In my previous blog posts, I described how to install, enable, and populate the In-Memory column store (IM column store). This week’s post focuses on how data is accessed within the IM column store.
Let’s take a simple query “What is the most expensive air-mail order we have received to date?”
SELECT Max(lo_ordtotalprice) most_expensive_order
FROM lineorder
WHERE lo_shipmode = 5;
The LINEORDER table has been populated into the IM column store and since we have no alternative access paths (indexes or views) the execution plan for this query is a full table scan of the LINEORDER table.
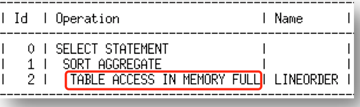
You will notice that the execution plan has a new set of keywords “IN MEMORY” in the access method description in the Operation column. These keywords indicate that the LINEORDER table has been marked for INMEMORY and we may use the IM column store in this query. What do I mean by “may use”? There are a small number of cases where we won’t use the IM column store even though the object has been marked INMEMORY. This is similar to how the keyword STORAGE is used in Exadata environments.
You can confirm that the IM column store was actually used by examining the session-level statistics, but more on that later.
For now let’s focus on how the data is accessed in the IM column store and why it’s faster to access the data in the new column format, for analytical queries, rather than the buffer cache.
There are four main reasons why accessing the data in the IM column store is more efficient.
1. Access only the column data needed
The IM column store only has to scan two columns – lo_shipmode and lo_ordtotalprice – to execute this query while the traditional row store or buffer cache has to scan all of the columns in each row of the LINEORDER table until it reaches both the lo_shipmode and the lo_ordtotalprice column.
2. Scan and filter data in its compressed format
When data is populated into the IM column it is automatically compressed using a new set of compression algorithms that allow WHERE clause predicates to be applied against the compressed formats. This means the volume of data scanned in the IM column store for our query will be far less than the same query in the buffer cache where it will scan the data in its uncompressed form, which could be 20X larger.
3. Prune out any unnecessary data within each column
The fastest read you can execute is the read you don’t do. In the IM column store, a further reduction in the amount of data accessed is possible due to the In-Memory Storage Indexes(IM storage indexes) that are automatically created and maintained on each of the columns in the IM column store. IM storage indexes allow data pruning to occur based on the filter predicates supplied in a SQL statement. An IM storage index keeps track of minimum and maximum values for each column in each of the In-Memory Compression Unit (IMCU).
In our query, the WHERE clause predicate is on the lo_shipmode column. The IM storage index on the lo_shipmode column is examined to determine if our specified column value 5 exist in any IMCU by comparing the value 5 to the minimum and maximum values maintained in the Storage Index. If the value 5 is outside the minimum and maximum range for an IMCU, the scan of that IMCU is avoided.
For the IMCUs where the value 5 does fall within the min, max range, an additional level of data pruning is possible via the metadata dictionary created when dictionary-based compression is used on IMCU. The dictionary contains a list of the unique column values within the IMCU. Since we have an equality predicate we can easily determine if 5 is one of the distinct column values or not.
The combination of the IM storage index and dictionary-based pruning enables us to only scan the necessary IMCUs.
4. Use SIMD to apply filter predicates
For the IMCU that needs to be scanned Oracle takes advantage of SIMD vector processing (Single Instruction processing Multiple Data values). Instead of evaluating each entry in the column one at a time, SIMD vector processing allows a set of column values to be evaluated together in a single CPU instruction.
The column format used in the IM column store has been specifically designed to maximize the number of column entries that can be loaded into the vector registers on the CPU and evaluated in a single CPU instruction. SIMD vector processing enables the Oracle Database In-Memory to scan billions of rows per second per core versus the millions of rows per second per core scan rate that can be achieved in the buffer cache.
I mentioned earlier in this post that in order to confirm the IM column store was used; we need to examine the session-level statistics. You can monitor the session-level statistics by querying the performance views v$mystat and v$statname. All of the statistics related to the In-Memory Column Store begin with IM. You can see the full list of these statistics by typing:
display_name format a30
SELECT display_name
FROM v$statname
WHERE display_name LIKE ‘IM%’;
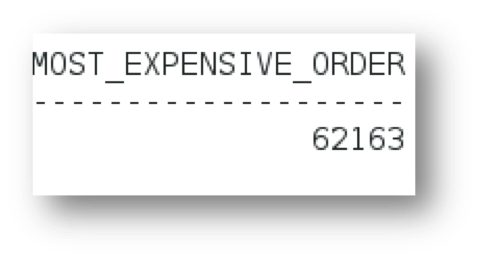
If we check the session statistics after we execute our query the results would be as follow;
SELECT Max(lo_ordtotalprice) most_expensive_order
FROM lineorder
WHERE lo_shipmode = 5;
SELECT display_name
FROM v$statname
WHERE display_name IN (‘IM
scan CUs columns accessed’,
‘IM scan segments
minmax eligible’,
‘IM scan CUs pruned’);
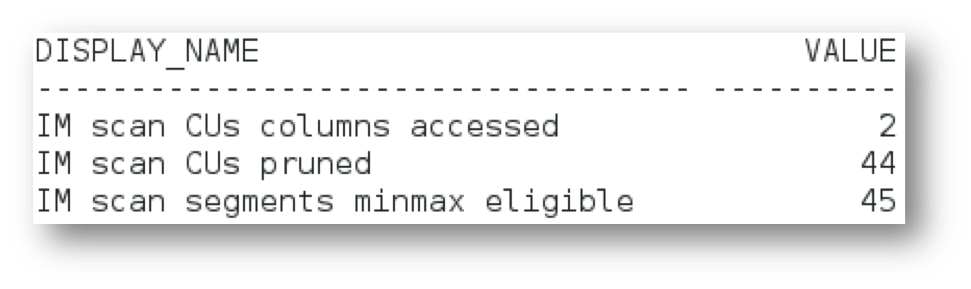
As you can see, only 1 IMCUs was accessed during the scan(45 – 44) as the majority of the IMCUs (44) in the LINEORDER table were pruned out thanks to the storage index on the lo_shipmode column. IM SCAN CUs COLUMNS ACCESSED shows 2 as 2 columns are being accessed in the LINEORDER table (lo_ordtotalprice – lo_shipmode).
In next week’s post, I will describe how you can control which queries use the IM column store and which don’t.
Original publish date: August 17, 2014
