Introduction
Over the last decade, machine learning has evolved from experimental data science projects into mission-critical enterprise workloads. Yet many organizations still struggle to move beyond isolated notebooks and prototypes. The real challenge is not building models, it is operationalizing them at scale.
Data scientists can create highly accurate models in controlled environments, but production introduces a different reality. Models behave differently with real-world data, deployments become manual and inconsistent, teams lose visibility into model behavior over time, and collaboration across data science, engineering, and operations starts to break down. This gap between experimentation and production is often called the last mile problem in machine learning.
MLOps is the discipline that closes this gap. It introduces automation, standardization, and governance across the model lifecycle, much like DevOps did for application delivery. In this blog, a practical way to bridge that last mile and build a repeatable, scalable, and production-ready path from model development to reliable inference is shown
Core Concepts
The core idea is simple: treat machine learning as a continuous flow, not a one-time experiment. A healthy MLOps setup moves from source changes to build, training, model tracking, deployment, and monitoring in a predictable rhythm. Each stage hands off cleanly to the next, so teams spend less time firefighting and more time improving models. MLflow ties the pipeline together by keeping experiment results and model versions in one place. That shared record helps everyone stay aligned, from training runs to live inference updates. It also makes model promotion a controlled step instead of a guess. Security and operations are part of the pipeline, not an afterthought. Secrets, access control, and logs are handled as standard parts of day-to-day workflows so troubleshooting is faster and production behavior is easier to trust.

Figure 1. Basic MLOps Pipeline
The pipeline begins when a meaningful change is introduced, either in data preparation, model logic, or serving behavior. That change triggers a repeatable build path, where artifacts are packaged and stored in a way that keeps versions organized and easy to trace.
From there, training runs produce model outputs along with the context needed to understand them, including metrics and run history. Instead of treating each run as isolated, the pipeline captures results in a shared tracking layer so teams can compare experiments and confidently decide what should move forward.
The final stages focus on releasing and operating the model in production. Deployment promotes a selected model version to a live service, and observation closes the loop by watching health, predictions, and runtime behavior over time. This is what turns machine learning from a one-off activity into a dependable product lifecycle.
At a high level, the pipeline covers seven essentials: source and trigger, build, artifact storage, training, tracking and registry, deployment, and observation. Oracle Cloud Infrastructure (OCI) services and open-source tools map naturally to these steps, giving a practical structure that is easy to follow without making the process heavy.
End to End Architecture Overview
The following architecture diagram illustrates the full lifecycle and service interactions discussed in this section.
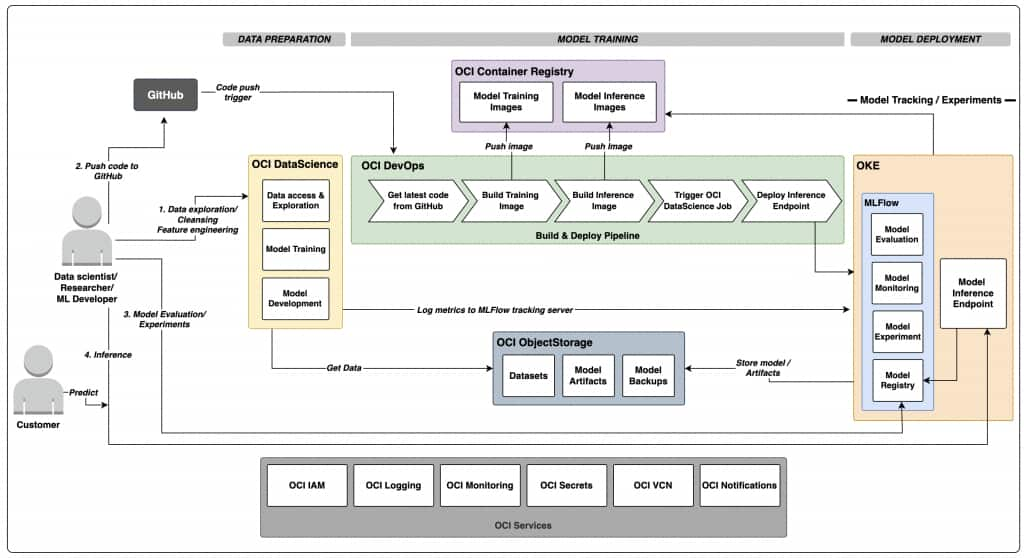
Figure 2. MLOps architecture on OCI
The flow starts in GitHub. A push to the main branch, scoped by configured path filters, triggers OCI DevOps. The build pipeline prepares two image paths: one for training and one for serving. Both images are pushed to OCIR, so they are versioned and available for controlled deployments.
After the build stage, the pipeline triggers a OCI Data Science job run. This is where model training happens in a managed, containerized runtime. The training run logs experiment details and model artifacts to MLflow. Artifacts and datasets are backed by OCI Object Storage, which keeps data externalized and durable instead of tied to ephemeral job runtimes.
When training is complete, the deploy pipeline updates the serving workload on OCI Kubernetes Engine (OKE). The serving app exposes health and prediction endpoints and pulls the right model state through MLflow tracking configuration. Because deployment is pipeline-driven, rollout is consistent and repeatable, and the same process can be reused across future model updates.
Networking is structured to support both access and control. OKE runs inside a VCN with dedicated subnets, and services such as MLflow and model serving can be exposed through load balancer endpoints. OCI Data Science runs use configured subnet placement and log configuration so operational visibility is preserved from day one.
Observability spans the full chain. DevOps project logs capture CI/CD behavior, while OCI Data Science job logs capture training execution details. This becomes critical during incident handling. For example, if a training run fails, teams can quickly determine whether the issue is model code, network reachability, secret access, or endpoint configuration.
Key Benefits of OCI for MLOps
One major benefit is service integration without forcing teams into fragmented tooling. OCI DevOps, OCI Data Science, OKE, OCI Logging, OCI Vault, and OCI Object Storage can be composed into a single workflow that feels cohesive rather than stitched together. This reduces glue code and operational overhead.
Another benefit is operational clarity. OCI Data Science jobs provide a managed training runtime that works well with container workflows. OKE provides flexibility for serving modern APIs and model inference services. OCI Logging and OCI Identity and Access Management (IAM) make it practical to run this in a way that is observable and governed, not just functional.
An equally important benefit is the ability to keep using open-source tooling on OCI without redesigning the workflow. Teams can build with familiar packages such as MLflow, scikit-learn, pandas, FastAPI, and Docker/Kubernetes patterns, while OCI provides the managed foundation around them. This balance is valuable because it avoids hard dependency on proprietary model formats or platform-specific serving logic, making it easier to move workloads, retrain elsewhere, or extend across multi-cloud and hybrid environments over time.
Security posture improves significantly when secrets and access are treated as platform features. With Vault-backed secrets, scoped OCI IAM policies, and Terraform-managed resources, teams avoid many common risks caused by ad-hoc credentials and manual configuration drift.
OCI is also strong when it comes to scaling from a single team setup to broader organizational use. The same patterns in this workspace can be expanded across environments, projects, and model families with minimal redesign. Since everything is infrastructure-as-code, standardization becomes realistic.
Summary
Good MLOps is less about adding process for its own sake and more about removing uncertainty. This workspace demonstrates that principle clearly: training, tracking, deployment, and serving are connected in a repeatable, observable, and secure path.
By combining OCI DevOps, OCI Data Science, OKE, MLflow, and supporting services through Terraform, the project moves from “it works on my notebook” to “it works as a system.” The value is not only speed, but trust: teams know what is deployed, how it got there, and how to diagnose it when something goes wrong.
If you are trying to operationalize ML in a way that feels production-ready without becoming overly complex, this architecture is a practical and scalable foundation.

