皆さん、明けましておめでとうございます。今年も素敵な一年になりますようお祈り申し上げます。
今回は、久しぶりに「パフォーマンスの良いSQL文について」の続きとして、複雑な表結合(ネストした副問合せや外部結合)とそれのSQL自動変換について説明しようと思います。後半に、ROWNUM疑似列やダイレクト・パス・インサートなどの注意点についても説明していますので、参考にしてください。
1. 複雑な表結合
ネストした副問合せや外部結合は、表結合の中でも少し複雑で使用するのが難しいことから、無駄なアクセスをされている方も多いように思います(ネストした副問合せとは、第29回で説明したWHERE句の副問合せのことです)。特に、索引スキャンと全表スキャンでSQLが異なる場合や必要ない処理を知らずに行ってしまう場合などのSQLを良く見かけます。そのため、そのような中から以下のSQLについて説明します。
- ネストした副問合せの自己結合
- 複数のネストした副問合せ
- 必要ない外部結合
このようなSQLは、SQL自動変換(問合せトランスフォーマ)で最適にしますが、オプティマイザ統計の問題や複雑なSQLなどで、正しく動作しないときがあります。また、バージョンによってはSQL自動変換されないSQLもあるので、SQLチューニングを効果的に行うための参考としてまとめています。
(1)ネストした副問合せの自己結合
まずは、ネストした副問合せを自己結合したSQLについて説明します。
自己結合は、第47回で説明しましたが、使用する機会が多いので、使い分けも含めてもう少し説明しようと思います。よく見かけるのが、最大値や平均値などと比較するような場合です。例えば、以下のような部門ごとに平均給料より多い従業員を求めるSQLなどです。

このようなSQLは、部門ごとの平均値を求めてから比較するので、主問合せと同じ表をネストした副問合せでもアクセスする必要があります。そのため、無駄なアクセスをしないように、ネストした副問合せを索引のみでアクセスさせる場合が多いです(以下の実行計画では、索引’IX_TAB1_2’のアクセスがそれになります)。
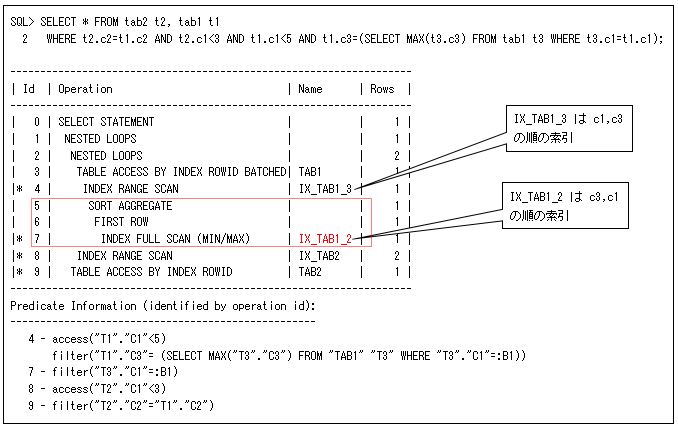
ただし、この実行計画は、アクセスするデータが多くなると非効率になることから、以下のようなGROUP BY句を使用した処理(右側のSQL)にSQL自動変換して最適にします。以下のように第29回で説明したUNNEST(ネスト解除)ヒントで、強制的に行うこともできます(NO_UNNESTヒントでSQL自動変換させないようにもできます)。
|
SQL> SELECT * FROM tab2 t2, tab1 t1 2 WHERE t2.c1=t1.c2 3 AND t1.c3=(SELECT /*+ UNNEST +/ MAX(t3.c3) 4 FROM tab1 t3 WHERE t1.c2=t3.c2); ————————————————- | Id | Operation | Name | Rows | ————————————————- | 0 | SELECT STATEMENT | | 10 | |* 1 | HASH JOIN | | 10 | |* 2 | HASH JOIN | | 10 | | 3 | VIEW | VW_SQ_1 | 10 | | 4 | HASH GROUP BY | | 10 | | 5 | TABLE ACCESS FULL| TAB1 | 100 | | 6 | TABLE ACCESS FULL | TAB1 | 100 | | 7 | TABLE ACCESS FULL | TAB2 | 100 | ————————————————- Predicate Information (identified by operation id): ————————————————– 1 – access(“T2″.”C1″=”T1”.”C2″) 2 – access(“T1″.”C3″=”MAX(T3.C3)” AND “T1”.”C2″= |
SQL> SELECT t2.*, t1.* FROM tab2 t2, tab1 t1, 2 (SELECT c2, MAX(c3) maxc3 3 FROM tab1 GROUP BY c2) t3 4 WHERE t2.c1=t1.c2 and t1.c2=t3.c2 5 AND t1.c3=t3.maxc3; ———————————————- | Id | Operation | Name | Rows | ———————————————- | 0 | SELECT STATEMENT | | 10 | |* 1 | HASH JOIN | | 10 | |* 2 | HASH JOIN | | 10 | | 3 | VIEW | | 10 | | 4 | HASH GROUP BY | | 10 | | 5 | TABLE ACCESS FULL| TAB1 | 100 | | 6 | TABLE ACCESS FULL | TAB1 | 100 | | 7 | TABLE ACCESS FULL | TAB2 | 100 | ———————————————- Predicate Information (identified by operation id): ————————————————— 1 – access(“T2″.”C1″=”T1”.”C2″) 2 – access(“T1″.”C2″=”T3”.”C2″ AND “T1”.”C3″= |
これでも同じ表をアクセスするのは変わらないので、GROUP BY句の重複値が少ないとあまり効果的ではありません(内部ビューでGROUP BYを行ってから結合するので、重複値が多いときに効果が大きいからです)。そこで以下のように、第47回で説明した分析ファンクションを使用して行います(PARTITION BY句を使用すると、行グループ単位に関数を実行できるので、関数の結果と元の値を比較することができ、再度結合する必要がなくなります)。このような自己結合のSQLで、バッチ処理などのパフォーマンス問題に苦労している方は使用を検討してみてください。
2 FROM tab2 t2, tab1 t1 WHERE t2.c1=t1.c2)
3 WHERE maxc3=t1c3;
———————————————
| Id | Operation | Name | Rows |
———————————————
| 0 | SELECT STATEMENT | | 100 |
|* 1 | VIEW | | 100 |
| 2 | WINDOW SORT | | 100 |
|* 3 | HASH JOIN | | 100 |
| 4 | TABLE ACCESS FULL| TAB2 | 100 |
| 5 | TABLE ACCESS FULL| TAB1 | 100 |
———————————————
Predicate Information (identified by operation id):
—————————————————
1 – filter(“MAXC3″=”T1C3”)
3 – access(“T2″.”C1″=”T1”.”C2″)
ただし、この分析ファンクション(WINDOW SORT)にはSQL自動変換されないので、少ないデータのネステッド・ループ結合と、そうでないWINDOW SORTのどちらが効果的かを判断してSQLを作成する必要があります。
(2)複数のネストした副問合せ
次に、複数のネストした副問合せを使用したSQLについて説明します。
複数のネストした副問合せは、複数の結合条件で表を絞り込むときに行いますが、同じ表の副問合せで行っている場合があります。これも同じ表を何度もアクセスするので、索引アクセスが効果的なときだけ使用するようにして、それ以外のときは副問合せを一つにすることを検討してください。以下の左側のように、OR条件で同じ表に異なる条件のネストした副問合せを行っている場合、以下の右側のようなOR条件の副問合せに変換することができます。
|
SQL> SELECT * FROM tab1 2 WHERE EXISTS (SELECT 0 FROM tab2 3 WHERE tab2.c1=tab1.c1) 4 OR EXISTS (SELECT 0 FROM tab2 5 WHERE tab2.c1=tab1.c2); |
SQL> SELECT * FROM tab1 2 WHERE EXISTS (SELECT 0 FROM tab2 3 WHERE tab2.c1=tab1.c1 4 OR tab2.c1=tab1.c2); |
また、以下の左側のように、ANDとNOT条件(NOT EXISTSなど)を行っている場合も、以下の右側のような副問合せに変換することができます(副問合せの同じ行で一致する必要がないので、AND条件でないのが注意点です)。
|
SQL> SELECT * FROM tab1 2 WHERE NOT EXISTS (SELECT 0 FROM tab2 3 WHERE tab2.c1=tab1.c1) 4 AND NOT EXISTS (SELECT 0 FROM tab2 5 WHERE tab2.c1=tab1.c2); |
SQL> SELECT * FROM tab1 2 WHERE NOT EXISTS (SELECT 0 FROM tab2 3 WHERE tab2.c1=tab1.c1 4 OR tab2.c1=tab1.c2); |
もう少し分かりやすく説明すると、最初のSQLが以下の左側の図で、どちらかの副問合せが一致する行(塗りつぶし部分)を求めています。二つ目のSQLが以下の右側の図で、どちらの副問合せも一致しない行(塗りつぶし部分)を求めています。そのため、どちらも同一副問合せでOR条件にすることができます。

ただし、OR条件を使用するので、索引が使用できなくなります。そのため、これも索引を使用する方が効果的かという判断になりますが、Oracle Database 11g(Oracle11g)R2からSQL自動変換するようになりました。このときSQLが複雑などで正しく判断されない場合、以下のようにNO_COALESCE_SQヒントで、一つの副問合せに結合させないようにもできます(COALESCE_SQヒントで強制的に一つにすることもできます)。
2 WHERE NOT EXISTS (SELECT /*+ NO_COALESCE_SQ */ 0 FROM tab2 WHERE tab2.c1=tab1.c1)
3 AND NOT EXISTS (SELECT /*+ NO_COALESCE_SQ */ 0 FROM tab2 WHERE tab2.c1=tab1.c2);
(3)必要ない外部結合
最後に、必要ない外部結合のSQLについて説明します。
外部結合は、核になる表のデータをすべて返す結合になるので、データ行が多いときにはできるだけ使わない方が良い処理になります。しかし、たまに必要ない外部結合を行っているSQLを見かけるので、そのような以下のSQLについてSQL自動変換も含めて説明します。
- 核でない表にフィルター条件があるSQL
- 完全外部結合にフィルター条件があるSQL
- 核でない表にIS NULL条件があるSQL
(a) 核でない表にフィルター条件があるSQL
外部結合の核でない表に、フィルター条件があるSQLを見かけますが、これは内部結合で行うことができます(以下のSQLは、どちらも同じ意味のSQLになります)。外部結合は、核でない表(以下ではtab2)で一致しない行はNULLになるので、表’tab2’に条件を指定するとNULLは対象外になり、内部結合と同じ意味になります。
|
SQL> SELECT * FROM tab1 LEFT OUTER JOIN 2 tab2 ON tab1.c2 = tab2.c2 3 WHERE tab2.c1 < 100; |
SQL> SELECT * FROM tab1 INNER JOIN 2 tab2 ON tab1.c2 = tab2.c2; 3 WHERE tab2.c1 < 100; |
そのため、Oracle11gからは、以下のように内部結合にSQL自動変換を行います(OUTER_JOIN_TO_INNERヒントで強制的に行うこともできます)。
SQL> SELECT /*+ OUTER_JOIN_TO_INNER(tab2) */ * 2 FROM tab1 LEFT OUTER JOIN tab2 ON tab1.c2 = tab2.c2 WHERE tab2.c1 < 100; ----------------------------------- | Id | Operation | Name | ----------------------------------- | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN | | |* 2 | TABLE ACCESS FULL| TAB2 | | 3 | TABLE ACCESS FULL| TAB1 |
(b) 完全外部結合にフィルター条件があるSQL
完全外部結合も同じように、フィルター条件があると完全でない外部結合で行うことができます(以下のSQLは、どちらも同じ意味になります)。完全外部結合は、どちらの表のデータもすべて返す結合になるので、更に効率が悪い処理となります。
|
SQL> SELECT * FROM tab1 FULL OUTER JOIN 2 tab2 ON tab1.c2 = tab2.c2 3 WHERE tab2.c1 < 100; |
SQL> SELECT * FROM tab1 RIGHT OUTER JOIN 2 tab2 ON tab1.c2 = tab2.c2; 3 WHERE tab2.c1 < 100; |
これもOracle11gR2からは、以下のようにSQL自動変換を行います(FULL_OUTER_JOIN_TO_OUTERヒントで強制的に行うこともできます)。
SQL> SELECT /*+ FULL_OUTER_JOIN_TO_OUTER(tab2) */ * 2 FROM tab1 FULL OUTER JOIN tab2 ON tab1.c2 = tab2.c2 WHERE tab2.c1 < 100; ----------------------------------- | Id | Operation | Name | ----------------------------------- | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN OUTER | | |* 2 | TABLE ACCESS FULL| TAB2 | | 3 | TABLE ACCESS FULL| TAB1 |
(c)核でない表にIS NULL条件があるSQL
外部結合の核でない表の列に、IS NULL条件を指定しているSQLも見かけますが、これは第29回で説明したアンチ結合で行うことができます(以下のSQLは、どちらも同じ意味になります)。核でない表にIS NULL条件を指定すると、一致しない行だけが対象になり、アンチ結合と同じ意味になります。
|
SQL> SELECT tab1.* FROM tab1 LEFT OUTER JOIN 2 tab2 ON tab1.c1 = tab2.c1 3 WHERE tab2.c1 IS NULL; ———————————— | Id | Operation | Name | ———————————— | 0 | SELECT STATEMENT | | |* 1 | FILTER | | |* 2 | HASH JOIN OUTER | | | 3 | TABLE ACCESS FULL| TAB1 | | 4 | TABLE ACCESS FULL| TAB2 | ———————————— Predicate Information (identified by operation id): ————————————————— 1 – filter(“TAB2”.”C1″ IS NULL) 2 – access(“TAB1″.”C1″=”TAB2”.”C1″(+)) |
SQL> SELECT tab1.* FROM tab1 2 WHERE NOT EXISTS 3 (SELECT 0 FROM tab2 WHERE tab1.c1 = tab2.c1); ———————————– | Id | Operation | Name | ———————————– | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN ANTI | | | 2 | TABLE ACCESS FULL| TAB1 | | 3 | TABLE ACCESS FULL| TAB2 | ———————————– Predicate Information (identified by operation id): ————————————————— 1 – access(“TAB1″.”C1″=”TAB2”.”C1″) |
これもOracle11gR2からは、以下の左側のようにアンチ結合にSQL自動変換を行います(OUTER_JOIN_TO_ANTIヒントで強制的に行うこともできます)。また、以下の右側のようにON句に条件があると、意味が異なるので注意してください(結合する前にNULLチェックをすることになります)。
|
SQL> SELECT /*+ OUTER_JOIN_TO_ANTI(tab2) */ tab1.* 2 FROM tab1 LEFT OUTER JOIN tab2 3 ON tab1.c1 = tab2.c1 4 WHERE tab2.c1 IS NULL; ———————————– | Id | Operation | Name | ———————————– | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN ANTI | | | 2 | TABLE ACCESS FULL| TAB1 | | 3 | TABLE ACCESS FULL| TAB2 | ———————————– Predicate Information (identified by operation id): ————————————————— |
SQL> SELECT tab1.* 2 FROM tab1 LEFT OUTER JOIN tab2 3 ON (tab1.c1 = tab2.c1 AND tab2.c1 IS NULL); ———————————– | Id | Operation | Name | ———————————– | 0 | SELECT STATEMENT | | |* 1 | HASH JOIN OUTER | | | 2 | TABLE ACCESS FULL| TAB1 | |* 3 | TABLE ACCESS FULL| TAB2 | ———————————– Predicate Information (identified by operation id): ————————————————— 1 – access(“TAB1″.”C1″=”TAB2”.”C1″) 3 – filter(“TAB2”.”C1″(+) IS NULL) |
2. その他の注意点
ここからは、その他で知っておくと便利そうな、以下の注意点について説明します。
- ROWNUM疑似列とROW_NUMBERファンクション
- ダイレクト・パス・インサート
- 空文字
(1)ROWNUM擬似列とROW_NUMBERファンクション
第24回や第59回で説明したROWNUM疑似列とROW_NUMBERファンクションの注意点について説明します。
上位N件を取得するためにROWNUM疑似列を使用すると、Oracle Database 10gR2からはFIRST_ROWS()ヒントを指定した動作を行います(以下の実行計画のように、c1<50の条件によって49行のアクセスが必要なのに、RowsはROWNUM<=10の条件が反映された値になります)。つまり、より索引スキャンが選択されやすくなります。
SQL> SELECT * FROM (SELECT * FROM tab1 WHERE c1 < 50 ORDER BY c1) WHERE ROWNUM <= 10; --------------------------------------------------------- | Id | Operation | Name | Rows | --------------------------------------------------------- | 0 | SELECT STATEMENT | | 10 | |* 1 | COUNT STOPKEY | | | | 2 | VIEW | | 11 | | 3 | TABLE ACCESS BY INDEX ROWID| TAB1 | 11 | |* 4 | INDEX RANGE SCAN | IX_TAB1 | | --------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(ROWNUM<=10)
今度はROW_NUMBERファンクションを使用したときを確認してみます。以下ではROW_NUMBERファンクションの代わりにOracle Database 12c(Oracle12c)からのFETCH FIRST句を使用しています(第37回で説明したように、ROW_NUMBERファンクションと同じ動作になります)。実行計画のRowsは、c1<50の条件である49行になっていることから、FIRST_ROWS(10)ヒントは指定されていないことが分かります。つまり、より全表スキャンが選択されやすくなります。
SQL> SELECT * FROM tab1 WHERE c1 < 50 ORDER BY c1 FETCH FIRST 10 ROWS ONLY;
---------------------------------------------------------
| Id | Operation | Name | Rows |
---------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 |
|* 1 | VIEW | | 10 |
|* 2 | WINDOW NOSORT STOPKEY | | 49 |
| 3 | TABLE ACCESS BY INDEX ROWID| TAB1 | 49 |
|* 4 | INDEX RANGE SCAN | IX_TAB1 | 49 |
---------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("from$_subquery$_002"."rowlimit_$$_rownumber"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "TAB1"."C1")<=10)
ROWNUM疑似列は、索引を使用するときは良いですが、そうでなければ第59回で説明したように、ROW_NUMBERファンクションの方が効果的です。特に、Exadataでは、索引スキャンしないときに、以下のようなフル・スキャン(TABLE ACCESS STORAGE FULL FIRST ROWS)になり、第26回で説明したSmart Scan(スマート・スキャン)が効果的に動作しないので注意してください。
SQL> SELECT * FROM ( … ) WHERE ROWNUM <= 10 ; -------------------------------------------------------------------------- | Id | Operation | Name | E-Rows | A-Rows | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | 10 | |* 1 | COUNT STOPKEY | | | 10 | | 2 | VIEW | | 1000K| 10 | |* 3 | SORT ORDER BY STOPKEY | | 1000K| 10 | |* 4 | TABLE ACCESS STORAGE FULL FIRST ROWS| TAB1 | 1000K| 1000K|
索引スキャンしたいときには、以下のようにFISRT_ROWS(10)ヒントを使用すると、ROWNUM疑似列のときと同じようにできるので、ROW_NUMBERファンクションを使用して、索引スキャンのときにはFISRT_ROWS()ヒントを使用した方が、SQLの変更が少なく使いやすいです。
SQL> SELECT /*+ FIRST_ROWS(10) */ * FROM tab1 WHERE c1 < 50 ORDER BY c1 FETCH FIRST 10 ROWS ONLY;
---------------------------------------------------------
| Id | Operation | Name | Rows |
---------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 |
|* 1 | VIEW | | 10 |
|* 2 | WINDOW NOSORT STOPKEY | | 11 |
| 3 | TABLE ACCESS BY INDEX ROWID| TAB1 | 11 |
|* 4 | INDEX RANGE SCAN | IX_TAB1 | |
---------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("from$_subquery$_002"."rowlimit_$$_rownumber"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "TAB1"."C1")<=10)
(2)ダイレクト・パス・インサート
次に、索引が存在する表に対するダイレクト・パス・インサートの注意点について説明します。
第10回のパーティション表に対するダイレクト・パス・ロード(インサート)では、ロード後に索引作成が行われると説明しましたが、正確には別セグメントに作成された索引をロード後にマージします。また、パラレル・ダイレクト・パス・インサートでは、パラレルで索引メンテナンスが行われるので、Oracle Real Application Clusters(RAC)環境ではGC(Global Cache)系の待機が発生する場合があります。
そのため、ロード終了後に作成するように、索引の削除またはUNUSABLE(使用禁止)にして行うようにしてください。このとき複数の索引が存在するときには、同時作成することもできるので、さらに効果的に行うことができます(索引作成は、ソート処理を行うので、パラレル度を増やしても効果的に処理できないときがあり、複数の索引を同時に作成した方が短時間で行うことができる場合が多いです)。
ただし、TRUNCATE TABLEしてからダイレクト・パス・インサートする場合には注意が必要です。索引がUNUSABLEのときに、TRUNCATE TABLEを行うと、以下のように索引はUSABLE(使用可能)になります(USER_INDEXESビューではSATUSがVALIDになります)。そのため、TRUNCATE TABLE後にUNUSABLEにする必要があります。
SQL> SELECT index_name, index_type, status, partitioned FROM user_indexes WHERE table_name='TAB1'; INDEX_NAME INDEX_TYPE STATUS PAR ---------- ---------- -------- --- IX_TAB1 NORMAL UNUSABLE NO SQL> TRUNCATE TABLE tab1; SQL> SELECT index_name, index_type, status, partitioned FROM user_indexes WHERE table_name='TAB1'; INDEX_NAME INDEX_TYPE STATUS PAR ---------- ---------- -------- --- IX_TAB1 NORMAL VALID NO
(3)空文字
最後に、Oracleデータベースの空文字について説明します。
Oracleデータベースは、空文字はNULLとして扱うので、空文字をサポートする他のデータベースから移行するときや他のデータベースに慣れている方には、SQLが正しく動作しない場合があります(私も移行するときに悩んだことがあります)。
そのようなときにOracleデータベースでは、’IS NULL’または’IS NOT NULL’を使用する必要がありますが、SQLを変更するのは大変になることから、INSERTするときに別の値に変換して、SQLの変更をしないようにします。
そのため、Oracle12cからは、INSERTなどでNULLを他の値に変更できるように、’DEFAULT ON NULL’の指定が追加されました。以下は、列’c3’がDEFAULT、列’c4’が’DEFAULT ON NULL’を指定した場合です。列’c4’は、列’c3’とは異なり、どのようなとき(空文字やNULLを指定したとき)でも変換されているのが分かります(DEFAULTは、INSERTで列を指定しないときだけ使用されます)。これも覚えておくと便利と思い載せておきました。
2 c3 VARCHAR2(10) DEFAULT ‘A’,
3 c4 VARCHAR2(10) DEFAUL ON NULL ‘B’);
SQL> INSERT INTO abc(c1) VALUES (1);
SQL> INSERT INTO abc VALUES (2,NULL,NULL,NULL);
SQL> INSERT INTO abc VALUES (3,”,”,”);
SQL> SET NULL ‘NULL’
SQL> SELECT * FROM abc;
C1 C2 C3 C4
—— —— —— ——
1 NULL A B
2 NULL NULL B
3 NULL NULL B
3. おわりに
今回は複雑な表結合とその他の注意点について説明しましたが、少しは参考になりましたでしょうか。今年も頑張りますのでよろしくお願いします。
それでは、次回まで、ごきげんよう。
