The bloom filters are created on the lo_partkey and the lo_orderdate column of the LINEORDER table. The Oracle Database is not limited to just one bloom filter per scan. It is possible to apply multiple bloom filters on a single table scan when appropriate.
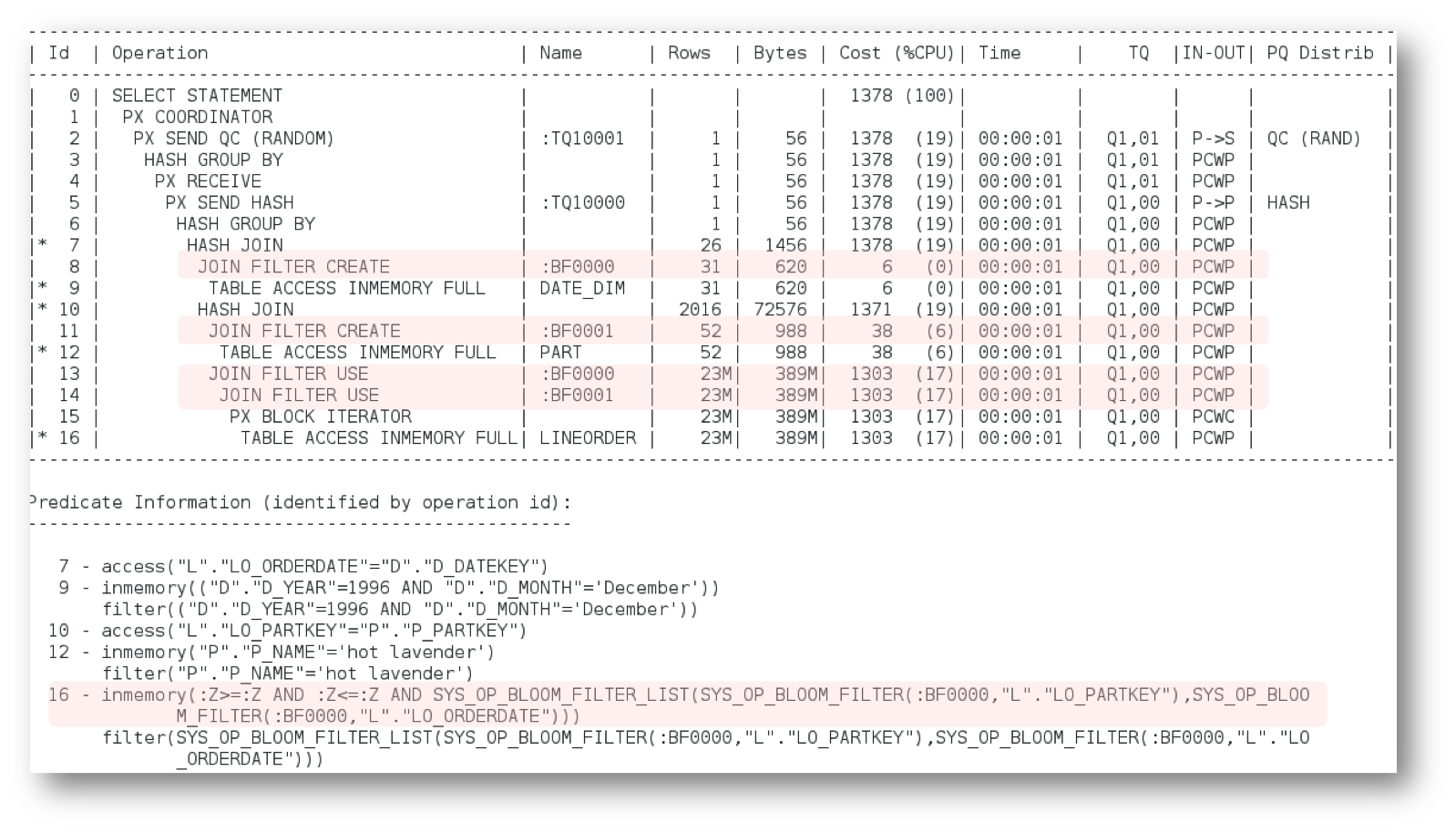
But how is Oracle able to apply two join filters when the join order would imply that the LINEORDER is accessed before the DATE_DIM table?

This is where Oracle’s 30 years of database innovation kick in. By embedding the column store into the Oracle Database we can take advantage of all of the optimizations that have been added to the database over the last 11 releases. In this case, the Optimizer has switched from its typically left deep tree execution plan (shown above) to create a right deep tree using an optimization called ‘swap_join_inputs’. So, instead of the LINEORDER table being the second table accessed in the plan, it actually becomes the third.
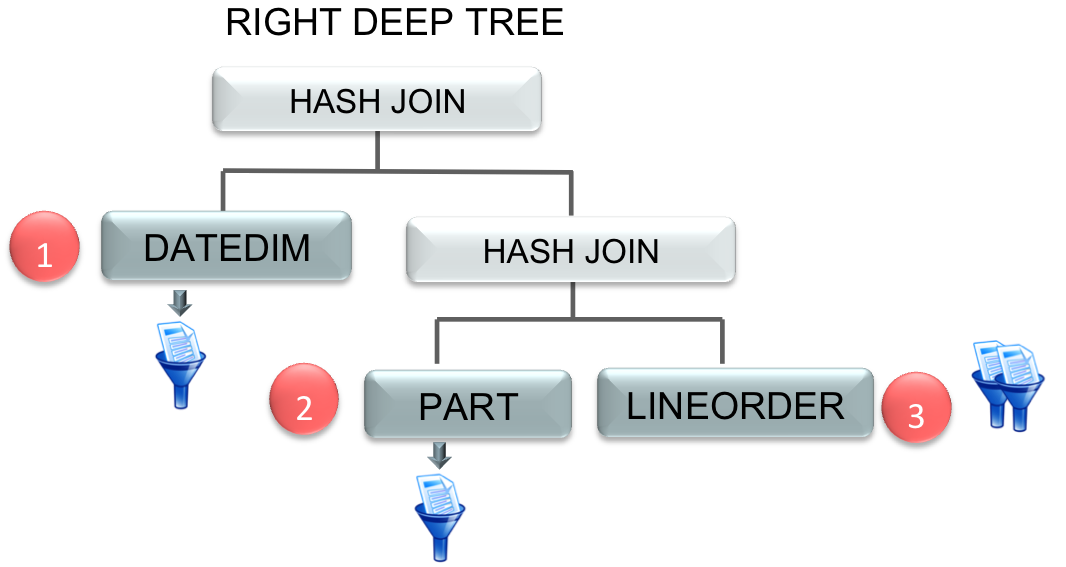
This allows multiple bloom filters to be generated before we scan the necessary columns for the LINEORDER table, meaning we are able to benefit by eliminating rows during the scan rather than waiting for the join to do it.
How did I know the ‘swap_join_inputs’ optimization had taken place?
You can see it in the plan outline, which you can display by setting the format parameter of DBMS_XPLAN.DISPLAY_CURSOR procedure.
SELECT *
FROM TABLE(dbms_xplan.Display_cursor(format => ‘+outline’));
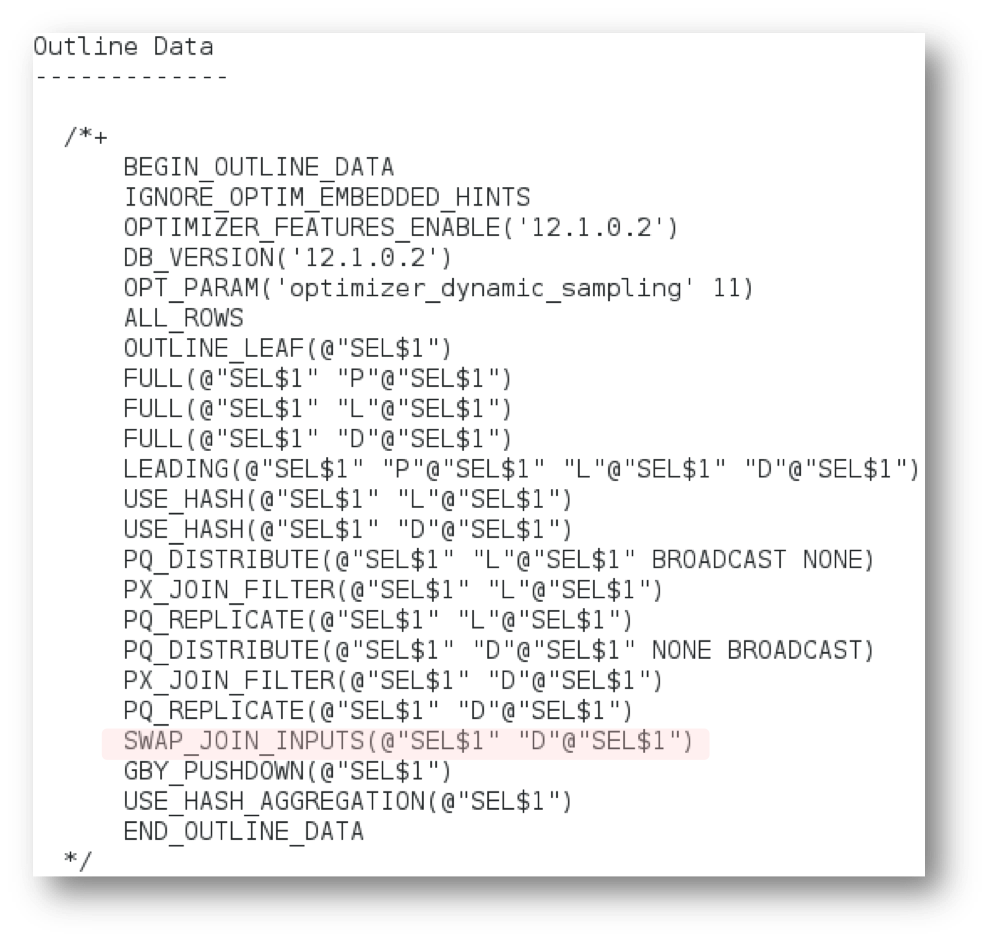
You may also be wondering if all of the benefits we saw during the table scan tests in Part 3 of this series are still relevant now that we are executing joins. The answer is a definite YES!
In the next post, we will cover how the In-Memory column store is able to speed up the execution of complex analytics that include not just joins but aggregation.
Original publish date: October 13, 2014
SELECT SUM(lo_extendedprice * lo_discount) revenue
FROM lineorder l,
date_dim d
WHERE l.lo_orderdate = d.d_datekey
AND l.lo_discount BETWEEN 2 AND 3
AND l.lo_quantity < 24
AND d.d_date=’December 24, 1996′;
The Optimizer has three join methods it could choose for this query;
- Nest Loops
- Hash Join
- Sort Merge Join
Since there are no indexes on our tables the Optimizer picks a Hash Join. When two tables are joined via a Hash Join, the first table (typically the smaller table) is scanned and the rows that satisfy the ‘where’ clause predicates (for that table) are used to create a hash table, based on the join key, in memory. Then the larger table is scanned and for the rows that satisfy the ‘where’ clause predicates (for that table) the same hashing algorithm is performed on the join column(s). It then probes the previously built hash table for each value and if they match, it returns a row.
The In-Memory column store (IM column store) has no problem executing a query with a Hash Join efficiently because it is able to take advantage of Bloom Filters. A bloom filter transforms a join to a filter that can be applied as part of the scan of the fact table. Bloom filters were originally introduced in Oracle Database 10g to enhance hash join performance and are not specific to Oracle Database In-Memory. However, they are very efficiently applied to columnar data via SIMD vector processing.
So how does it work?
During the hash table creation, a bit vector or bloom filter is also created based on the join column. The bit vector is then sent as an additional predicate to the second table scan. After the where clause predicates have been applied to the second table scan, the resulting rows will have their join column hashed and it will be compared to values in the bit vector. If a match is found in the bit vector that row will be sent to the hash join. If no match is found then the row will be discarded.
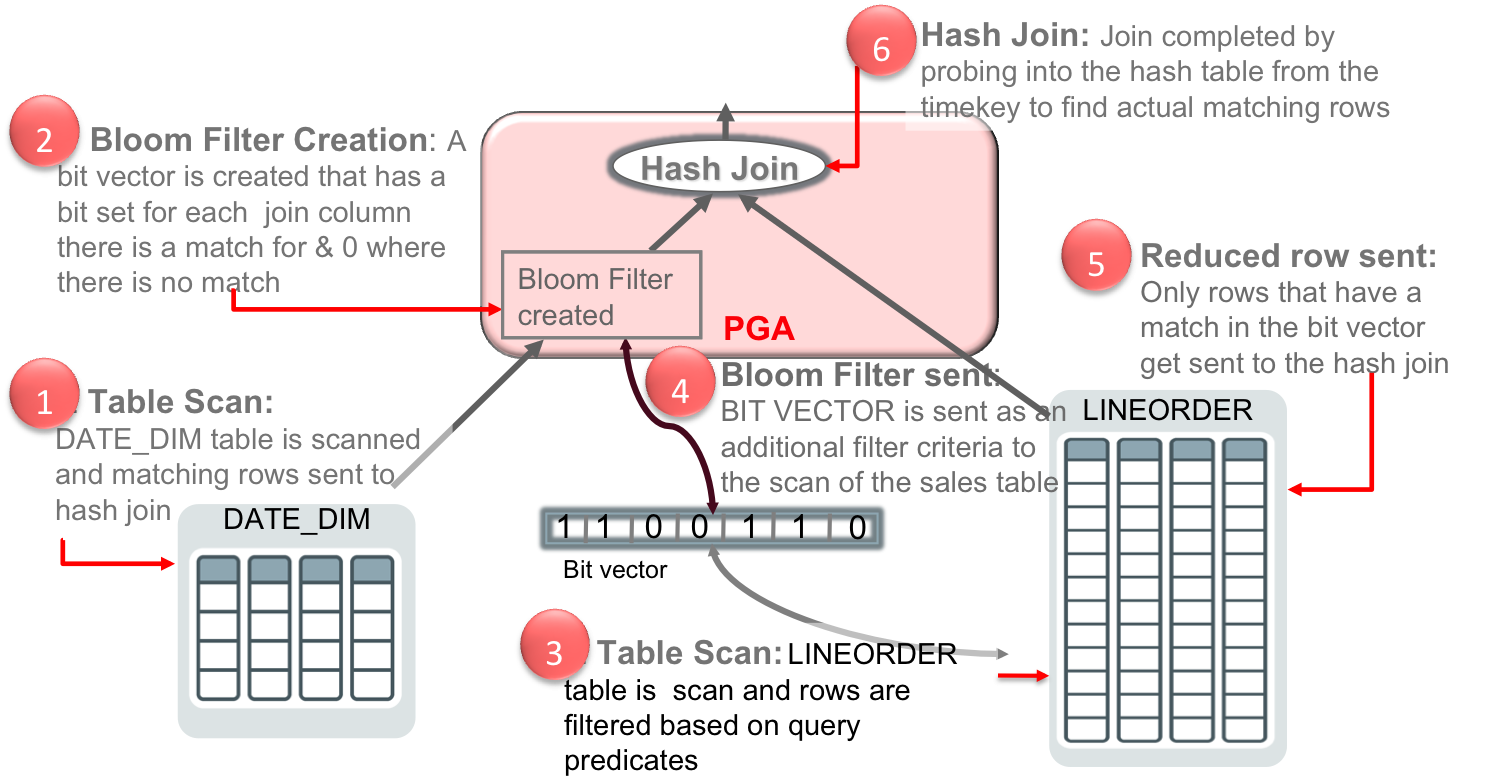
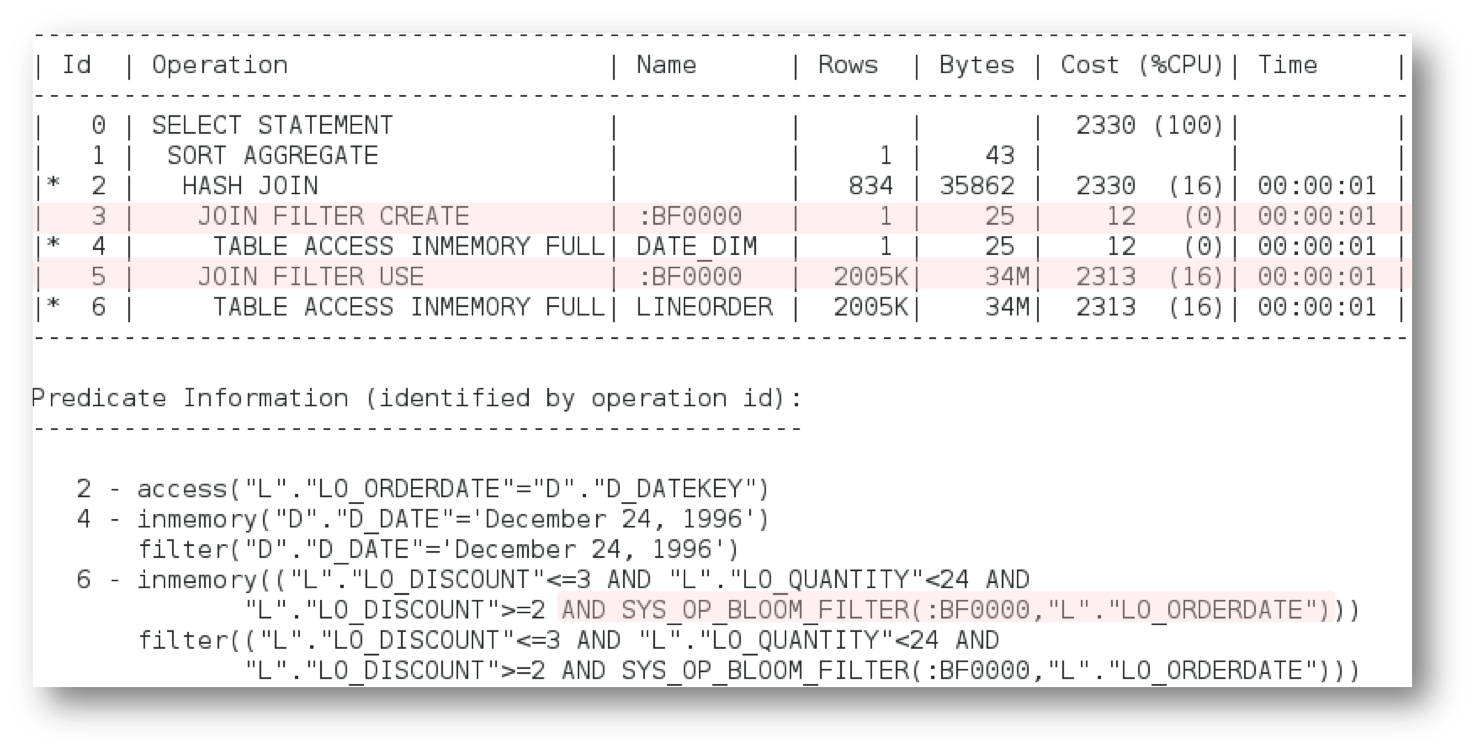
It’s easy to identify a bloom filter in the execution plan. It appears in two places, at creation time and again when it is applied. Below is the plan for our query with the Bloom filter highlighted. The first step executed in this plan is actually line 4; an in-memory full table scan of the DATE_DIM table. The Bloom filter (:BF0000) is created immediately after the scan of the DATE_DIM table completes (line 3). The Bloom filter is then applied as part of the in-memory full table scan of the LINEORDER table (line 5 & 6). You can also see what join condition was used to build the bloom filter by looking at the predicate information under the plan. Look for ‘SYS_OP_BLOOM_FILTER’ in the filter predicates.
Let’s now try a more complex query that encompasses two joins and an aggregation of a lot more data. In this case the query will compute the revenue generated from a specific product in the busiest month of the year, December.
SELECT /*+ PARALLEL(2) */ p.p_name, SUM(l.lo_revenue)
FROM lineorder l,
date_dim d,
part p
WHERE l.lo_orderdate = d.d_datekey
AND l.lo_partkey = p.p_partkey
AND p.p_name = ‘hot lavender’
AND d.d_year = 1996
AND d.d_month = ‘December’
GROUP BY p.p_name;
If you examine the execution plan for this SQL statement (below) you will see that two bloom filters were created. The bloom filters are created on the lo_partkey and the lo_orderdate column of the LINEORDER table. The Oracle Database is not limited to just one bloom filter per scan. It is possible to apply multiple bloom filters on a single table scan when appropriate.
But how is Oracle able to apply two join filters when the join order would imply that the LINEORDER is accessed before the DATE_DIM table?
This is where Oracle’s 30 years of database innovation kick in. By embedding the column store into the Oracle Database we can take advantage of all of the optimizations that have been added to the database over the last 11 releases. In this case, the Optimizer has switched from its typically left deep tree execution plan (shown above) to create a right deep tree using an optimization called ‘swap_join_inputs’. So, instead of the LINEORDER table being the second table accessed in the plan, it actually becomes the third.
This allows multiple bloom filters to be generated before we scan the necessary columns for the LINEORDER table, meaning we are able to benefit by eliminating rows during the scan rather than waiting for the join to do it.
How did I know the ‘swap_join_inputs’ optimization had taken place?
You can see it in the plan outline, which you can display by setting the format parameter of DBMS_XPLAN.DISPLAY_CURSOR procedure.
SELECT *
FROM TABLE(dbms_xplan.Display_cursor(format => ‘+outline’));
You may also be wondering if all of the benefits we saw during the table scan tests in Part 3 of this series are still relevant now that we are executing joins. The answer is a definite YES!
In the next post, we will cover how the In-Memory column store is able to speed up the execution of complex analytics that include not just joins but aggregation.
Original publish date: October 13, 2014
