We often get asked the same two questions at conferences and customer presentations. That is can’t I just cache my tables in the buffer cache or put them in the keep pool, and how much memory do I need to allocate to the IM column store? While not directly related, I’m going to try and answer both questions in this post. First let’s tackle the issue of “in-memory”.
If all of my data is “in-memory” in the buffer cache then why do I need Database In-Memory?
The problem with this type of reasoning is that it ignores the real key to Database In-Memory and that is the columnar format, along with other optimizations that are part of the columnar format of Database In-Memory like compression, storage indexes and SIMD vector processing. The fact that the column store is in-memory is essentially just an enabler for the columnar format.
Let’s take a look at an example to see what I mean. The following query makes use of our SSB schema, and specifically the LINEORDER table. The LINEORDER table has 23,996,604 rows and has been fully populated into the IM column store and fully populated into the buffer cache as well. First let’s see the query run with a NO_INMEMORY hint against the buffer cache:


We can see that we performed a full table scan against the LINEORDER table and the query took 2.45 seconds on the database run in VirtualBox on my laptop. In the statistics section note that we did no physical I/O, and also note the amount of CPU used by the query.Next let’s look at the same query run against the IM column store. The only change that I’ve made to the query is to remove the NO_INMEMORY hint.
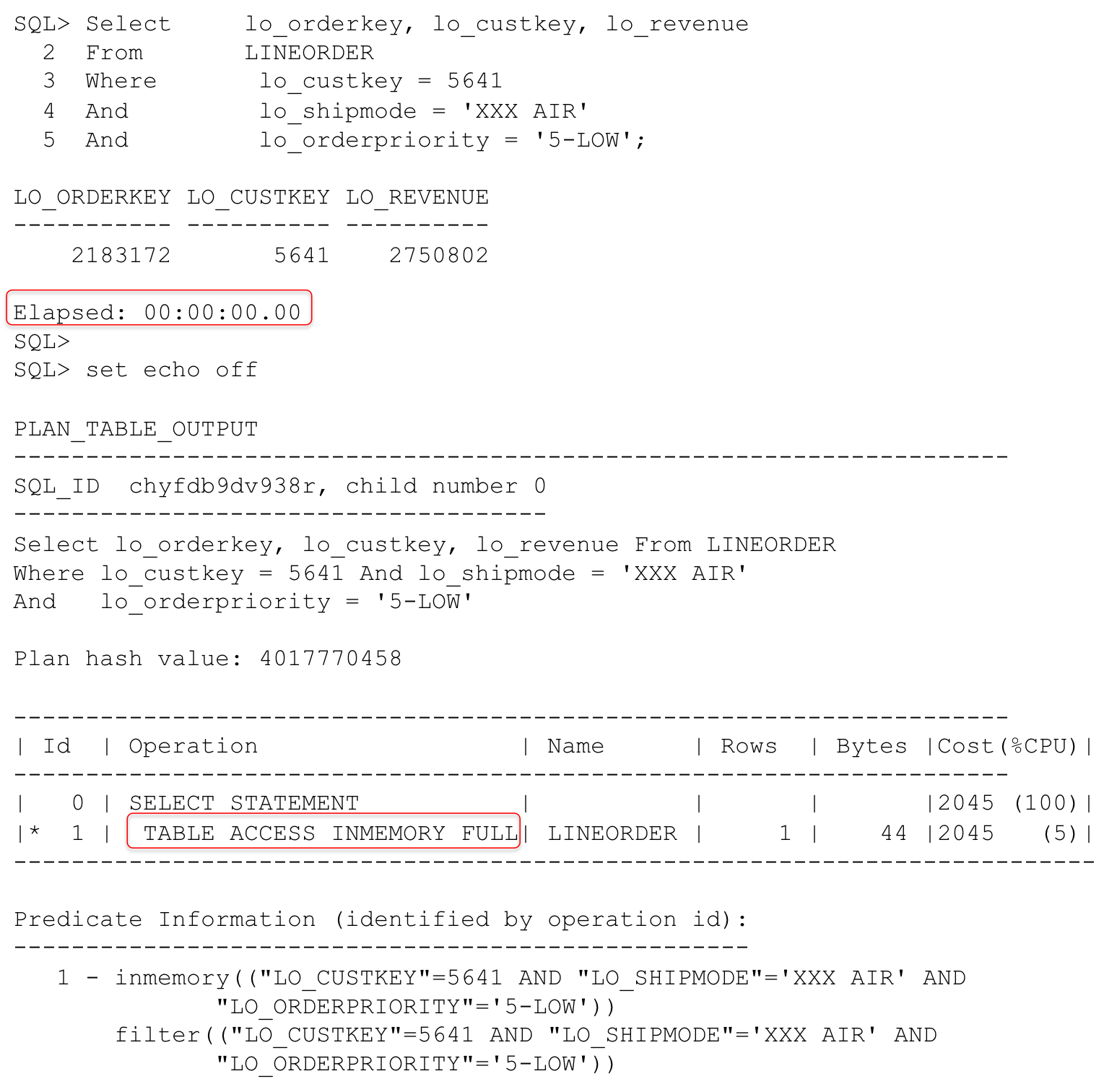

Now we see that the execution plan tells us that we did a full in-memory scan of the LINEORDER table and that it took no time (of course this isn’t really true, but it took so little time that SQL*Plus didn’t record any time for the execution). We can also see that we only had to look at one IMCU (IM scan CUs memcompress for query low – IM scan CUs pruned) and that we only had to return one row (IM scan rows projected). Now obviously this is a best-case scenario, but it highlights the difference that the columnar format makes with Database In-Memory. One other thing to note is to look at the CPU usage. Look at how much less CPU was consumed for the same query.
What if we actually had to scan all of the values for the columns in the query? In other words, what if we had a query that couldn’t take advantage of storage indexes and had to scan all of data for the columns in the query in all of the IMCUs for the LINEORDER table in the IM column store? Will that still be faster than scanning the data in the buffer cache? Recognizing that this is a contrived example, I think it is still worth exploring in light of our initial question.
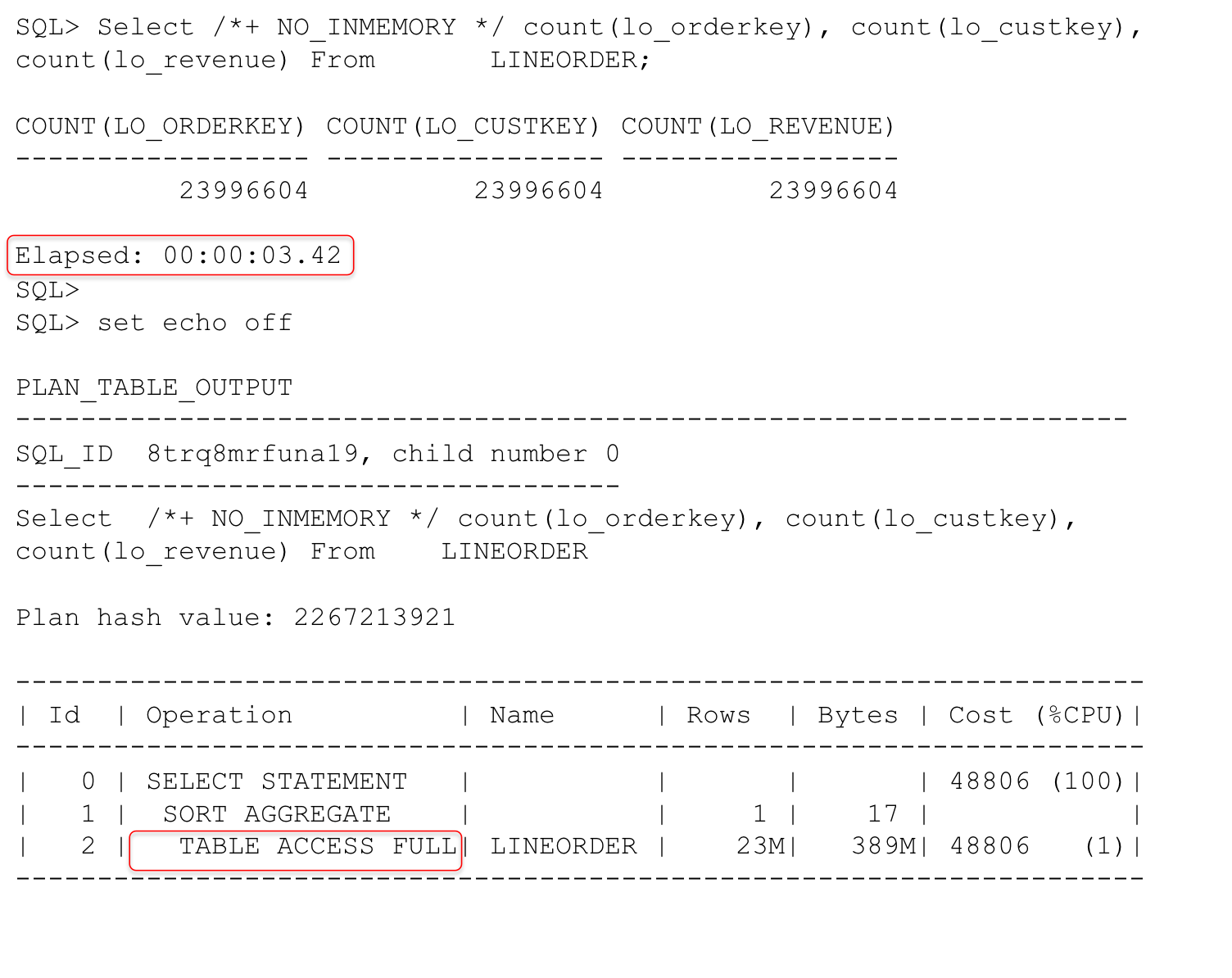
I’ve taken the first query and removed the where clause predicates and surrounded each column returned with a COUNT function. This will generate a full table scan of the LINEORDER table for the three column values and return the total count for each column. Here’s an example for the buffer cache:

Now here’s an example of the query against the IM column store:
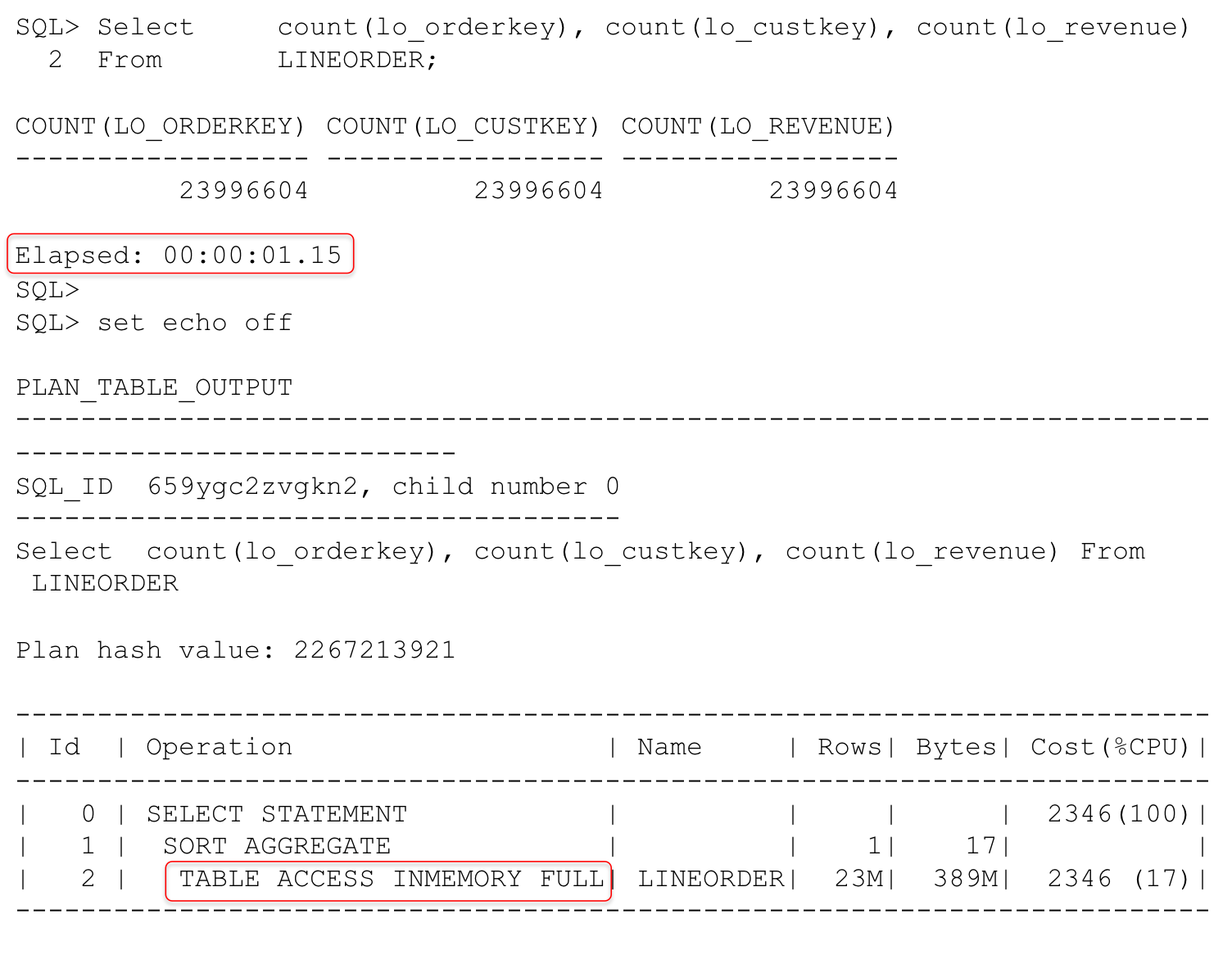

In this example we had to look at all of the data in the IMCUs for the columns in the query. Note that now the IM scan rows projected statistic shows all of the “rows” being returned. The in-memory query runs in 1.15 seconds versus 3.42 seconds for the “row” version. We still did no physical I/O so both formats were truly “in-memory”.
However we still see that the IM column store is significantly faster and more efficient than accessing the data in row format from the buffer cache. Hopefully this helps answer the question of why just placing your row based data “in-memory” is not the same thing as using Database In-Memory.
And what about our second question.
How much memory do I need to allocate to the IM column store?
The simple answer is that you need enough memory allocated to hold the objects that you want to be able to run analytic queries on. Normally this generates two more questions, the first is how do I know how much memory each object will consume in the IM column store and the second is how do I tell which objects should be placed into the IM column store?
The answer to the first question is the Compression Advisor. The Compression Advisor can be run to determine how much space an object will consume in the IM column store based on the compression level chosen. But be warned only the 12c Compression Advisor is aware of the new In-Memory compression techniques.
The answer to the second question is to start with the In-Memory Advisor. Between the output of the In-Memory Advisor and the knowledge of your application you should be able to determine which objects are the best candidates for the IM column store.
Let’s dig a little deeper though. Now that you know how much memory you will need for the IM column store, you need to figure out where you’re going to get it. Unfortunately, the tendency that we have seen is to take the memory from existing usage.
In general this is a bad approach. Very few existing systems have unallocated memory on their database servers. If you are in this category then by all means use that memory, but more often than not the tendency is to “steal” the memory from something else. For instance the buffer cache, the SGA in general, or the memory allocated for the PGA. The problem with these approaches is that it is very likely to impact the performance of your existing workload. We recommend that the memory required for the IM column store should be in addition to your existing database memory allocations. Here is a formula that reflects this goal:
SGA_TARGET = SGA_TARGET(original) + INMEMORY_SIZE
In addition, sufficient PGA must be allocated to handle the memory requirements of parallel processing, sorting and aggregation that can occur due to the potentially large amounts of data being queried by in-memory analytical queries without spilling to disk. This is in addition to the PGA requirements of your existing workload. A good way to view your current PGA usage is to use your AWR reports from your running systems. In the Advisory Statistics section there is a PGA Memory Advisory section. The data from this section can provide good information about the current PGA usage. Alternatively you can provision enough memory for the maximum number of parallel server processes allowed on the system to allocate their full amount of memory using the following formula.
PGA_TARGET = MAX_PARALLEL_SERVERS * 2GB
Hopefully this will help in understanding and planning for memory usage when implementing Database In-Memory.
Original publish date: May 22, 2015
