Accessibility Policy
Skip to content
Oracle
TimesTen In-Memory Database
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
General
HowTo
Introduction
Performance
Recent
Blogs Home
RSS
TimesTen In-Memory Database
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
TimesTen In-Memory Database 26.1 Now Available
Jenny Bloom
2 minute read
GA Announcement: Oracle TimesTen In-Memory System of Record for OKE ...
Jenny Bloom
1 minute read
Optimizing TimesTen Synchronous Replication on Oracle Database ...
Doug Hood
7 minute read
Work with JSON Natively in Oracle TimesTen: New Samples Across ...
Carlos Blanco
2 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to Oracle Connect email updates
General
See all
Work with JSON Natively in Oracle TimesTen: New Samples Across ...
Carlos Blanco
2 minute read
TimesTen In-Memory Database 26.1 Now Available
Jenny Bloom
2 minute read
TimesTen 22.1.1.37.0 Now Available on macOS (ARM 64)
Jenny Bloom
2 minute read
TimesTen 22.1.1.36.0 Release Highlights
Jenny Bloom
2 minute read
Lifetime Support Policy for TimesTen 22.1.1 release has been extended
Jenny Bloom
1 minute read
TimesTen dialect is available via Hibernate-community-dialect
Jenny Bloom
2 minute read
Using TimesTen on Oracle Database Appliance (ODA)
Jenny Bloom
2 minute read
GA Announcement: Oracle TimesTen In-Memory System of Record for OKE ...
Jenny Bloom
1 minute read
HowTo
See all
Work with JSON Natively in Oracle TimesTen: New Samples Across ...
Carlos Blanco
2 minute read
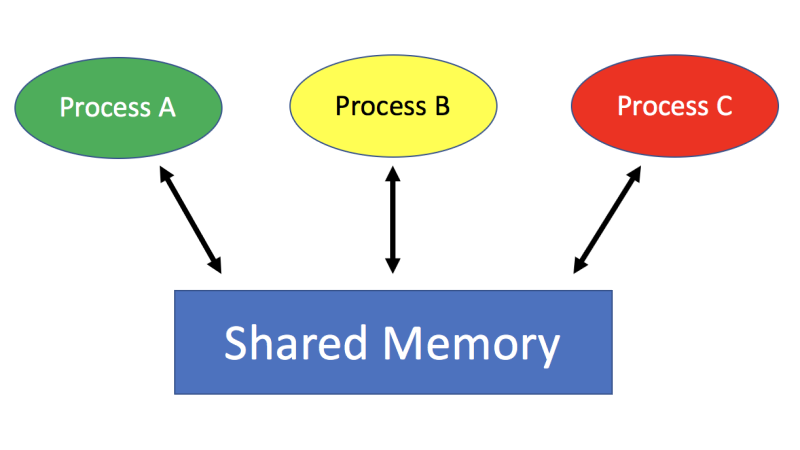
How to configure Shared Memory for TimesTen 18.1
Doug Hood
4 minute read
How to Install Oracle TimesTen 18.1 Classic
Doug Hood
1 minute read
How to Create a TimesTen 18.1 Classic Instance
Doug Hood
4 minute read
TimesTen Memory Management
Doug Hood
10 minute read
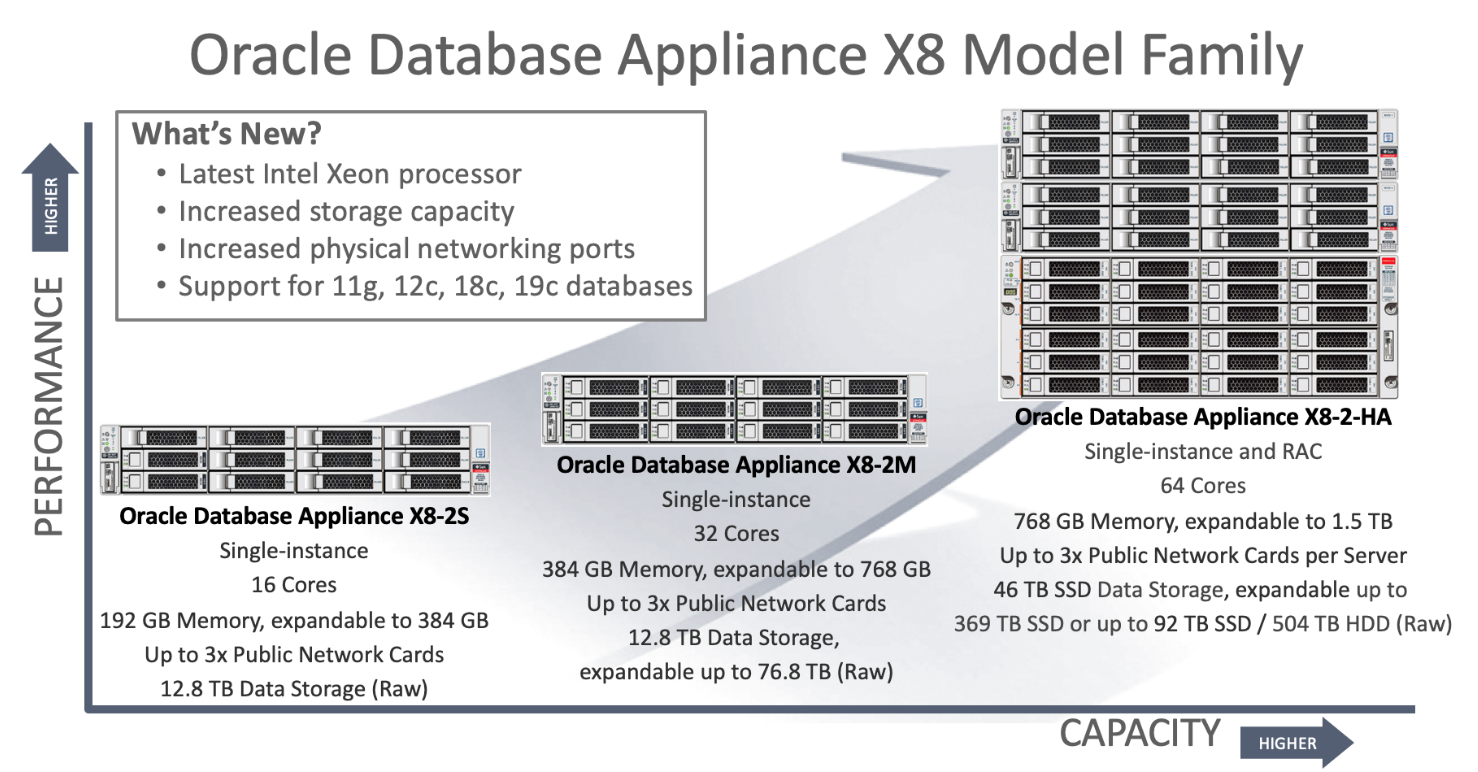
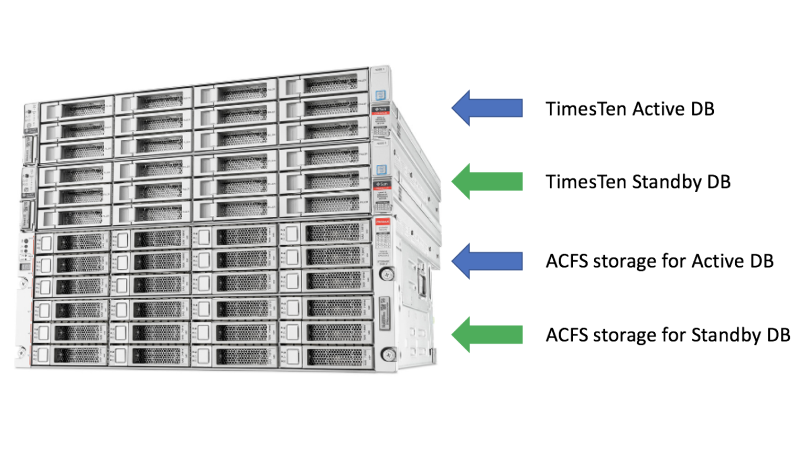
Installing Oracle TimesTen on an Oracle Database Appliance
Doug Hood
5 minute read
Creating an Oracle TimesTen Database on Oracle Database Appliance
Doug Hood
5 minute read
Configuring Oracle Database Appliance X8-2-HA for TimesTen ...
Doug Hood
14 minute read
Introduction
See all
TimesTen In-Memory Database 26.1 Now Available
Jenny Bloom
2 minute read
TimesTen 22.1.1.37.0 Now Available on macOS (ARM 64)
Jenny Bloom
2 minute read
Best practices for Pro*C Indicator Variables and PLSQL Procedures
Doug Hood
4 minute read
Oracle Database Appliance for TimesTen
Doug Hood
7 minute read
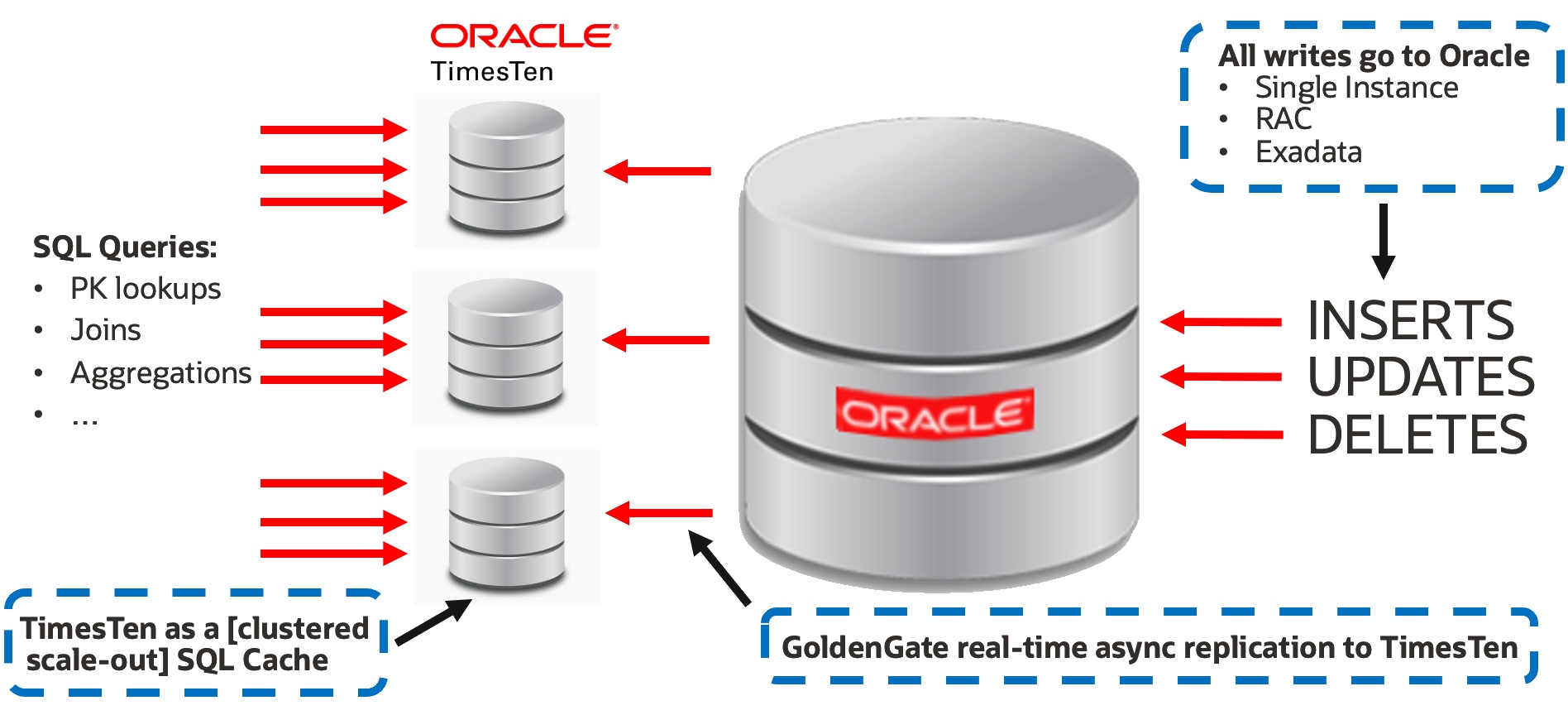
When to Use Oracle GoldenGate with Oracle TimesTen
Chris Jenkins
3 minute read
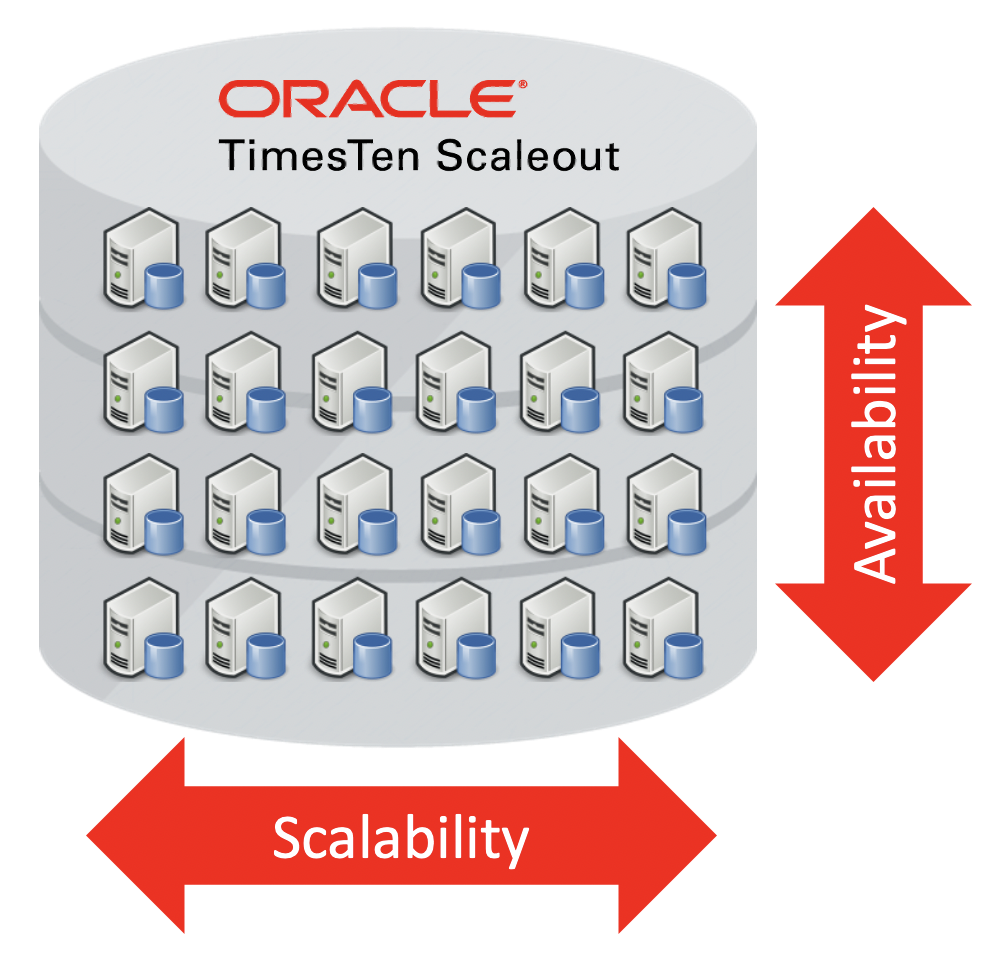
Scalability and Availability for TimesTen Scaleout 22.1
Doug Hood
6 minute read
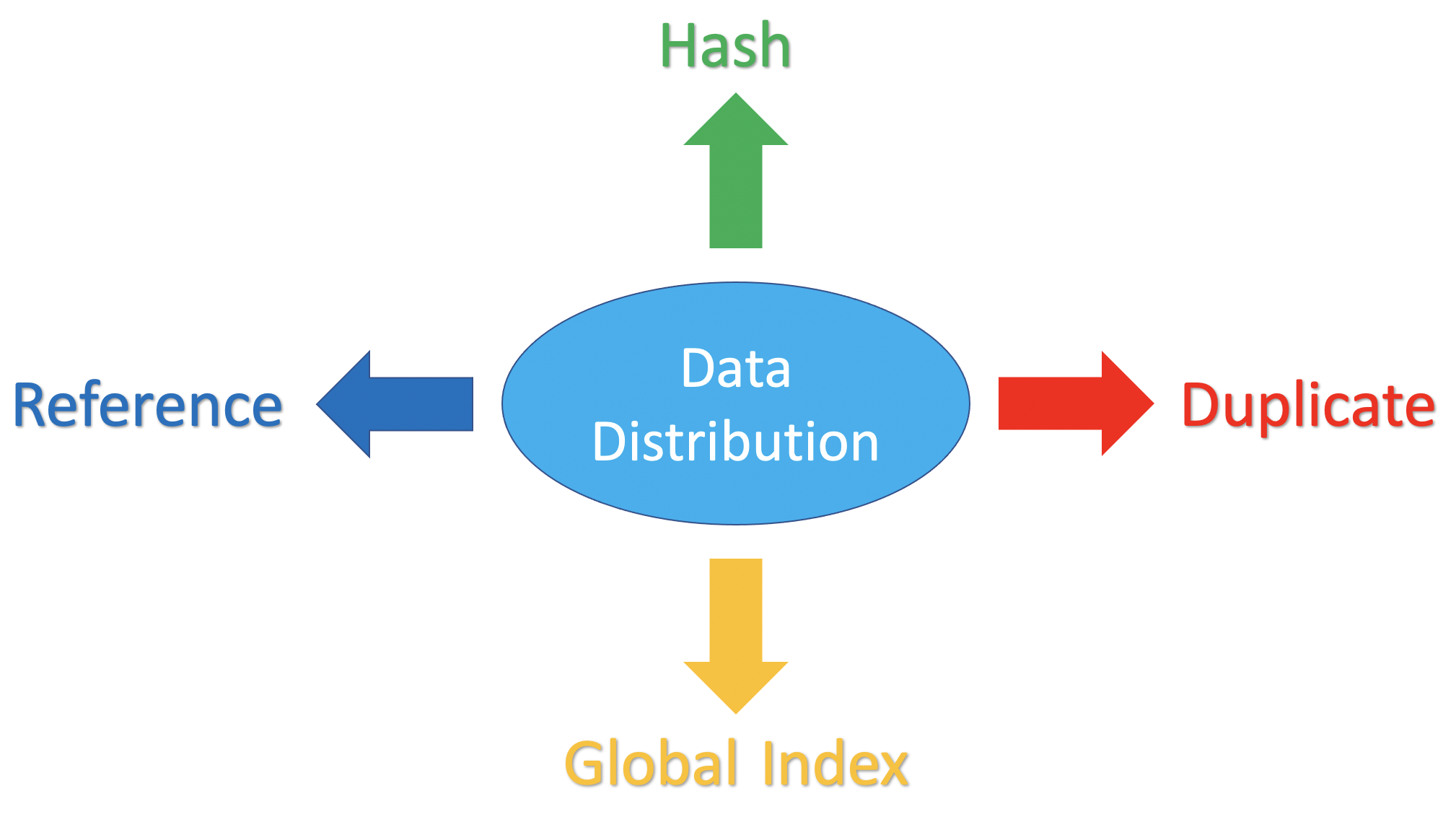
Data Distribution in TimesTen Scaleout 22.1
Doug Hood
10 minute read
Why the Database Character Set Matters
Doug Hood
11 minute read
Performance
See all
Optimizing TimesTen Synchronous Replication on Oracle Database ...
Doug Hood
7 minute read
Dell Intel Optane PMem Oracle RAC and TimesTen Benchmark
Doug Hood
1 minute read
Is Kubernetes slowing down my database?
Doug Hood
10 minute read
When to Use Oracle GoldenGate with Oracle TimesTen
Chris Jenkins
3 minute read
Scalability and Availability for TimesTen Scaleout 22.1
Doug Hood
6 minute read
Indexing TimesTen Scaleout 22.1
Doug Hood
10 minute read
How fast is TimesTen XE
Doug Hood
8 minute read
Oracle TimesTen XE
Doug Hood
7 minute read
Recent
See all
TimesTen In-Memory Database 26.1 Now Available
Jenny Bloom
2 minute read
TimesTen 22.1.1.37.0 Now Available on macOS (ARM 64)
Jenny Bloom
2 minute read
TimesTen 22.1.1.36.0 Release Highlights
Jenny Bloom
2 minute read
Lifetime Support Policy for TimesTen 22.1.1 release has been extended
Jenny Bloom
1 minute read
TimesTen dialect is available via Hibernate-community-dialect
Jenny Bloom
2 minute read
Using TimesTen on Oracle Database Appliance (ODA)
Jenny Bloom
2 minute read
GA Announcement: Oracle TimesTen In-Memory System of Record for OKE ...
Jenny Bloom
1 minute read
Scalability and Availability for TimesTen Scaleout 22.1
Doug Hood
6 minute read
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers