皆さんこんにちは、先月は夏休みを取ってリフレッシュさせていただきました。今年の夏は後半が(お盆過ぎ頃から)雨が多くて少し涼しい感じでしたが、このまま秋になってしまうようですね。いつもの残暑がないのは嬉しいのですが、台風による雨の被害が多いようなので注意してください。
今回は、Oracle Database 12cから拡張されてまだ説明していないオプティマイザ統計の列統計とBツリー索引の圧縮について説明しますので、参考にしてください。
1. 列統計
これまで様々なSQLチューニングについて説明してきましたが、できるだけそのようなSQLを少なくしたいものです。そのため、以下のような列の見積もり行数を正しくするために、第27回で説明したオプティマイザ統計の列統計が重要になります。
- フィルター列(行数を求めて結合順やアクセス方法などを決める)
- 結合列(結合後の行数を求めて結合順を決める)
- Group by列(Group by後の行数を求めて先に行うかを判断する)
これが正確なことで性能問題を少なくしますが、正しく設定できない場合もあるので、Oracle Database 12c(Oracle12c)から拡張された機能も含めて説明します。
(1)列サイズ
列統計のサイズに制限があることを知らない方も多いと思うので、まずは列サイズから説明します。
列統計の対象サイズは、先頭から32バイトまでになるので、大きいサイズだと正しい列統計にならない場合があります。32バイトを超える列サイズはそんなにないと思いますが、列統計が必要な列として使用している場合に、先頭から32バイトまでと後半部分のデータ特性が大きく異なっていないか注意が必要です。このような場合には、できるだけ先頭部分に一意性の高いデータがくるようにする必要があります。例えば、以下のような40バイトの後半部分が一意なデータになっているような場合です(製品コードなどのように、それぞれの桁に意味を持たせているデータに多いと思います)。
col1 ----------------------------------------- AAAAAAAAA-BBBBBBBBB-CCCCCCCCCC-0011111111 AAAAAAAAA-BBBBBBBBB-CCCCCCCCCC-0022222222 AAAAAAAAA-BBBBBBBBB-CCCCCCCCCC-0033333333
Oracle12cからは2倍の64バイトに変更しているので、このような問題も少し改善されていますが、できれば列を分割するなどして、このような列にしないようにしてください。
SUBSTR関数を使用すれば良いのではと思う方もいるかもしれませんが、第9回で説明したように関数を使用すると索引は使用されません(使用するにはファンクション索引が必要です)。また、オプティマイザ統計も第27回で説明した拡張統計の式に対する統計が必要になるので、異なる難しさが発生してしまうことを忘れないでください。
(2)列グループ統計(自動列グループ検出)
次に、第27回や第33回で説明した拡張統計の列グループ統計についてもう少し説明します。
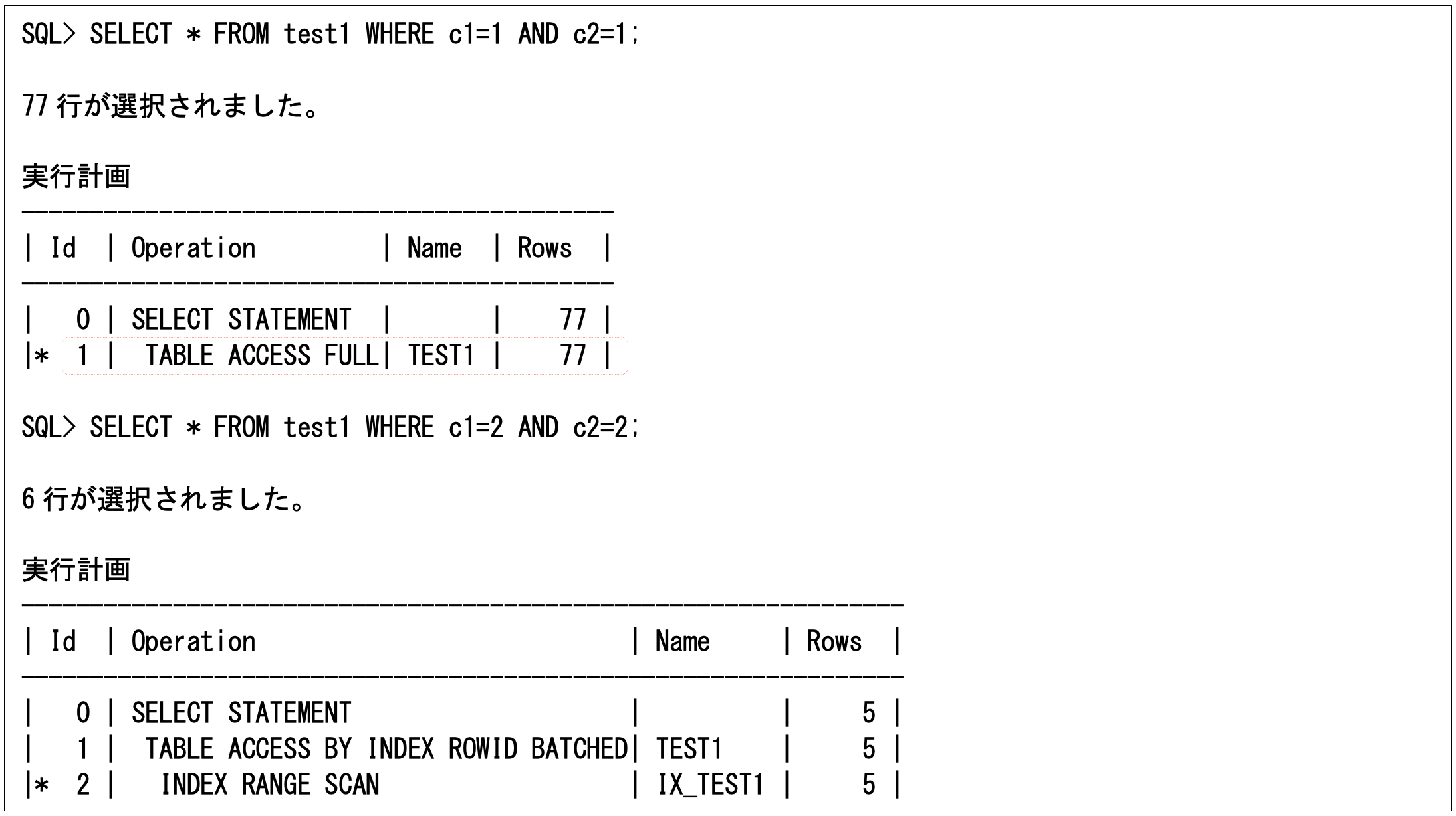
列グループ統計は、常に必要な訳ではありませんが、組合せのデータが単一列のデータとカーディナリティやデータ分布が大きく異なっている場合に必要になります(列グループ統計がないと、列間の関係を均等として求めるからです)。例えば、以下のような条件によって行数が異なるような場合です(検索行数が77行と6行ですが、見積もり行数は5行になっています)。
SQL> SELECT * FROM test1 WHERE c1=1 AND c2=1; 77行が選択されました。 実行計画 ---------------------------------------------------------------- | Id | Operation | Name | Rows | ---------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TEST1 | 5 | |* 2 | INDEX RANGE SCAN | IX_TEST1 | 5 | SQL> SELECT * FROM test1 WHERE c1=2 AND c2=2; 6行が選択されました。 実行計画 ---------------------------------------------------------------- | Id | Operation | Name | Rows | ---------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TEST1 | 5 | |* 2 | INDEX RANGE SCAN | IX_TEST1 | 5 |
この列グループ統計は、自動オプティマイザ統計収集でもデフォルトでは作成しないので、このような組合せを見つけるのは簡単ではありません(すべてのデータ特性を知らないと見つけられないでしょう)。
そのため、基本はSQLを実行して遅くなっているもの(第32回で説明した実行計画の見積もり行数’E-Rows’と実行行数’A-Rows’が大きく異なっているSQLなど)を対象に検討しますが、SQLの数が多いとそれも大変になります。最近では、動的サンプリングやカーディナリティ・フィードバックで対応するようになっていますが、多少のオーバーヘッドがあるので、事前に作成する方が効果的です。そのため、Oracle12cからは、第33回で説明したSQL計画ディレクティブ以外に、自動的に必要な列グループを検出する自動列グループ検出機能が追加されています(この自動列グループ検出機能は、Oracle12cからの新機能となっていますが、Oracle11gR2でも使用できます。そのため、Oracle11gR2で列グループ統計に苦労されている方は、これを使用してください)。これは、以下のような手順で行います。
① DBMS_STATS.SEED_COL_USAGEを実行して監視を行い、見積もりカーディナリティが正しくない列/列グループの使用情報を作成します。
② DBMS_STATS.REPORT_COL_USAGEを実行することで、監視中に作成された列/列グループ使用情報を確認します。
③ DBMS_STATS.CREATE_EXTENDED_STATSを使用して、監視中に取得された使用情報に基づいて列グループを作成します。
分かりやすいように、先程の列統計に問題があったSQLを使用して行ってみます。まずは、事前にオプティマイザ統計を収集して、列統計を出力しておきます(まだ、列グループ、ヒストグラムは作成されていません)。
SQL> EXEC dbms_stats.gather_table_stats(NULL,'test1'); SQL> SELECT column_name,num_distinct,histogram FROM user_tab_col_statistics WHERE table_name = 'TEST1'; COLUMN_NAME NUM_DISTINCT HISTOGRAM ------------------------------ ------------ --------------- C1 63 NONE C2 31 NONE C3 15 NONE
以下のように実行することで、自動的に必要な列グループの検出と作成を行っています(この例では、すべてのテーブルの列グループを検出するために、300秒間の監視を有効にしています)。
SQL> EXEC dbms_stats.seed_col_usage(NULL,NULL,300);
SQL> SELECT * FROM test1 WHERE c1=1 AND c2=1;
SQL> SELECT * FROM test1 WHERE c1=2 AND c2=2;
SQL> SELECT dbms_stats.report_col_usage('user','test1') FROM DUAL;
…
###############################################################################
COLUMN USAGE REPORT FOR USER.TEST1
....................................
1. C1 : EQ
2. C2 : EQ
3. (C1, C2) : FILTER JOIN
###############################################################################
SQL> SELECT dbms_stats.create_extended_stats('user','test1') FROM DUAL;
###############################################################################
EXTENSIONS FOR USER.TEST1
...........................
1. (C1, C2) : SYS_STUF3GLKIOP5F4B0BTTCFTMX0W created
###############################################################################
そして、DBMS_STATS.GATHER_TABLE_STATSなどを実行して列グループ統計を収集します(CREATE_EXTENDED_STATSは、列グループを作成するだけになるので、列グループ統計は作成されないのに注意してください)。このとき、デフォルトではヒストグラムを収集するかを自動的に判断します。以下のように実行することで、追加で作成された列統計を確認できます(この例では、列’c1’と’c2’にもヒストグラムが追加されています)。
SQL> SELECT column_name,num_distinct,histogram FROM user_tab_col_statistics WHERE table_name = ‘TEST1’;
COLUMN_NAME NUM_DISTINCT HISTOGRAM
—————————————- ———— —————
C1 63 FREQUENCY
C2 31 FREQUENCY
C3 15 NONE
SYS_STUF3GLKIOP5F4B0BTTCFTMX0W 1924 HYBRID
SQLを実行すると見積もり行数がほぼ正しい値になっています(最初のSQLの実行計画も最適な全表スキャンになっています)。
監視中に取得された使用情報に対して、すべての列グループを作成しない場合、以下のように作成するものだけを手動で作成することもできます。
SQL> SELECT dbms_stats.create_extended_stats('user','test1','(c1,c2)') FROM DUAL;
列グループにも「(1)列サイズ」で説明した対象サイズの制限があるので注意してください。
このようなOracleデータベースが提供する自動機能は、動作状況を判断して行うものになるので、何も動作していない状態では設定されないので注意してください(第5回で説明したヒストグラム収集列の自動判断もデフォルトで行いますが、SQLで使用されないと対象にならないことを忘れないでください)。
2. Bツリー索引の圧縮
圧縮機能は、物理I/Oの削減やキャッシュ・ヒット率の向上などのパフォーマンスに有効な機能ですが、Bツリー索引の圧縮は第6回でも説明したように、オーバーヘッドによって効果的に使用するのが難しいところがあります。そのため、その索引圧縮の特徴についてOracle12c(12.1.0.2)からの拡張索引圧縮(Advanced Index Compression)も含めて説明します。
第6回で説明したキー圧縮(接頭辞圧縮)は、キーの先頭部分の重複値をブロック・レベルで圧縮する機能になるので、先頭部分に重複値が多いようなキーの場合に効果があります。ただし、重複値が存在するデータでも一意な値は存在するものなので、その割合が多いと圧縮のオーバーヘッドによって、逆にサイズが増えてしまう場合があります(これは、すべてのリーフ・ブロックで同じ圧縮を行うからです)。そのため、圧縮を行うかどうかの判断を難しくしていましたが、Oracle12cからの拡張索引圧縮では以下のような拡張を行うことで改善しています。ただし、単一列の一意索引は、圧縮できるデータがないので使用できません。また、Advanced Compression Optionが必要になります。
- 各ブロックに最適な圧縮が自動的に選択される
データ特性に関する知識がなくても最適な圧縮を行うことが可能になります(一意なデータに対してもオーバーヘッドが少なくなります)。また、圧縮対象列数もブロック単位に決定するので、複数列索引のときに更に効果的に圧縮することが可能になります。 - ブロック内の使用率がしきい値を超えると自動的に圧縮される
高度な行圧縮(以前のOLTP表圧縮)のように、通常のインサートなどの更新でも(索引の作成時以外でも)しきい値を超えると圧縮されるので、スプリットのタイミングを遅らせることが可能になります。
「各ブロックに最適な圧縮が自動的に選択される」について、分かりやすいように以下の簡単な例(一意な値の割合を変えたデータ)を使用して説明します(50,000行のデータに対して、列c01~c03はすべて同じ値、列c11~c13は前半の25,000行が一意、列c21~c23は前半の40,000行が一意、列c31~c33はすべてが一意になります)。
CREATE TABLE tab10 (c01 CHAR(10), c02 CHAR(10), c03 CHAR(10), -- すべて同じデータ
c11 CHAR(10), c12 CHAR(10), c13 CHAR(10), -- 25000まで一意データ
c21 CHAR(10), c22 CHAR(10), c23 CHAR(10) -- 40000まで一意データ
c31 CHAR(10), c32 CHAR(10), c33 CHAR(10)); -- すべて一意データ
DECLARE
vc1 CHAR(10);
vc2 CHAR(10);
vc3 CHAR(10);
BEGIN
for i in 1..50000 loop
if i <= 25000 then
vc1 := TO_CHAR(i,'FM0000000000'); -- 一意なデータ生成
else
vc1 := TO_CHAR(MOD(i,5),'FM0000000000'); -- 0~4を設定
end if;
if i <= 40000 then
vc2 := TO_CHAR(i,'FM0000000000'); -- 一意なデータ生成
else
vc2 := TO_CHAR(MOD(i,5),'FM0000000000'); -- 0~4を設定
end if;
vc3 := TO_CHAR(i,'FM0000000000'); -- 一意なデータ生成
INSERT INTO tab10 VALUES (10000,10000,10000, vc1,vc1,vc1, vc2,vc2,vc2, vc3,vc3,vc3);
end loop;
commit;
END;
/
まずは、それぞれの列に索引(非圧縮、キー圧縮、拡張索引圧縮)を作成してみます。
SQL> CREATE INDEX tab10_ix01 ON tab10 (c01) PCTFREE 0; SQL> CREATE INDEX tab10_ix02 ON tab10 (c02) PCTFREE 0 COMPRESS; SQL> CREATE INDEX tab10_ix03 ON tab10 (c03) PCTFREE 0 COMPRESS ADVANCED LOW; … SQL> CREATE INDEX tab10_ix31 ON tab10 (c21) PCTFREE 0; SQL> CREATE INDEX tab10_ix32 ON tab10 (c22) PCTFREE 0 COMPRESS; SQL> CREATE INDEX tab10_ix33 ON tab10 (c23) PCTFREE 0 COMPRESS ADVANCED LOW;
以下のように、それぞれの索引のリーフ・ブロック数を出力して確認します。
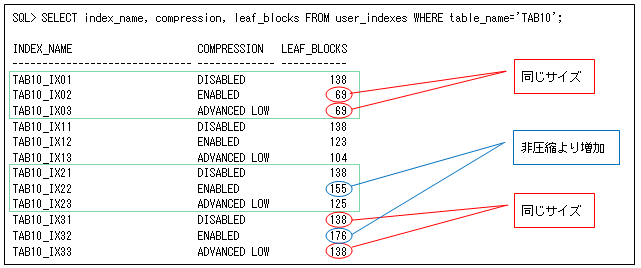
- すべて同じデータの場合
すべて圧縮できるデータに対して、拡張索引圧縮とキー圧縮のサイズが同じことから、圧縮方法に変わりがないことが分かります。 - 前半の25,000行が一意な場合
これでも圧縮した方が効果的ですが、一意データが存在する分だけ拡張索引圧縮の効果が大きいのが分かります。これは、一意データのブロックを圧縮しないことで、オーバーヘッドを削減しているからです(これが各ブロックに最適な圧縮が選択されるということです)。 - 前半の40,000行が一意な場合
これくらい一意データが増えるとキー圧縮は非圧縮よりもブロック数が増えていますが、拡張索引圧縮ではそのようなことがないのが分かります。 - すべてが一意なデータの場合
圧縮するデータがないので、拡張索引圧縮は非圧縮と同一サイズになっていますが、キー圧縮は更にブロック数が増えています。
次に、以下のような複数列索引についても確認してみます。
SQL> CREATE INDEX tab10_ix41 ON tab10 (c01,c21) PCTFREE 0; -- 先頭列がすべて同じ SQL> CREATE INDEX tab10_ix42 ON tab10 (c02,c22) PCTFREE 0 COMPRESS; -- 先頭列がすべて同じ SQL> CREATE INDEX tab10_ix43 ON tab10 (c03,c23) PCTFREE 0 COMPRESS ADVANCED LOW; -- 先頭列がすべて同じ SQL> CREATE INDEX tab10_ix42_2 ON tab10 (c02,c22) PCTFREE 0 COMPRESS 1; -- 先頭列だけ圧縮 SQL> CREATE INDEX tab10_ix43_2 ON tab10 (c33,c23) PCTFREE 0 COMPRESS ADVANCED LOW; -- 先頭列が一意
これもリーフ・ブロック数を確認します(索引’tab10_ix42’と’tab10_ix42_2’は同じ列になるので同時に作成できませんが、分かりやすいように一覧で出力しています)。
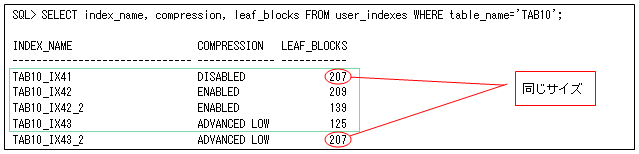
- “すべて同じ、40,000行が一意”の順に作成した場合(TAB10_IX41、TAB10_IX42、TAB10_IX42_2、TAB10_IX43)
キー圧縮は、先頭列だけ圧縮する索引’TAB10_IX42_2’でないと非圧縮よりサイズが増えてしまいますが、拡張索引圧縮はそんなことを気にする必要がありません。また、最もサイズが小さくなっているので、2列目も圧縮されていることから、ブロック毎に圧縮対象列数が異なっているのが分かります。 - 先頭列が一意の拡張索引圧縮の場合(TAB10_IX43_2)
非圧縮’TAB10_IX41’と同じサイズになっていることから、拡張索引圧縮でも先頭列が一意だと圧縮されないのが分かります。
このようにキー圧縮は作成する列によっては非効率になっていますが、拡張索引圧縮はすべてで最適に行っているので、非常に使いやすくなっているのが分かります。また、以下のようにパーティション・レベルでも指定できるので、再構築などのメンテナンスでも問題ありません(索引圧縮は、表圧縮のようなデータ変更による行連鎖などは発生しませんが、非圧縮の索引と同じようにスプリットによる断片化によって効果が低下するので、定期的な再構築は必要です)。
SQL> ALTER INDEX ix_tab3 REBUILD PARTITION p01 COMPRESS ADVANCED LOW; SQL> SELECT partition_name,compression FROM user_ind_partitions WHERE index_name = 'IX_TAB3'; PARTITION_NAME COMPRESSION -------------------- ------------- P01 ADVANCED LOW P02 DISABLED …
今回は、「ブロック内の使用率がしきい値を超えると自動的に圧縮される」について詳しく説明できませんでしたが、索引作成時の圧縮率向上だけでも非常に有効な機能といえるので、利用することを検討してみてください。
3. おわりに
今回はオプティマイザ統計の列統計とBツリー索引の圧縮について説明しましたが、少しは参考になりましたでしょうか。これからも頑張りますのでよろしくお願いします。質問をお待ちしています(このような内容を取り上げて欲しいというご要望などもお待ちしております)。
それでは、第50回まで、ごきげんよう。
