皆さんこんにちは、今年も残すところあと1ヶ月となり、年々1年が短く感じます。今年のやり残しがないようにしたいですね。
今回は、第48回の分析ファンクション(ウィンドウ関数)の続きとして、まだ説明していないパラレル実行について、Oracle Database 12c(Oracle12c)の拡張も含めて説明しようと思います。後半に、その他のOracle12cで拡張されたパラレル実行関係の機能についても説明していますので、参考にしてください。
1. 分析ファンクションのパラレル実行
分析ファンクションは、第47回で説明したように、自己結合の代わりに使用できる便利な機能ですが、大量データではパラレル実行を効果的に行う必要があるので、パラレル実行の動作方法や注意点をOracle12cも含めて説明します。
分析ファンクションは、行グループ(PARTITION BY句)ごとに処理を行う必要があるので、パラレル実行のときにはPARTITION BY句の値で、以下の左側のようにWINDOW SORTに対してHASH分散を行います。また、複数の分析ファンクションを指定してもPRTITION BY句が同じであれば、以下の右側のように1度だけのデータ再分散で行うことができます。このときWINDOW SORTは、分析ファンクションの数と同じになりますが、ORDER BY句の列が同じかORDER BY句がないときにはこれも一つになります。そのため、パラレル実行のときには、一つのSQLに異なるPARTITION BY句を指定しない方が効果的と言えます。
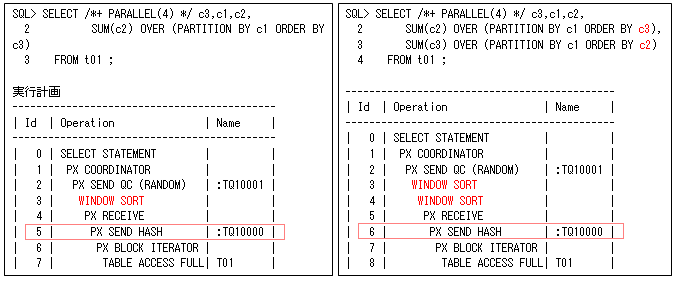
このように、PARTITION BY句をベースにパラレル実行を行うので、PARTITION BY句の一意な値の数が少ないときや偏っているときは効果的にパラレル実行を行うことができません。例えば、この値がパラレル度より少ないと、その一意な値の数のPQプロセス(パラレル・スレーブ・プロセス)だけにデータ再分散することになり、すべてのPQプロセスを使用することができません(HASH分散は、第39回で説明したように、同じ値を分割することができないからです)。これを改善するために、Oracle12cから以下のような拡張がされています。
- Extended Destribution Key(拡張分散キー)
- Window Pushdown(2ステージでの実行)
それでは、それぞれについて説明していきます。
(1)Extended Destribution Key(拡張分散キー)
PARTITION BY句の一意な値がパラレル度より少ないときなどは、データ分散する数を増やすことができるように、ORDER BY句が存在するときには拡張分散キー(ORDER BY句を含めたキー)によってデータ再分散を行います。ただし、ORDER BY(ソート)処理は、HASH分散することができないので、このときは以下のようにRANGE分散になります(第9回で説明したように、RANGE分散はデータによっては偏りやすいところはありますが、同一データのHASH分散よりは効果的という訳です)。
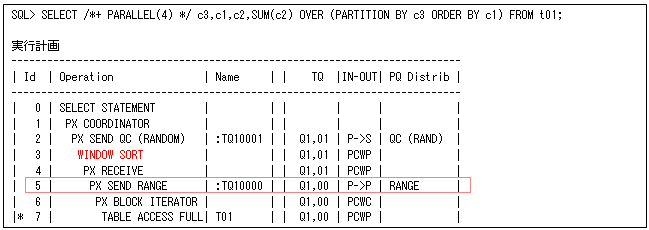
これはPARTITION BY句の値で判断されますが、オプティマイザ統計などによって正しく判断されないために、以下のようにPQ_DISTRIBUTE_WINDOWヒントで強制的に指定できるようになっています。指定方法は、PQ_DISTRIBUTE_WINDOW([<問合せブロック>] N)と行います(Nが1だとこれまでのようにHASH、2または3だとRANGEになります。問合せブロックについては、第55回を参照してください)。
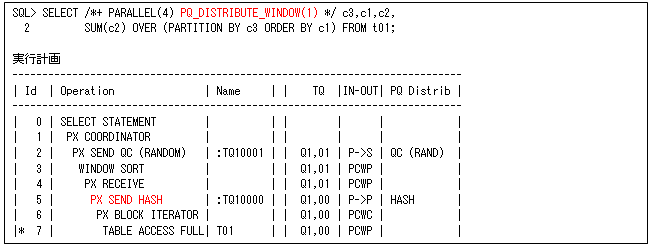
拡張分散キーのときは、ORDER BY句が使用されているので、分析ファンクションの数だけRANGE分散が行われます。ただし、以下の左側のように二つ目はRANGE分散にならない場合があるので注意してください。このときもPQ_DISTRIBUTE_WINDOWヒントを使用すると、二つ目もRANGE分散にすることができます(以下の右側のように、一つ目の後に分散方法を指定してPQ_DISTRIBUTE_WINDOW(3 3)と行います)。
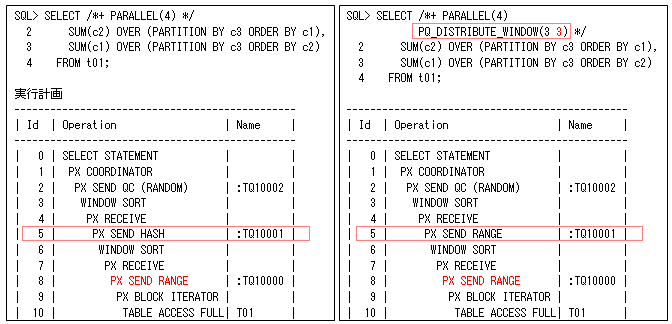
二つ目の分析ファンクションがHASH分散になると(拡張分散キーでないと)、以下のように三つ目以降はデータ再分散されなくなります。これもPQ_DISTRIBUTE_WINDOWヒントで、同じようにRANGE分散にすることができます(PQ_DISTRIBUTE_WINDOW(3 3 3)のように二つ目の後に指定します)。このようなヒントを使用することはないかと思いますが、SQLチューニング時に役に立つときもあるかと思い載せておきました。
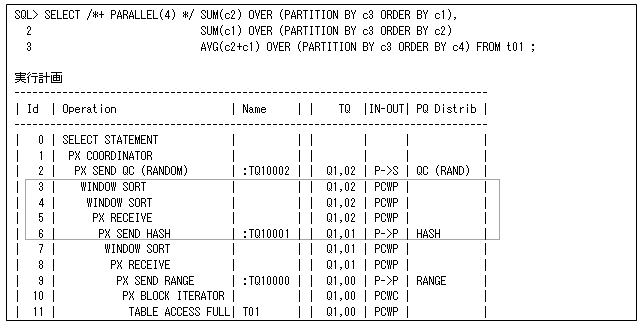
(2)Window Pushdown(2ステージでの実行)
ORDER BY句が指定されていない場合には、拡張分散キーによってデータ分散する数を増やすことができません。そのため、第20回で説明したGroup-by pushdownのように2ステップで処理を行います。ただし、GROUP BY処理などと異なり、分析ファンクションはデータ件数を削減できないので、効果的にデータ分散することがメインになります。つまり、スキャン・プロセスで分析ファンクションの途中結果を作成することで、多くのPQプロセスで処理されるようにします。
最初に、PQプロセスごとにスキャンされたデータに対して分析ファンクションを行います(そのため、以下の実行計画ではPX SEND HASHする前にWINDOW SORTを行っています)。次に、その途中結果をデータ再分散して最終結果を作成するように動作します(WINDOW CONSOLIDATOR BUFFERがその処理になります)。
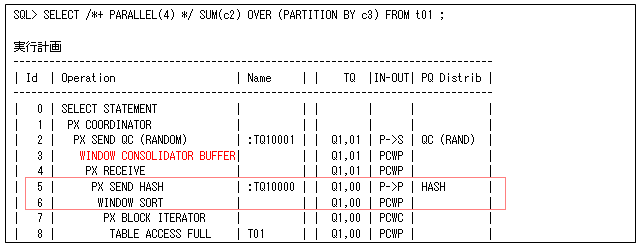
ただし、PARTITION BY句の値で単純にHASH分散すると偏ってしまうので、各プロセスのファンクション途中結果(ORDER BY句がないとPARTITION BY句の値ごとに同じ値になります)の一意な値をBROADCAST分散して、それに対して必要なデータとファンクション途中結果をランダム分散することで最終結果を求めます(2重でデータ分散されるので、そのオーバーヘッドが発生しますが、途中結果の一意な値はそんなに多い数にはならないと言えます)。
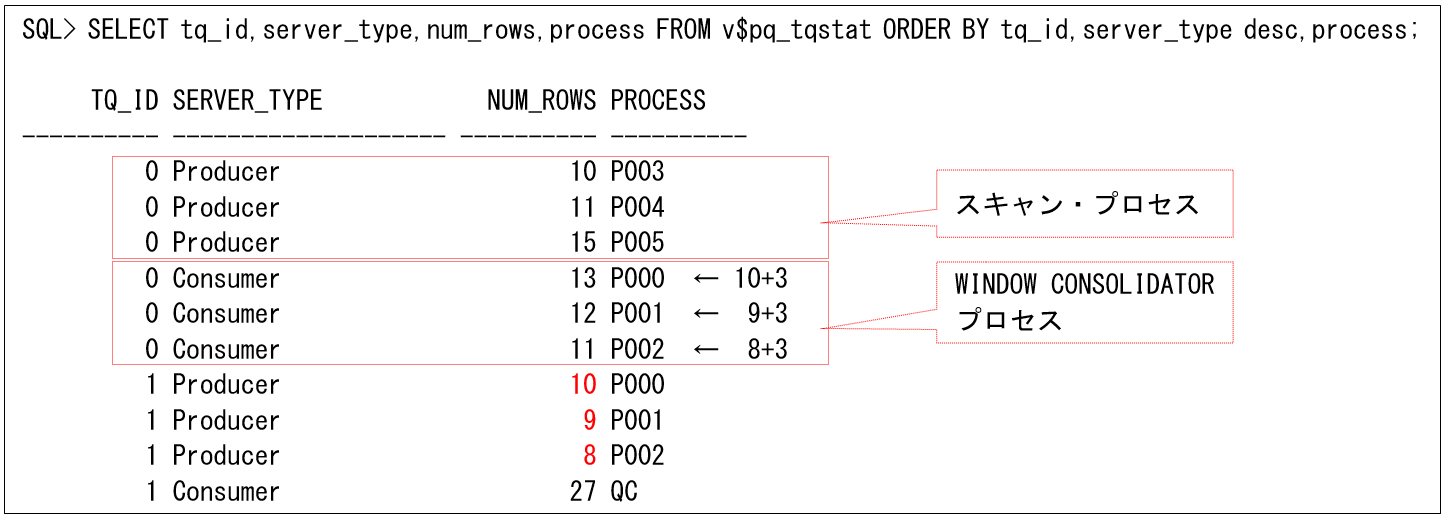
以下は、分かりやすいように、列c3の値がすべて同じデータに対して、上記SQLをパラレル度3で実行した場合です。PARTITION BY句の値がすべて同じなので、それぞれのPQプロセスのファンクション途中結果の一意な値が1件になります。これをCONSOLIDATORプロセスにBROADCAST分散するので、それぞれパラレル度と同じ数(この例では3)だけ増加しているのが分かります。
このときもPQ_DISTRIBUTE_WINDOW(1)ヒントで、2ステージで行わないようにすることが可能です。また、PQ_DISTRIBUTE_WINDOW(2)ヒントで、強制的に2ステージにすることもできます。
このように、分析ファンクションをパラレル実行するときには、条件によってデータ分散方法が異なることを知っておいてください。
2. その他のパラレル実行機能
ここからは、パラレル実行関係でOracle12cから拡張されてまだ説明していない、以下の機能について説明しようと思います。
- UNIONブランチの同時実行
- Small Table Replicate(小さい表の複製)
- パラレルDMLヒント
- GROUP BYの排除
(1)UNIONブランチの同時実行
UNION(またはUNION ALL)演算子のSQLをパラレル実行したときに、パラレル実行できない問合せブランチが存在すると、効果的に実行することができません。そのため、Oracle12cから複数のブランチを同時に実行できるようになりました。
問合せには、リモートDBアクセスなどのシリアル実行になるものがあります。そのような問合せをUNION演算子のブランチに指定すると、効果的に実行することができませんでしたが、このようなブランチを同時に実行することで、処理時間を短縮することができるようになります。
例えば、以下のような一つのブランチだけが、パラレル実行するようなSQLのときに実行されます(実行されると実行計画に、以下の左側のようなPX SELECTORが出力されます)。また、ヒント(PQ_CONCURRENT_UNION / NO_PQ_CONCURRENT_UNION)で強制的に実行させることもできます。
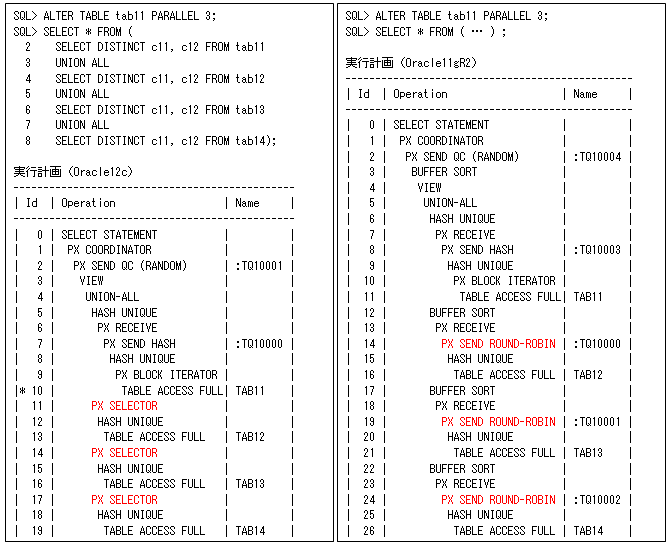
以下は、分かりやすいように、実行結果を各ブランチで1件だけにした場合です。それぞれのPQプロセスの処理件数を見てみると、tab1のパラレル実行を行った後に、tab2からtab4をそれぞれのPQプロセスで同時に行っています(パラレル度が3なので、p000プロセスが二つのテーブルのデータを処理しています)。

(2)Small Table Replicate(小さい表の複製)
Oracle12cから小さい表のBROADCAST分散をデータ分散なしにすることが可能になりました。
第39回の「(2)データ分散なしとブロードキャスト」で説明しましたが、正確にはOracle12cからできるようになった機能になります。説明が足りませんでしたので、ヒントも含めてもう少し説明します。
表結合するときに、片方の表の結合する件数が少ないとBROADCAST分散することで、もう一つの表をデータ再分散しないようにします(これによりデータの偏りを少なくすることができます)。ただし、データ件数が非常に少ない表のときは、各プロセスでデータの複製を作成した方が(すべてのデータをスキャンした方が)、データ転送する必要がなく効果的です。そのため、Oracle12cからBROADCAST分散しないように追加された機能になります。以下の実行計画のように、最初にアクセスする表の各スキャン・プロセスがすべてスキャンするので、どちらの表もデータ再分散していないのが分かります。
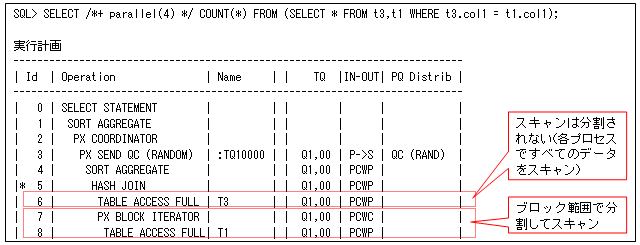
これはオプティマイザが自動的に判断しますが、以下のようにNO_PQ_REPLICATEヒントで強制的にBROADCAST分散にすることも可能です。また、PQ_REPLICATEヒントで強制的にデータ分散なしにすることもできます。
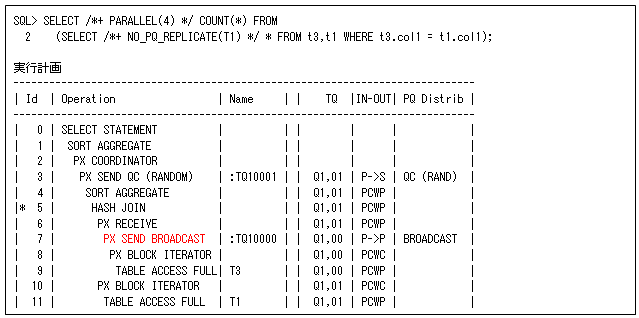
これの使い分けは、スキャンするサイズによって判断します。例えば、結合するデータが少なくてもスキャンするデータが多い場合(フィルター条件によって行数が非常に少なくなる場合など)はBROADCAST分散の方が効果的です。
(3)パラレルDMLヒント
Oracle12cからパラレルDMLヒント(ENABLE_PARALLEL_DML / DISABLE_PARALLEL_DML)が追加されました。
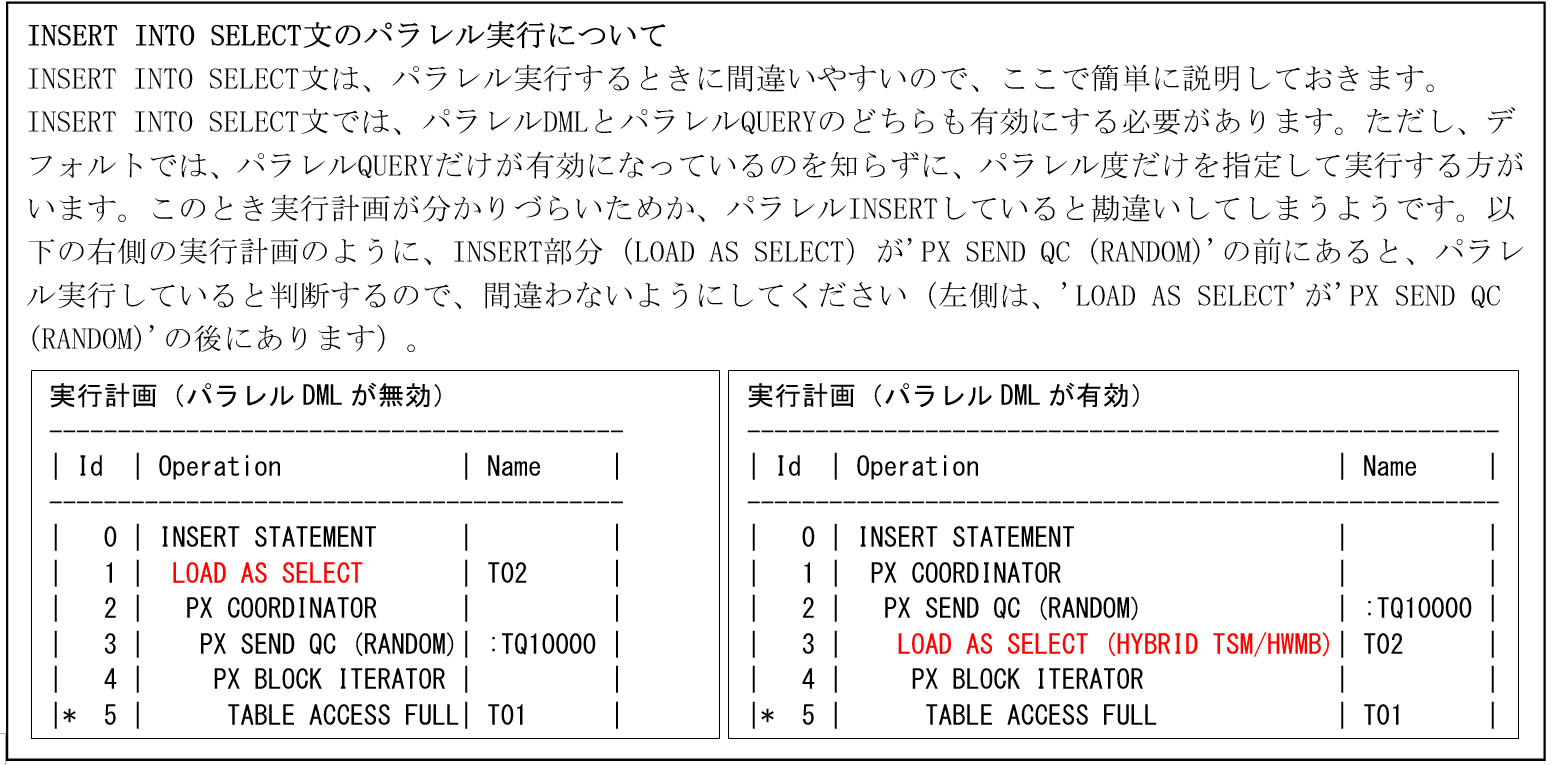
パラレルDMLは、第20回で説明したように、デフォルトはDISABLEになっているので、パラレルDMLを行うには以下の左側のように、ALTER SESSIONでモードを有効にする必要がありましたが、Oracle12cからヒントだけでも可能になりました。以下の右側のように実行しますが、SQLのモードを有効にするだけになるので、パラレル度を指定しないと動作しません(以下は、PARALLELヒントで指定しています)。

シリアル実行するSQLがあるときに、明示的にDISABLE_PARALLEL_DMLヒントで特定のSQLのモードだけを無効にするような使い方も可能になります。例えば、表にPARALLEL句(パラレル度)が指定されていたときに、SQLごとにパラレルDMLを行うか行わないかを、このヒントだけでも指定することが可能になります。
(4)GROUP BYの排除
これはパラレル実行には関係ないのですが、説明できていなかったので、これも記載しておきました。
第34回で説明した不必要な処理の排除の問合せ変換(SQL自動変換)に、Oracle12cから「GROUP BYの排除」も追加されました。
インライン・ビュー内のGROUP BY句は、結合する前に行数を削減できるのがメリットになります。そのため、結合がないときには、GROUP BY句を主問合せとインライン・ビューに指定していると、オーバーヘッドになってしまうので、Oracle12cから以下の左側のように、実行しないようになりました。このようなことを知らない方でも効果的に実行できるようになります。
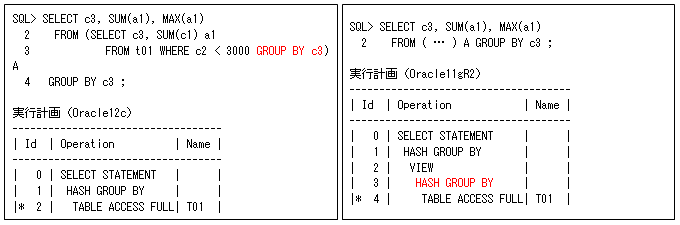
このSQLは、一見するとGROUP BYを2度行う必要があるように思われますが、以下のSQLのように1度のGROUP BYで問題ありません(同じGROUP BY句でSUM関数の後にMAX関数を実行しても結果は変わりません)。そのため、以下のSQLのように内部的に変換を行います。

3. おわりに
今回は分析ファンクションのパラレル実行とOracle12cのその他のパラレル実行機能について説明しましたが、少しは参考になりましたでしょうか。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
