In a previous post, Application and AI Scalability with Oracle Active Data Guard, we explained the offloading capabilities offered by Oracle Active Data Guard.
Offloading AI inference into Oracle Active Data Guard can provide a safer and more cost-effective alternative for enterprise applications. In this post, we will explore possible use cases and provide real code you can try. To make it more engaging, we will use multi-modal models that combine images and text embeddings.
Why run AI inference in the Database?
Running AI inference inside your Oracle AI Database, rather than calling third-party APIs or public endpoints, can enhance privacy and efficiency while reducing complexity and, in many cases, costs.
💰 Lower Costs: External APIs and GPU cloud services can become very expensive as data volumes increase. GPU supply can be problematic, and underutilized GPUs are cost-ineffective. In-database inference uses hardware you already own, leveraging optimized ONNX models that run inside the Database engine.
👮 Stronger Security and Governance: Data never leaves your database. You eliminate network hops and massive data transfers, including local ones, and reduce the risk of potential data potential leaks.
🏄♂️ Operational Simplicity: No external network calls, no API keys to manage, and no ETL overhead. Your AI pipeline runs close to your data, typically embedded directly into SQL queries, benefiting from Oracle’s advanced security and audit capabilities.
Balancing cost and performance
Yes, GPUs are faster for massive models, but they are costly, require specialized management, and may be unnecessary in some cases. Many popular ONNX models run efficiently on CPUs.
Scale AI inference and offload to Active Data Guard
AI inference is CPU-intensive and requires proper capacity management. When CPUs become overloaded, Oracle Real Application Clusters (RAC) can scale to an impressive amount of CPUs. You can always run cluster services dedicated to the AI workload and relocate them to meet CPU requirements.
Scale out with Oracle RAC when:
- you have real-time inference requirements
- you deploy on a scalable infrastructure (e.g. Exadata Database Services, not Base Database Services)
- you have write-intensive data pipelines
- you use special features or PL/SQL packages that are not available on Active Data Guard (e.g. DBMS_SCHEDULER, DBMS_PARALLEL_EXECUTE, etc)
While you can run models on the primary database for real-time transactions, other workloads involving bulk jobs, vector search, or asynchronous inference work best on Active Data Guard standby databases. Having the choice of using the standby database for AI inference let you to strike the right balance for your needs.
Offload to Active Data Guard when:
- you already have an offload strategy for read-only workloads
- your standby databases are not utilized or are under-utilized
- your RAC infrastructure can’t scale (ODA, BaseDB) or you cant step up because of costs/approvals (e.g. 1/2 rack to full rack)
- your primary is performance-sensitive and you don’t want any impact
When offloading to the standby database, the AI workload doesn’t compete with the primary workload’s resources:
🚀 Production stays fast and safe
📊 AI models still run close to the data
🔄 Standby resources are fully utilized
Practical walkthrough: Find images with semantic search using Active Data Guard
Let’s explore how AI workloads can be offloaded to the standby with a practical example: finding the most similar pictures to a search phrase.
This example assumes that you have an Oracle AI Database in an Active Data Guard configuration, with a pluggable database and role-based services properly configured.
Step 1: Create the application user (ADGVEC)
-- run this script as a DBA on the primary PDB
create user adgvec identified by &adgvecpass;
create role vec_role not identified;
-- most developer require these grants:
grant db_developer_role to vec_role;
-- usage of ONNX models:
grant create mining model to vec_role;
-- optional: grants for Application Continuity:
grant keep date time to vec_role;
grant keep sysguid to vec_role;
grant vec_role to adgvec;
alter user adgvec quota unlimited on users;Step 2: Create the schema for pictures and vectors
-- run this script as the user (ADGVEC) on the primary PDB
-- contains the images
create table if not exists pictures (
id number primary key,
img_size number,
img blob
);
-- contains vector embeddings (1:1 relation with pictures)
create table if not exists picture_embeddings (
id number,
embedding vector,
constraint picture_embeddings_pk primary key ( id ),
constraint picture_embeddings_fk foreign key ( id ) references pictures ( id )
);Step 3: Prepare and load your ONNX models
Export and load the pre-configured Clip model using OML4Py:
from dotenv import load_dotenv
from oml.utils import ONNXPipeline
import oml
db_user = os.getenv('DB_USER')
db_password = os.getenv('DB_PASSWORD')
db_dsn = os.getenv('DB_DSN') # Use the DSN of the primary PDB
pipeline = ONNXPipeline("openai/clip-vit-large-patch14")
oml.connect(db_user, db_password, dsn=db_dsn)
pipeline.export2db("clip")The full examples and documentation are available here: https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/onnx-pipeline-models-multi-modal-embedding.html
This yields two ONNX models available to the user:
select model_name, mining_function, algorithm, model_size from user_mining_models;MODEL_NAME MINING_FUNCTION ALGORITHM MODEL_SIZE
---------- --------------- --------- ----------
CLIPIMG EMBEDDING ONNX 306374876
CLIPTXT EMBEDDING ONNX 125759349Step 4: Load images into the pictures table
Use the Primary PDB DSN:
'''
This python script inserts all the images as blobs into the pictures table using the oracledb driver.
'''
import os
import oracledb
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Database connection parameters and image directory
db_user = os.getenv('DB_USER')
db_password = os.getenv('DB_PASSWORD')
db_dsn = os.getenv('DB_DSN')
image_directory = os.getenv('IMAGE_DIRECTORY')
oracle_home = os.getenv('ORACLE_HOME')
oracledb.init_oracle_client(lib_dir=oracle_home)
# Establish a database connection
with oracledb.connect(user=db_user, password=db_password, dsn=db_dsn) as connection:
with connection.cursor() as cursor:
for filename in os.listdir(image_directory):
if filename.endswith('.jpg'):
image_id = int(os.path.splitext(filename)[0])
image_path = os.path.join(image_directory, filename)
with open(image_path, 'rb') as image_file:
image_data = image_file.read()
image_size = len(image_data)
try:
# Insert the image data into the 'pictures' table
cursor.execute("""
INSERT INTO pictures (id, img_size, img)
VALUES (:id, :img_size, :img)""",
{'id': image_id, 'img_size': image_size, 'img': image_data})
except oracledb.IntegrityError as e:
error_obj, = e.args
if error_obj.code == 1: # ORA-00001: unique constraint violated
print(f"Skipping image {filename}: ID {image_id} already exists.")
else:
raise
print(image_id)
# Commit the transaction
connection.commit()In a production environment, you would have the documents loaded into the database as part of your business processes.
Step 5: Create the process_embedding procedure
Create the procedure definition on the primary PDB:
/*
This script creates a procedure that process the embeddings of the images in the pictures table and insert them via DML redirection.
*/
CREATE OR REPLACE PROCEDURE process_embeddings (
p_batch_size IN PLS_INTEGER,
p_iterations IN PLS_INTEGER
) AS
TYPE t_embedding IS RECORD (
id pictures.id%TYPE,
embed_vector picture_embeddings.embedding%TYPE
);
TYPE t_embedding_table IS TABLE OF t_embedding;
v_embeddings t_embedding_table;
v_batch_count PLS_INTEGER := 0;
v_total_processed PLS_INTEGER := 0;
v_continue BOOLEAN := TRUE;
CURSOR c_embeddings IS
SELECT c.id,
vector_embedding(clipimg USING img AS data) AS embed_vector
FROM pictures c
LEFT OUTER JOIN picture_embeddings v ON c.id = v.id
WHERE v.id IS NULL AND c.img IS NOT NULL and c.id IS NOT NULL;
BEGIN
OPEN c_embeddings;
EXECUTE IMMEDIATE 'ALTER SESSION ENABLE ADG_REDIRECT_DML';
LOOP
FETCH c_embeddings BULK COLLECT INTO v_embeddings LIMIT p_batch_size;
EXIT WHEN v_embeddings.COUNT = 0;
FOR i IN v_embeddings.FIRST .. v_embeddings.LAST LOOP
DBMS_OUTPUT.PUT_LINE('Processing ID: ' || v_embeddings(i).id);
INSERT INTO picture_embeddings (id, embedding)
VALUES (v_embeddings(i).id, v_embeddings(i).embed_vector);
END LOOP;
COMMIT;
v_total_processed := v_total_processed + v_embeddings.COUNT;
v_batch_count := v_batch_count + 1;
IF p_iterations > 0 AND v_batch_count >= p_iterations THEN
v_continue := FALSE;
END IF;
EXIT WHEN NOT v_continue;
END LOOP;
CLOSE c_embeddings;
END process_embeddings;
/Note that the procedure enables Data Manipulation Language (DML) redirection using “ALTER SESSION ENABLE ADG_REDIRECT_DML”. Once the session uses DML redirection, all the SELECT statements, including the one generating embeddings with VECTOR_EMBEDDING(), still run on the standby database, while all the DML statements (INSERT in this case) run on the primary database.
Step 6: Execute the procedure on Active Data Guard
Run this from the Active Data Guard standby:
EXECUTE process_embeddings(p_batch_size => 10, p_iterations => 100);This offloads the CPU-intensive embedding generation to the standby, preserving primary resources for mission-critical, transactional workload.
Embedding generation can scale linearly with the number of standby databases.
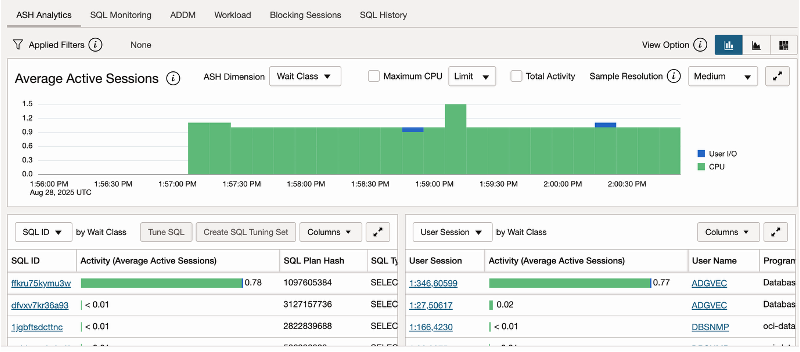
The following two images show the primary and standby databases load during a single-thread batch.
Primary workload:
Standby workload:
Step 7: Perform semantic search on Active Data Guard
Run a semantic search on the standby database to find images that match a text description:
SELECT c.id, c.img,
VECTOR_DISTANCE(
v.embedding,
VECTOR_EMBEDDING(cliptxt USING 'a blue bird' AS data),
COSINE
) AS distance
FROM pictures c
JOIN picture_embeddings v ON c.id = v.id
ORDER BY distance
FETCH FIRST 10 ROWS ONLY;VECTOR_EMBEDDING(cliptxt USING 'a blue bird' AS data)encodes the search query into the same space as the image embeddings.VECTOR_DISTANCEfinds images with the closest semantic match.
AI Vector Search runs securely inside the standby database. No external APIs. No privacy risk.
An application backend would use similar queries to retrieve the pictures from the standby database, without using any external endpoint or any language other than SQL. Easy, no?
An application frontend would use the backend API to search and display the pictures:
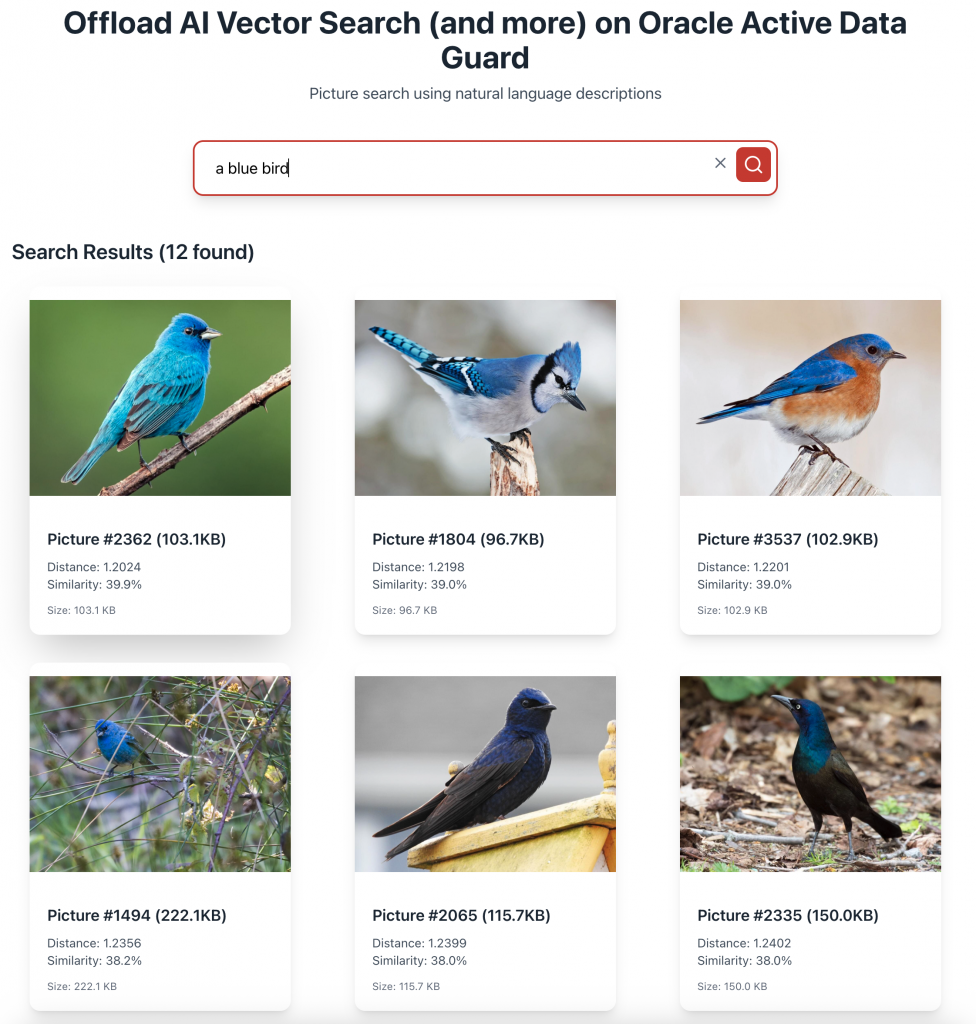
Ready to Build?
You’ve seen how Oracle AI Database, ONNX Runtime, and Active Data Guard create a powerful environment for in-database, multi-modal AI. Benefits include
- Inline inference without external hops
- Full resource utilization and no impact on the primary database
- Simplified architecture with inherent cost-saving opportunities
- Enhanced security and governance
Explore the full example code and a React application in the adg-vector GitHub repository.
