Many apps show user streaks – how many consecutive days they logged in, their winning streaks or they completed a task. On SQuizL we display your longest and current series of successful guesses.
The question is: how do you find these sequences using SQL?
To celebrate #JoelKallmanDay let’s find out!
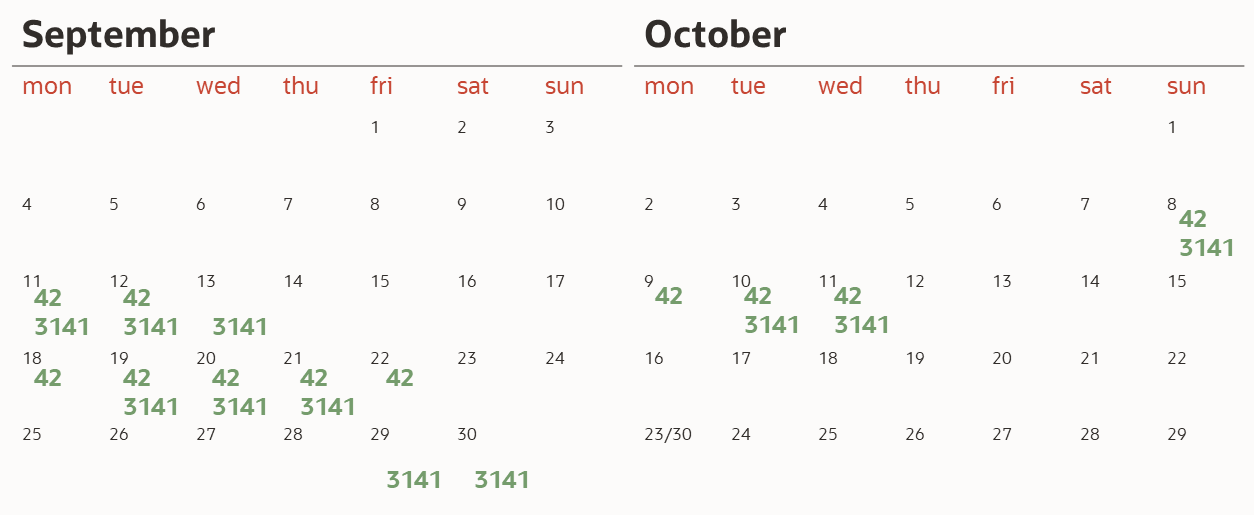
For example, say users 42 and 3141 both have four separate answer chains:
- The longest for user 42 started on 18th Sept and ran for five days. Their current sequence (ending 11th Oct) is four days long
- User 3141’s longest streak is three days. This has happened twice, starting on the 11th and 19th Sept. Their current chain is two days
To find these groups you need to:
- Group together rows on consecutive days
- Count the rows in each group
- Return the group with the most rows and the most recent group
This is a job that SQL pattern matching is perfect for.
You can use this statement to find the streaks for each user:
This works by:
- Splitting up rows into separate groups for each user (
partition by user_id) - Sorting the rows for each user by the answer date (
order by answer_date) - The
patternfinds any row (init) followed by zero or moreconsecutiverows. - The definition of
consecutiveis rows where theanswer_datefor the current row equals theanswer_datefor the previous row plus one (day). - The
measuresclause defines the output columns. These are the number of rows in each group (count(*) streak) and it’s start date (min ( answer_date ) grp_start)
Note this assumes a maximum of one answer per day. If you can have multiple events per day, de-duplicate these in a subquery first.
Find the longest and current consecutive series
At this point you have a row per streak per user. Grouping by user and returning the max ( streak ) gives the length of the longest sequence.
It’s less obvious how to find when this chain started and the current streak’s length. The first and last functions – perhaps better known as the keep clause – are ideal here.
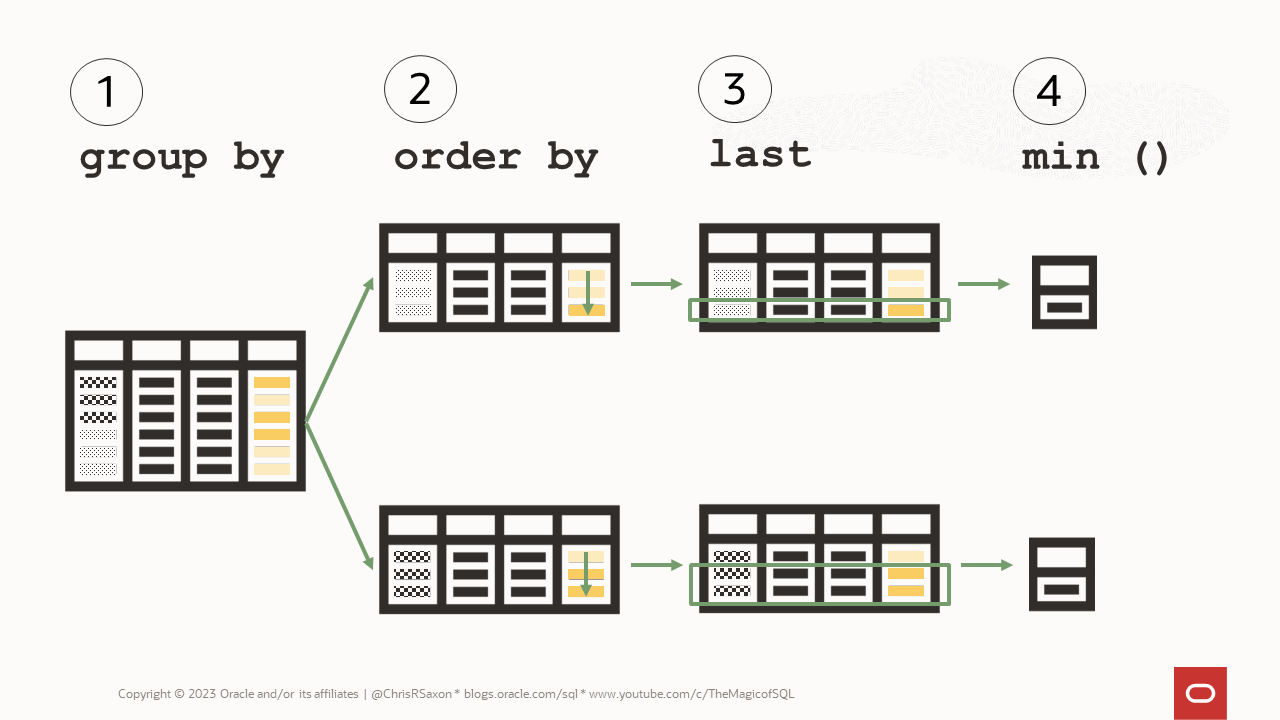
This is an extension to aggregate functions which looks like:
<aggregate function> keep ( dense_rank [ first | last ] order by <expr> )
These:
- Sort the data in each group (
order by <expr>) - Gets the rows with the initial (
first) or final (last) values in the ordered group - Returns the aggregate value for these rows
So to find the longest chain you can:
- Sort by streak (ascending)
- Get the rows with the last value for this
- Return the first (
min) or last (max)answer_datefor these rows
The choice of min or max matters when there’s a tie for the first or last value. Remember user 3141 has two separate three-day streaks. Using min returns the start date of the oldest, max the start date of the newest.
To find the start of the oldest, longest streak use:
min ( grp_start ) keep ( dense_rank last order by streak )
You can use a similar approach to find the length of the current series. These are the rows with the most recent grp_start. Instead of getting the last of an ascending order, let’s get the first of a descending sequence:
- Sort by
grp_startdescending - Get the rows with the
firstvalue for this - Return the
max ( streak )
Giving:
max ( streak ) keep ( dense_rank first order by grp_start desc )
Conceptually taking the last rows of an ascending sort or the first values of a descending order are the same. If the sort columns include null, check whether you want these at the top or bottom of the data set. You can control this with the nulls first|last clause if necessary.
Plug these into the pattern matching query above to give this final statement:
And viola: you have the start and length of the longest consecutive sequence, along with the days in the most recent streak!
For more details on using SQL pattern matching, here’s my slides on using this to find patterns in your data:
You can run the queries to find streaks in Live SQL or build the tables with this script:
Want to test your SQL syntax knowledge? Take SQuizL, a daily free guess the SQL statement quiz.
UPDATED 11 Apr 2025 Changed Live SQL link to new version of this platform
