はじめまして。本日からこの連載を始めます津島と申します。
長年に渡りデータベースの構築やパフォーマンスチューニングなどに従事し、最近では若手エンジニアの育成および大規模データベース案件などの支援に従事しております。今までの経験が少しでもお役に立てればと思い、この連載を始めることにいたしました。できるだけ長く続けたいと思いますのでよろしくお願いいたします。
さて、第1回目である今回は「パフォーマンス問題はなぜ起きるのか」と題して説明します。事前に考えておくと回避できることもあると思いますので、参考にしてください。
■1. パフォーマンス問題はなぜ起きるか
最適なパフォーマンスはCPUをできるだけ多く使用して動作することですが、一般的には、何かの待機(例えばI/O待ち)でCPUリソースを使用しきれないでパフォーマンス問題になる場合が多いと思います。これを解析ツール(StatspackやAWRレポートなど)を参照して改善すればパフォーマンスが向上する訳ですが、どこで発生しているかを見つけるのが難しい作業になります。そこで、先ずはどんな時になぜ発生するのかを説明しようと思います。よく耳にするものとしては、「ユーザ数の増加による」、「データ量の増加による」、「長期運用による」、「その他(データベース設計が悪い、SQL文が悪いなど)」の4つがあります。
(1)ユーザ数の増加による
ユーザ数が多くなると競合が発生し易くなります。代表的なのが行ロックの競合です。
それ以外にもメモリー上のラッチ競合、セグメントのブロック競合などがあります。これは同時アクセスできないものや同時アクセスできる上限があるためです。できるだけ最小限にすることです。例えば、ブロック競合などは同じブロックにアクセスしないように、挿入処理はFreelistなどを使用します(今ではASSM:自動セグメント領域管理を使用すれば自動的に行ってくれます)。できるだけ少なくするようにしても競合は発生してしまいます。CPU使用率が少ない場合は、待機イベントを確認する必要があります。あまりにも競合が多いときには、同時ユーザ数が多い場合も考えられます。
(2)データ量の増加による
大規模なデータになるとアクセスするデータの増加でキャッシュヒット率の低下により、物理ディスクI/Oが増えてしまいます。そして、データの増加によるCPU処理時間も増えます。物理I/Oを減らすにはメモリーを増やせば良いのですが、メモリーを増やすのも限界があります。そこで、効率よく使用するメモリーチューニングやアクセスデータを削減するために索引の設計などが重要になる訳です。
また、バッチ処理などの大量のデータにアクセスする必要がある場合には、マルチコアCPUを利用するように並列処理させる方法が有効な場合があります。これは、この後に説明します。
(3)長期運用による
運用しているとデータ更新により構造の劣化や情報が陳腐化していき、アクセス効率が低下します。これには、「表の断片化」、「索引の断片化」、「統計情報が古い」などがあります。表や索引の断片化はI/O効率が低下してI/O待ちが増加します(表の断片化とはエクステントの断片化(表領域に様々なエクステントサイズの表を格納して、削除と挿入を行っていくと割当てできない小さいサイズの領域が点在することです)と行連鎖などです。
索引の断片化とは削除などを頻繁に行ってしまうと索引ブロック内の使用率が低下することです(これは索引ブロックのマージを自動的に行わないので必ず発生してしまいます)。
統計情報が古くなると実行計画がベストではなくなります。このように大量のデータ更新が発生した場合には、再構築や再収集する必要があることを知っておくことが大事です。
(4)その他
その他に、データベース設計が悪い、SQL文が悪いなどがありますが、これは一概に言えません。データベース設計は、非正規化や物理設計などを行って論理I/O数を減少させることです(例えば、結合を頻繁に行う表は同一表にするや頻繁にある表を参照して算出するデータは導出データとするなどです)。ただし、運用が複雑になりますので注意が必要です。SQL文が悪く実行計画が非効率になっている場合は、索引を使用できないSQL文になっている場合などがあります。最近のオプティマイザは優秀なのである程度は効率良い実行計画に変換してくれるのですが、それでも限界がありますので、良いSQL文の書き方のヒントや実行計画の読み方などに関して、ご要望があれば別の回で解説したいと思います。
これ以降はここで挙げたことを解説していこうと思いますが、読者の方から他の具体的な質問があれば、それについても説明する予定です。今回と次回では、よく聞くトラブルである「大規模データのバッチ処理」について説明します。
■2. 大規模データのバッチ処理
1つのコアCPUで処理できるデータ量には限界があるので、データ量が増加すると処理時間も増加して目的の時間に終わらなくなってしまいます。マルチコアCPUが一般的になっていますので、処理を並列化して複数のコアCPUを有効に使用することは有効なケースがあります。
ただし、並列化すると競合が発生する可能性が出てきます。大量にデータ更新する必要があるバッチ処理では、競合が大量に発生する場合があります。競合が多くなるとかえって処理時間が遅くなってしまいますので、競合を発生しないようにしないとバッチ処理では並列処理を行うことができませんので、気にする必要があります。
2.1 並列化処理とは
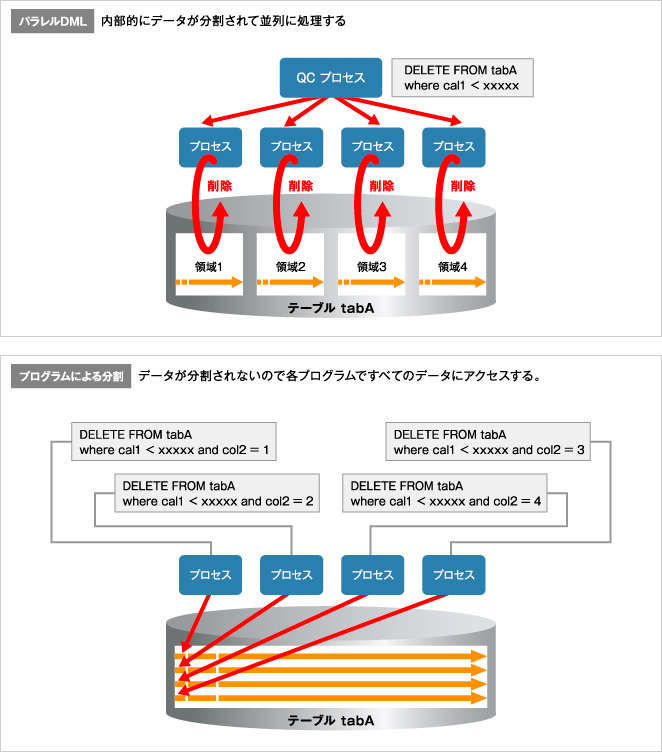
並列化する方法には以下の二つがあります。
- プログラムで分割する(プログラムであるキーを使用して処理する単位を分割して行う)
- OracleのパラレルDMLを使用する(Oracleが自動的にデータを分割して並列処理を行う)
パラレルDMLを使用できるのであれば、これを使用した方がベストです。パラレルDMLでもINSERT(APPEND)はREDOログを生成しないようにできますので、できればINSERT(APPEND)で行ってください(例えば、DELETEは対象外を別表に挿入して元表をDROPするなどです)。
プログラムで分割する場合は、データが競合しないように、表分割やパーティション機能を使用する必要があります。
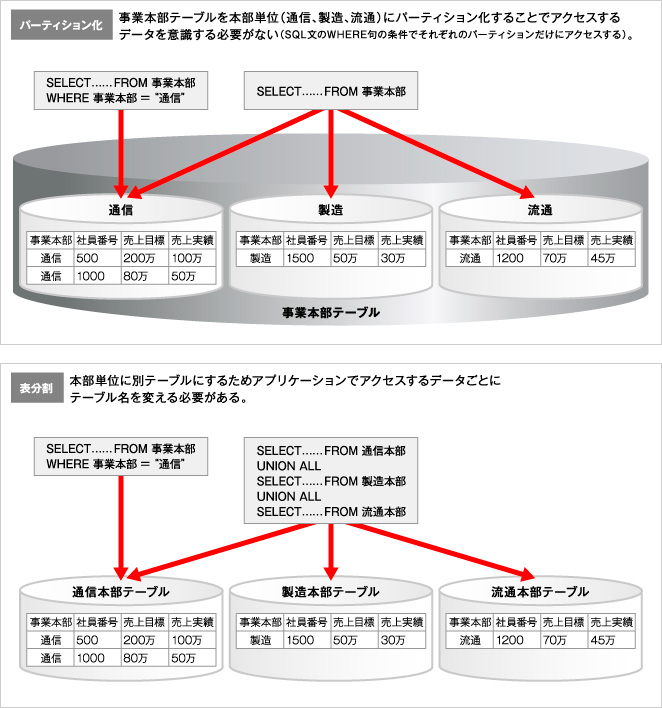
2.2 表分割とパーティション化
表分割でも競合はしなくなりますがアプリケーションでアクセスする表を意識して作成する必要がありますので複雑になると思います。並列度を変更する度にアプリケーションの変更も必要になります。今でも表分割を使用しているシステムもありますが、これはパーティション機能がないときのソリューションです。今はパーティション機能を使用するのがベストです。
■3. おわりに
「パフォーマンス問題はなぜ起きるか」、「大規模バッチ処理」の前半について説明してきました。次回はRAC(Real Application Clusters)の時のバッチ処理について事例を交えながら説明しようと思います。

