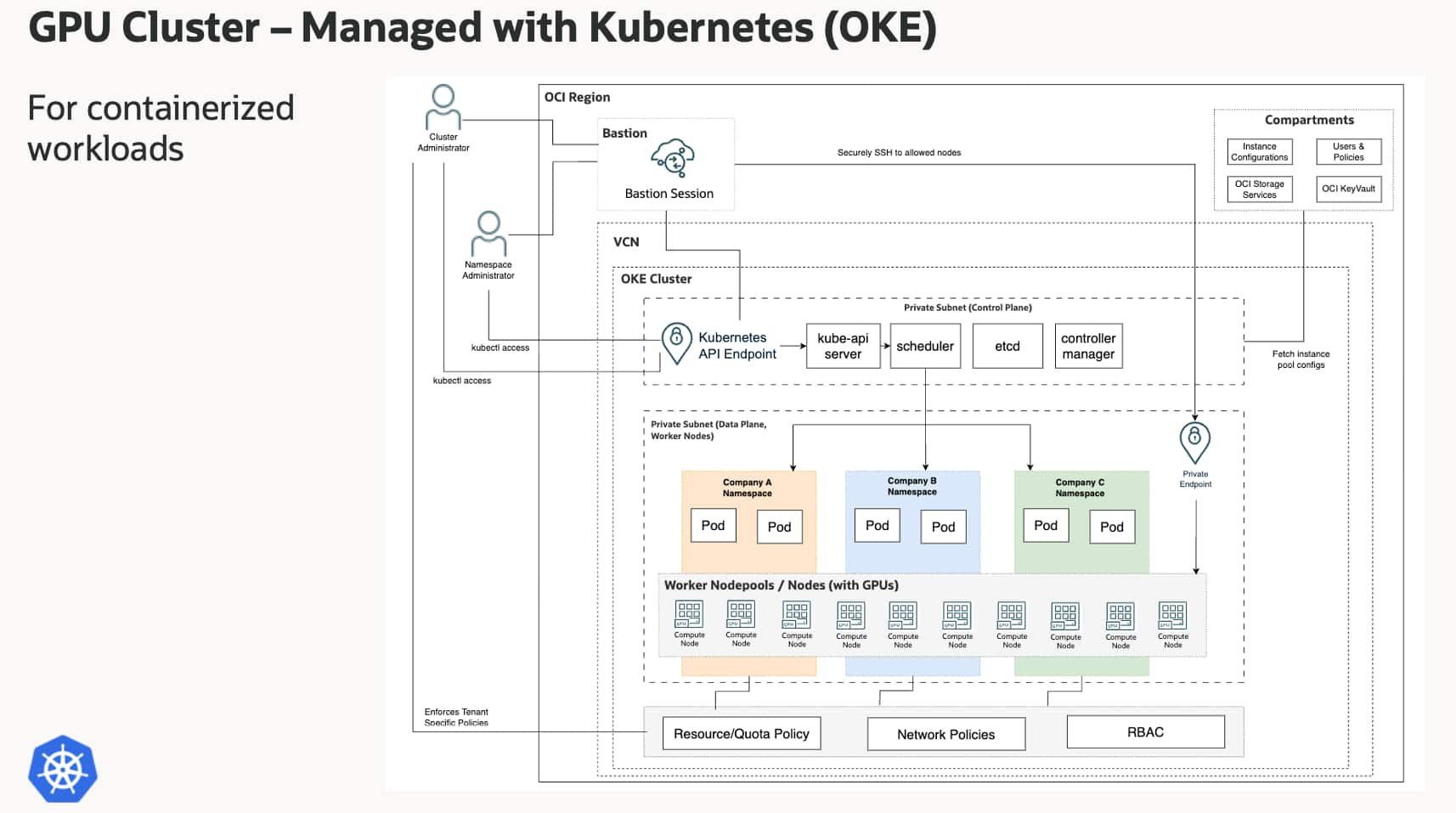
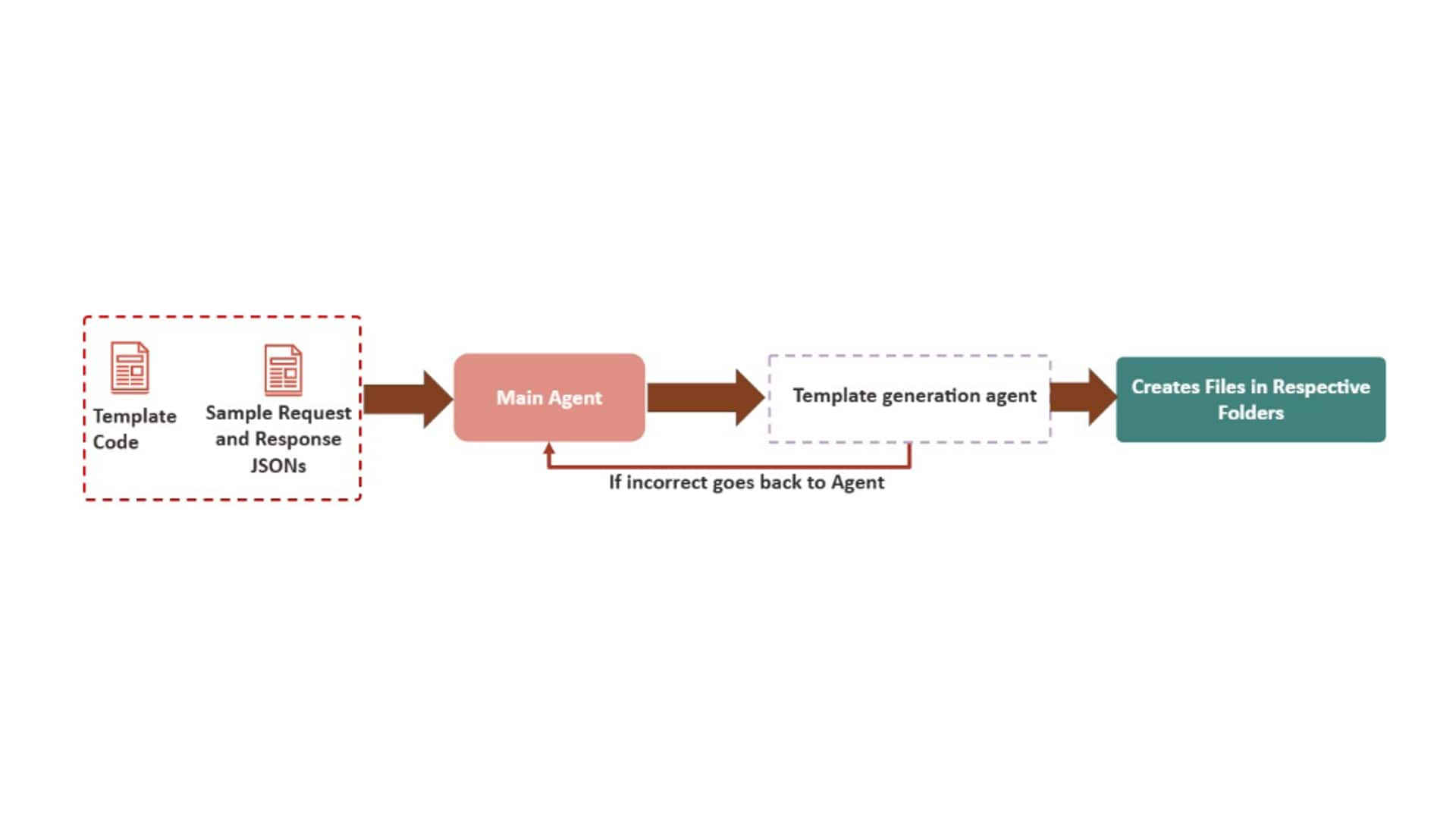
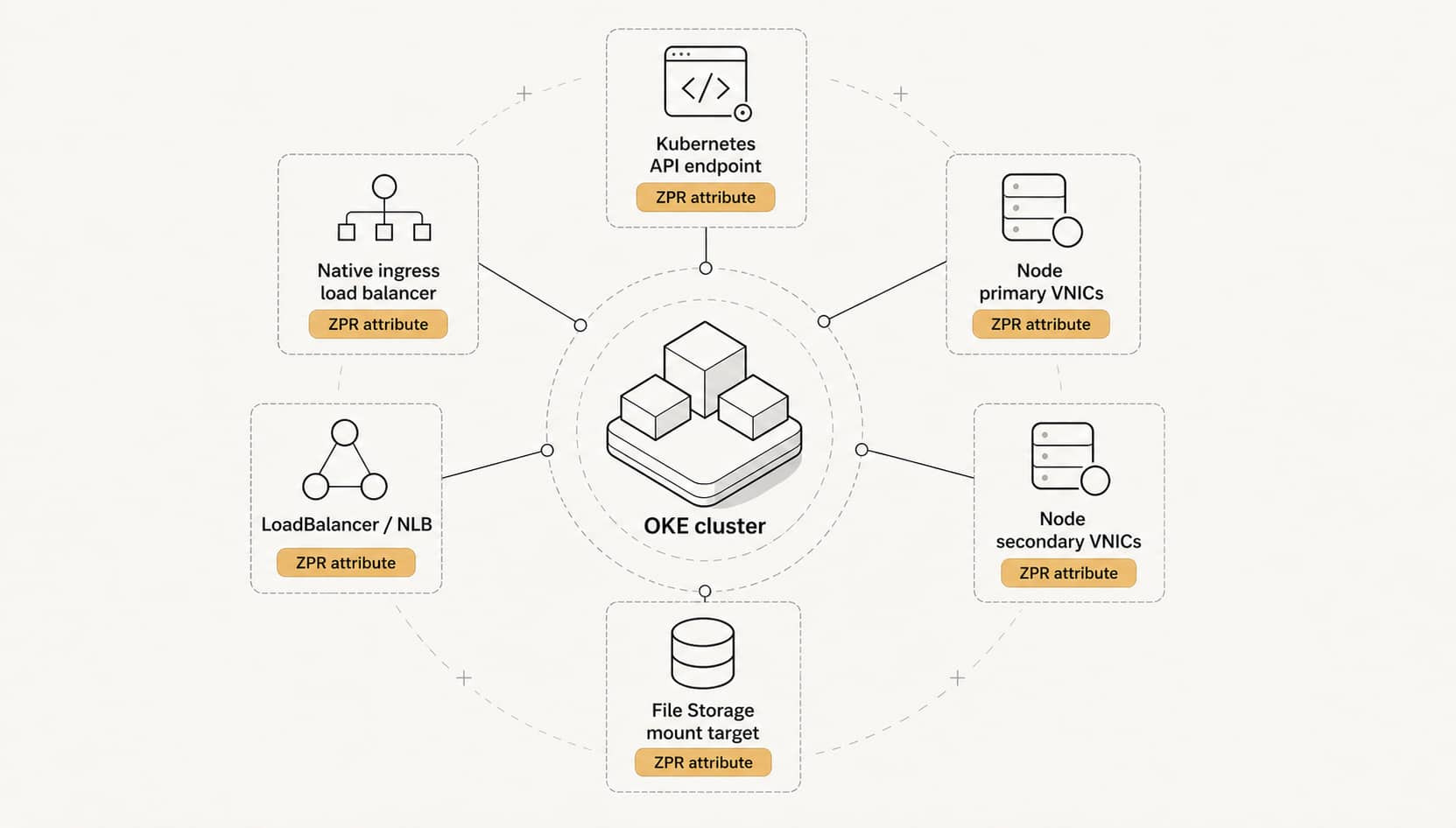
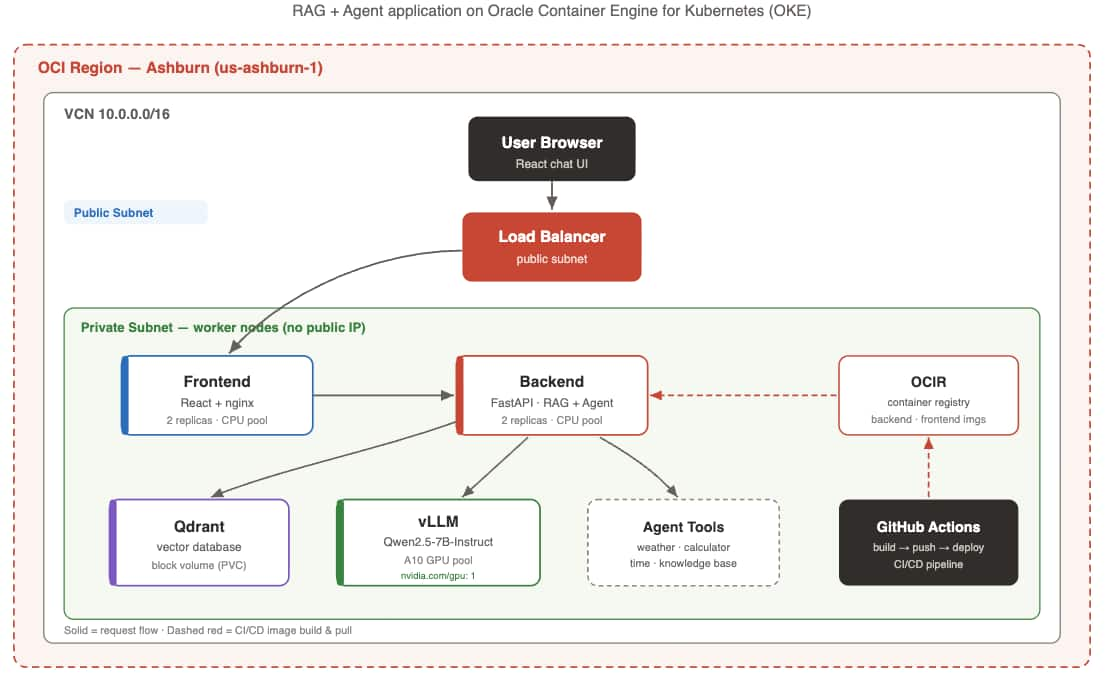
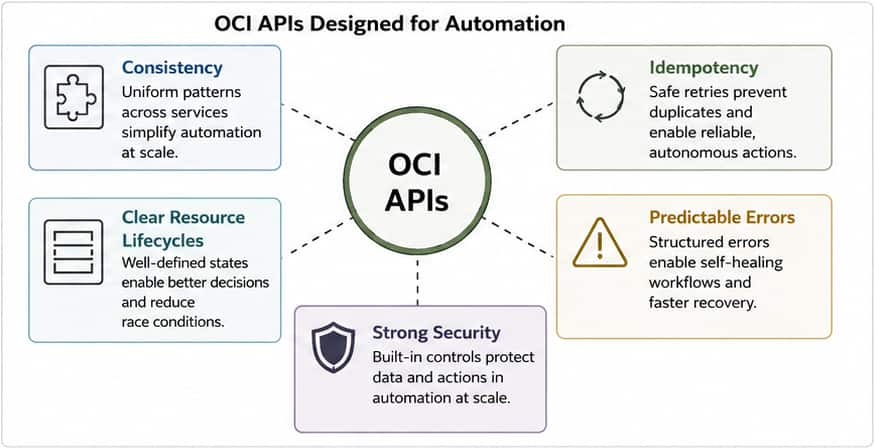
Accessibility Policy
Skip to content
Oracle
Oracle Cloud Infrastructure Blog
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
Oracle AI
Back
Oracle AI
Oracle Labs
Oracle Cloud Infrastructure (OCI)
Technical Solutions
Use Cases
RELATED CONTENT
Cloud.oracle.com
Blogs Home
RSS
Oracle Cloud Infrastructure Blog
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
Oracle Multicloud – What’s News
Nathan Thomas
Vijay Bangaru
Muneer Mirza
26 minute read
Bringing Business Data Insights to Every User with Gemini Enterprise ...
Nathan Thomas
Hasan Rizvi
5 minute read
More Oracle Autonomous AI Database deployment options on Oracle AI ...
Muneer Mirza
2 minute read
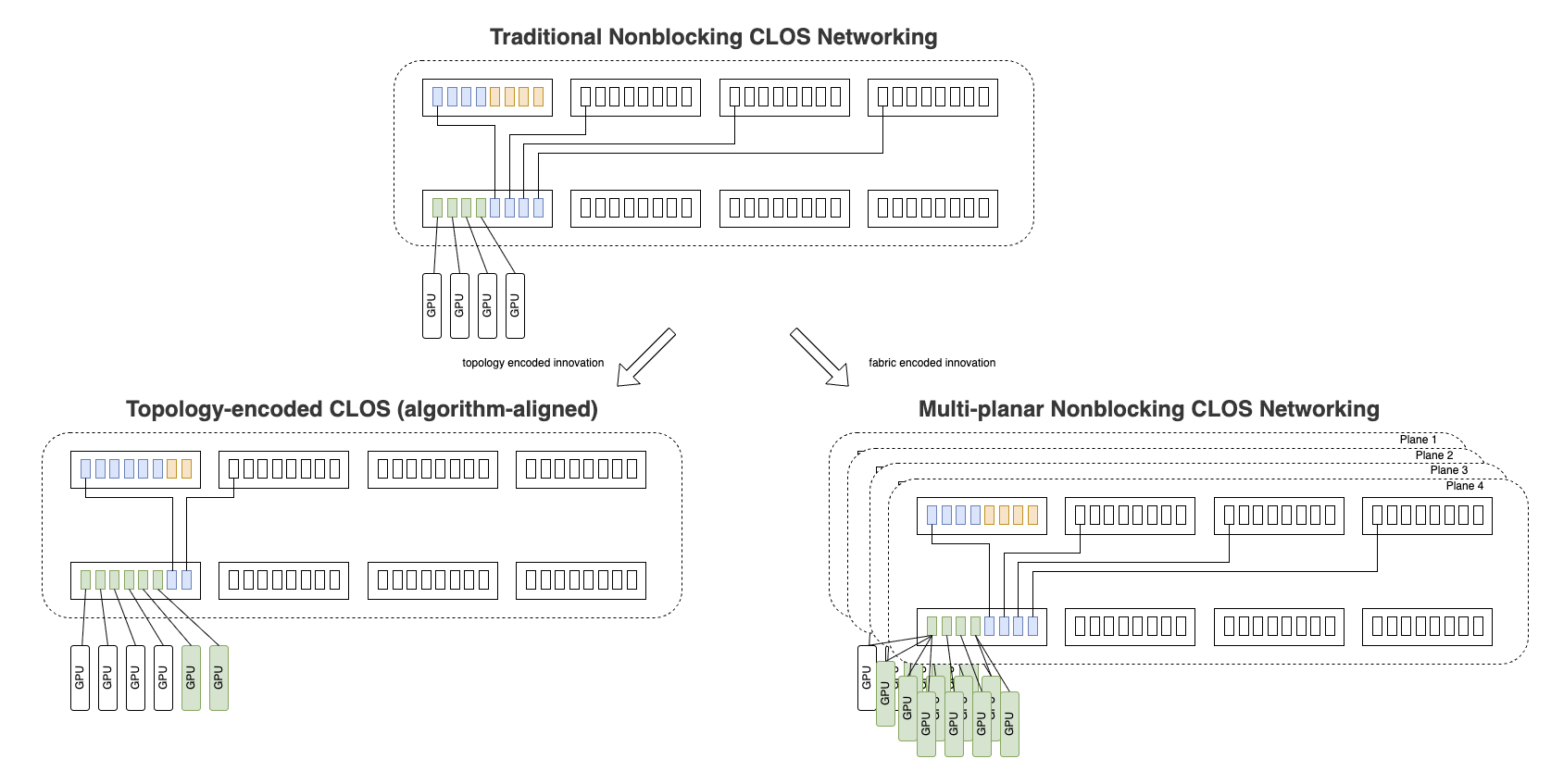
First Principles: Unlocking Oracle Acceleron Multiplanar Fabric with ...
Pradeep Vincent
Andrew Dickinson
David Becker
Diptanshu Singh
4 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest OCI news
Subscribe to the Oracle Cloud Insider Newsletter
Application Security
See all
The Key Behind the Claim: Customer-Managed Encryption in OKE
Farooq Nafey
6 minute read
Get Involved: Introducing the Application Security ...
Miranda Jimenez
SaaS Cloud Security
4 minute read
Fusion AI Agents: Secure by Operations Best-Practice Considerations
Reshma Sivakumar
Ranveer Tiwari
Miranda Jimenez
SaaS Cloud Security
5 minute read
Fusion AI Agents: Secure by Enforcement Best-Practice Considerations
Reshma Sivakumar
Ranveer Tiwari
Miranda Jimenez
SaaS Cloud Security
6 minute read
Fusion AI Agents: Secure by Design Best-Practice Considerations
Reshma Sivakumar
Ranveer Tiwari
Miranda Jimenez
SaaS Cloud Security
5 minute read
Why Resilience Requires Independence: A New Approach to Business ...
Damien Rilliard
Leon Mullally
4 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
Why Quicknode, leading blockchain infrastructure provider chose ...
Mike Terra
3 minute read
Artificial Intelligence
See all
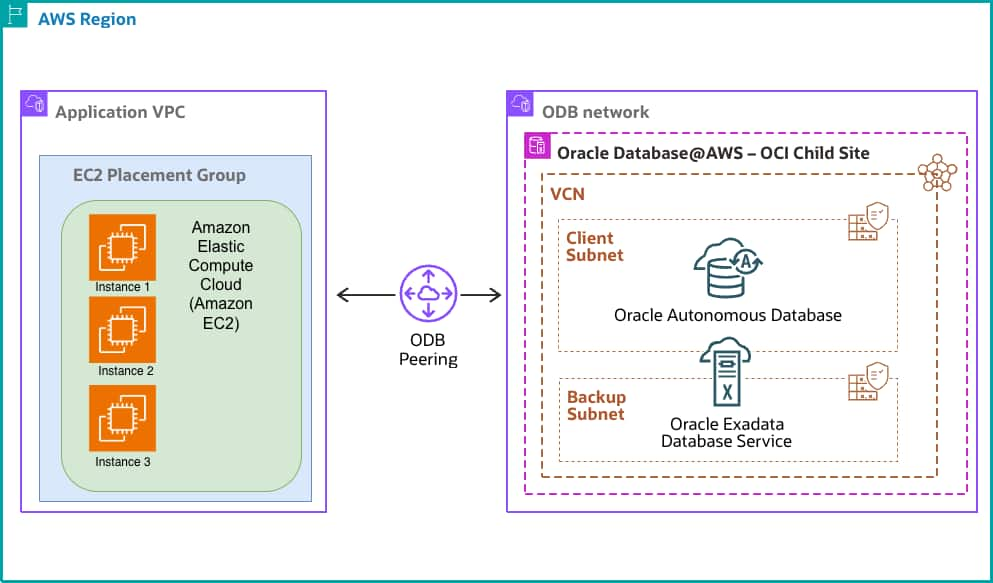
Run a Self-Managed Oracle Database in AWS with Autonomous AI Database ...
Muneer Mirza
Rakshana Balakrishnan
Peter Kurkowski
6 minute read
Scaling agentic systems with Semantic Caching
Dmitry Polyakovsky
7 minute read
Introduction to Vector Similarity Search
Dmitry Polyakovsky
7 minute read
Cloud Infrastructure Security
See all
Introducing DNS Resolution for Oracle Exadata Database on Dedicated ...
Partha Srinivasan
3 minute read
Why Resilience Requires Independence: A New Approach to Business ...
Damien Rilliard
Leon Mullally
4 minute read
Managing Custom Gold Images on OCI for Secure and Compliant Compute ...
Jitesh Kunder
8 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
OCI Confidential Computing on E5/E6 VM and Bare Metal Shapes
Alex Moffat
3 minute read
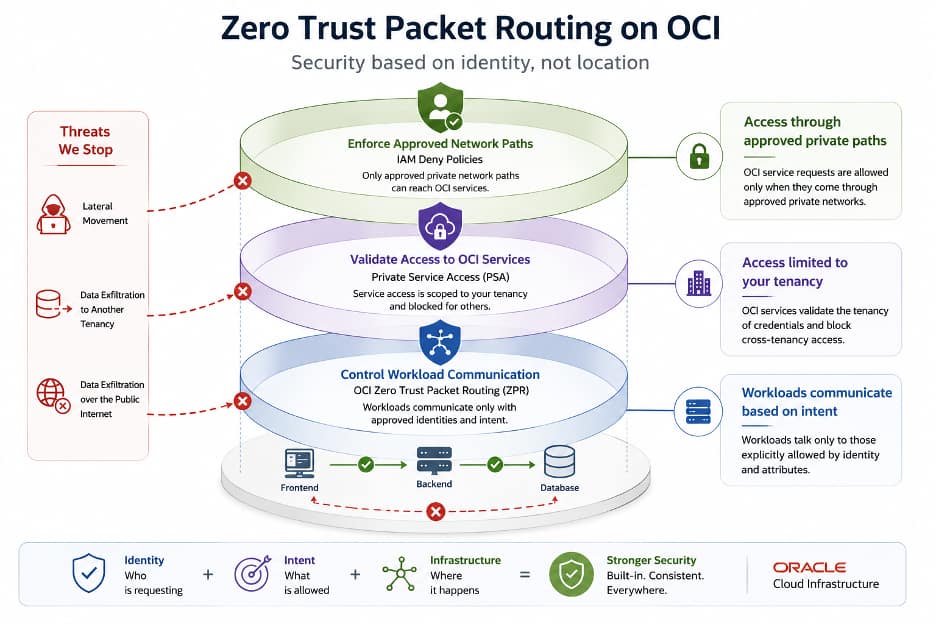
Zero Trust Packet Routing on OCI: Enforce Network Security Based on ...
Ritesh Kumari
6 minute read
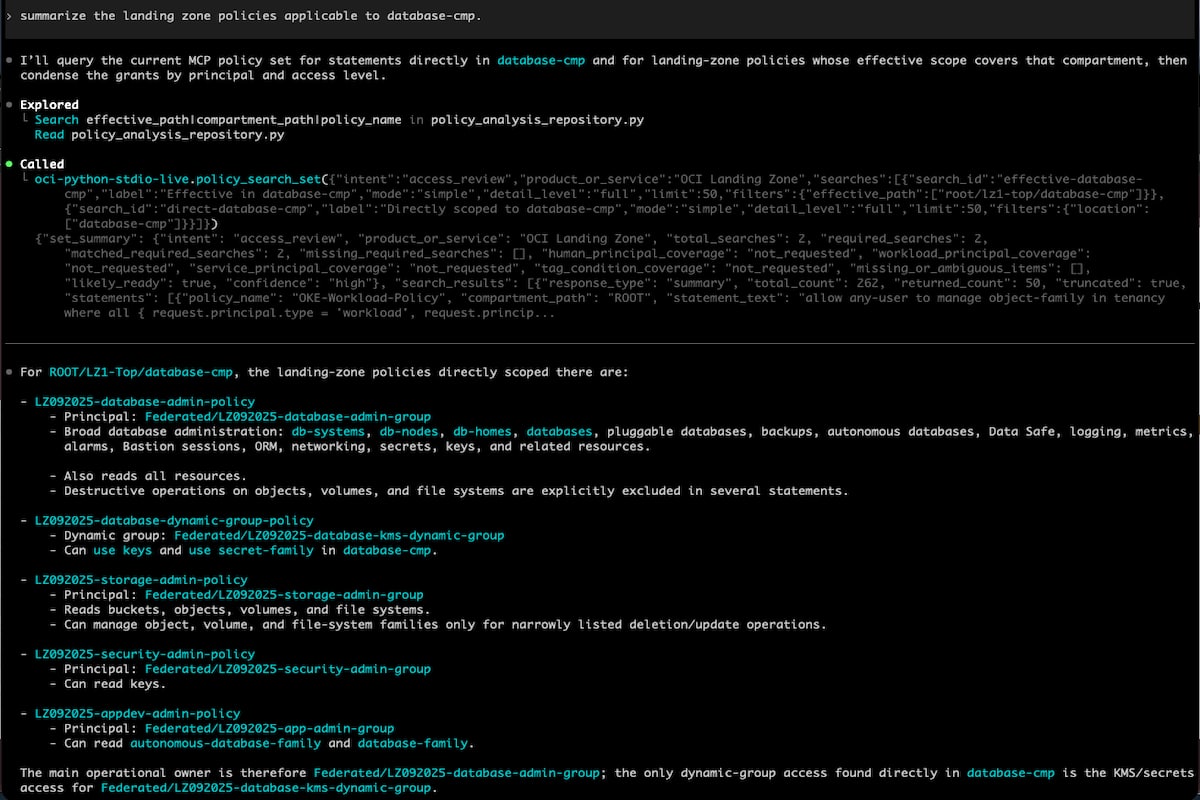
OCI Policy Analysis Part 3 – Bringing OCI Policy Intelligence to AI ...
Andrew Gregory
10 minute read
Why Quicknode, leading blockchain infrastructure provider chose ...
Mike Terra
3 minute read
Product News
See all
Introducing DNS Resolution for Oracle Exadata Database on Dedicated ...
Partha Srinivasan
3 minute read
Oracle Defence Tech Summit: Accelerating mission advantage through ...
Greg Magram
6 minute read
Introducing BM.Optimized3.36 for Oracle Cloud VMware Solution: A New ...
Divya Kamath
3 minute read
OCI Container Instances (CI) now support persistent file storage
Kevin Liu
Harshit Patel
3 minute read
OCI Search with OpenSearch adds new capabilities for AI-ready, ...
Mandy Pang
4 minute read
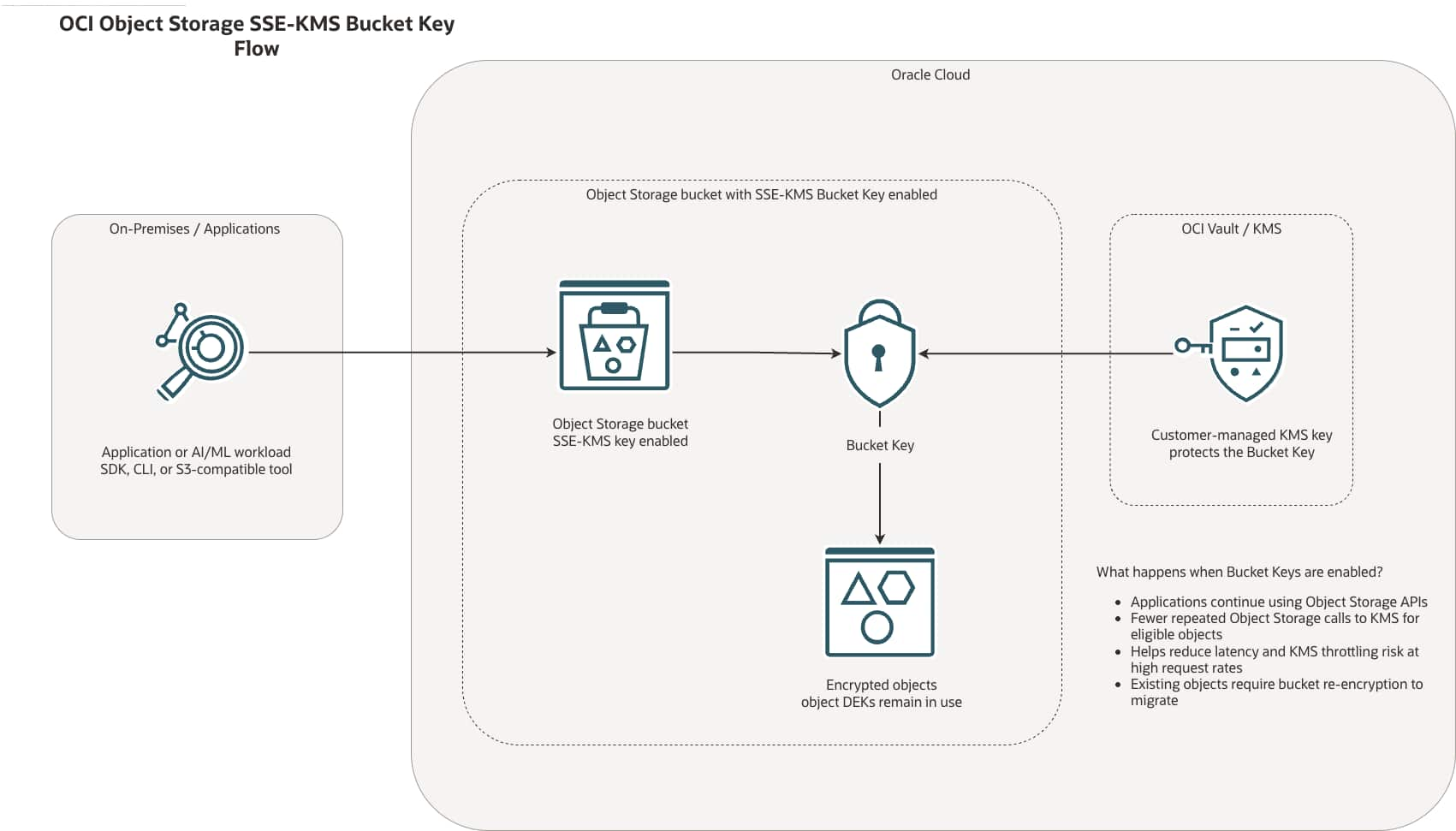
Improve Object Storage Throughput with Bucket Keys
Melinda Centeno
3 minute read
OCI Confidential Computing on E5/E6 VM and Bare Metal Shapes
Alex Moffat
3 minute read
Duality and Oracle: Rethinking Data Sharing in Defense
Kelly Crooks
5 minute read
Autonomous Database
See all
Putting Customers First, Together: A Year of Oracle AI Database@AWS ...
Nathan Thomas
6 minute read
Oracle AI Database@AWS Achieves Oracle MAA Platinum Certification and ...
Muneer Mirza
Pandit Prasad
Peter Kurkowski
Glen Hawkins
5 minute read
Run a Self-Managed Oracle Database in AWS with Autonomous AI Database ...
Muneer Mirza
Rakshana Balakrishnan
Peter Kurkowski
6 minute read
OCI Database AI Vector Search: A Practical Step-by-Step approach
ANUPAM ABHISHEK
5 minute read
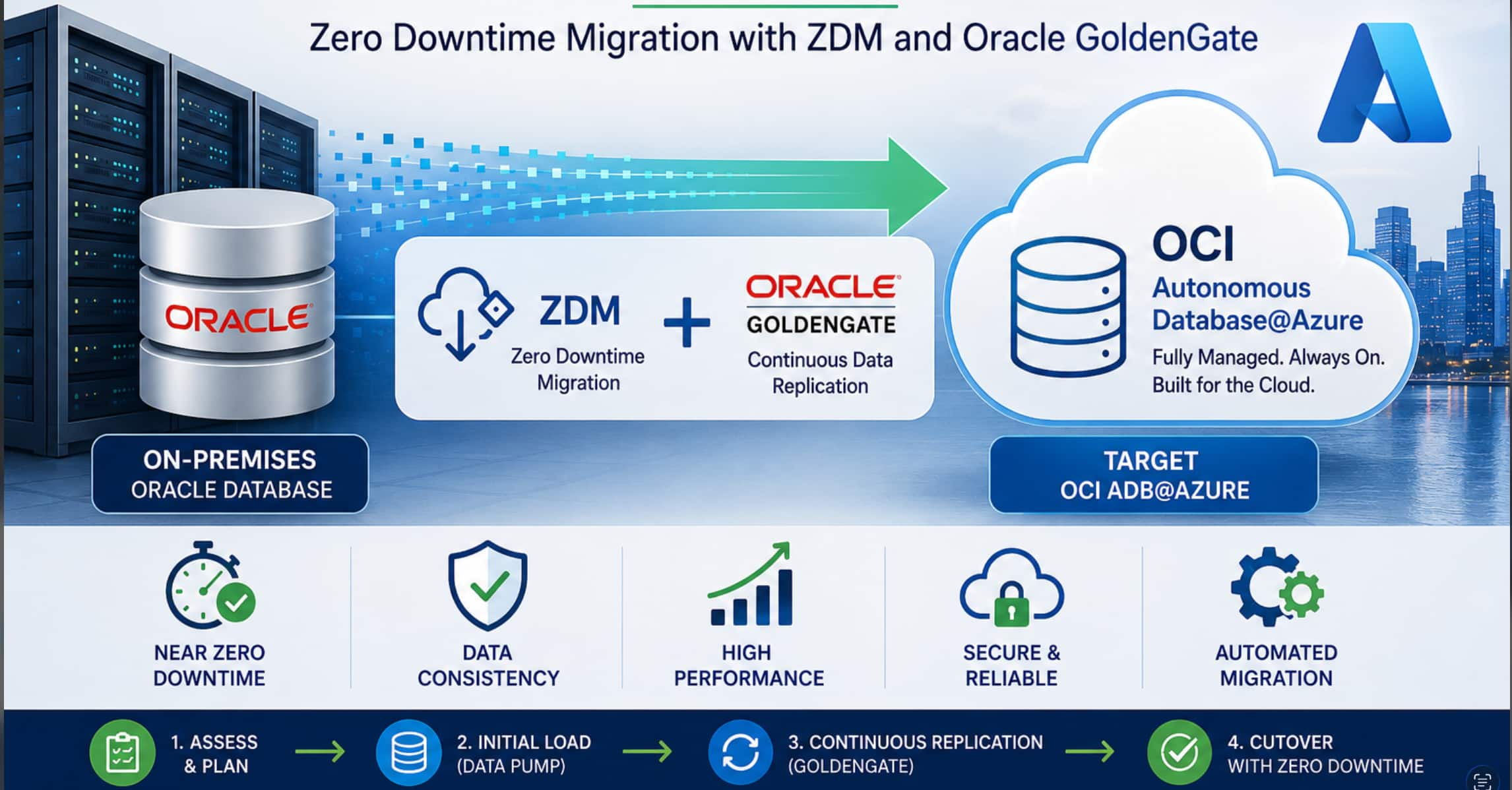
Migration from On-Premises Oracle Database to ADB@Azure using ZDM and ...
ANUPAM ABHISHEK
5 minute read
From Device Symptoms to IoT Context with the OCI IoT Platform MCP ...
Pete St. Pierre
Rayne Sanders
9 minute read
Database Security
See all
Introducing Cloudflare@Oracle Cloud Infrastructure: Supercharge ...
Juliette Paterno
Tim Mclaughlin
5 minute read
Connecting to Oracle Database from outside OCI: 4 practical options
Thangaraj Karol Stuart
Shiva Gurumurthy
6 minute read
Implement Time-Based Access Control Using Oracle Database Vault
Manasa Anantharamaiah Nanjunda Swamy
4 minute read
OCI Key Management service: Crossregion replication for virtual ...
Ankit Goyal
FREDERICK BOSCO
4 minute read
Simplified Database Governance through Oracle Access Governance
Anuj Tripathi
George Hong
5 minute read
Navigate the World of Database APIs with Oracle
Phani Turlapati
4 minute read
Oracle Audit Vault and Database Firewall release update 9 introduces ...
Nazia Zaidi
4 minute read
Announcement: Oracle DBSAT 2.2.2 is now GA
Pedro Lopes
2 minute read
Technical Solutions
See all
The Key Behind the Claim: Customer-Managed Encryption in OKE
Farooq Nafey
6 minute read
Introducing the OCI OKE Troubleshooter Skill
Chip Hwang
7 minute read
Managing Custom Gold Images on OCI for Secure and Compliant Compute ...
Jitesh Kunder
8 minute read
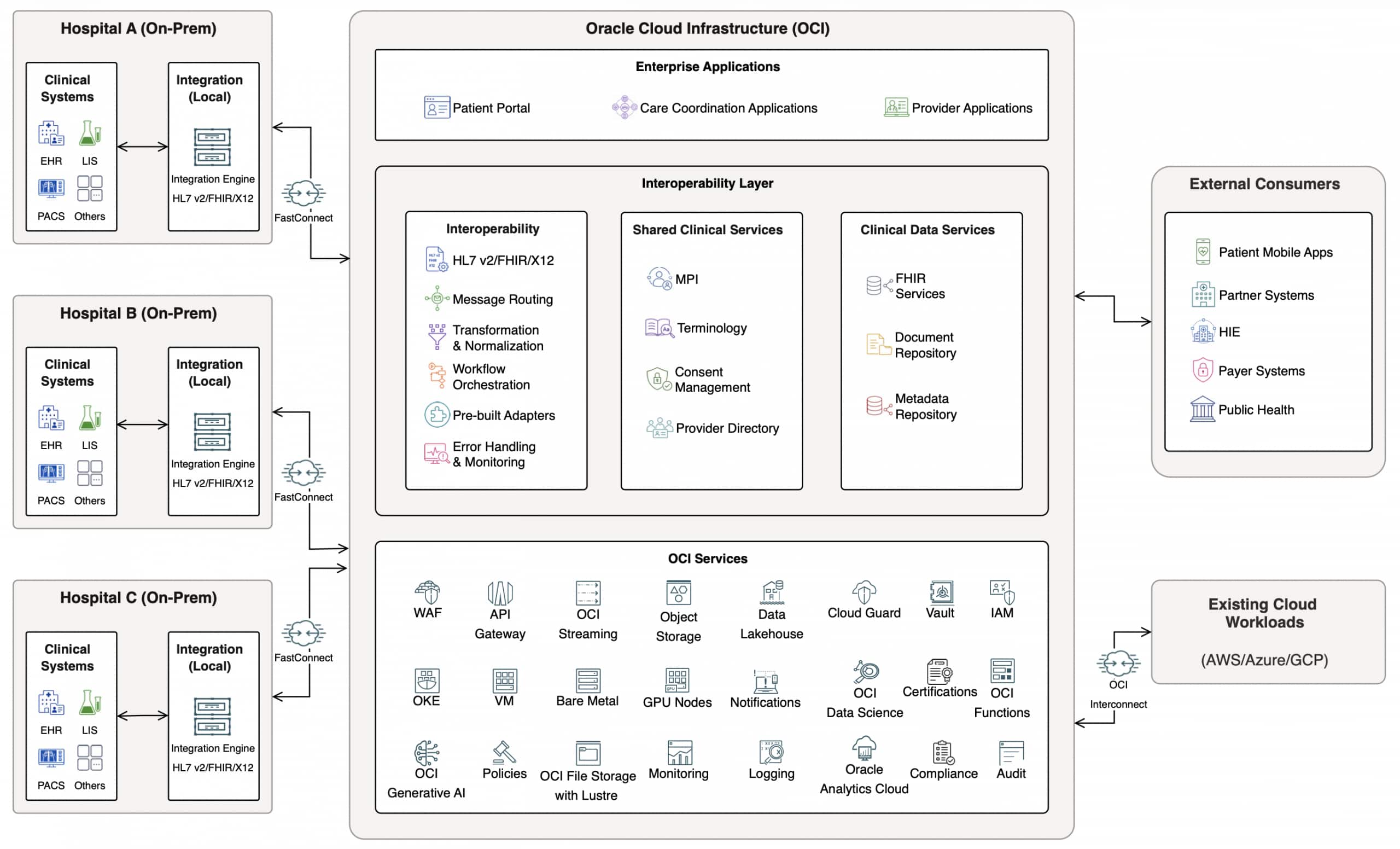
Modernizing healthcare interoperability with Oracle Cloud ...
Sean Ru
4 minute read
Snapshot Smarter: Automating Recovery Points for Stateful Apps on OKE
Farooq Nafey
8 minute read
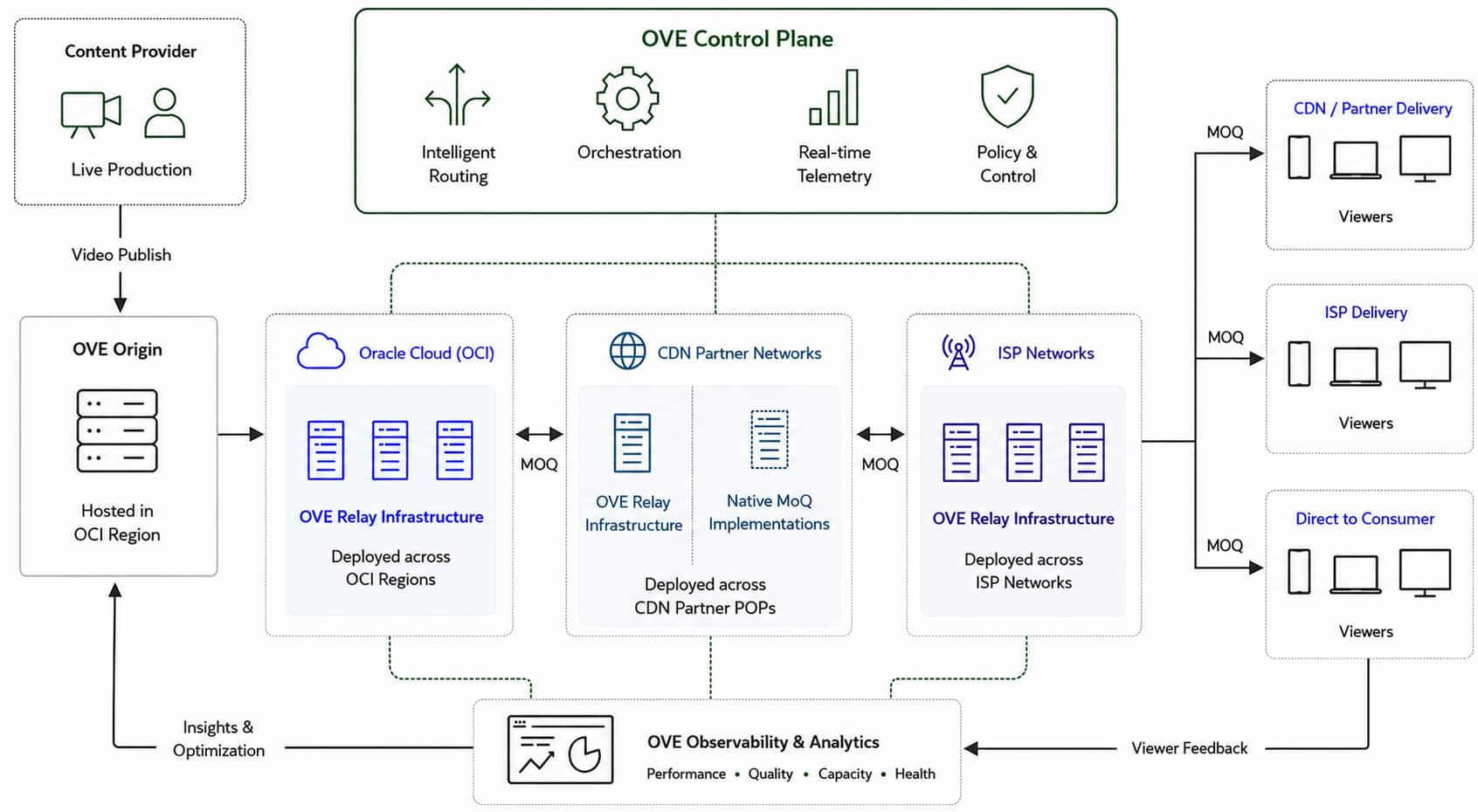
Oracle Video Edge: Orchestrating Large-Scale Live Streaming Across ...
Dustin Encelewski
Mathias Guille
4 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
Improve Object Storage Throughput with Bucket Keys
Melinda Centeno
3 minute read
Analytics and Data Warehousing
See all
Putting Customers First, Together: A Year of Oracle AI Database@AWS ...
Nathan Thomas
6 minute read
Run a Self-Managed Oracle Database in AWS with Autonomous AI Database ...
Muneer Mirza
Rakshana Balakrishnan
Peter Kurkowski
6 minute read
Identity and Access Management
See all
Managing Custom Gold Images on OCI for Secure and Compliant Compute ...
Jitesh Kunder
8 minute read
OCI Policy Analysis Part 3 – Bringing OCI Policy Intelligence to AI ...
Andrew Gregory
10 minute read
Why Quicknode, leading blockchain infrastructure provider chose ...
Mike Terra
3 minute read
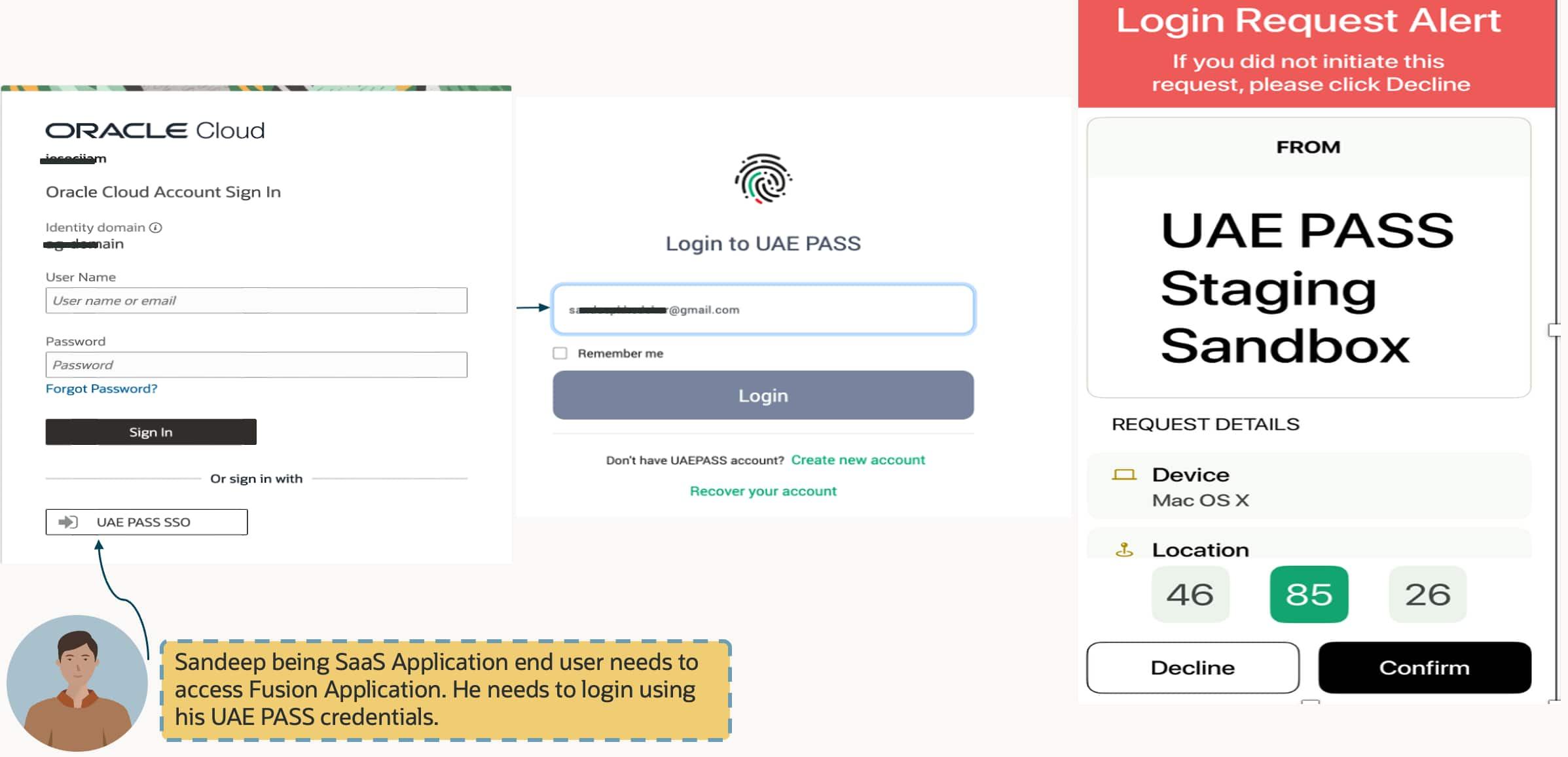
Beyond Social Login: Integrating UAE PASS as a National IdP with OCI ...
Sandeep Khedekar
7 minute read
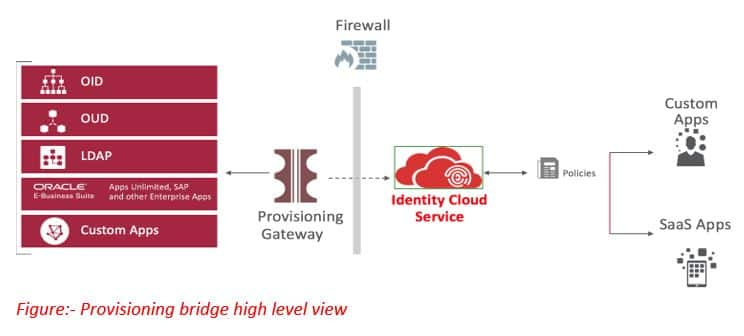
Automating User Lifecycle Management in On-Premises Applications
Atul Goyal
Ritesh Kumari
5 minute read
AI-Assisted Acceleration of Generic REST Integrations in Oracle ...
Nitin Popli
Pavan Gangadhar
5 minute read
Oracle Access Governance: New Updates for Identity Lifecycle ...
Abhishek Juneja
Atul Goyal
7 minute read
Build consumer applications that scale with modern identity and ...
Matthew Flynn
4 minute read
Cloud Infrastructure Security
See all
Why Resilience Requires Independence: A New Approach to Business ...
Damien Rilliard
Leon Mullally
4 minute read
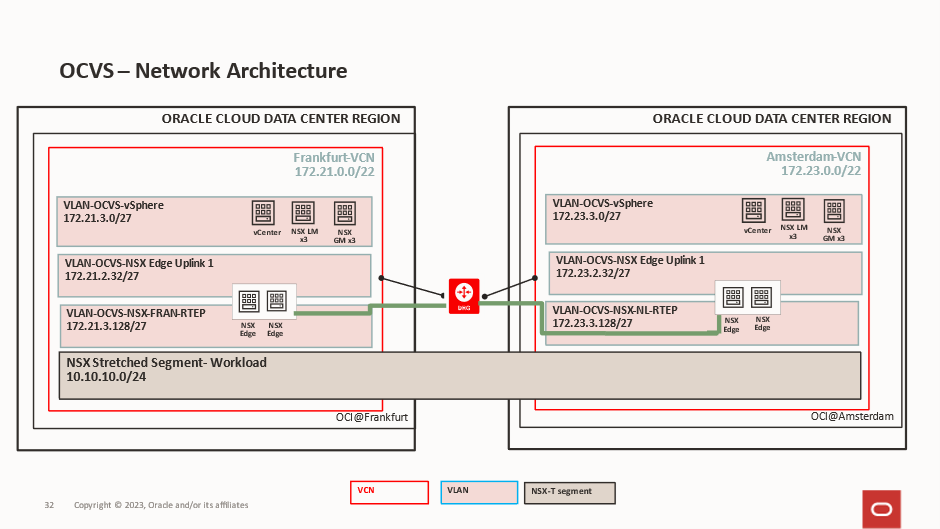
Architecting Multi-Region Networking and Security with NSX Federation ...
Bilal Ahmed
23 minute read
Certificate Best Practices for 2026 and Beyond: A Guide for Security ...
Meghana Vyakaranam
6 minute read
Announcing OKE support for Zero Trust Packet Routing (ZPR)
Kay Singh
10 minute read
Service Gateway vs Private Endpoint vs Private Service Access in OCI: ...
Arvind Bassan
Achinthya Gopinath
Brandon Beck
5 minute read
Developer Tools and Solutions
See all
OCI Container Services Newsletter (July 2026)
Jordan Spore
Mickey Boxell
Kay Singh
Chip Hwang
Shreshtha Saxena
Winston Lin
Kevin Liu
Jeetendra Kukreja
5 minute read
OCI Container Instances (CI) now support persistent file storage
Kevin Liu
Harshit Patel
3 minute read
Open-Source AI on OCI: Serving LLMs on Kubernetes with vLLM, Qdrant, ...
Deepak Khopade
6 minute read
OCI Functions Skills: AI-Guided Serverless Deployment and ...
Winston Lin
Vasishta Chemudupati
4 minute read
OKE Now Supports Clusters with up to 20,000 Worker Nodes
Jordan Spore
5 minute read
Understanding Digital Twin Models in OCI IoT Platform
Pete St. Pierre
9 minute read
Virtual Node Cycling: A Simpler Way to Keep Kubernetes Infrastructure ...
Shreshtha Saxena
Driviz Kumar
4 minute read
Queue-Driven Autoscaling on Kubernetes with KEDA, OKE, and OCI Queue
Srihari Babu Vaskuri
4 minute read
Strategy
See all
Building a 24/7 Healthcare Call Agent with ...
Saipriya Thirvakadu
Thangaraj Karol Stuart
5 minute read
Managing Custom Gold Images on OCI for Secure and Compliant Compute ...
Jitesh Kunder
8 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
Choosing NFS and OCI File Storage for shared data access
Vinoth Krishnamurthy
5 minute read
Raising the bar for trustworthy AI at Oracle: ISO/IEC 42001 ...
Heather VanCura
4 minute read
How to send required legal & ToS emails without ruining your ...
Josh Nason
3 minute read
Why API design matters for FinOps—and how OCI accelerates the rise of ...
Megan Walitsch
5 minute read
OCI Resource Analytics: Turn Cloud Inventory into Operational ...
Jordan Acosta
Sowjanya Yaddanapudi
4 minute read
Networking
See all
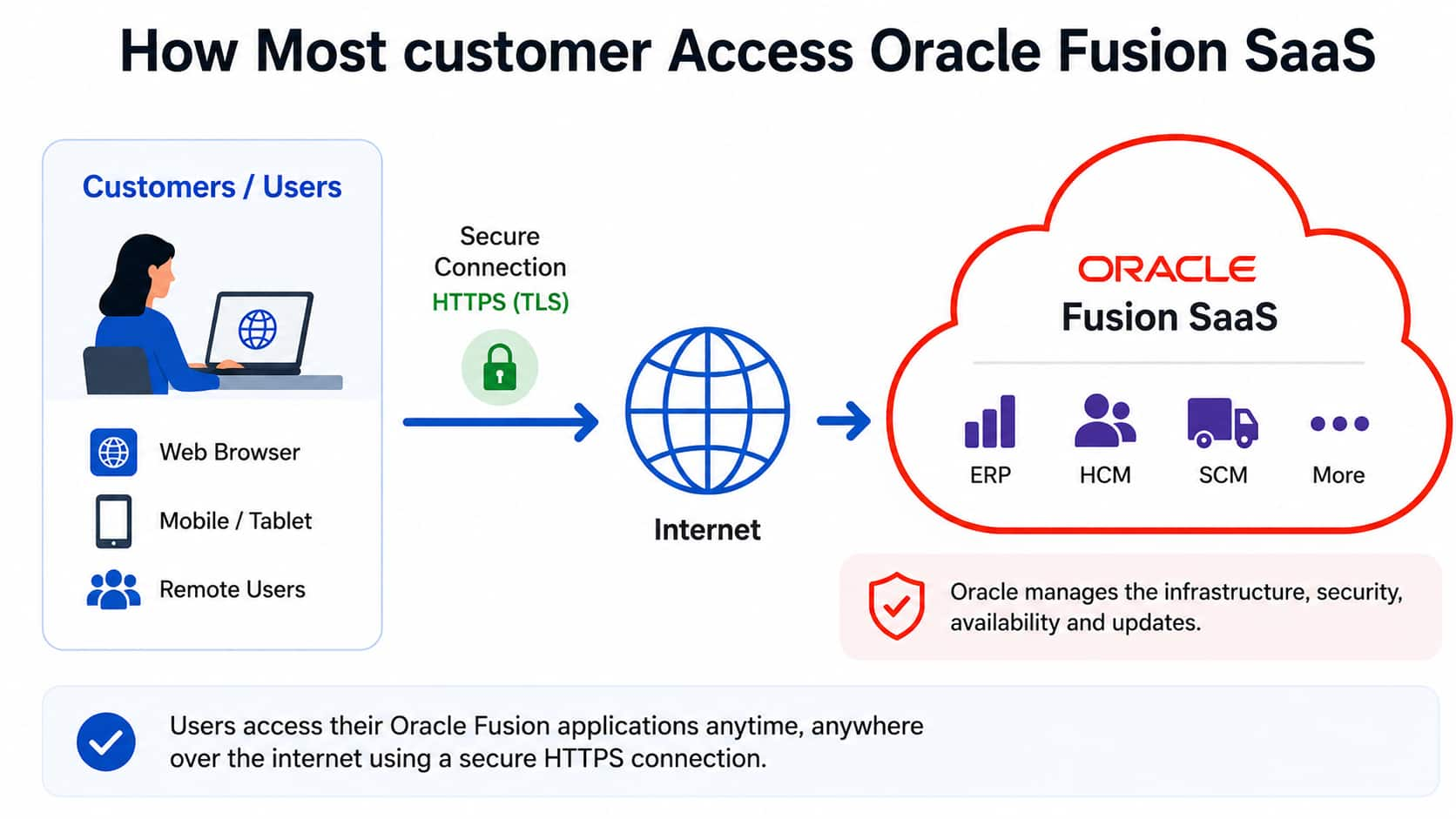
Accessing Oracle Fusion through private network using OCI Network ...
Par Kansala
Joshua Thomas
7 minute read
Architecting Multi-Region Networking and Security with NSX Federation ...
Bilal Ahmed
23 minute read
Oracle Database@AWS High Performance Networking
Firasathuddin Ahmed
3 minute read
Scaling Deep Inspection: What Our Benchmark Shows About OCI Network ...
Luis Catalan Hernandez
Par Kansala
6 minute read
Service Gateway vs Private Endpoint vs Private Service Access in OCI: ...
Arvind Bassan
Achinthya Gopinath
Brandon Beck
5 minute read
Automate DNS Record Creation in OCI Private DNS Zone with Python or ...
Arvind Bassan
Indiradarshni Balasundaram
4 minute read
Security & Identity
See all
The Key Behind the Claim: Customer-Managed Encryption in OKE
Farooq Nafey
6 minute read
Oracle External Key Management (EKMS) Support now available for ...
Mina Deng
Miranda Jimenez
SaaS Cloud Security
7 minute read
Why Resilience Requires Independence: A New Approach to Business ...
Damien Rilliard
Leon Mullally
4 minute read
Managing Custom Gold Images on OCI for Secure and Compliant Compute ...
Jitesh Kunder
8 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
Improve Object Storage Throughput with Bucket Keys
Melinda Centeno
3 minute read
OCI Policy Analysis Part 3 – Bringing OCI Policy Intelligence to AI ...
Andrew Gregory
10 minute read
Beyond Social Login: Integrating UAE PASS as a National IdP with OCI ...
Sandeep Khedekar
7 minute read
First Principles
See all
First Principles: Unlocking Oracle Acceleron Multiplanar Fabric with ...
Pradeep Vincent
Andrew Dickinson
David Becker
Diptanshu Singh
4 minute read
First Principles: Oracle Acceleron Multiplanar Networking Architecture
Pradeep Vincent
Jag Brar
David Becker
9 minute read
First Principles: Data Center Innovations to Power Gigawatt Scale ...
Pradeep Vincent
Ram Nagappan
1 minute read
First Principles: Oracle Acceleron Converged NIC for Next-Gen AI ...
Pradeep Vincent
6 minute read
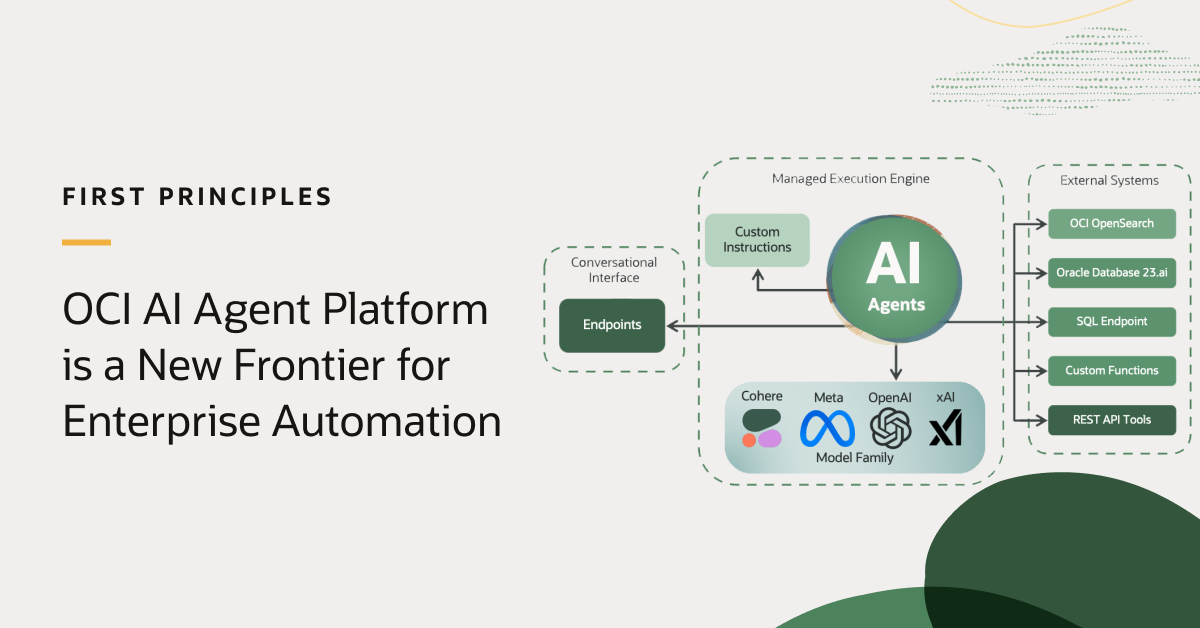
First Principles: OCI AI Agent Platform is a New Frontier for ...
Egor Pushkin
Pradeep Vincent
12 minute read
First Principles: Inside Zettascale OCI Superclusters for Next-gen AI
Jag Brar
Pradeep Vincent
10 minute read
First Principles: Robust data breach protection with Zero Trust ...
Pradeep Vincent
13 minute read
First Principles: Exploring the depths of OCI Generative AI Service
Egor Pushkin
Pradeep Vincent
13 minute read
Operations
See all
Automate DNS Record Creation in OCI Private DNS Zone with Python or ...
Arvind Bassan
Indiradarshni Balasundaram
4 minute read
Platform Leader
See all
OCI Cloud Achieves Exemplar Cloud with NVIDIA GB200 NVL72
Tolga Tekin
Jon Shelley
2 minute read
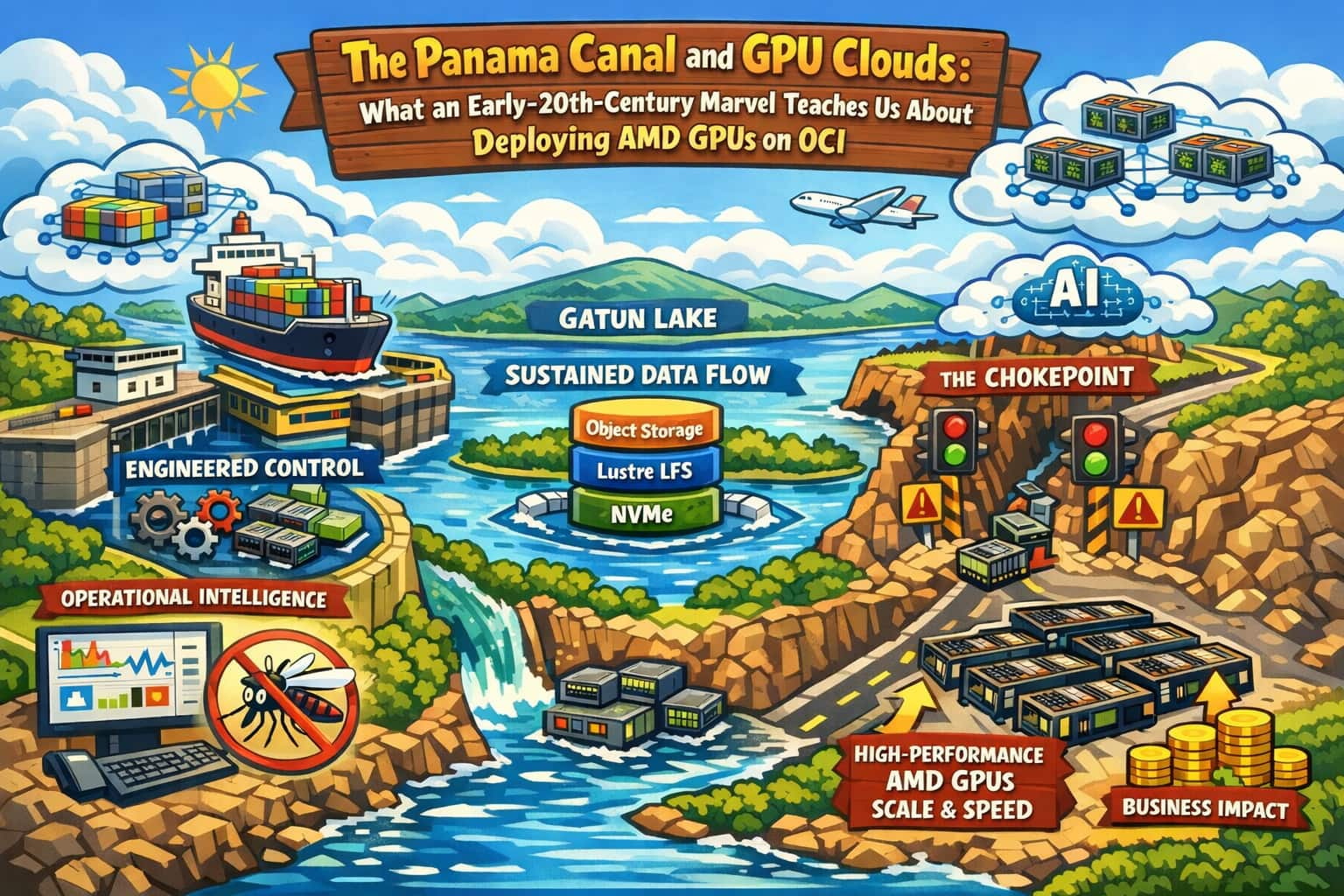
The Panama Canal and GPU Clouds: What an Early-20th-Century Marvel ...
Thiago Pereira
Ericka Salas
5 minute read
The Physics of Network Collapse: Why Seismic Imaging Demands Bare ...
João Speglich
Thiago Pereira
6 minute read
Zettascale in Practice: Scaling Beyond Limits — Flexible Fabric vs. ...
Leo Li
9 minute read
Oracle Cloud Infrastructure Earns Top Commercial Accreditation in ...
Viktor Nemec
2 minute read
Modernizing Heterogeneous Workloads on Oracle Cloud Infrastructure ...
Dev Gawale
10 minute read
Introducing Resource Locking: Securing and Safeguarding Your Critical ...
Allan Yeung
2 minute read
Oracle named a Challenger in 2025 Gartner® Magic Quadrant™ for ...
Deepak Arora
4 minute read
Industry Solutions
See all
Building a 24/7 Healthcare Call Agent with ...
Saipriya Thirvakadu
Thangaraj Karol Stuart
5 minute read
Modernizing healthcare interoperability with Oracle Cloud ...
Sean Ru
4 minute read
Oracle Video Edge: Orchestrating Large-Scale Live Streaming Across ...
Dustin Encelewski
Mathias Guille
4 minute read
Why Quicknode, leading blockchain infrastructure provider chose ...
Mike Terra
3 minute read
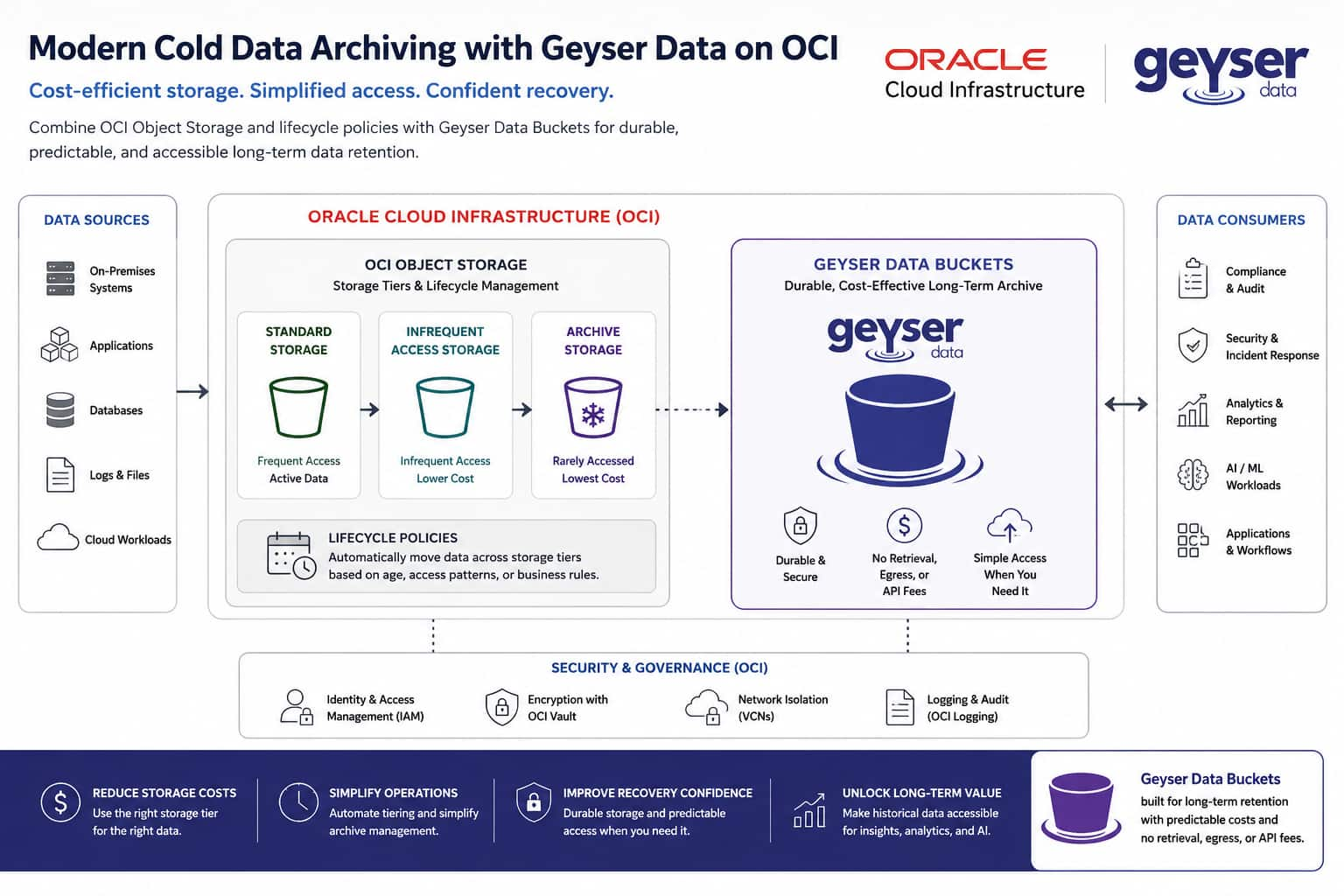
Modern Cold Data Archiving with Geyser Data on Oracle Cloud ...
Awais Ibrahim
6 minute read
Architecting Enterprise Imaging for Scale with Mach7 and OCI
Esteban Rubens
5 minute read
OCI Resource Analytics: Turn Cloud Inventory into Operational ...
Jordan Acosta
Sowjanya Yaddanapudi
4 minute read
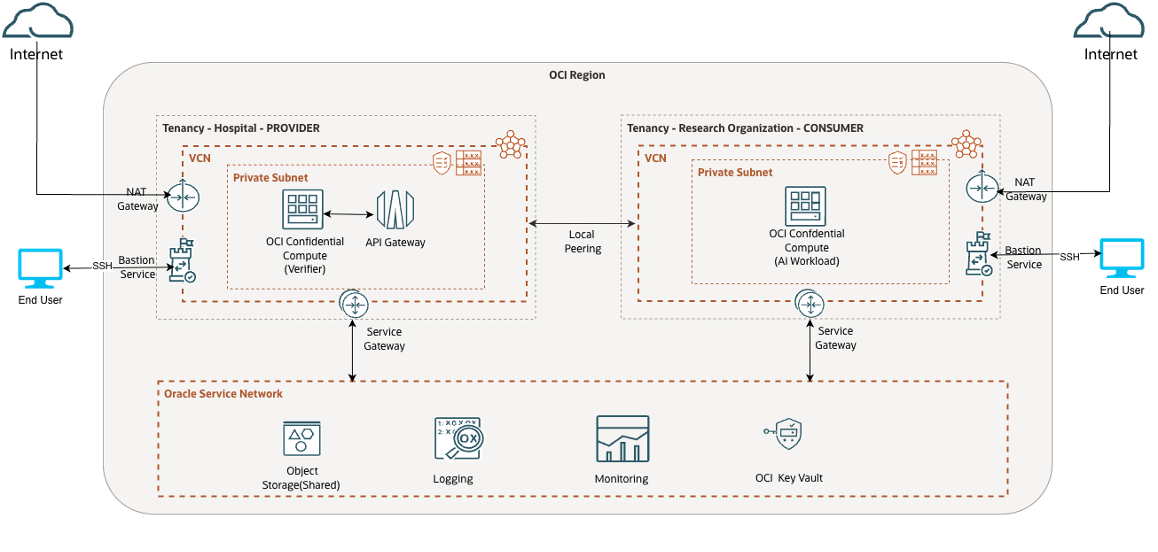
Protecting Sensitive Healthcare Workloads with Confidential Computing ...
Raghu Iyer
6 minute read
Performance Solutions
See all
Quantum Option Pricing on OCI A100s: 28 to 32 Qubit Benchmarks with ...
6 minute read
Run AI Inference Without GPUs
Sanjay Basu
8 minute read
Queue-Driven Autoscaling on Kubernetes with KEDA, OKE, and OCI Queue
Srihari Babu Vaskuri
4 minute read
OCI Cloud Achieves Exemplar Cloud with NVIDIA GB200 NVL72
Tolga Tekin
Jon Shelley
2 minute read
Choosing NFS and OCI File Storage for shared data access
Vinoth Krishnamurthy
5 minute read
Oracle AI Database@AWS Achieves Oracle MAA Platinum Certification and ...
Muneer Mirza
Pandit Prasad
Peter Kurkowski
Glen Hawkins
5 minute read
How Oracle Red Bull Racing Uses OCI and A4 Acceleron for Real-Time ...
Catherine Cacciotti
Miles Jackson
6 minute read
Scaling Deep Inspection: What Our Benchmark Shows About OCI Network ...
Luis Catalan Hernandez
Par Kansala
6 minute read
Partner Solutions
See all
Introducing DNS Resolution for Oracle Exadata Database on Dedicated ...
Partha Srinivasan
3 minute read
Why Quicknode, leading blockchain infrastructure provider chose ...
Mike Terra
3 minute read
OCI Cloud Achieves Exemplar Cloud with NVIDIA GB200 NVL72
Tolga Tekin
Jon Shelley
2 minute read
Microsoft Build recap – enabling developers to build AI apps grounded ...
Alan Patterson
2 minute read
Modern Cold Data Archiving with Geyser Data on Oracle Cloud ...
Awais Ibrahim
6 minute read
Architecting Enterprise Imaging for Scale with Mach7 and OCI
Esteban Rubens
5 minute read
Introducing Cloudflare@Oracle Cloud Infrastructure: Supercharge ...
Juliette Paterno
Tim Mclaughlin
5 minute read
How Oracle Red Bull Racing Uses OCI and A4 Acceleron for Real-Time ...
Catherine Cacciotti
Miles Jackson
6 minute read
Public Sector and Government
See all
Oracle Defence Tech Summit: Accelerating mission advantage through ...
Greg Magram
6 minute read
Duality and Oracle: Rethinking Data Sharing in Defense
Kelly Crooks
5 minute read
Airis Labs and Oracle Cloud Infrastructure bring AI-enabled media ...
Kelly Crooks
6 minute read
Shielding sensitive data with Oracle Cloud Infrastructure: Three ...
Mike Hart
Greg Magram
4 minute read
Preparing defense organizations for the post-quantum era with Oracle ...
Kelly Crooks
5 minute read
How OCI Delivers Cloud Consistency and Isolation: Gartner® Names ...
Alejandro Casas
Christian Linacre
5 minute read
Oracle’s GovRAMP authorization: What it means for US government ...
Jerry Niemeyer
3 minute read
Mission-ready sovereign AI with Oracle and Mattermost
Kelly Crooks
4 minute read
Behind the Scenes with OCI Engineering
See all
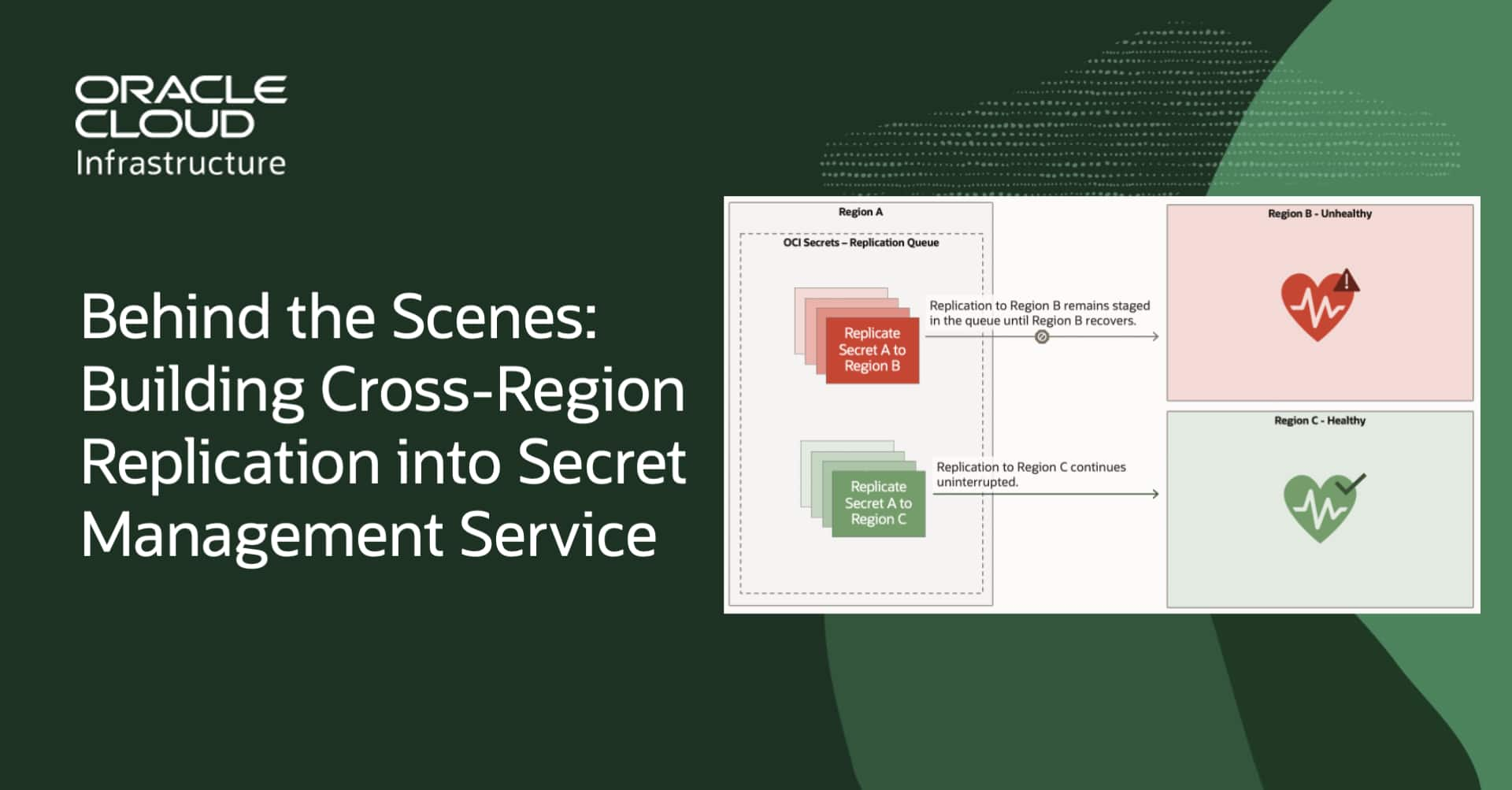
Behind the Scenes: Building Cross-Region Replication into Secret ...
Maia Whitley
10 minute read
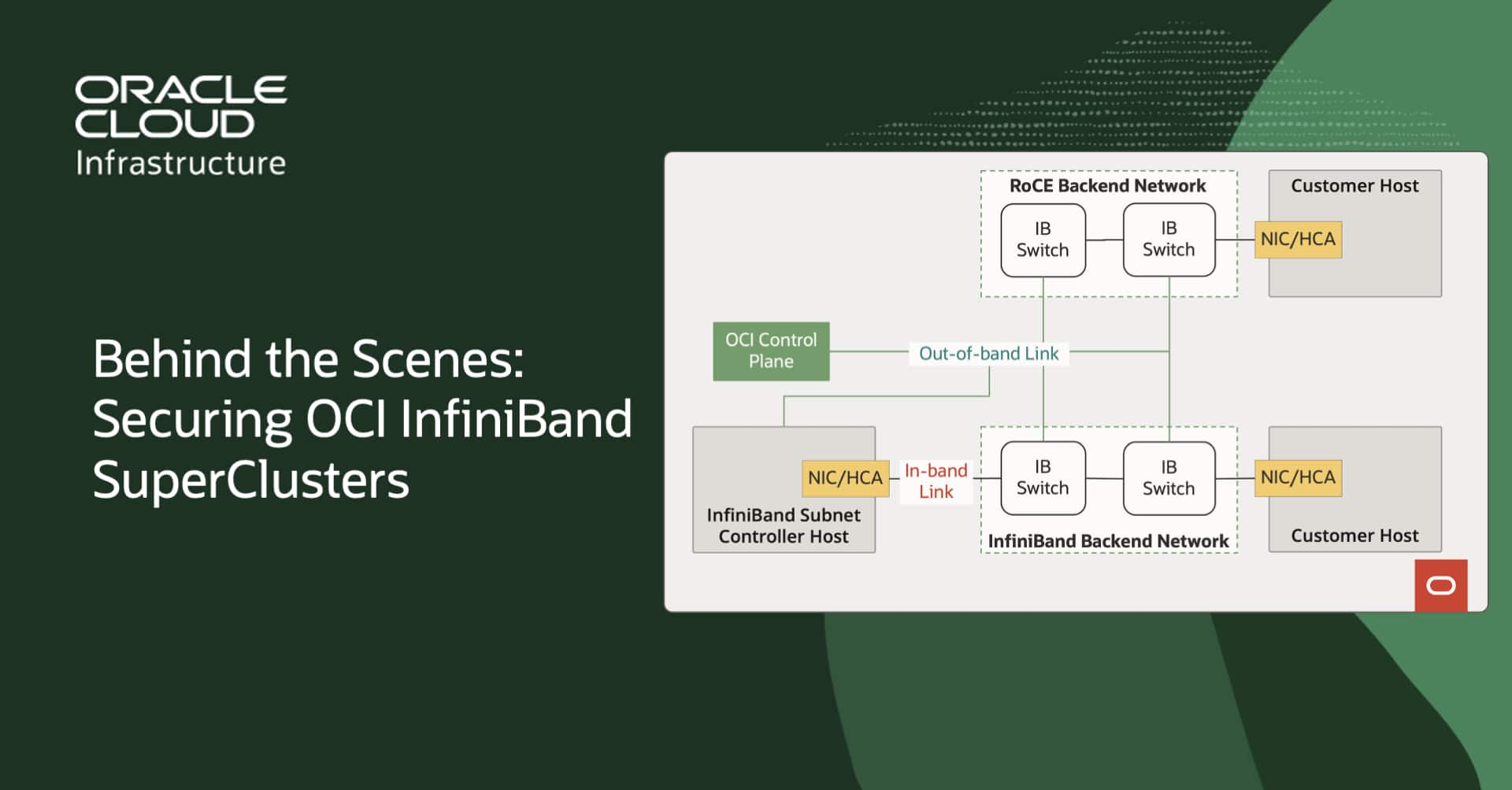
Behind the Scenes: Securing OCI InfiniBand SuperClusters
Dr. Nikhil Shetty
13 minute read
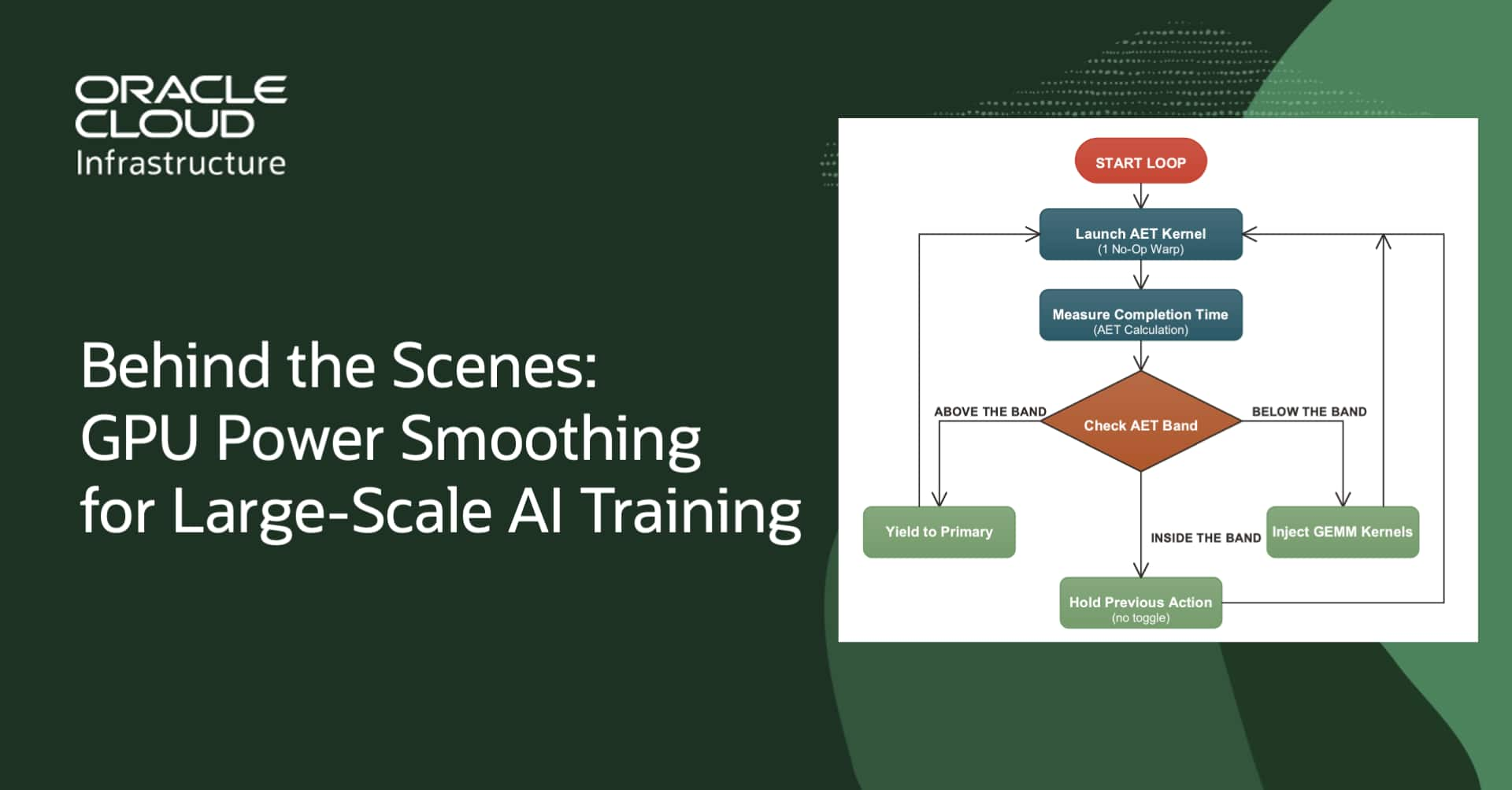
Behind the Scenes: GPU Power Smoothing for Large-Scale AI Training
Arash Saifhashemi
13 minute read
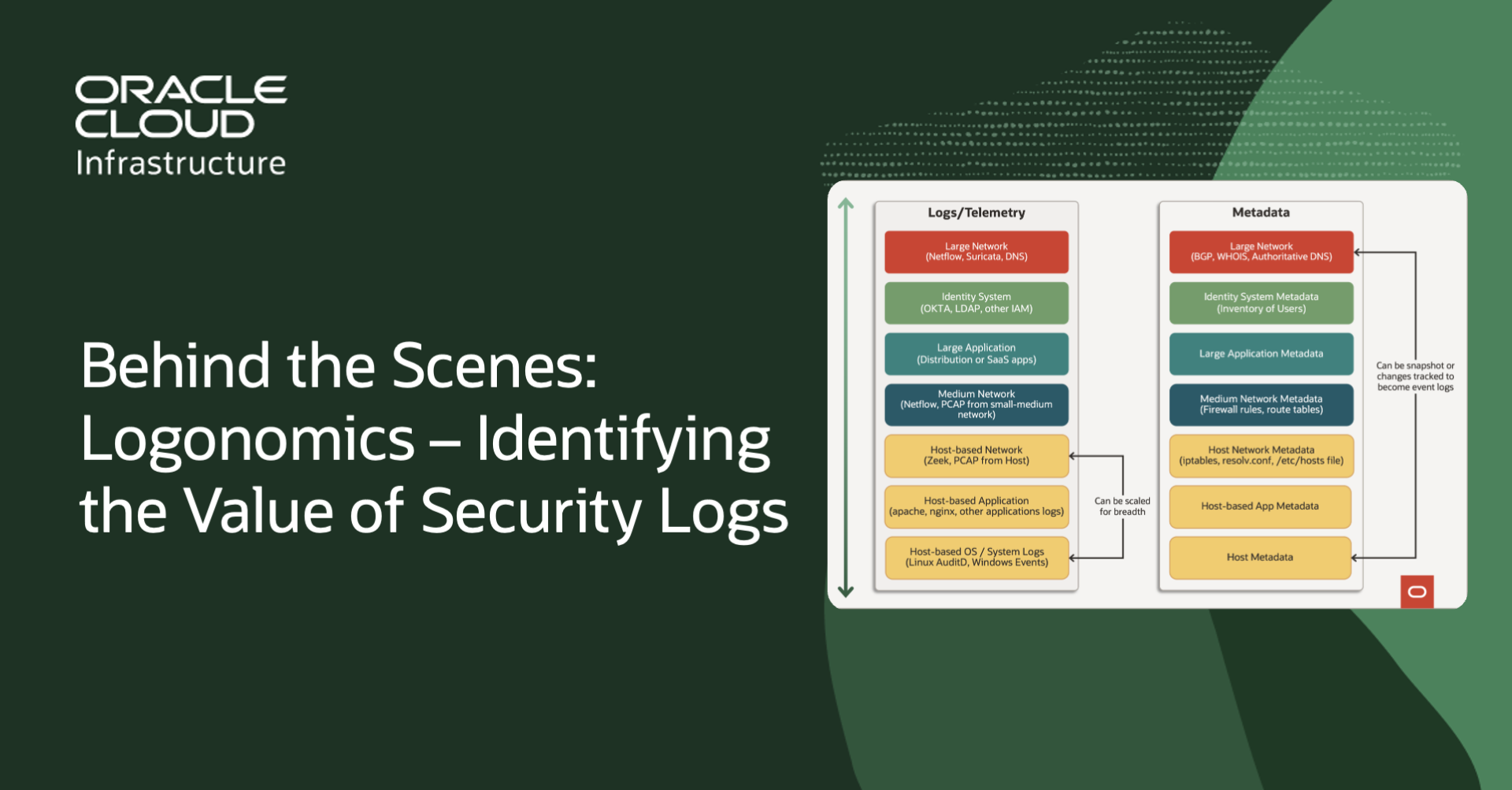
Behind the Scenes: Logonomics—Identifying the Value of Security Logs
Peter Hanily
10 minute read
Behind the Scenes: Scale your NVIDIA GB200 NVL72 deployments with ...
Harsh Verma
Sudhir Singh
Rik Kisnah
10 minute read
Behind the Scenes: Oracle’s Data-Driven Journey to Faster, Automated ...
Igor Vasilev
10 minute read
Behind the Scenes: Disaster Recovery in Minutes with HSM Write-Behind ...
Rakesh Ganimineni
12 minute read
Behind the Scenes: Scale your NVIDIA GB200 NVL72 deployments with ...
Harsh Verma
Sudhir Singh
Rik Kisnah
10 minute read
Compliance
See all
Managing Custom Gold Images on OCI for Secure and Compliant Compute ...
Jitesh Kunder
8 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
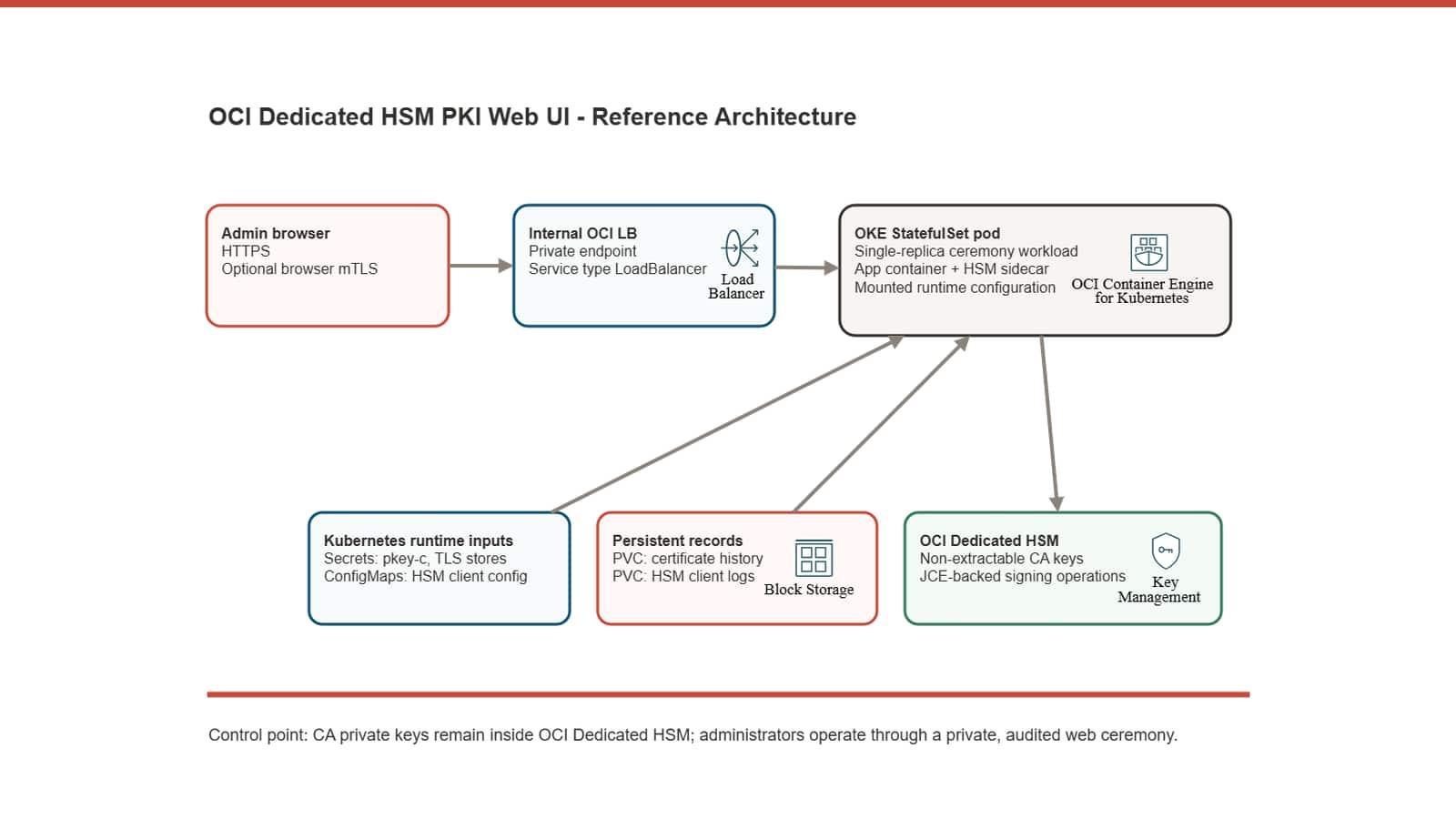
Build a secure private PKI with OCI Dedicated HSM and Kubernetes
Lodato Luciano
10 minute read
Oracle Access Governance: New Updates for Identity Lifecycle ...
Abhishek Juneja
Atul Goyal
7 minute read
Gaining Visibility into Your Network Exposure in OCI: A Practical ...
Michel Roitman
6 minute read
Gaining Visibility into Your Network Exposure in OCI: Why Context ...
Michel Roitman
4 minute read
Modern Cold Data Archiving with Geyser Data on Oracle Cloud ...
Awais Ibrahim
6 minute read
Introducing Cloudflare@Oracle Cloud Infrastructure: Supercharge ...
Juliette Paterno
Tim Mclaughlin
5 minute read
Distributed Cloud
See all
Announcing: Accelerating Enterprise AI with OCI Dedicated Cloud ...
Alejandro Casas
Kwang Ok
4 minute read
Announcing Enterprise AI for OCI Dedicated Cloud: Run AI where your ...
Alejandro Casas
Kwang Ok
4 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
Oracle Multicloud – What’s News
Nathan Thomas
Vijay Bangaru
Muneer Mirza
26 minute read
How OCI Delivers Cloud Consistency and Isolation: Gartner® Names ...
Alejandro Casas
Christian Linacre
5 minute read
Introducing the Next Generation of OCI Compute Shapes
Donald Lu
3 minute read
The Panama Canal and GPU Clouds: What an Early-20th-Century Marvel ...
Thiago Pereira
Ericka Salas
5 minute read
Oracle AI Database@Google Cloud: New Region Launches + Restore ...
Vijay Bangaru
2 minute read
Sovereignty
See all
Why Resilience Requires Independence: A New Approach to Business ...
Damien Rilliard
Leon Mullally
4 minute read
Announcing Enterprise AI for OCI Dedicated Cloud: Run AI where your ...
Alejandro Casas
Kwang Ok
4 minute read
Shielding sensitive data with Oracle Cloud Infrastructure: Three ...
Mike Hart
Greg Magram
4 minute read
How OCI Delivers Cloud Consistency and Isolation: Gartner® Names ...
Alejandro Casas
Christian Linacre
5 minute read
The Panama Canal and GPU Clouds: What an Early-20th-Century Marvel ...
Thiago Pereira
Ericka Salas
5 minute read
European standards, international harmonization, and digital ...
Machiel Bolhuis
6 minute read
Oracle EU Sovereign Cloud – Reflecting on the Journey and Lessons ...
Cormac Watters
7 minute read
Autonomous AI Database
See all
Putting Customers First, Together: A Year of Oracle AI Database@AWS ...
Nathan Thomas
6 minute read
Oracle AI Database@AWS Achieves Oracle MAA Platinum Certification and ...
Muneer Mirza
Pandit Prasad
Peter Kurkowski
Glen Hawkins
5 minute read
Run a Self-Managed Oracle Database in AWS with Autonomous AI Database ...
Muneer Mirza
Rakshana Balakrishnan
Peter Kurkowski
6 minute read
OCI Database AI Vector Search: A Practical Step-by-Step approach
ANUPAM ABHISHEK
5 minute read
Migration from On-Premises Oracle Database to ADB@Azure using ZDM and ...
ANUPAM ABHISHEK
5 minute read
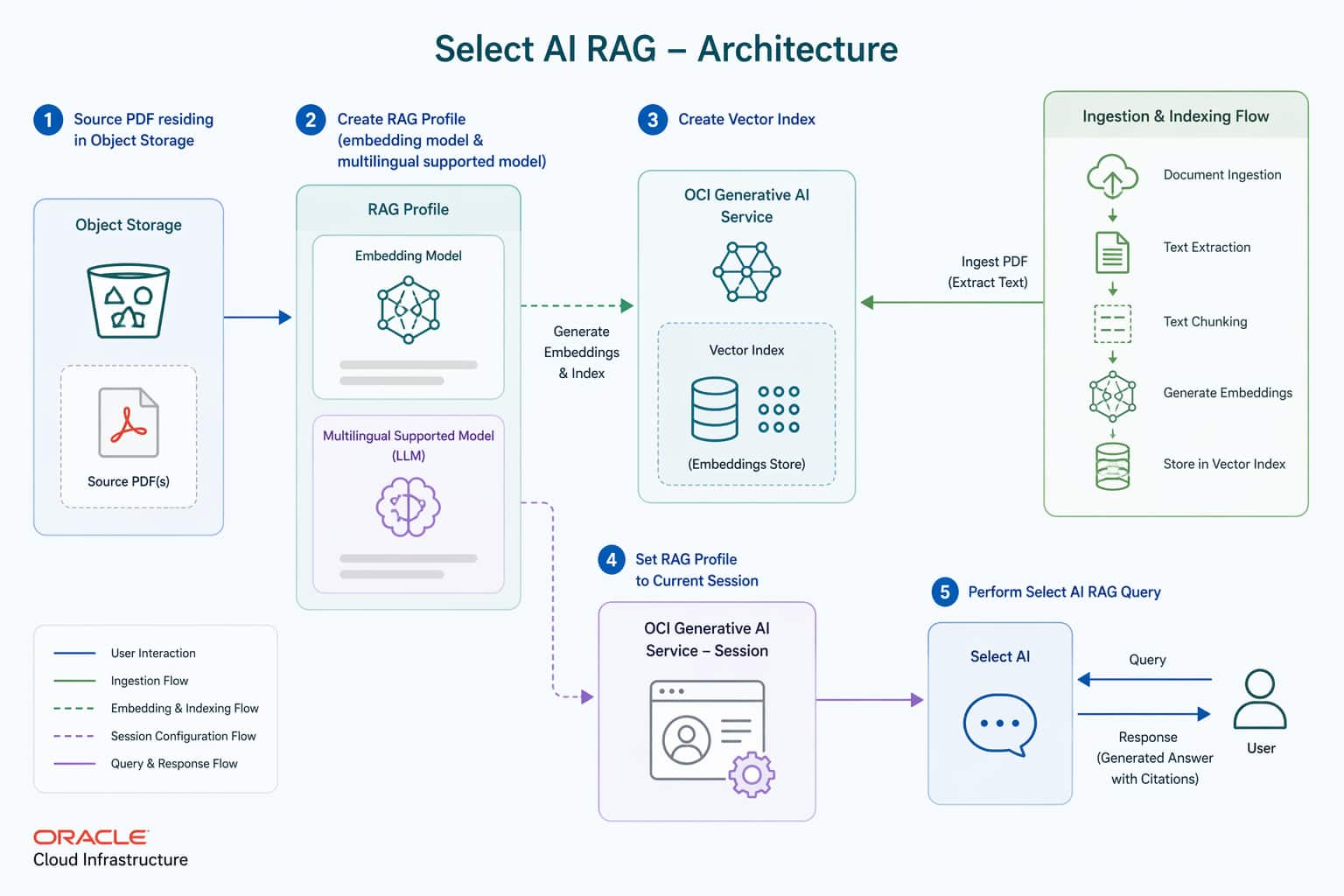
How Oracle ADB Eliminates RAG Complexity: Native Select AI with OCI ...
Sathishkumar Rangaraj
7 minute read
Oracle Defense Ecosystem
See all
Oracle Defence Tech Summit: Accelerating mission advantage through ...
Greg Magram
6 minute read
Duality and Oracle: Rethinking Data Sharing in Defense
Kelly Crooks
5 minute read
Airis Labs and Oracle Cloud Infrastructure bring AI-enabled media ...
Kelly Crooks
6 minute read
Preparing defense organizations for the post-quantum era with Oracle ...
Kelly Crooks
5 minute read
Mission-ready sovereign AI with Oracle and Mattermost
Kelly Crooks
4 minute read
Oracle Cloud Infrastructure and Reka: A 4-Step Approach to AI-Driven ...
Maria Duany
5 minute read
Oracle Cloud Infrastructure and American Binary: Post-quantum threats ...
Maria Duany
5 minute read
Empowering warfighters at the tactical edge with the Oracle Defense ...
Greg Magram
5 minute read
Oracle AI
See all
Announcing: Accelerating Enterprise AI with OCI Dedicated Cloud ...
Alejandro Casas
Kwang Ok
4 minute read
Announcing Enterprise AI for OCI Dedicated Cloud: Run AI where your ...
Alejandro Casas
Kwang Ok
4 minute read
Open-Source AI on OCI: Serving LLMs on Kubernetes with vLLM, Qdrant, ...
Deepak Khopade
6 minute read
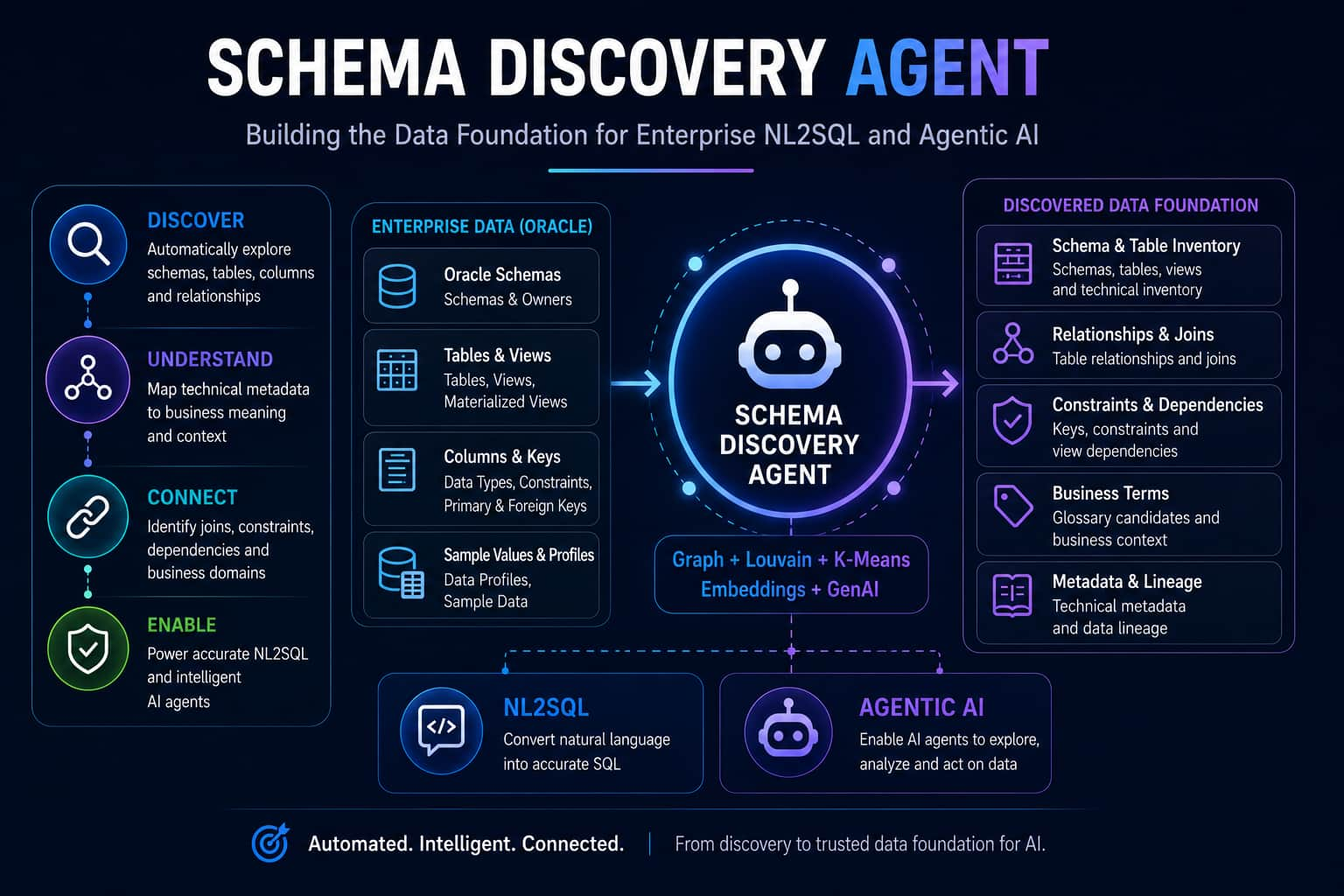
Schema Discovery Agent (Building the Data Foundation for Enterprise ...
Harihara Vijayakumar
Shravya Madhyastha
12 minute read
Putting Customers First, Together: A Year of Oracle AI Database@AWS ...
Nathan Thomas
6 minute read
Oracle AI Database@AWS Achieves Oracle MAA Platinum Certification and ...
Muneer Mirza
Pandit Prasad
Peter Kurkowski
Glen Hawkins
5 minute read
Run a Self-Managed Oracle Database in AWS with Autonomous AI Database ...
Muneer Mirza
Rakshana Balakrishnan
Peter Kurkowski
6 minute read
Go From Questions to Insights with Oracle AI Database 26ai
Gloria Hughes
5 minute read
Oracle Cloud Infrastructure (OCI)
See all
Introducing the OCI OKE Troubleshooter Skill
Chip Hwang
7 minute read
How Nanoprecise migrated AI workloads from AWS to OCI and cut cloud ...
Brindha Balan
5 minute read
Why Resilience Requires Independence: A New Approach to Business ...
Damien Rilliard
Leon Mullally
4 minute read
Building a 24/7 Healthcare Call Agent with ...
Saipriya Thirvakadu
Thangaraj Karol Stuart
5 minute read
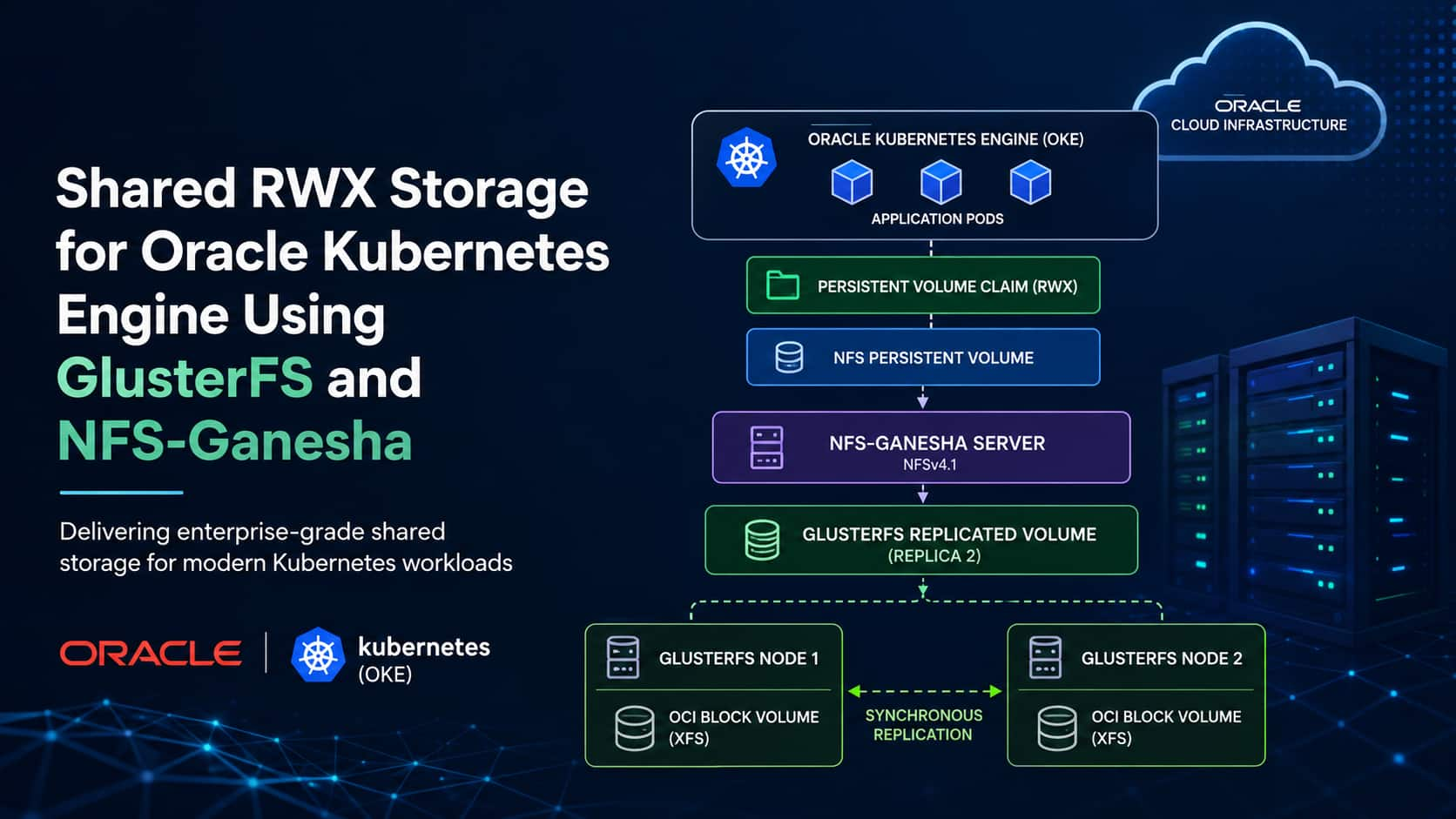
GlusterFS Integration with Oracle Kubernetes Engine
Payal Sharma
7 minute read
Oracle Video Edge: Orchestrating Large-Scale Live Streaming Across ...
Dustin Encelewski
Mathias Guille
4 minute read
OCI Container Instances (CI) now support persistent file storage
Kevin Liu
Harshit Patel
3 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
Technical Solutions
See all
Rethinking Xstore deployment on OCI: From monolithic delivery to a ...
Adina Nicolescu
Paolo Lovati
5 minute read
Introducing the OCI OKE Troubleshooter Skill
Chip Hwang
7 minute read
How Nanoprecise migrated AI workloads from AWS to OCI and cut cloud ...
Brindha Balan
5 minute read
GlusterFS Integration with Oracle Kubernetes Engine
Payal Sharma
7 minute read
Oracle Video Edge: Orchestrating Large-Scale Live Streaming Across ...
Dustin Encelewski
Mathias Guille
4 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
Open-Source AI on OCI: Serving LLMs on Kubernetes with vLLM, Qdrant, ...
Deepak Khopade
6 minute read
Why Quicknode, leading blockchain infrastructure provider chose ...
Mike Terra
3 minute read
Use Cases
See all
How Nanoprecise migrated AI workloads from AWS to OCI and cut cloud ...
Brindha Balan
5 minute read
GlusterFS Integration with Oracle Kubernetes Engine
Payal Sharma
7 minute read
Oracle Video Edge: Orchestrating Large-Scale Live Streaming Across ...
Dustin Encelewski
Mathias Guille
4 minute read
Open-Source AI on OCI: Serving LLMs on Kubernetes with vLLM, Qdrant, ...
Deepak Khopade
6 minute read
Democratizing Supercomputing: How OCI Transforms Computational Power ...
Deepak Khopade
4 minute read
OCI GoldenGate Data Streams: Turning Database Changes into Revenue ...
Desmond Tay
5 minute read
Why Quicknode, leading blockchain infrastructure provider chose ...
Mike Terra
3 minute read
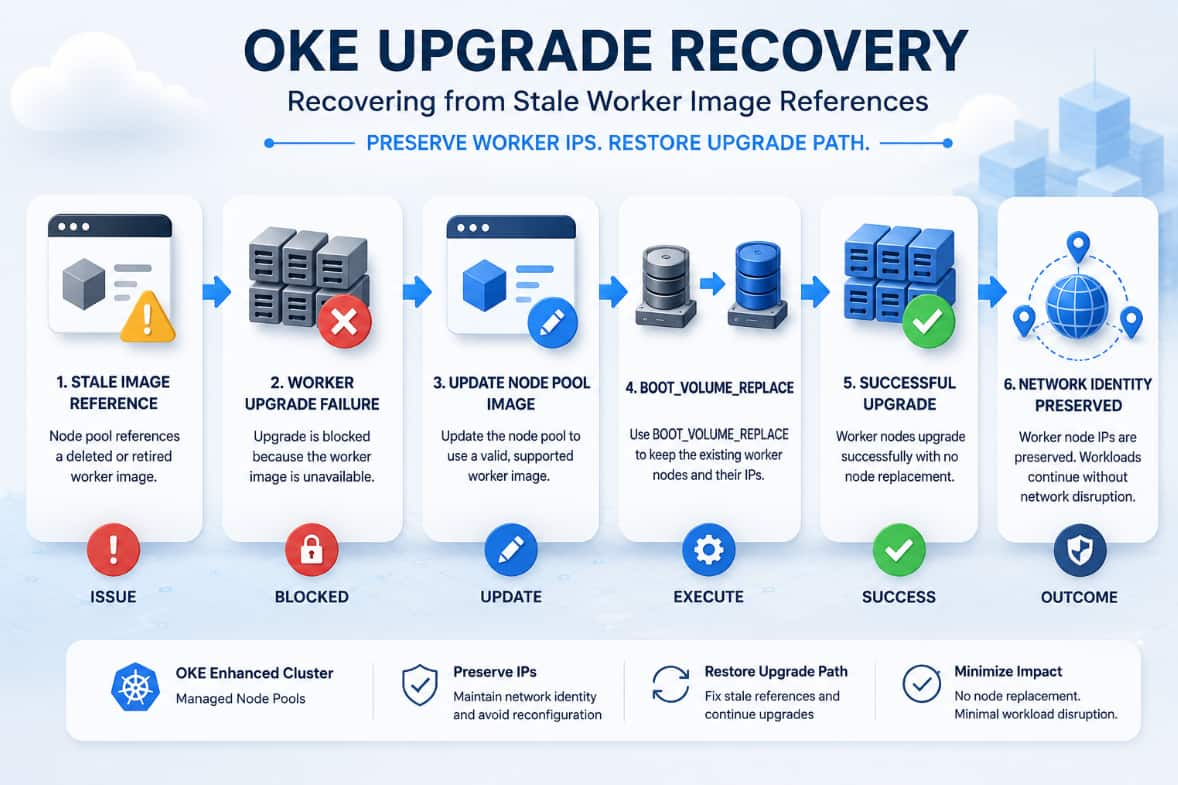
Recovering OKE Node Pool Upgrades from Stale Worker Image References
Payal Sharma
Maulik Modi
6 minute read
Receive the latest OCI news
Subscribe to the Oracle Cloud Insider Newsletter
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers