皆さんこんにちは、関東の桜は散ってしまいましたが、過ごしやすい気候になりましたね。私はこの時期が最も好きですが、花粉症の方は大変と思いますので頑張ってください。
今回は第44回の続きとしてパフォーマンス問題になりやすいOR条件について、今まで説明できていなかったことをいくつか説明しようと思います。後半に、SQL計画ディレクティブの使用についても少し説明していますので、参考にしてください。
1. OR条件の続き
OR条件は、パフォーマンス問題になりやすいSQLですが、そうは言っても使用する機会は意外と多いように思います。そこで、第44回の続きとして、最近目にしたOR条件でパフォーマンス問題になっていた(特に、大量のデータに対するパラレル実行で問題になっていた)以下について説明しようと思います。処理によっては使用する必要があるのも分かりますが、パフォーマンス問題になっては意味がないので、SQLチューニングの参考にしていただければと思います。
- ネストした副問合せ内のOR条件
- 外部結合に対するOR条件
- パラレル実行時のOR拡張
(1)ネストした副問合せ内のOR条件
まずは、ネストした副問合せ内にOR条件があるような場合について説明します。
第44回でネストした副問合せ外のOR条件については説明しましたが、副問合せ内のOR条件までは説明していなかったので、それについても紹介しておきます。これもネスト解除されない場合があるので、どのようなことに注意して改善するかなどを、EXISTS条件とNOT EXISTS条件の例を使用して説明しようと思うので参考にしてください。
副問合せと主問合せの表に対するフィルター条件に、OR条件を行っているSQLで問題になります(副問合せの表に対するフィルター条件だけでは、問題にならないので間違わないでください)。このようなSQLだと、以下のようにFILTER操作になってしまうので、主問合せの対象件数が多いとパフォーマンス問題になります(その数だけ副問合せの実行が必要になるので、ハッシュ・セミ結合やハッシュ・アンチ結合の方が効果的です)。

これを改善するには、UNION ALLにするために、OR条件を副問合せの外に出す必要があります。そのため、OR条件を行っているフィルター条件を二つの副問合せに分割します。このSQLの場合には、以下のようにUNION ALLを使用して、EXISTS条件の副問合せを二つに分けることでセミ結合にしています(LNNVL関数は、最初のブランチと同じ結果を検索しないために行っています)。ただし、UNION ALLにすることでセミ結合が2回になるので、それでも効果があるようなときに使用してください(ブルーム・フィルターが動作するときなどは非常に有効です)。
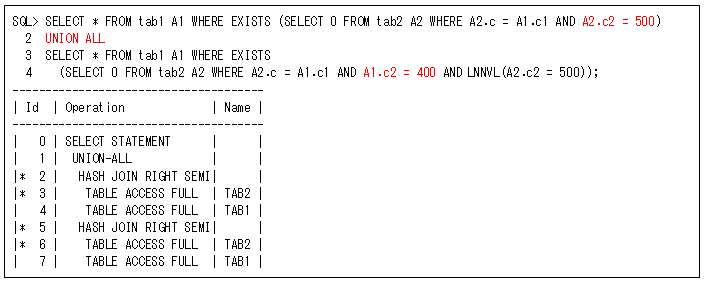
そして、NOT EXISTSについても同じようにFILTER操作になりますが、OR条件を副問合せの外に出すには少し注意が必要です(副問合せ内の条件とは変える必要があります)。
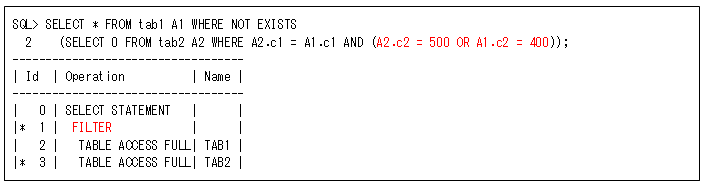
このSQLでは、以下のようにNOT EXISTS条件を二つに分けて、OR条件をAND条件に変更しています(ここを間違わないように注意してください)。AND条件なのでUNION ALLに変更する必要がありませんが、この場合でも表’tab2’は2回アクセスされるので、それでも効果があるときに使用してください(表’tab2’が小さいときなどは効果が大きいです)。

このように少し難しいように感じますが、慣れるとそうでもないと思うので、このようなSQLのときには(FILTER操作が存在するときには)検討してみてください。
(2)外部結合に対するOR条件
次に、外部結合している表に対してOR条件を行っているような場合について説明します。
外部結合している表にOR条件を行う場合とは、NULL以外のデータだけにするために、OR条件でそれぞれの表に’IS NOT NULL’を行うような使用が多いと思います(NULLチェック以外の条件でも同じですが、あまり使用することはないと思います)。
以下のSQLでは、表別名’A’に対して’B’と’C’を外部結合して、列’c2’をNULL以外にするために、CASE式と’IS NOT NULL’をOR条件で行っています。これについてもFILTER操作になってしまい、効率の悪い動作になります(フィルター条件のチェックは、結合や表アクセス時ではなく結合後に行う必要があるので、対象件数が多いとパフォーマンス問題になります)。

また、以下のようにフィルター条件を副問合せ’AA’の外で行っても、FILTER操作をなくすことはできません(’AA.c2 IS NOT NULL’のAA.c2がCASE式になります)。
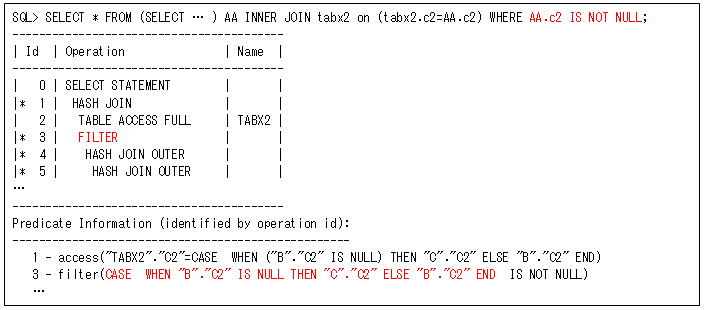
このような外部結合の場合には、UNION ALLにしてもFILTER操作が行われるので、改善するのが非常に難しくなります。そのため、できれば行わない方が良いSQLです。どうしてもNULLを排除したい場合には、他の方法がないか検討するようにしてください。このSQLでは、後から列’c2’で内部結合を行っているので、それで列’c2’のNULLは排除されます。そのため、以下のようにOR条件を削除して、FILTER操作を行わないようにできます。

このような必要ない処理までは、さすがにSQL自動変換(問合せ変換)されないので、最適な実行計画にするにはこのようなことを覚えておくことも重要になります。
(3)パラレル実行時のOR拡張
最後に、OR拡張に対するパラレル実行について説明します。
第9回で説明したように、OR条件を使用するとOR拡張(UNION ALLに変換)を行う場合がありますが、これは索引スキャンが効果的なときなどに行うものなので、対象件数が多い場合には効果的でないときがあります。そのため、件数が多いパラレル実行の場合に、このOR拡張が行われると逆に性能が悪いときがあるので注意してください(一部の処理がパラレル実行されないときがあります)。
以下のようなSQLでは、パラレル実行時にOR拡張されて、片方のブランチの検索結果をマージする前の”BUFFER SORT”がシリアル処理になっています(以下の赤枠のところです)。このデータが多くなければ問題ありませんが、データが多いとここでTEMP領域を使用して遅くなるときがあります。このようなOR拡張が行われると、実行計画に”CONCATENATION”が出力されるので、パラレル実行しているときには注意するようにしてください。
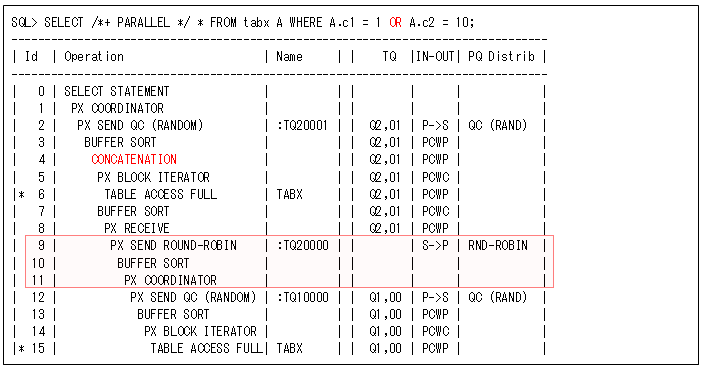
このような実行計画になっている場合には、以下のことを検討してください。
- OR拡張をさせない(NO_EXPANDヒントなどを使用する)
- 手動でUNION ALLのSQLを作成する(シリアルでBUFFER SORTされなくなる)
このように少し注意することで、効果的な実行計画にすることができるので、再確認などしてみてください。
2. SQL計画ディレクティブの使用
第33回で説明したOracle Database 12cからのSQL計画ディレクティブですが、効果的に使用すると非常に便利な機能になるので、使用方法についても説明しておきます。
第49回でSQL計画ディレクティブは多少のオーバーヘッドがあるので、事前に拡張統計(列グループ統計)を作成する方が効果的ですと説明しましたが、SQL計画ディレクティブを使用しても事前に作成することができます。ただし、どのようなタイミングで作成されるかを知らない方も多いようなので、そのタイミングや方法について紹介します。
列グループを使用しているSQLに対して、以下の手順で実行することで列グループ統計が作成されます。その後に初期化パラメータOPTIMIZER_ADAPTIVE_FEATURESを’FALSE’にすると事前作成だけに使用することができます。また、テスト環境で実行計画の確認やチューニングなどで使用するのにも便利だと思います(このとき列グループ統計の移行は必要です)。
- 1).統計フィードバックを動作させてSQL計画ディレクティブをメモリ上に作成する
- 2).SQL計画ディレクティブを使用してオプティマイザ統計の収集待ちにする
- 3).オプティマイザ統計を収集して列グループ統計を作成する
- 4).再コンパイルして列グループ統計を認識させる
それでは、分かりやすいように以下の簡単な例(列グループによって実行計画のE-RowsとA-Rowsが大きく異なるSQL)を使用して説明していきます。
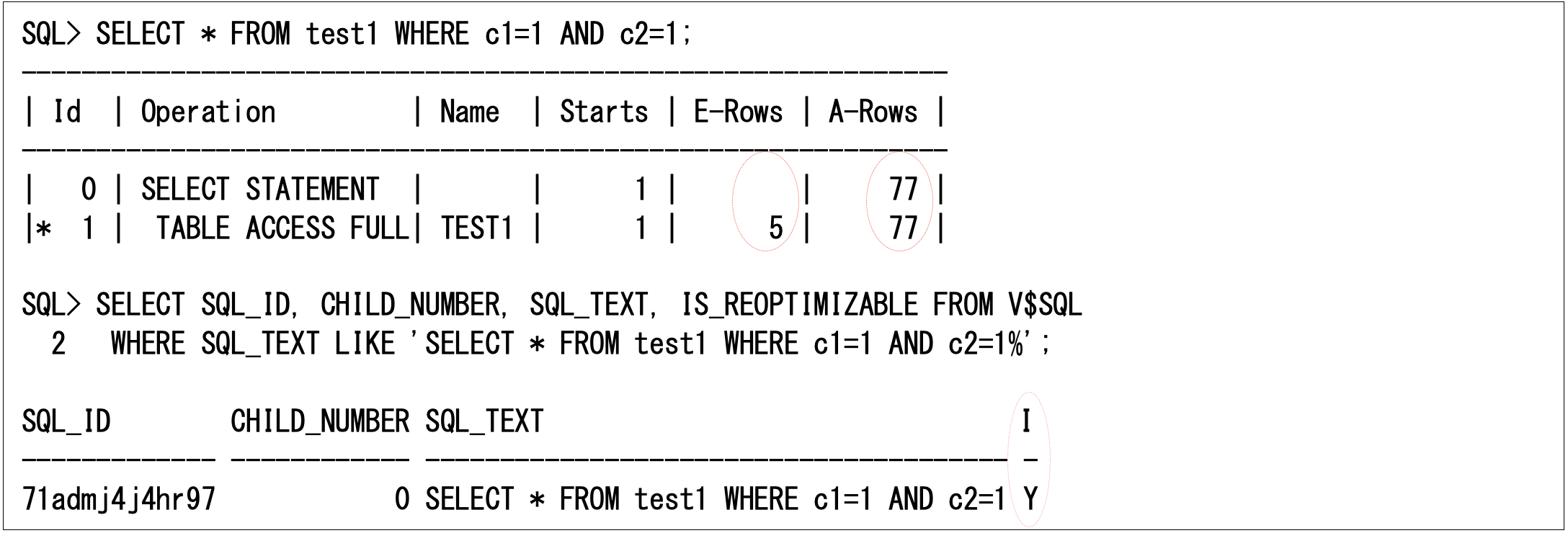
このようなE-Rowsが正しくない状態だとIS_REOPTIMIZABLE=Yとなり、次回実行に再最適化が行われます。このときSQL計画ディレクティブも使用できるようにメモリ上に作成されています。以下のように確認すると、状態が’NEW’として作成されています。ただし、SQL計画ディレクティブを確認するには、ディスク(SYSAUX表領域)に書き込まれている必要があります(15分おきにディスクに書き込みますが、ここではDBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVEプロシージャを使用して、ディスクへの強制的な書き込みを行っています)
SQL> EXEC dbms_spd.flush_sql_plan_directive;
SQL> SELECT TO_CHAR(directive_id) dir_id,object_name obj_name,subobject_name col_name,object_type,type,
2 state||'('||EXTRACTVALUE(d.notes,'/spd_note/internal_state')||')' state,reason
3 FROM dba_sql_plan_directives d INNER JOIN dba_sql_plan_dir_objects USING(directive_id)
4 WHERE object_name IN ('TEST1') ORDER BY 1,2,3,4;
DIR_ID OBJ_NAME COL_NAME OBJECT TYPE STATE REASON
-------------------- -------- -------- ------ ---------------- -------------------- ------------------------------------
15793819631681001063 TEST1 C1 COLUMN DYNAMIC_SAMPLING USABLE(NEW) SINGLE TABLE CARDINALITY MISESTIMATE
15793819631681001063 TEST1 C2 COLUMN DYNAMIC_SAMPLING USABLE(NEW) SINGLE TABLE CARDINALITY MISESTIMATE
15793819631681001063 TEST1 TABLE DYNAMIC_SAMPLING USABLE(NEW) SINGLE TABLE CARDINALITY MISESTIMATE
次に、統計フィードバックを実行すると列グループ統計を作成できる状態になります(SQLを変えるとSQL計画ディレクティブから動的統計が動作します)。ここではコメント’/*test*/’を入れることでSQLを変えて実行しています(このときSQL計画ディレクティブがディスクに書き込まれている必要があるので、テスト時などでは強制的な書き込みが必要になります)。以下のように確認すると、状態が‘MISSING_STATS‘(オプティマイザ統計の収集待ち)になります。Note部を見ると、SQL計画ディレクティブが使用されて、動的統計が動作しているのが分かります。
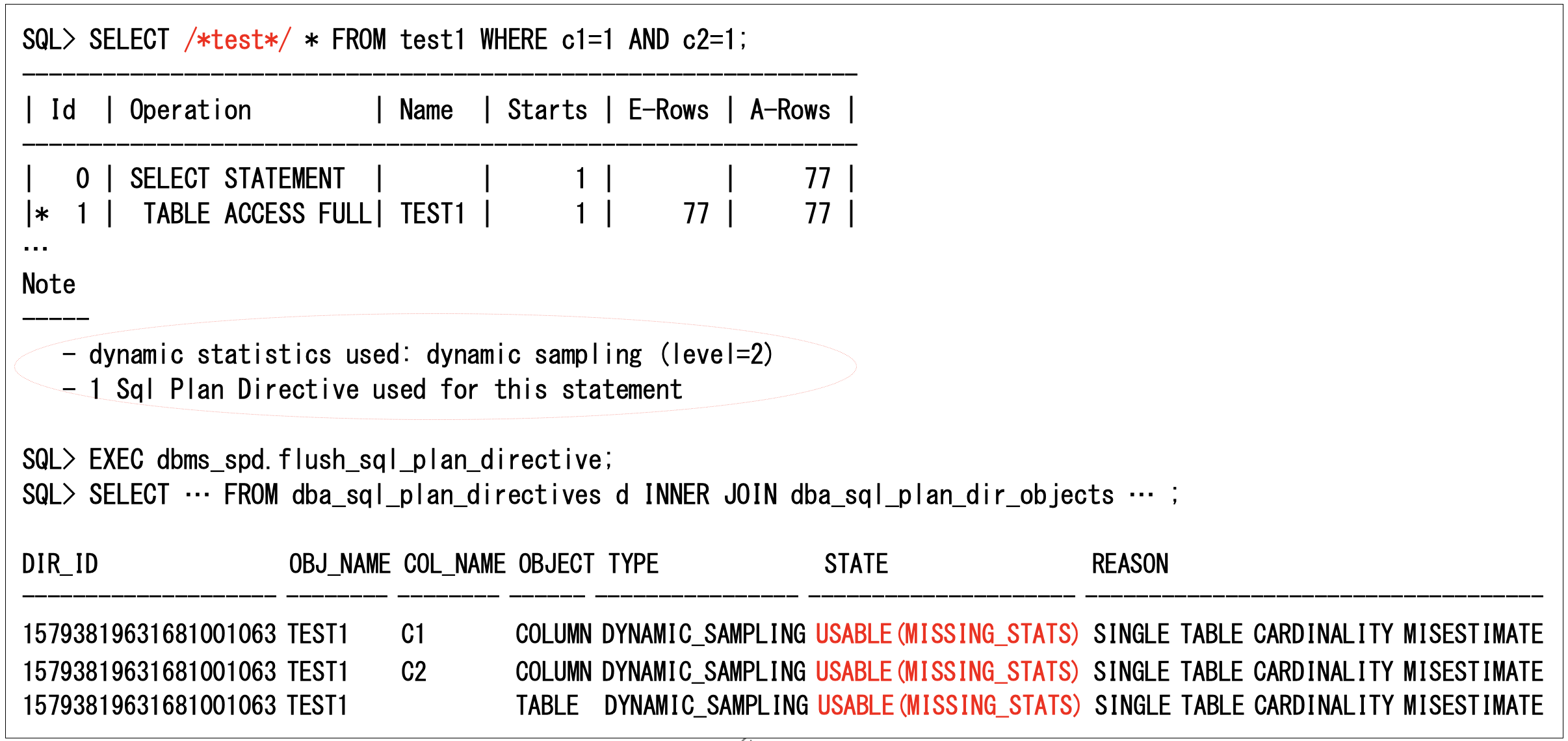
この状態でオプティマイザ統計を収集すると、以下のように列グループ統計が作成されます。ただし、この時点で列グループ統計は存在しますが、データベースで再コンパイルがまだ行われていないため、SQL計画ディレクティブの状態は’MISSING_STATS’のままです。

ここでSQLを実行すると、コンパイル時に列グループ統計が検証されて、以下のように状態は’HAS_STATS’になります。これでSQL計画ディレクティブは使用されなくなるので、自動的に削除されます(デフォルトはSPD_RETENTION_WEEKS_DEFAULT(53週)間使用されないと削除されます)。また、列グループ統計の更新については、デフォルトで使用状況などからオプティマイザ統計の収集時に行われます。

これ以降は、列グループ統計が使用されますが、これも共有SQL領域上にカーソルが存在している間はそのカーソルが使用されるので注意してください。
カーソルが存在しているかの注意などは必要になりますが、このようにしても列グループ統計を作成することができるので、覚えておくと便利な場合もあるかと思います。
SQL計画ディレクティブの状態について
SQL計画ディレクティブの状態(DBA_SQL_PLAN_DIRECTIVES.STATE)が12.1.0.2で変更になっているので、ここで簡単に説明しておきます。
12.1.0.1の状態は詳細に区別されていましたが、12.1.0.2からは’USABLE’と’SUPERSEDED’だけになり、詳細はNOTES列(XMLTYPEデータ型)のINTERNAL_STATEタグに格納されるようになっています。そのため、12.1.0.2での確認はNOTES列を見るようにしてください。それぞれの状態の意味については、以下のように変わっていません(今回の説明で使用しているSQLでは、分かりやすいようにEXTRACTVALUE関数を使用して、STATEを’ <state>(<internal_state>)’の形式で出力するようにしているので、使用するときの参考にしてください)。
| 12.1.0.1 | 12.1.0.2 | 意味 | |
| STATE | STATE | INTERNAL_STATE | |
| NEW | USABLE | NEW | 見積りが正しくないのでディレクティブが作成された |
| MISSING_STATS | USABLE | MISSING_STATS | 次回の収集で拡張統計が収集される |
| PERMANENT | USABLE | PERMANENT | 見積りが正しくないので拡張統計は無視される |
| HAS_STATS | SUPERSEDED | HAS_STATS | 正しい見積りの統計である(ディレクティブは使用されない) |
3. おわりに
今回はOR条件の続きとSQL計画ディレクティブの使用について説明しましたが、少しは参考になりましたでしょうか。それから、多くの方にクイズに答えて頂いてありがとうございました(メッセージや取り上げてほしいテーマを頂いた方には感謝しております。ありがたく読ませていただきました)。好評でしたので、また機会があれば実施したいと思います。これからも頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
