Accessibility Policy
Skip to content
Oracle
Maximum Availability Architecture
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
Backup & Recovery
Blogs Home
RSS
Maximum Availability Architecture
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
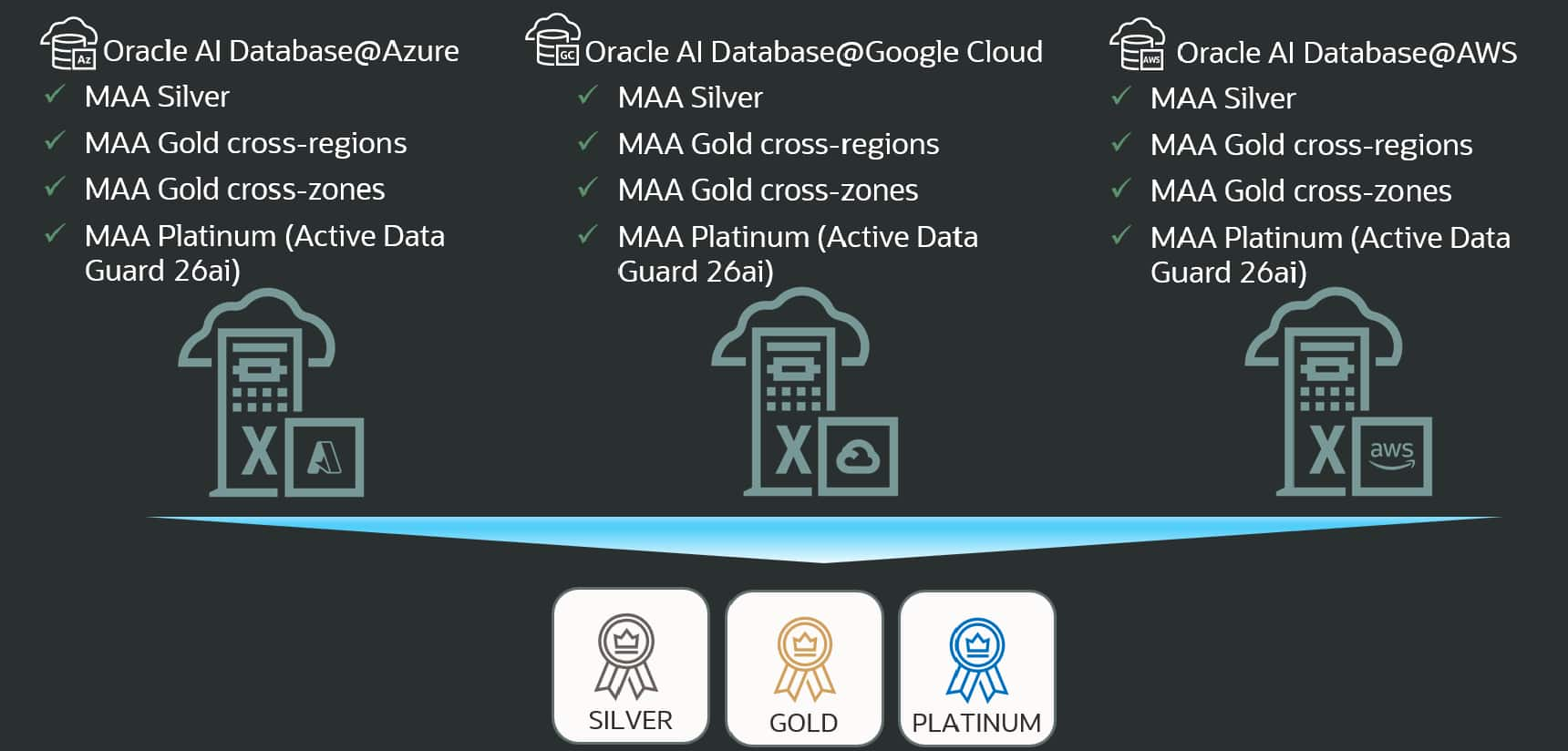
Oracle AI Database 26ai and Active Data Guard Advance MAA Platinum ...
Glen Hawkins
4 minute read
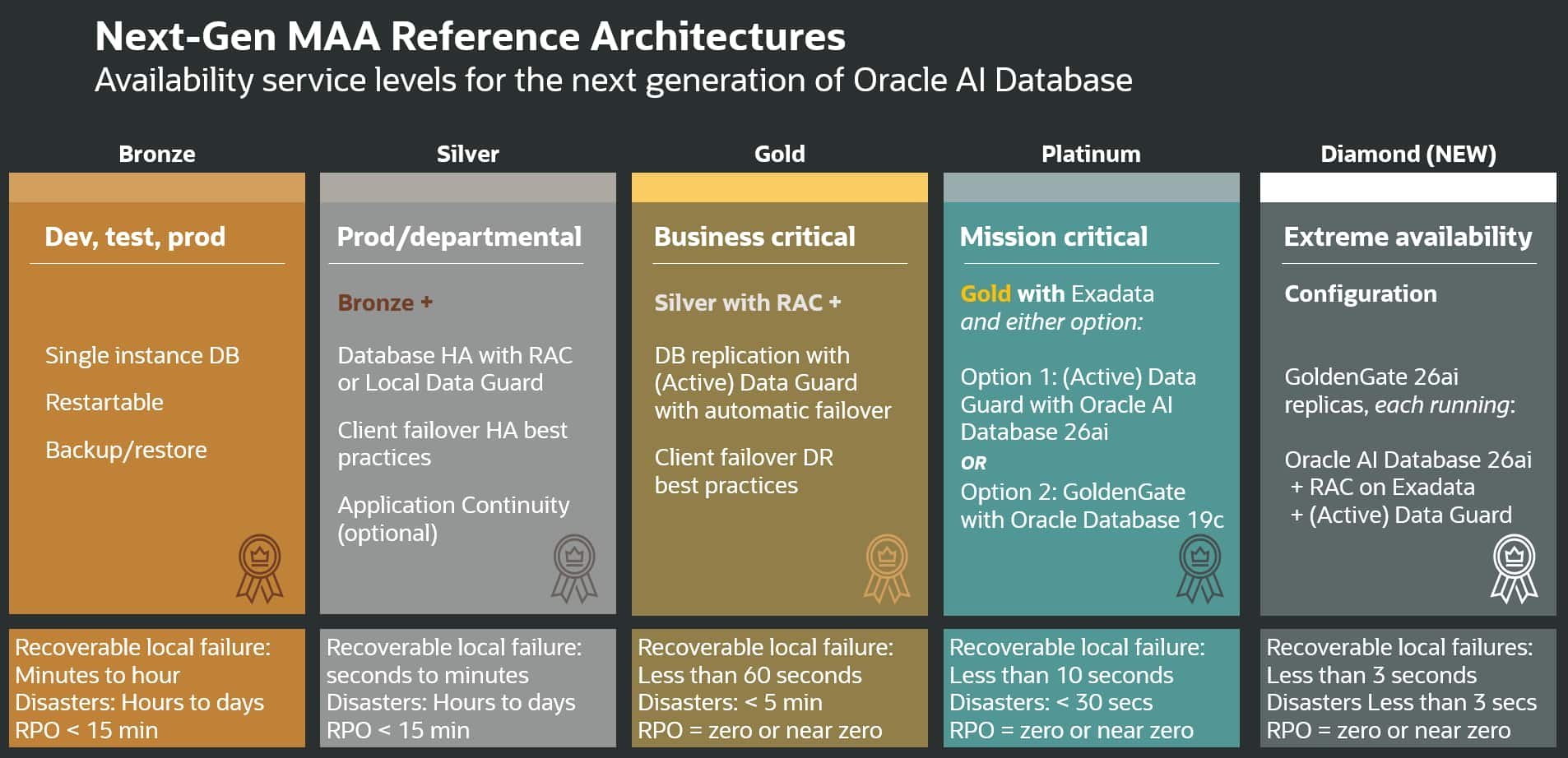
Ascend to the Diamond Tier: Introducing the Next-Gen Oracle Maximum ...
Glen Hawkins
3 minute read
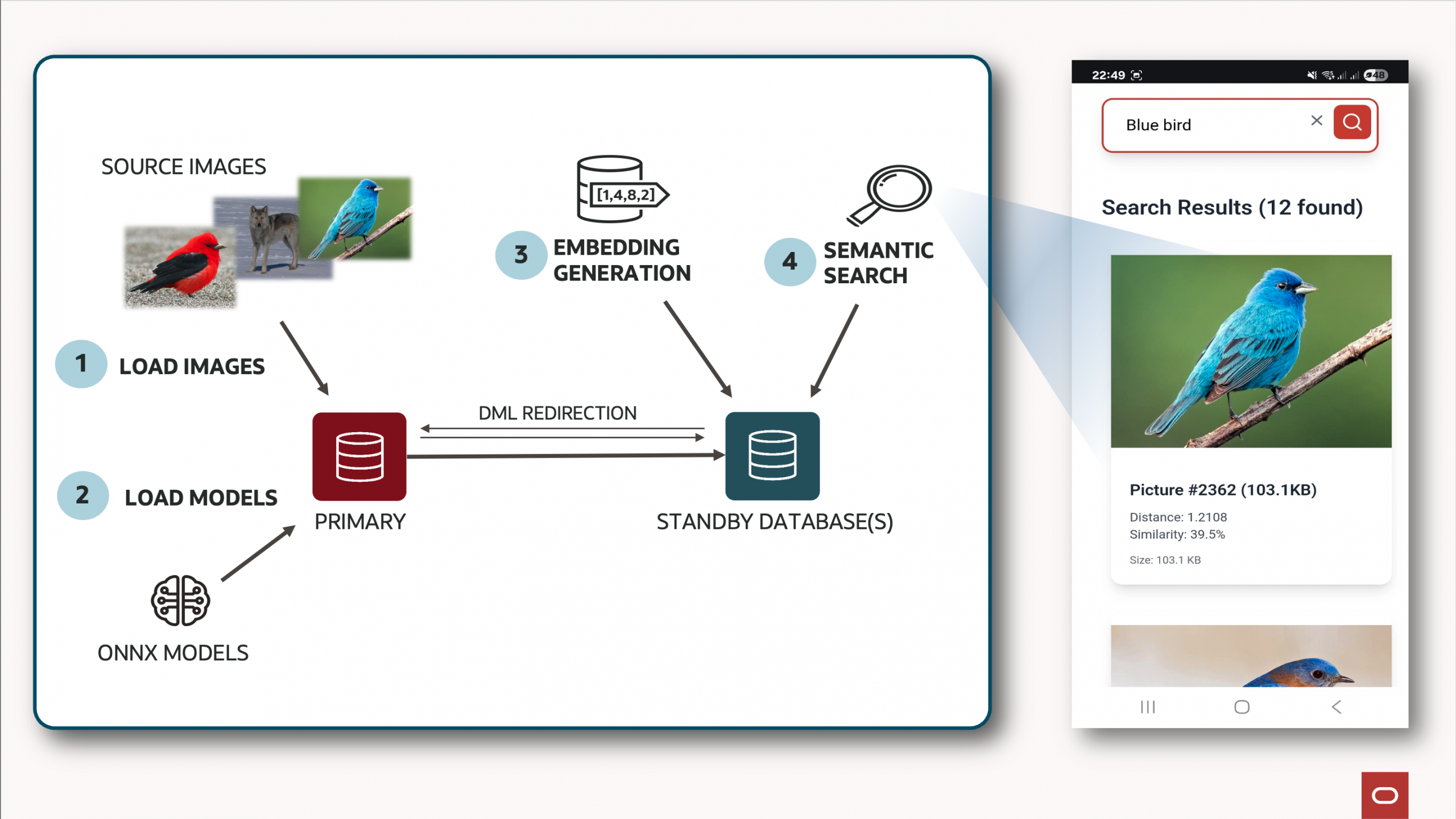
In-database AI inference on Oracle Active Data Guard: A practical ...
Ludovico Caldara
7 minute read
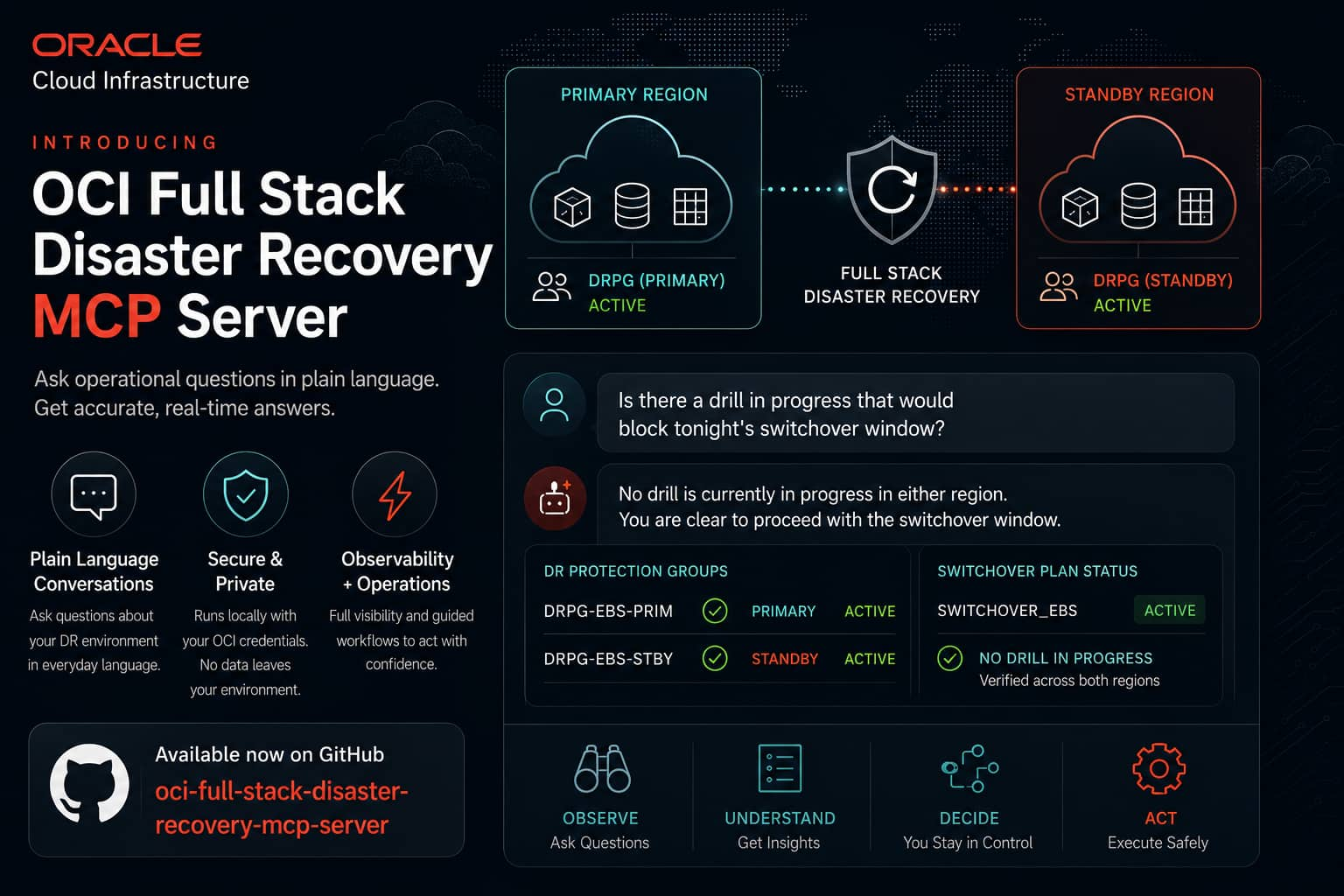
Introducing the OCI Full Stack Disaster Recovery MCP Server
Suraj Ramesh
8 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Recent Posts
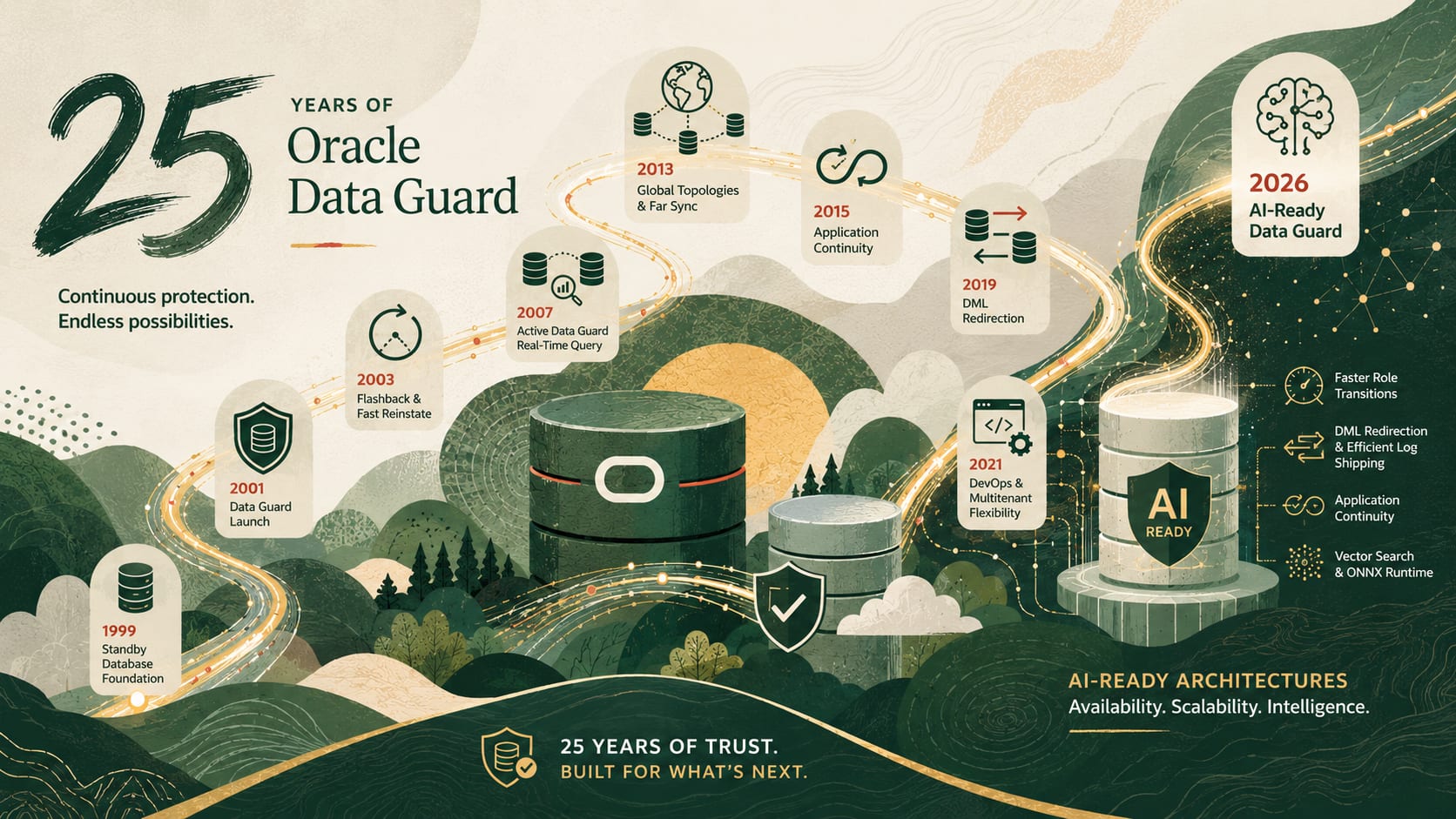
Happy 25th anniversary, Oracle Data Guard!
Ludovico Caldara
4 minute read
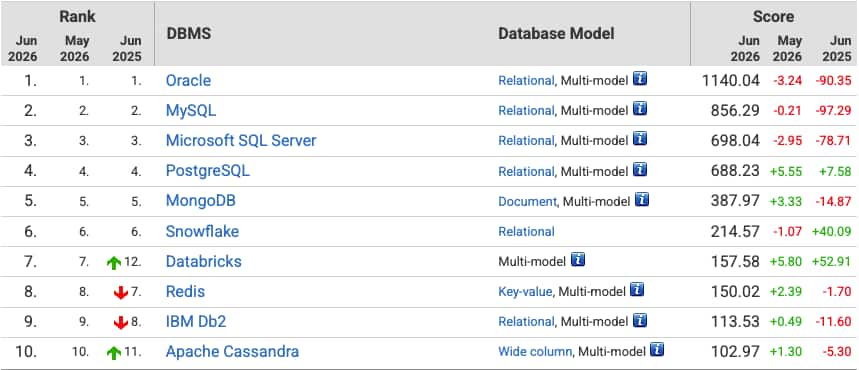
Evaluating Databases for Mission-Critical Workloads – ...
Markus Michalewicz
9 minute read
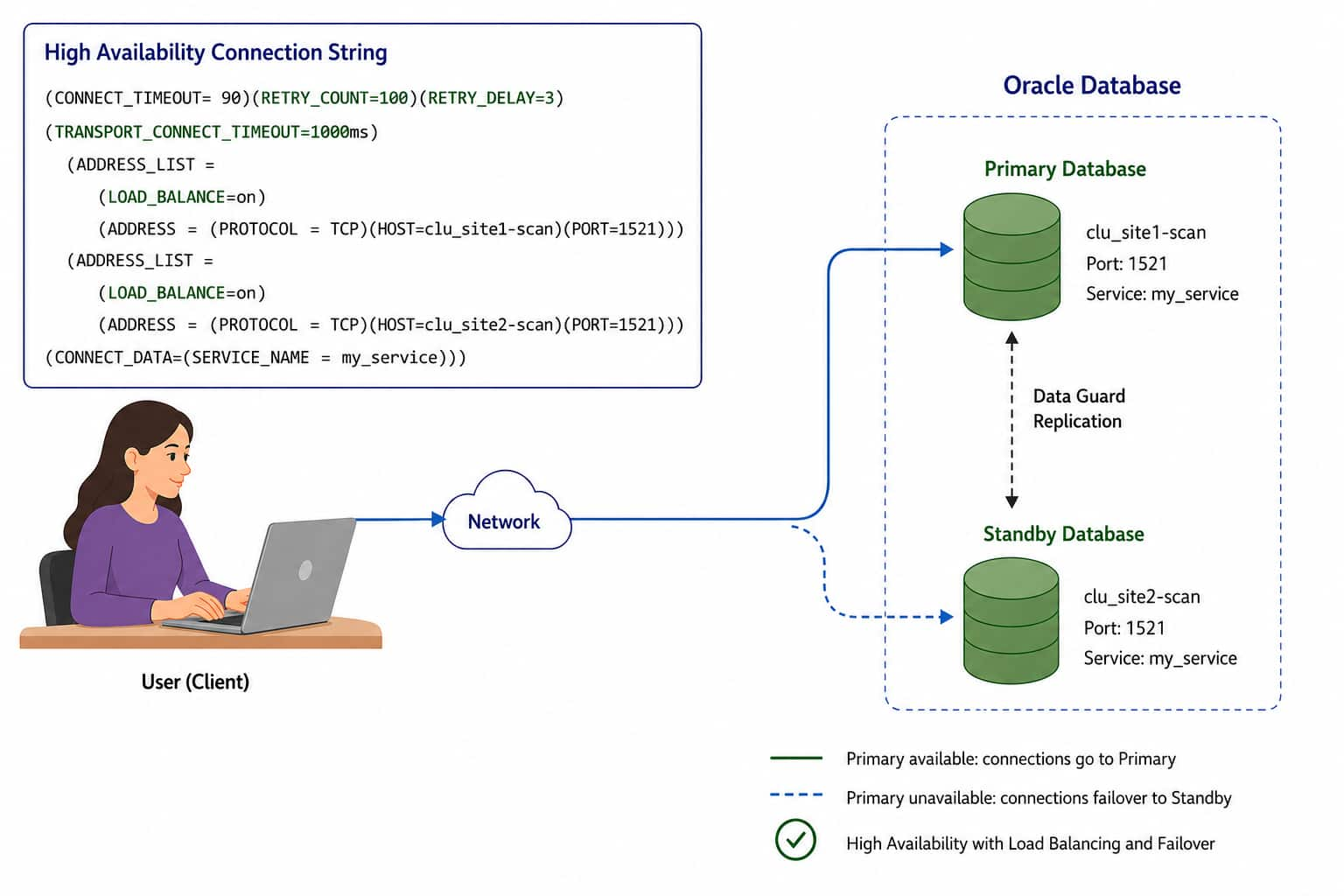
High Availability Connections Explained
Sebastian Solbach
16 minute read
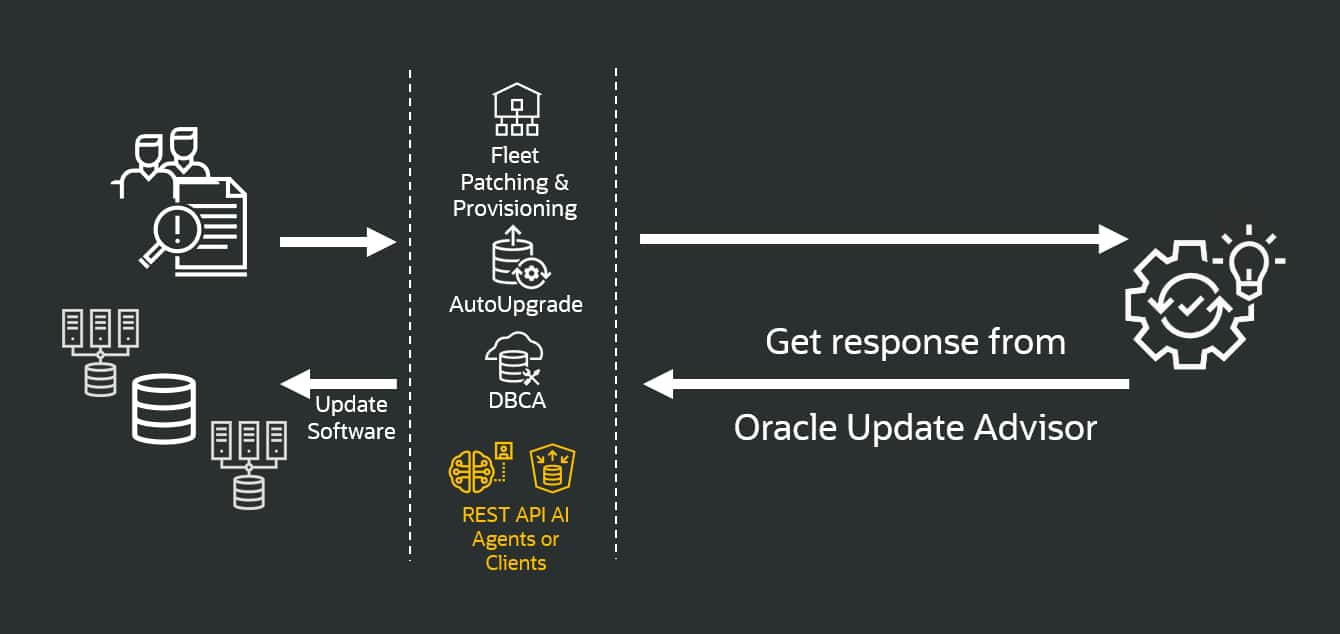
Accept the AI Challenge: Build Your Own Oracle Update Advisor Client ...
Glen Hawkins
3 minute read
Online Tablespace Encryption in Oracle Data Guard 26ai
Ludovico Caldara
3 minute read
Beyond Routine Updates: How ZDLRA Monthly Release Updates(RUs) ...
Gagan Singh
2 minute read
Rebuild After a Cyber Event with Recovery Service and a Cloud Clean ...
Kelly Smith
4 minute read
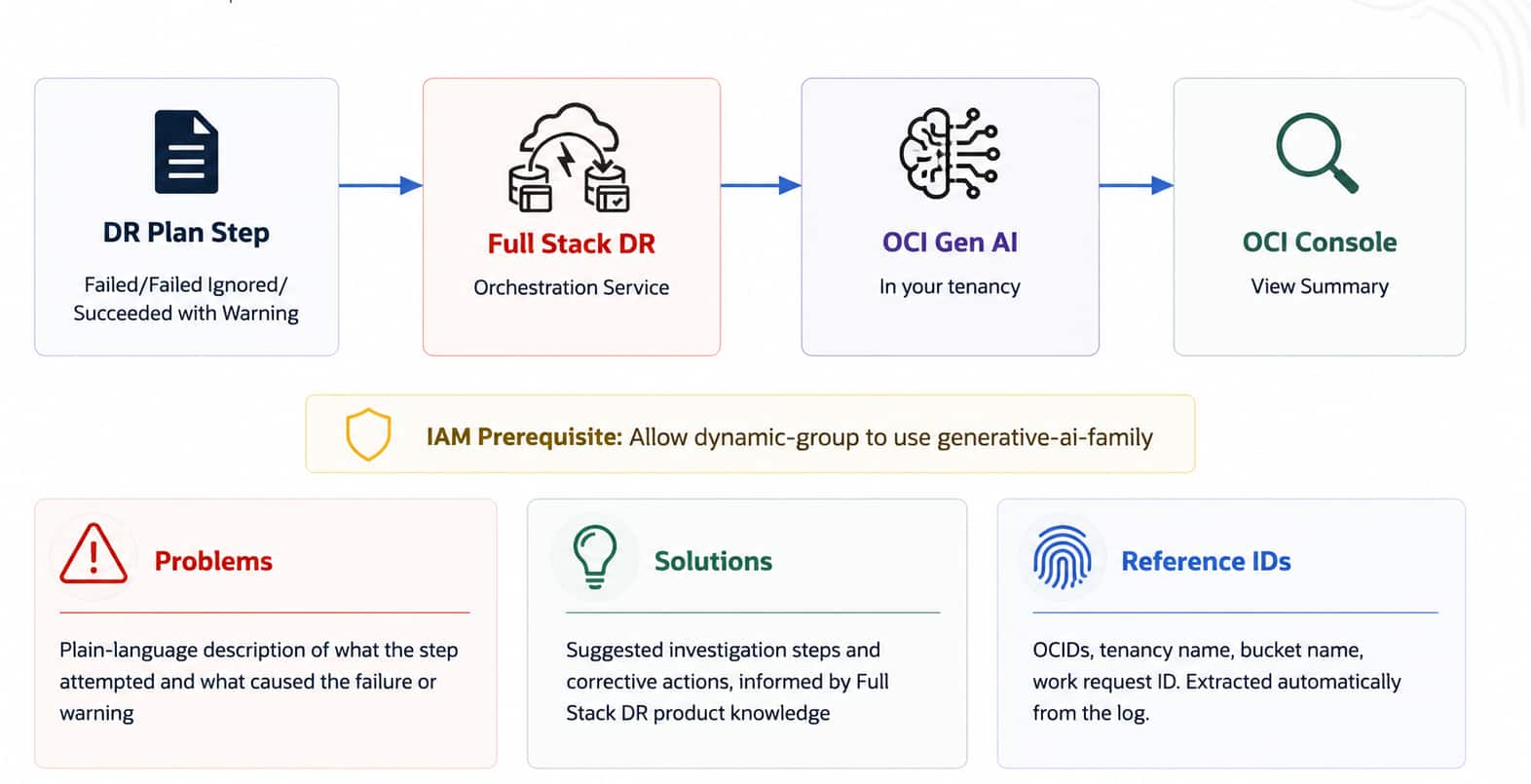
Faster Disaster Recovery Troubleshooting: Generative AI Log ...
Suraj Ramesh
5 minute read
From Compromised to Clean: A Database-Optimized Cyber Vault & ...
Tim Chien
5 minute read
Announcing the OCI Recovery MCP Server: Bringing AI-Driven Resilience ...
Allen Best
2 minute read
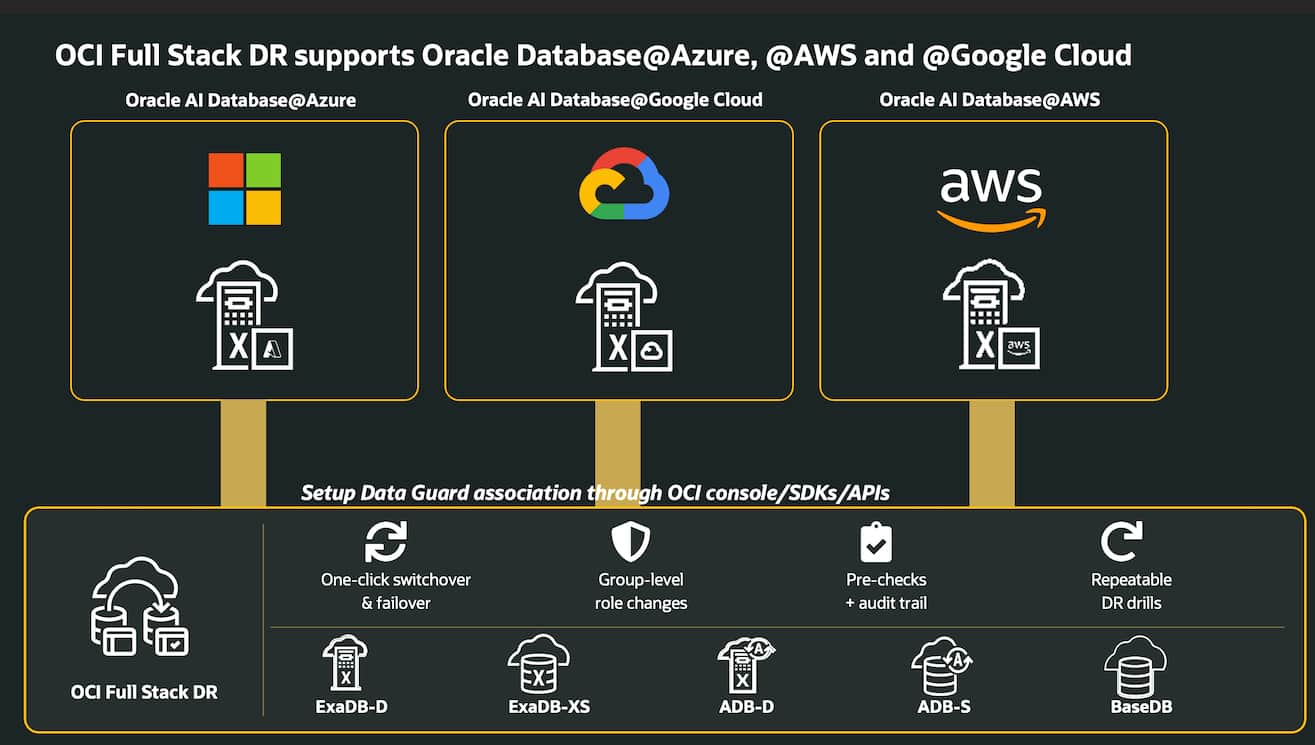
OCI Full Stack DR Supports Oracle AI Database@Azure, @AWS, and ...
Suraj Ramesh
5 minute read
Modernizing Oracle Database Patching for Continuous Security and High ...
Anil Nair
3 minute read
View more
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers