Accessibility Policy
Skip to content
Oracle
All Things SQL
Search
Exit Search Field
Clear Search Field
Menu
RELATED CONTENT
The Magic of SQL
Simply Smarter SQL
Ask TOM
Oracle Dev Gym
Blogs Home
RSS
All Things SQL
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
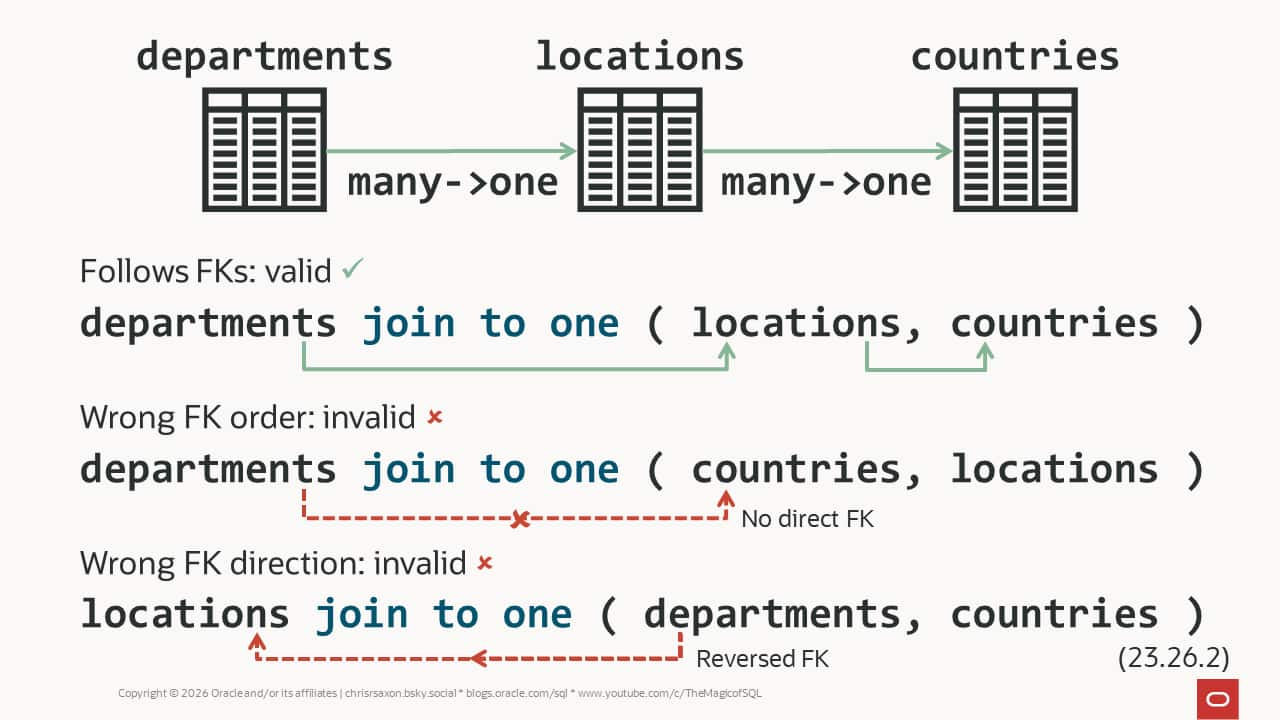
Guarantee at least one in one-to-many relationships in Oracle AI ...
Chris Saxon
7 minute read
Free developer resources to help you get started with Oracle AI ...
Chris Saxon
3 minute read
How to stop updates from hanging forever with [no]wait in Oracle AI ...
Chris Saxon
3 minute read
Avoid join duplicates with modern join syntax in Oracle AI Database
Chris Saxon
6 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to receive the latest blog updates
Recent Posts
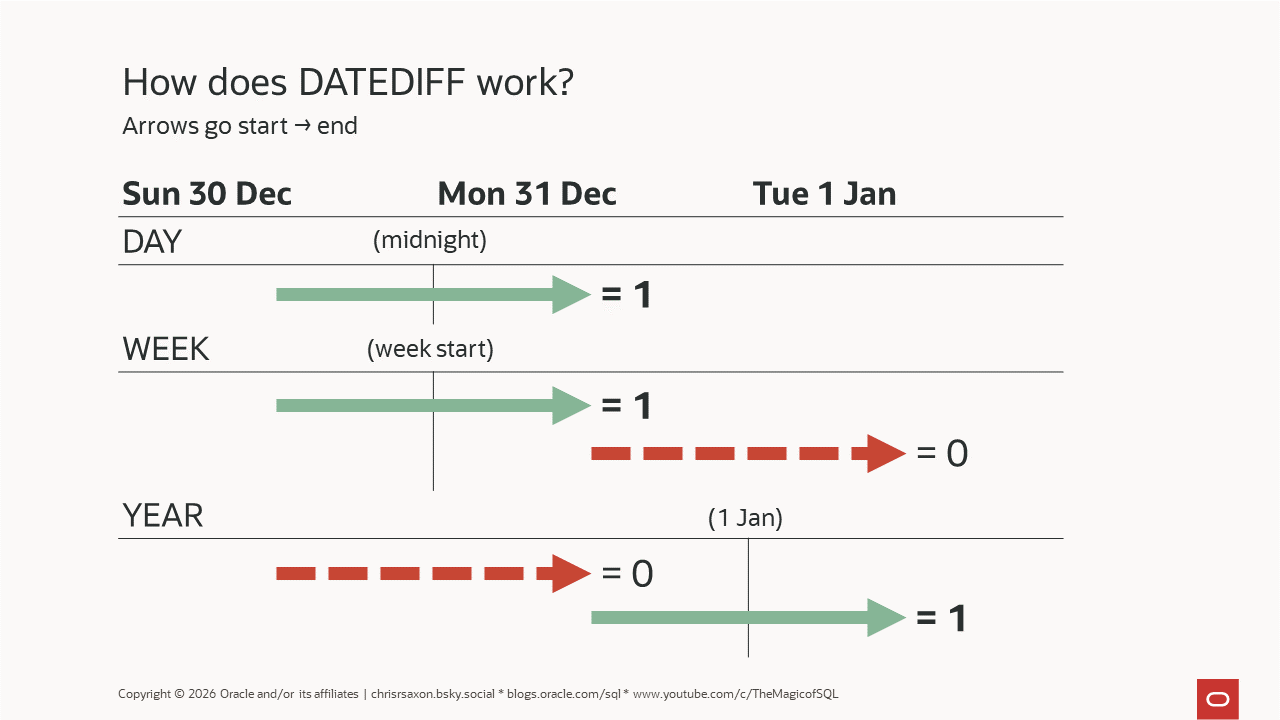
How to find datetime boundaries crossed with DATEDIFF in Oracle AI ...
Chris Saxon
4 minute read
How to get the Nth row with Oracle SQL
Chris Saxon
5 minute read
Assertions bounty winners
Chris Saxon
2 minute read
Conditional filters for count, sum, and other aggregates in Oracle AI ...
Chris Saxon
2 minute read
Assertions use case bounty for Oracle ACEs
Chris Saxon
1 minute read
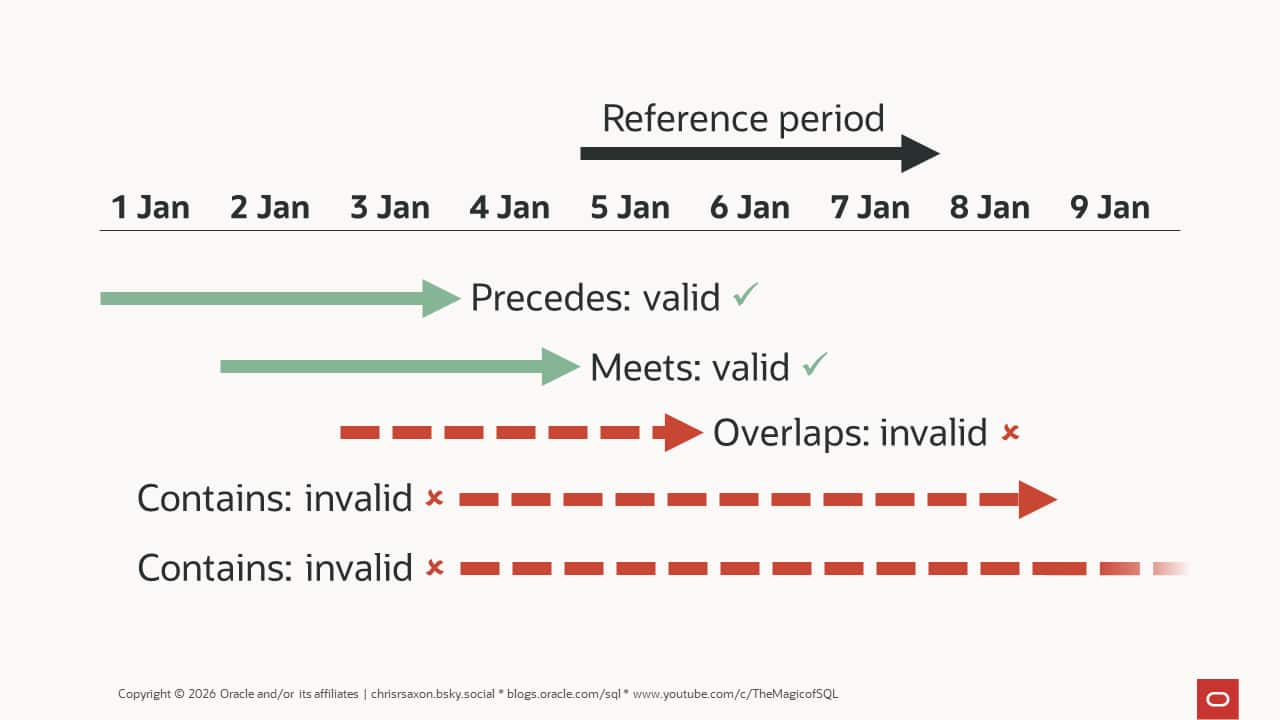
How to stop overlapping date ranges in Oracle AI Database
Chris Saxon
3 minute read
Announcing the winners of the 2025 Oracle Dev Gym Championships
Chris Saxon
2 minute read
How to define cross-table constraints with assertions in Oracle AI ...
Chris Saxon
4 minute read
Announcing the 2025 Oracle Dev Gym Championships
Chris Saxon
2 minute read
How to convert object comments to schema annotations
Chris Saxon
2 minute read
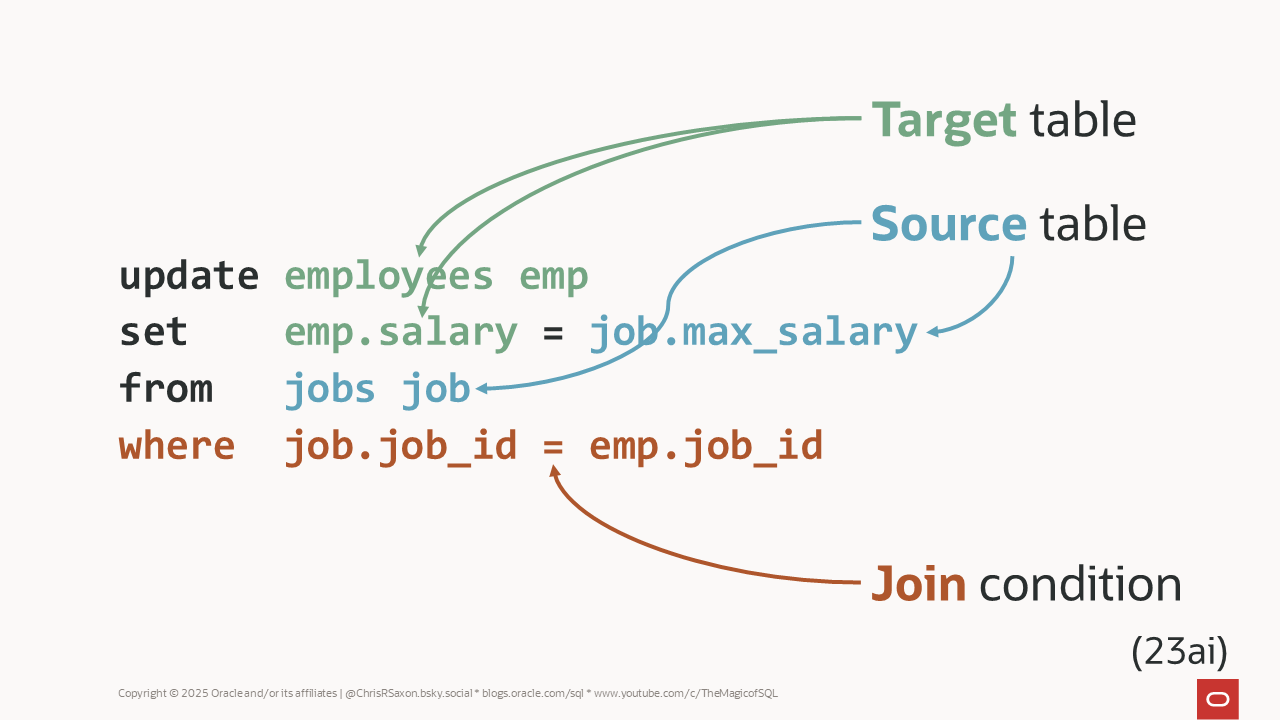
How to update columns in one table with data from another using ...
Chris Saxon
9 minute read
Faster PL/SQL in SQL with the Automatic SQL Transpiler
Chris Saxon
7 minute read
View more
Receive the latest blog updates
Subscribe to receive the latest blog updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers


![How to stop updates from hanging forever with [no]wait in Oracle AI Database](https://blogs.oracle.com/sql/wp-content/uploads/sites/69/2026/05/DML-nowait-clause.png)