Resiliency is a foundation for trust and continuity in the cloud. As more mission-critical workloads move to Oracle Cloud Infrastructure (OCI), organisations are rightfully focused on building solutions that can withstand unexpected disruptions, service failures, or even large-scale regional issues.
In this blog, we have compiled key reference material and guidance available within OCI documentation (blogs, solution docs, etc.). You should consider these best practices for maintaining a highly available and resilient environment.
Multi-Availability Domain (AD) & Fault Domain Deployment
Oracle Cloud Infrastructure is hosted in regions across the world that are situated in different cities, providing geographical separation. Designing resiliency in OCI starts with distributing your resources across multiple Availability Domains (ADs) within a region. Each AD is isolated with independent power, cooling, and networking, minimising the risk of simultaneous failures.
For regions with only one AD, leverage Fault Domains, which provide additional isolation within that domain to protect against hardware and maintenance events. By architecting your application and databases across ADs or Fault Domains, you ensure high availability and reduce the risk of downtime from localised outages, making it possible to maintain service continuity even during unexpected infrastructure issues. To dive deeper into best practices for architecting high availability in Oracle Cloud, review the solution playbook on architecting a highly available cloud topology.
For workloads running on Oracle Cloud VMware Solution (OCVS), review the solution playbook for deploying VMware vSAN stretched clusters across multiple OCI regions.
Cross-Region Disaster Recovery
Resilient architectures go beyond availability within a single region; true business continuity requires a robust disaster recovery (DR) strategy that safeguards against regional outages or catastrophic events. In OCI, this means architecting your critical workloads, data, and services to span two geographically separated regions.
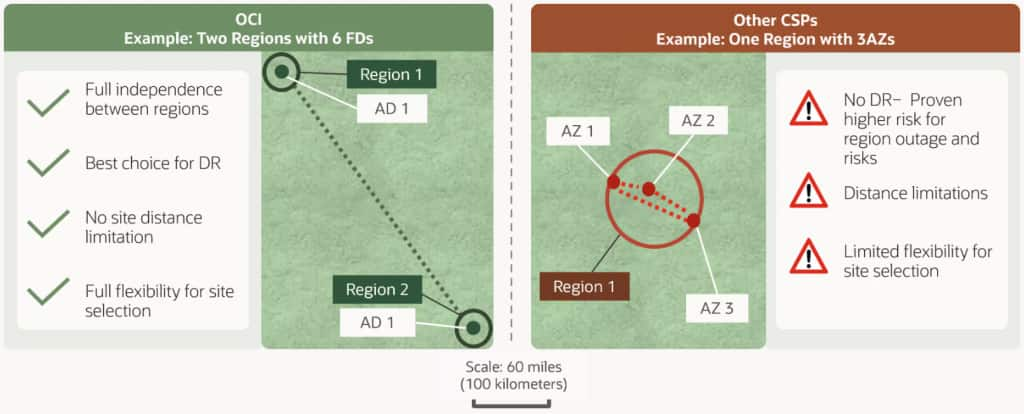
With more than 50 commercial regions globally, you can deploy resources nearby to provide end users with fast access and meet various requirements such as regulatory compliance and data residency requirements. For maximum resiliency, consider OCI’s two-region strategy, which enables full disaster recovery and business continuity even in the rare event of a regional outage.
Redundant Networking & Load Balancing
A resilient cloud architecture depends on eliminating single points of failure in your network design. In OCI, this means deploying redundant resources at every layer: leverage multiple virtual cloud networks (VCNs), subnets, and gateways spread across Availability Domains or Fault Domains to withstand localized disruptions.
Implement Oracle Cloud Infrastructure Load Balancer or Network Load Balancer in front of your applications to intelligently distribute traffic and provide seamless failover if any backend instance becomes unhealthy or unavailable. For critical workloads, use multiple load balancers across ADs for added redundancy, and configure health checks and active-active configurations to ensure continuous and a highly available service.
Don’t forget to leverage redundant routing, DNS, and security policies that align with your failover plans. By architecting your networking and load balancing with redundancy in mind, you ensure your applications can tolerate failures. Maintain high performance, and keep your users connected even during unexpected outages or spikes in demand.
Database High Availability Options
Ensuring the continuous availability of your databases is vital to overall application resiliency on OCI. Oracle offers robust, integrated high availability (HA) solutions tailored for both managed and user-managed databases.
Options include Oracle Real Application Clusters (RAC) for active-active clustering within a region, Autonomous Data Guard and Data Guard for real-time data replication and automated failover across regions, and MySQL HeatWave HA for distributed MySQL workloads. For less operational overhead, Oracle Autonomous Database services provide built-in HA, automated patching, and self-healing capabilities.
It’s best practice to deploy databases across multiple Availability Domains when possible or utilise cross-region Data Guard for critical disaster recovery (DR) and regulatory compliance. Carefully select the HA strategy that meets your workload’s recovery time and recovery point objectives (RTO/RPO). By leveraging OCI’s database HA options, you minimise data loss, avoid prolonged downtime, and maintain business continuity for your mission-critical workloads.
For a comprehensive overview and best practices on Oracle database high availability options, review our official guide on DB HA and best practices.
Backups & Snapshots
A robust backup strategy is a cornerstone of resiliency on OCI. Automated backups and snapshots ensure you can quickly recover from accidental deletions, data corruption, or catastrophic failures. OCI offers scheduled, policy-driven backups for Block Volume, File Storage, and Database services, enabling point-in-time recovery with minimal data loss.
Use block volume backup policies to automate snapshot creation and retention across all your disks, and leverage database backup automation for regular, consistent data protection without manual intervention. For object storage and other services, configure lifecycle policies to transition or archive data as needed. Always test your backup and restore procedures to validate your recovery plan under real conditions. Combine automated backups with cross-region replication to safeguard against geographic failures and comply with strict business continuity or regulatory requirements. Regular, automated backups and snapshots transform disaster recovery from a stressful event into a smooth, predictable process; keeping your most valuable data safe.
Automate Everything
Automation is foundational to building resiliency in OCI. By automating the deployment, configuration, monitoring, scaling, and recovery of your cloud resources, you remove manual steps that can introduce errors or slow down response times during incidents. Use native OCI tools, scripts, and orchestration services to handle routine tasks from patching and backups to application failover and scaling. Automated playbooks and run-books ensure consistent execution, while scheduled tasks and event-driven workflows help your environment self-heal without human intervention. Embracing end-to-end automation not only improves uptime and speeds up recovery, but also frees your team to focus on innovation, not repetitive operations.
Proactive Monitoring, Alerts & Event Handling
Building resiliency isn’t just about reacting to failures, it’s about anticipating and quickly responding to issues before they escalate. With Oracle Cloud Infrastructure, leverage native Monitoring, Logging, and Events services to gain real-time visibility into your cloud resources and workloads. Set up metrics and custom alarms to detect anomalies, performance degradation, or breaches of critical thresholds. Use automated event handling to trigger notifications, remediation scripts, or response workflows, ensuring rapid mitigation of emerging problems.
Centralised dashboards and actionable alerts empower your team to address incidents proactively, minimise downtime, and maintain service continuity. Regularly reviewing monitoring and alerting configurations ensures your resiliency posture adapts as your architecture evolves.
Protecting Against Ransomware Style Threats
A resilient OCI environment must be prepared to defend against ransomware and similar advanced threats that can encrypt or destroy mission-critical data. In Oracle Cloud, this starts with implementing immutable, automated backups that remain protected even if production systems are compromised. Use features like Object Storage retention rules (WORM), backup vaults for databases, and separation of backup management permissions from everyday operations. Enhance your protection with strict IAM policies, multi-factor authentication, and continuous monitoring for suspicious behaviour. Regularly testing your restore procedures is also essential to ensure rapid recovery.
Regular Testing & Chaos Engineering
Resiliency is only as strong as your ability to validate it in real-world conditions. Regularly testing your failover, backup, and disaster recovery procedures ensures that your infrastructure and teams are ready when disruption strikes. Go beyond planned drills by embracing chaos engineering, purposefully injecting failures and disruptions to proactively uncover weaknesses and improve system robustness. OCI customers can leverage industry-leading practices and native tooling to simulate outages or failures, ensuring recovery plans are effective, and applications behave as expected under stress.
Adopting a Holistic Resiliency Framework and Disaster Recovery Automation
Building true resiliency in OCI isn’t just about individual tools or isolated tactics; success depends on a comprehensive, framework-driven approach. Start by aligning your architecture and operations with the Oracle Cloud Adoption Framework’s resiliency pillar, which provides best practices for designing, implementing, and governing resilient cloud environments. Complement this strategy by leveraging automated recovery and orchestration tools like OCI Full Stack Disaster Recovery, enabling seamless, orchestrated disaster recovery across all layers—applications, middleware, and databases. This combined approach ensures your entire IT landscape is prepared for disruptions, enabling rapid recovery and minimising downtime across workloads and business processes.
Check out the blog on cross-region OCI Kubernetes Engine cluster disaster recovery with OCI full stack DR (FSDR)
https://blogs.oracle.com/cloud-infrastructure/kubernetes-engine-full-stack-disaster-recovery
Summary
This blog outlines essential best practices for building resilient architectures on Oracle Cloud Infrastructure (OCI), focusing on high availability, fault tolerance, and business continuity. It covers strategies such as deploying across availability and fault domains, implementing cross-region disaster recovery, designing redundant networking, and leveraging robust database high availability solutions, while emphasising automation, proactive monitoring, secure backups, and regular testing. Readers are encouraged to explore the linked solution playbooks, guides, and blogs throughout to deepen their understanding and apply these practices effectively in their OCI environments.
