皆さんこんにちは、やっと朝晩が涼しく秋らしい季節になってきましたね。
今回は、SQLの中でも非常に難しくパフォーマンス問題になり易い、再帰的問合せについて説明します。そして、再帰的問合せを簡単にパラレル化する方法の紹介、MERGE文の補足についても説明しますので、参考にしてください。
1. 再帰的問合せとは
まずは、再帰的問合せ(再帰問合せ)について説明しましょう。
再帰問合せは、テーブルに階層構造が含まれているデータに対して、再帰的に問合せを行う処理を指します。これは、自身を何度もアクセスする必要があるため、処理が複雑になってしまいパフォーマンス問題が発生し易くなります。このような処理で有名なのが、部品構成表から必要部品を求める部品展開などです。Oracleデータベースには、このような処理に対するSQLとして、階層問合せと再帰問合せがあります。階層問合せはOracle独自のSQLですが、再帰問合せは11gR2からANSI準拠として提供されたSQLになります。どちらも同じように行うことが可能ですが、基本はパフォーマンス問題がなければ、ANSI準拠の再帰問合せを使用するようにしてください。そこで、どのように異なるかなどを、部品展開を例にして簡単に説明していきます。
(1)部品展開について
これ以降で使用する部品展開の例から簡単に説明します。
部品展開は、以下のような部品構成表(BOM)を使用して行います。BOMには、親部品と子部品によって、以下の図のような親子関係(階層ツリー)になっています。この関係を利用して、ある部品に対する必要な部品を求めるような処理になります(例えば、部品”A01”を構成するすべての部品を求めるなどです)。これは部品によって階層が一定ではないので、単純なSQLでは求めることができません。そのため、パフォーマンスで困っている方も多いのではないでしょうか。階層問合せなどのSQLでは難しいということで、PL/SQLプロシージャーなどの手続き型言語で作成して、パフォーマンス問題などに苦労している方も多いと思います。
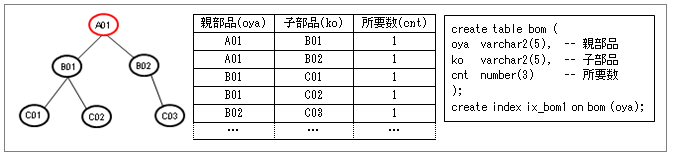
(2)階層問合せ
階層問合せについてから説明します。
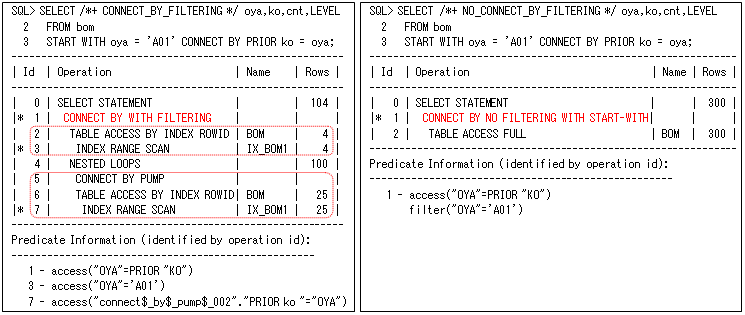
階層問合せは以下のように、START WITH句とCONNECT BY句を使用して行います(赤い部分がルート行を求める指定で、青い部分が親/子の行の関連を指定します)。LEVEL疑似列は、ルート行を1とした階層レベル番号になります(ルート行の”A01”が1で、その子の”B01”、”B02”が2になります)。その他に、繰返されている(先祖にも子にも存在する)行を求めるCONNECT_BY_ISCYCLE疑似列、リーフ行を求めるCONNECT_BY_ISLEAF疑似列などがあります。

階層問合せには、以下のように”CONNECT BY WITH FILTERING”(左側)と”CONNECT BY NO FILTERING WITH START-WITH”(右側)の二つの処理方式があります(ここでは、CONNECT_BY_FILTERINGヒントとNO_CONNECT_BY_FILTERINGヒントで実行しています)。左側は、最初のSTART WITH句と次の”CONNECT BY PUMP”の二つのステップに分かれます。それに対して右側は、すべての行を1回の処理で行うので、全表スキャンになっています。つまり、索引を使用した方が効果的な場合は左側、そうでなければ右側を使用した方が効果的ということになります。
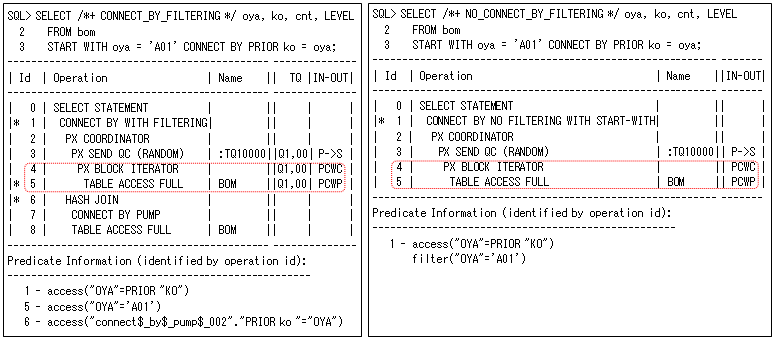
パラレル実行については、どちらのSQLも以下のように完全にパラレルでは動作しません(左側がルート行を求めるテーブル・スキャンだけ、右側がテーブル・スキャンだけなので、それ以降の処理で詰まります)。親子の関連を求める処理は、前の結果(親データ)を基に繰返す必要があるため、まとめて処理できないからです。つまり、最も時間の掛る部分がパラレル実行できないので、大規模データではパフォーマンス問題になり易いということです。
(3)再帰問合せ
次に、再帰問合せについて説明します。
再帰問合せは以下のように、再帰的WITH句を使用して行います。赤い部分の初期化ブランチ(ルート行)と青い部分の再帰的ブランチ(親子行の関連)の問合せをUNION ALLで指定します。再帰的ブランチでは、問合せ名”temp”とテーブル”bom”の結合を繰返します。LEVEL疑似列は使用できないので、列”lvl”として算出しています。SEARCH句で深さ優先検索(DEPTH FIRST)または幅優先検索(BREADTH FIRST)による順序付け、CYCLE句で繰返しをマーク付けするなどの機能があります。以下の例は幅優先検索になります(深さ優先検索は階層問合せの実行結果と同じです)。

SEARCH句は、以下のように実行計画に出力されます(左側が幅優先検索、右側が深さ優先検索です)。

再帰問合せは、二つのブランチを指定しているので、”CONNECT BY WITH FILTERING”と同じように二つのステップに分かれています。パラレル実行も階層問合せと同じように完全にパラレルでは動作しません(以下のように初期化ブランチのテーブル・スキャンだけがパラレル化されています)。

そのため、”CONNECT BY WITH FILTERING”と同じように、高速化するには索引が必要になります。以下は、列”oya”に対する索引”ix_bom1”を作成して、実行したときの実行計画です。

このように基本は索引を使用して行いますが、大規模なデータ件数になると索引の効果が薄れます(効果がなくなる場合もあります)。そのため、どうしてもアクセス件数に比例して処理時間が増加してしまい、シリアル処理の限界になってしまいます。そのような場合には、パラレル化する方法を検討する必要があります。そうはいってもPL/SQLですべて作成するのは大変なので、次からはその作成方法の例を説明します。
2. パラレル化について
ここでは、再帰問合せをパラレル化する方法について説明しましょう。
階層問合せと再帰問合せのどちらでも完全なパラレル実行にはなりません。そこで、第25回で説明したテーブル・ファンクションを使用して、再帰問合せをパラレル化するようにします。これは、ここで行っている再帰問合せ以外にも利用することが可能だと思うので、パラレル化できない場合などに利用することを検討してみてください。
(1)実装方法
まずは、実装方法について簡単に説明します。
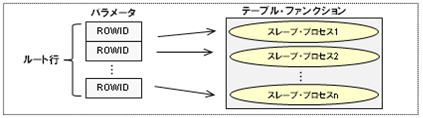
再帰問合せのルート行を求めるSELECT文を、テーブル・ファンクションのパラメータとして使用します。ただし、テーブル・ファンクションをパラレルで実行するには、パラメータとして渡すデータ行が複数行(パラレル度以上)になる必要があります。これは、このデータ行を分割することでパラレル化するからです。そのため、ルート行を複数行になるようにする必要があります(今回の例では、”A01”が親部品のものが二つ存在するので、それを使用してパラレル度2にできます)。そして、テーブル・ファンクション内の再帰問合せでもルート行を求めるので、同じ問合せを2回行わないようにする必要があります。ここでは、以下の図のようにパラメータをROWIDとすることで、テーブル・ファンクション内の再帰問合せで再度行わないようにします(ROWID疑似列を初期化ブランチの条件にすることで、ダイレクトにアクセスすることが可能になります)。
(2)サンプルプログラム
次に、テーブル・ファンクションを使用したサンプルプログラムについて説明します。
以下のサンプルプログラムは、テーブル・ファンクションの中で再帰問合せを実行することで、パラレル実行するようにしています。つまり、SQLはシリアルで動作するが、テーブル・ファンクションのパラレル化機能でパラレル実行するようにします(効果的にデータ分割できない場合は、PARTITION BY句をHASHにしてください)。

このテーブル・ファンクションを実行するには、ルート行のROWIDを求めるSELECT文を、以下のようにカーソルとしてパラメータにします。実行計画を確認すると第25回で説明したように、テーブル・ファンクションがパラレルで動作しているのが分かります。

このようにテーブル・ファンクション内にSELECT文を指定すると、それに対するアクセスの分割は行われないので、全表スキャンを行うとパラレル度の数だけ行い、アクセス数が増えることに注意してください。そのため、アクセス数を増加させないように、索引の作成またはパーティション化などをする必要があります。ここでは、列”oya”に索引を作成することで回避しています。ただし、ROWIDを求めるSELECT文をパラレル索引スキャンするには、複数の索引パーティションにアクセスする必要があるので、ここではパラレル全表スキャンにしています。
3. MERGE文の補足について
最後に、第30回のMERGE文で説明していない内容を少し補足します。
MERGE文は、対象表のすべての列で結合を行うので、レコードサイズが大きい表の更新には注意が必要です(これは、結合時には列を特定できないからです)。ただし、ハッシュ結合は小さいテーブル(通常はソース表です)でハッシュ・テーブルを作成するので、基本は大きなオーバーヘッドにはなりません。ただし、対象表でハッシュ・テーブルを作成する場合やパラレル実行する場合には、問題になることがあるので、それについて少し説明します。
(1)対象表でハッシュ・テーブルの作成
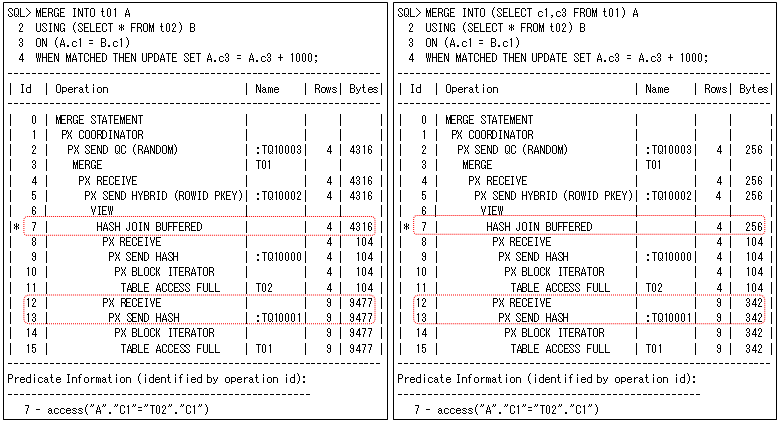
対象表でハッシュ・テーブルを作成すると、そのデータ・サイズのメモリが必要になるため、大きなテーブルだとメモリ不足によるパフォーマンス問題になる場合があります。そのような場合は、できるだけ小さいサイズでハッシュ・テーブルを作成するように、インライン・ビューを使用してください。以下の例は、インライン・ビューを使用したSQL(右側)と使用しないSQL(左側)に対して、対象表”t01”でハッシュ・テーブルを作成しています(最初にアクセスしたテーブルで作成するため、LEADINGヒントを使用しています)。どちらも同じ結果になりますが、実行計画を確認すると、ハッシュ・テーブルを作成するサイズが異なっていることが分かります。ただし、INSERT操作も行う場合には、インライン・ビューの列だけしかインサートできなくなるので、UPDATE操作のときだけに使用することになります。

(2)パラレル実行
パラレル実行を行うと以下の実行計画のように、プロセス間通信されるデータ量(PX SEND HASH、PX RECEIVE)やメモリ上のデータ量(HASH JOIN BUFFERED)に影響します(右側のインライン・ビューを使用した方が少なくなります)。そのため、パラレル処理ではメモリ不足でTEMP領域を使用する場合があるので、そのような場合にも対象表にインライン・ビューを使用した方が効果的です。このメモリ上のデータ量は、第20回で説明したように、パラレル実行では最大二つの処理までしか同時に行うことができないので、途中結果をメモリ上に確保する必要があるからです。
以下の例の実行計画は、データ分割を第20回で説明した”BROADCAST”で行っているので(PQ_DISTRIBUTEヒントも使用しています)、対象表のデータをプロセス間通信や”HASH JOIN BUFFERED”を行っていません。ソース表”t02”のサイズが小さい場合は、”BROADCAST”させることで、影響が少なくなります。基本は、ソース表のサイズが小さいので、このような場合が多いと思いますが、確認するようにしてください。つまり、INSERT操作が存在する場合は、このようになっていると最適ということです。このようなことを知っておくと、確認するときに便利だと思うので説明しました。

4. おわりに
今回もSQL文のノウハウとして、再帰的問合せとMERGE文について説明しましたが、少しは参考になりましたでしょうか。また機会があれば他のことについても説明したいと思います。これからもよろしくお願いします。
それでは、次回まで、ごきげんよう。
