皆さんこんにちは、まだ猛暑が続いていますが、体調は大丈夫でしょうか。それと局地的なゲリラ豪雨の被害が続いていますので、それにも気を付けてください。今年の夏は変な感じですが、残暑に負けずに頑張りましょう。
今回は、「パフォーマンスの良いSQL文について」の続きとして、UPDATE(更新処理)について説明します。複雑なUPDATE文、効率の悪いUPDATE文を見る機会が多いような気がするため、効率良い更新処理(特にMERGE文)について説明しようと思いますので、参考にして下さい。
1. 複雑な更新処理について
まずは、複雑な更新処理について説明しましょう。
更新処理は、システムの中でよく使用するものですが、複雑になり易い性質の処理ですので、意外と効率良く使用できていないケースが多いように思います。どうして複雑な(効率良くない)更新処理になるのかというと、表結合してUPDATE操作するような処理が多いからです(これを使用したくなる気持ちもよく分かります)。更新処理は、基本はUPDATE文で行いますが、結合することを想定したSQLではないので、副問合せなどを使用する必要があり、それで複雑なSQLになってしまう場合が多いのです。これによって実行計画に影響することにより、パフォーマンスの問題になる場合もあります。そのため、そのようにならない効果的なデータベース設計をすれば良いのですが、なかなか簡単にできるものではないと思いますので、ここでは更新処理について少し整理してみました。第11回の「更新可能な結合ビューについて」では、結合ビューの更新ができない場合についてだけ説明しましたが、もう少し更新処理についてパフォーマンスも含めて説明します。
(1)UPDATE文について
更新処理を行うUPDATE文について説明します。
UPDATE文には、対象表を一つだけしか指定することができないので、表結合によるUPDATE操作は複雑になってしまう場合が多いです。それが実行計画やパフォーマンスにも影響することが、大きな問題になります。UPDATE文を記述するだけでも難しいですが、効果的に実行するように記述するのは更に難しくなります。そのため、どのように行うと効果的なのかを考えて、上手く使い分けられるようになることが重要です。
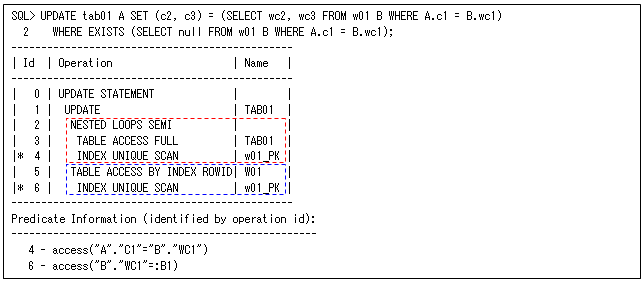
よくある一般的な更新処理は、更新に必要なデータを一時的なテーブルに作成して、そのテーブルと結合することで、まとめてUPDATE操作を行うような場合です(以下の例は、更新データをテーブル”w01”に作成している想定で、そのテーブルと結合することでUPDATE操作を行っています)。これを単純に副問合せを使用して更新処理を行うと、SQLと実行計画は以下のようになります(実行計画の赤い点線がWHERE句の副問合せ処理で、青い点線がSET句に対する副問合せです)。これは、UPDATE文では副問合せをSET句(更新データを求めるため)とWHERE句(更新対象表の行を絞り込むため)のそれぞれに指定する必要があるからです。ただし、別々に副問合せを実行するのではなく、WHERE句で絞り込んだ行から、SET句のテーブル”w01”の列”wc2”、”wc3”を求めるように行ってはいます。
このような表結合してUPDATE操作する処理は、以下のようにインライン・ビューを使用した方が、分かり易く効果的です(当然に視認性も向上するため、ミスも削減することができます)。実行計画も以下のように効率良くなりますので(すべての行を結合する必要があるので、効果的なハッシュ結合を行っています。そして、テーブル”w01”は1回しかアクセスしていません)、できるだけインライン・ビューを使用するようにしてください。ここでは、二つのテーブルの結合例だけなので、そんなに複雑には感じませんが、これがもっと多くのテーブルを結合するような場合は、更に複雑になってしまいます(そのようなSQLをよく見かけます)。
SQL> UPDATE (SELECT * FROM tab01 A, w01 B WHERE A.c1 = B.wc1) SET c2 = wc2, c3 = wc3;
-------------------------------------
| Id | Operation | Name |
-------------------------------------
| 0 | UPDATE STATEMENT | |
| 1 | UPDATE | TAB01 |
|* 2 | HASH JOIN | |
| 3 | TABLE ACCESS FULL| W01 |
| 4 | TABLE ACCESS FULL| TAB01 |
-------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A"."C1"="B"."WC1")
(2)ビューの更新
もう少しビュー(またはインライン・ビュー)の更新について説明します。
ビューは、すべての場合で更新できる訳ではないので、多少の注意が必要です。第11回で説明した結合ビューの「ORA-01779」エラー以外に、以下の要素が含まれるビューなどもUPDATE操作することはできません(この要素が含むと複数行が対象になるからです)。そのため、よりSQLが複雑になり易い訳です。
- 集合演算子(UNION、UNION ALLなど)
- DISTINCT演算子
- 集計ファンクションまたは分析ファンクション
- GROUP BY、ORDER BY、MODEL、CONNECT BYまたはSTART WITH句
- SELECT構文のリストにあるコレクション式
- SELECT構文のリストにある副問合せ
一般的によく行うのが、結合ビューだと思いますので、それについてもう少し説明します。
第11回で説明したように、結合ビューには更新できない列があります。一般的なリレーショナル・データベースの1対多の関係の結合では、論理表現であるビューに対して、どちらかのテーブルだけの更新しか行うことができないようになります。これは、主キーで結合するテーブルについては、1行のデータが複数の行に存在することになるからです(1対1の関係の場合は、どちらも更新可能です)。そのため、結合ビューを使用するときは、どのテーブルが更新可能かを知っておくのも重要です(確認方法は、第11回を参照してください)。ただし、結合列に主キー(または一意索引)が存在しないと、1対多などの関係を知ることができないので、結合ビューから更新することはできなくなります。
「(1)UPDATE文について」の例の場合、使用している別テーブル”w01”を更新するのに、以下のようにインライン・ビューを使用することはできません(この例では、結合列の”tab01.c1”が外部キー、”w01.wc1”が主キーという想定なので、主キー側のテーブルは更新できないということです)。
ORA-01779: キー保存されていない表にマップする列は変更できません。
このような場合には、「(1)UPDATE文について」の最初で説明したSQLのように、EXISTS条件(またはIN条件)などを使用する必要があるため、以下のように構文が多少複雑になってしまいます。MAX関数を使用しているのは、テーブル”tab01”を外部キーで結合しているため、単一行副問合せにする必要があるからです(同一値になる保証があればDISTINCT演算子で問題ないですが、そうでない場合はこのようにMAX関数などで単一行にする必要があります。このようなことが、副問合せを使用するときの難しさだと思います)。実行計画にも列”tab01.c1”のそれぞれの行に対して、MAX関数を行うように”SORT AGGREGATE”が追加されています。
2 WHERE EXISTS (SELECT null FROM tab01 A WHERE A.c1 = B.wc1)
————————————-
| Id | Operation | Name |
————————————-
| 0 | UPDATE STATEMENT | |
| 1 | UPDATE | W01 |
|* 2 | HASH JOIN SEMI | |
| 3 | TABLE ACCESS FULL| W01 |
| 4 | TABLE ACCESS FULL| TAB01 |
| 5 | SORT AGGREGATE | |
|* 6 | TABLE ACCESS FULL| TAB01 |
————————————-
Predicate Information (identified by operation id):
—————————————————
2 – access(“A”.”C1″=”B”.”WC1″)
6 – filter(“A”.”C1″=:B1)
このようになってくると、SQLも更に複雑になってくるため、あまり効果的な実行計画にならない場合が多くなりますので、注意する必要があります。そのため、私はMERGE文を使用することを薦めしているのですが、まだ知らない方も多いような気がしますので、次からはMERGE文について説明します。
2. MERGE文について
ここからは、第11回で説明したMERGE文についてもう少し説明しましょう。
MERGE文は、UPDATE操作とINSERT操作を同時に行うことが可能な、Oracle9iからの便利なSQLですが、UPDATE操作だけやINSERT操作だけを行うことも可能です(特に、これを知らない方が多いように思います)。このMERGE文は、UPDATE操作だけでも使い方によっては、非常に便利で効果的なSQLです。特に、表結合が必要な処理には有効です。これは、MERGE文が対象表(INTO句)とソース表(USING句)を結合条件(ON句)で結合することを前提にしている機能だからです。第11回では「ORA-01779」エラーの回避と視認性についてだけ説明しましたが、パフォーマンスにも効果的ですので、もっと使用して欲しいと思い、少しノウハウを含めて説明します。
(1)UPDATE操作だけ
まずは、UPDATE操作だけのMERGE文について説明します。
これにより結合条件が一致した場合に、UPDATE操作だけを行うようになります。簡単な例(t01.c1とt02.c1が同じ場合に、t01.c3にt02.c2を加算する処理)を使用して考えてみましょう。以下の左側がMERGE文、右側がUPDATE文で記述したSQLになります。UPDATE文を使用した右側は「(1)UPDATE文について」で説明したような実行計画になります。左側のMERGE文を使用した実行計画では、結合ビューを使用したときのように、無駄なアクセスがないのが分かります。また、ビューとは異なり、どちらだけしか更新できないなどの制限もないため(だから、結合ビューが使用できない更新のときには有効なのです)、使い易いSQLだということが、分かって頂けると思います。
SQL> MERGE INTO t01 A
2 USING (SELECT c1,c2 FROM t02) B
3 ON (A.c1 = B.c1)
4 WHEN MATCHED THEN UPDATE SET A.c3 = A.c3 + B.c2;
-------------------------------------
| Id | Operation | Name |
-------------------------------------
| 0 | MERGE STATEMENT | |
| 1 | MERGE | T01 |
| 2 | VIEW | |
|* 3 | HASH JOIN | |
| 4 | TABLE ACCESS FULL| T02 |
| 5 | TABLE ACCESS FULL| T01 |
-------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("A"."C1"="T02"."C1") |
SQL> UPDATE t01 A
2 SET A.c3 = A.c3 + (SELECT DISTINCT c2 FROM t02 B
3 WHERE A.c1 = B.c1)
4 WHERE A.c1 IN (SELECT c1 FROM t02);
------------------------------------
| Id | Operation | Name |
------------------------------------
| 0 | UPDATE STATEMENT | |
| 1 | UPDATE | T01 |
|* 2 | HASH JOIN SEMI | |
| 3 | TABLE ACCESS FULL| T01 |
| 4 | TABLE ACCESS FULL| T02 |
| 5 | HASH UNIQUE | |
|* 6 | TABLE ACCESS FULL| T02 |
------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A"."C1"="C1")
6 - filter("B"."C1"=:B1) |
MERGE文で検索条件を指定する場合には、ON句とUPDATEのWHERE句のどちらでも指定することが可能です。ここからは、どちらが効率良いかを簡単に説明します。
以下は、どちらも同じ結果になります(左側がON句で、右側がWHERE句で条件指定を行っています)。Predicate Informationを確認すると、左側がテーブル”t01”のアクセスでfilter”c2<104”を行っているのが分かります。これは、ON句は表結合時に行うのに対して、WHERE句は結合後に(つまりUPDATE操作する時に)条件チェックを行う必要があるからです(これによってINSERT操作がある場合には、どちらでも処理させたくない行を、WHERE句で対象外にすることが可能になっています)。つまり、INSERT操作がない場合には、どちらで行っても問題ないということになるので、左側のON句で行った方が結合処理が効果的ということになります。
2 USING (SELECT * FROM t02) B
3 ON (A.c1 = B.c1 AND A.c2 < 104)
4 WHEN MATCHED THEN UPDATE SET A.c3 = A.c3 + B.c2;
————————————-
| Id | Operation | Name |
————————————-
| 0 | MERGE STATEMENT | |
| 1 | MERGE | T01 |
| 2 | VIEW | |
|* 3 | HASH JOIN | |
| 4 | TABLE ACCESS FULL| T02 |
|* 5 | TABLE ACCESS FULL| T01 |
————————————-
Predicate Information (identified by operation id):
—————————————————
3 – access(“A”.”C1″=”T02″.”C1″)
5 – filter(“A”.”C2″<104)
SQL> MERGE INTO t01 A
2 USING (SELECT * FROM t02) B
3 ON (A.c1 = B.c1)
4 WHEN MATCHED THEN
5 UPDATE SET A.c3 = A.c3 + B.c2 WHERE A.c2 < 104;
-------------------------------------
| Id | Operation | Name |
-------------------------------------
| 0 | MERGE STATEMENT | |
| 1 | MERGE | T01 |
| 2 | VIEW | |
|* 3 | HASH JOIN | |
| 4 | TABLE ACCESS FULL| T02 |
| 5 | TABLE ACCESS FULL| T01 |
-------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("A"."C1"="T02"."C1")
ただし、更新列(この例ではA.c3です)は、以下のようにON句で指定することができないので注意してください。
2 USING (SELECT * FROM t02) B
3 ON (A.c1 = B.c1 AND A.c3 < 104)
4 WHEN MATCHED THEN UPDATE SET A.c3 = A.c3 + B.c2;
ORA-38104: ON句で参照する列は更新できません: “A”.”C3″
それから、ソース表に対する検索条件については、基本はUSING句で行った方が視認性も良く効果的です(何度か説明したように、結合する行数を削減できるからです)。これについてもINSERT操作がある場合には、UPDATE操作またはINSERT操作のどちらかだけで条件指定を行うのであれば、そのWHERE句で行う必要があります。このように、記述方法によって実行計画が異なってきますので、行う処理によって気を付ける必要があります。このようなことを意識して使用することで、より効果的に更新を行うことが可能になりますので、使用してみてください。
(2)INSERT操作だけ
最後に、INSERT操作だけのMERGE文について説明します。
これにより結合条件が一致しない行を、INSERT操作だけ行うようになります。そのため、これをINSERT INTO SELECT文で行うと、以下の右側のように第29回で説明したアンチ結合(NOT INまたはNOT EXISTS条件など)を使用する副問合せになります。INSERT操作(WHEN NOT MATCHED THEN)を含むMERGE文は、UPDATE操作だけと異なり、ソース表”t02”に対する外部結合を行います(以下の左側は”HASH JOIN OUTER”を行っています)。これは、結合条件に一致しないソース表の行も必要だからです(この一致しない行がINSERT対象のデータになるからです)。つまり、以下のA-Rows(実際の処理行数)のように、結合時の結果行が増えてしまう場合があるので、INSERT操作だけのMERGE文は効率が良くないと言えます(ソース表が大きいときは注意が必要です)。そのため、INSERT操作だけの場合はINSERT INTO SELECT文を使用してください。
2 USING (SELECT * FROM t02) B
3 ON (A.c1 = B.c1)
4 WHEN NOT MATCHED THEN INSERT VALUES (B.c1,B.c2,B.c3);
—————————————————–
| Id | Operation | Name | | A-Rows |
————————————-<省略>———-
| 0 | MERGE STATEMENT | | | |
| 1 | MERGE | T01 | | |
| 2 | VIEW | | | 8 |
|* 3 | HASH JOIN OUTER | | | 8 |
| 4 | TABLE ACCESS FULL| T02 | | 8 |
| 5 | TABLE ACCESS FULL| T01 | | 4 |
—————————————————–
Predicate Information (identified by operation id):
—————————————————
3 – access(“A”.”C1″(+)=”T02″.”C1″)
SQL> INSERT INTO t01
2 SELECT * FROM t02
3 WHERE c1 NOT IN (SELECT c1 FROM t01);
---------------------------------------------------------
| Id | Operation | Name | | A-Rows |
-----------------------------------------<省略>----------
| 0 | INSERT STATEMENT | | | |
| 1 | LOAD TABLE CONVENTIONAL | T01 | | |
|* 2 | HASH JOIN ANTI NA | | | 4 |
| 3 | TABLE ACCESS FULL | T02 | | 8 |
| 4 | TABLE ACCESS FULL | T01 | | 4 |
---------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T02"."C1"="C1")
3. おわりに
今回もSQL文のノウハウとして、UPDATEについて説明しましたが、少しは参考になりましたでしょうか。何度か言っているように、MERGE文は便利なSQLですので、是非とも使用してみてください。また機会があれば他のことについても説明したいと思います。これからもよろしくお願いします。それでは、次回まで、ごきげんよう。
