しばちょう先生の試して納得!DBAへの道 indexページ▶▶
みなさん、こんにちは。”しばちょう”こと柴田長(しばた つかさ)です。
かなり間が空いてしまいましたが前回に引き続き、[Oracle Code Tokyo 2017]においてLive Demoでチャレンジさせて頂いた、「SQLパフォーマンスの高速化の限界を目指せ!」の内容をお届けしたいと思います。
二回目の今回は、パラレルクエリで複数CPUを一つのSELECT文でフル活用したり、圧縮技術を適用したりすることで、問題となっているSELECT文を高速化させる部分まで解説できればと考えておりましたが、ごめんなさい。原稿量と執筆時間が原因で、パラレルクエリまでになってしまいました。圧縮技術は次回でお願いします・・・
以下の演習をOracle Database 12c Release 12.2.0.1 Enterprise Editionのデータベースで試してみてください。Oracle Database 12c Release 12.1.0.2環境でも動作させることは可能ですが、前回もお勧めさせて頂きましたが、是非、Oracle Database Cloud Service(以降、DBCS)のトライアルでのご活用もお勧めします。その際には、Database In-Memory機能を使用可能なExtreme Performance Packageをご利用ください。DBCS上にデータベースを作成する手順は、「第50回 [Oracle Database 12c Release 2] Oracle Database Cloud Service上にデータベースを作成」を参考にしてみてください。ちなみに、Oracle Code Tokyo 2017の公開資料は、「こちら」からダウンロードすることが可能ですので、そちらも参考にしてみてくださいね。
1. 前回までの復習、チューニング方法とその効果をおさらいしましょう
前回は演習用のSales Historyスキーマを作成して頂き、それに対して性能問題が発生している2つの傾向の異なるクエリを実行した際の処理状況を分析して頂きました。その分析で非常に役立ったのが毎度お馴染みの「リアルタイムSQL監視」でしたね。リアルタイムSQL監視レポートを確認する方法として一番簡単なのがOracle Enterprise Managerの利用ですが、その他の方法としてはDBMS_SQLTUNEパッケージのREPORT_SQL_MONITORファンクションを使用したActiveレポート取得ですね。
SQLの実行時間の主な内訳としてはCPU処理を必要とするCPU時間とHDD等の記憶デバイスとデータをI/Oする処理を必要とするI/O時間の2つですが、CPU時間の割合が大きいSQLをCPUバウンドなSQL、I/O時間の割合が大きいSQLをI/OバウントなSQLとそれぞれ呼びます。今回は、そのような傾向が異なる2つのクエリが同じチューニングを施すことで、どこまで高速化できるのかにチャレンジしていきます。(前回から引き続き使用する2つのクエリは前回の演習7と8で公開しています)
前回はチューニング前(Normal)の計測と、パーティション化によるチューニング効果を評価しましたが、(前回から間が空き過ぎて)覚えていますかね?その結果が次のスライドの通りです。
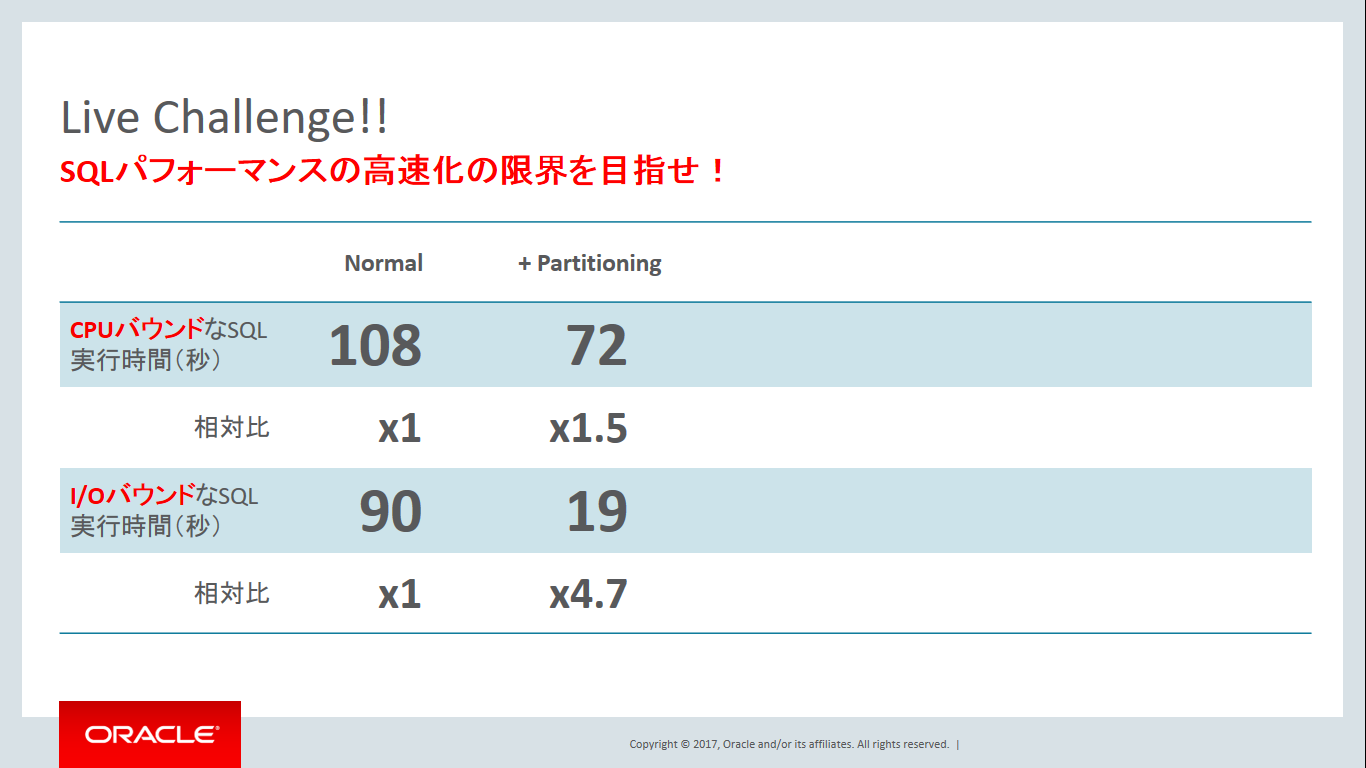
前回の記事に掲載しているリアルタイムSQL監視レポートを復習していただきたいのですが、パーティション化をすることで両クエリともにディスクからのデータの読み込み量が1/5まで削減できていましたね。「データの読み込み量が1/5まで削減」= 「データを読み込んでいる時間も1/5まで削減」したことを意味しますから、 ディスクI/O時間の割合が大きいI/OバウンドなSQLは4.7倍まで高速化したことはとても納得感があるかと思います。しかし、CPU処理時間の割合が大きいCPUバウンドなSQLは1.5倍しか高速化していませんね。これは何故でしょうか?
答えは「CPUバウンドなSQL」だからです。って答えになっていませんね。ごめんなさい。でも本当なのです。繰り返しになりますが、CPUバウンドなSQLはCPU処理を必要としている時間の内訳が大きいので、割合の小さなI/O時間が1/5に削減されたとしてもクエリ全体の時間で見た場合の削減率は小さいのですね。例えば、チューニング前にCPU時間とI/O時間の比率が「75% : 25%」=合計100%だとしましょう。パーティション化でI/O時間25%が1/5になることで「75% : 5%」=合計80%ですから、100%が80%にしかなりません。
ちなみに、パーティション化は「ディスクから不要なデータを読まなくて済む」ようになるので読み込むデータ量を削減できることはご理解いただけたかと思いますが、逆を言えば、パーティション化していないときは「ディスクから不要なデータも読んでいた」のですよね?つまり、読み込んだ後に「CPU処理で不要なデータだと判断する必要があった」ということも意味しています。そうなんです!!パーティション化することで「CPU処理で不要なデータだと判断する必要がなくなる」 = 「データをフィルタリングするCPU処理時間が削減される」効果も実はあります。よって、上述したCPUバウンドなSQLは「100%が80%しかならない」例では100/80=1.25倍しか高速化しませんが、実機ではI/O時間だけではなくフィルタリングのCPU時間も削減されているので1.5倍高速化していると推測できますね。
2. CPUバウンドなSQLのボトルネックを特定してください。
パーティション化した後、CPUバウンドなSQLを実行した際に取得したリアルタイムSQL監視レポートを使います。
下段「Details」ブロック内の「Activity」タブを表示させてみると以下のようなグラフが表示されます。これは何を意味しているのでしょうか?
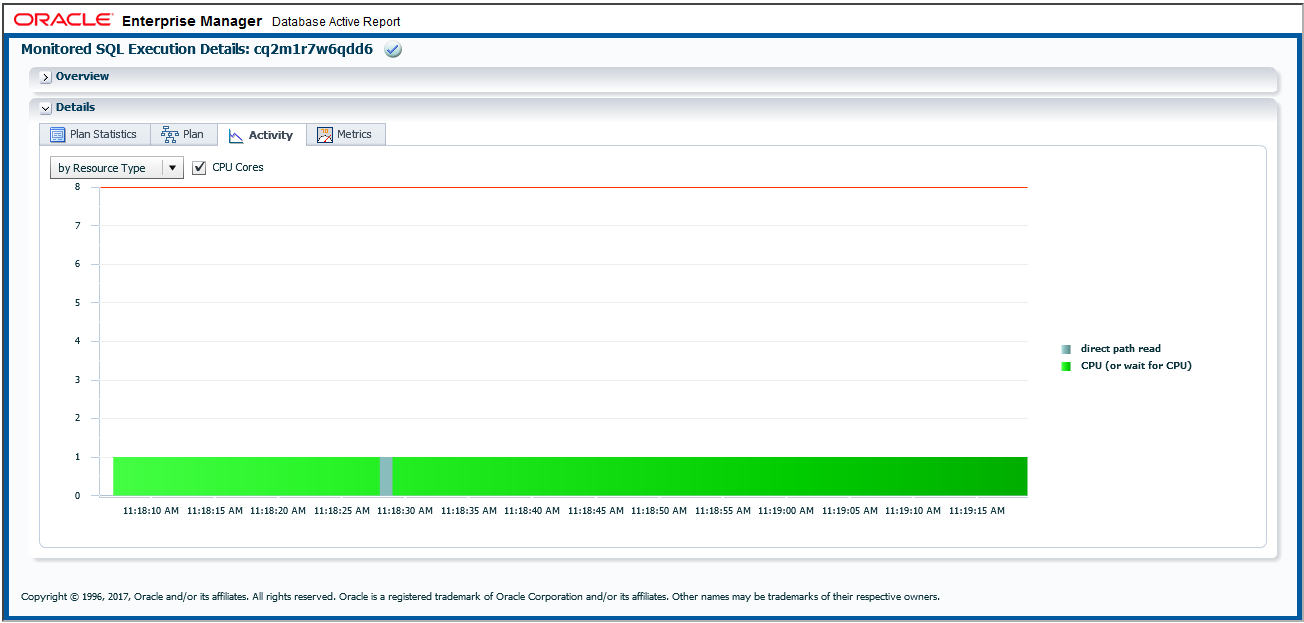
まず、横軸には時刻が表示されているので時系列であることは一目瞭然ですね。次に縦軸はちょいと感覚的には難しいですがCPUコア数を示しています。また、「8」のラインが赤線になっていますが、これは私がLive demoで利用したデータベースサーバーはCPUコア数を8つ搭載していた為です。ということは・・・8個のCPUコアを搭載しているにも関わらず、このCPUバウンドなSQLの実行を開始したタイミングから完了するまでの間、最大で1CPUコアしか使用できていないことがグラフから見て取れます。
これは次のスライドのイメージ図の通り、通常のシリアル実行の場合はSQLを処理するサーバープロセスが一人で頑張ることになるので、一つのCPUコアしか活用できない為です。
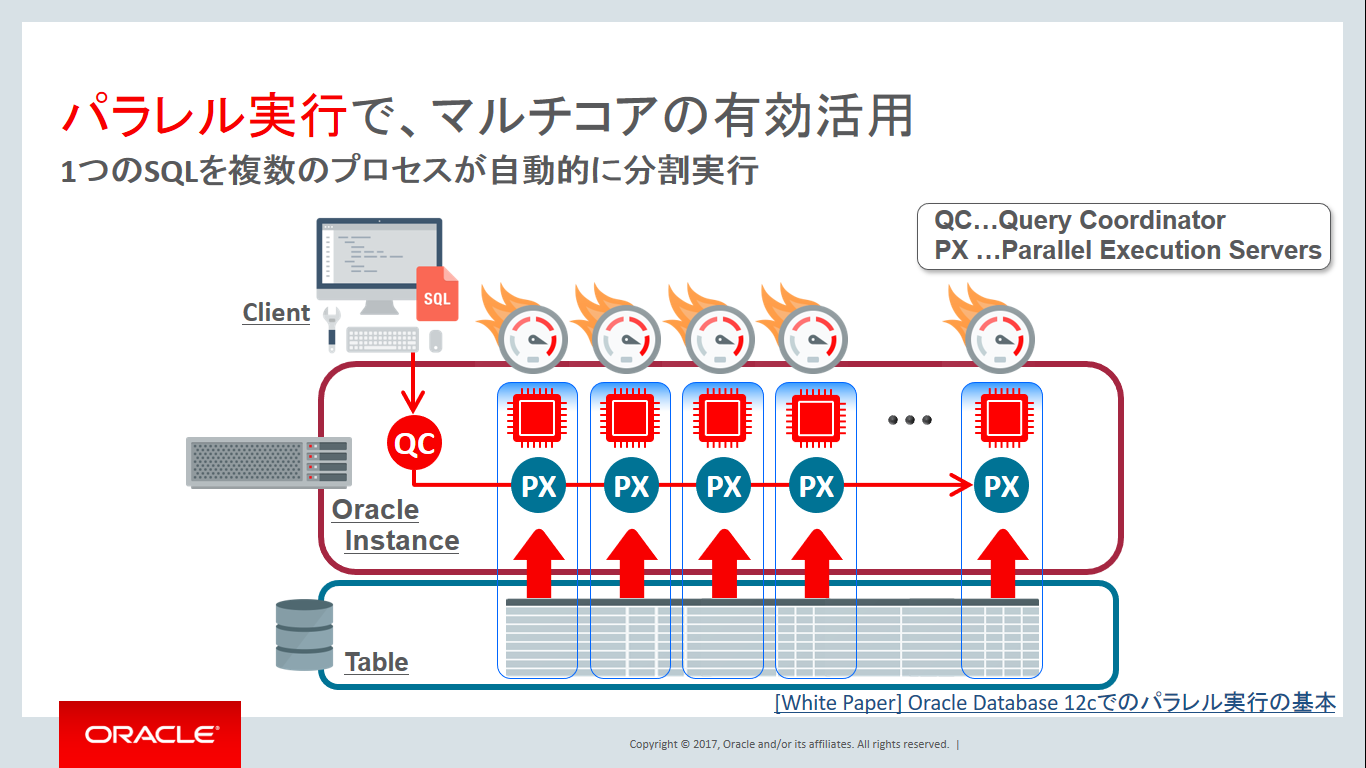
より多くのCPUコア数を搭載したサーバーの方が高性能として皆の共通認識だと思いますが、1つのSQL単体の性能から見た場合には複数コアを搭載しても無意味なように感じてしまうかもしれませんね。でも安心してください。もし、Oracle Database Enterprise Editionをご利用されている場合は、1つのSQLを複数のプロセスで並列処理可能なパラレル実行を使用することで複数CPUコアを活用し高速化を実現させることが可能です。ということで、次のチューニング手法としては1CPUコアの壁を超えるパラレル処理を試してみましょう!
3. 次のCPUバウンドなクエリ(SELECT文)を並列度16でパラレル実行し、その実行時間、傾向やボトルネックをリアルタイムSQL監視レポートで確認してください。
$ view query_CPU.sql
WITH /*+MONITOR */
DUMMY_SALES AS
( select * from (select 0 from CHANNELS ) D1, sales D2),
SACOMMON1340 AS
( select sum(T220.AMOUNT_SOLD) as c1, sum(T220.QUANTITY_SOLD) as c2,
T147.CHANNEL_CLASS as c3, T228.CALENDAR_QUARTER_DESC as c4,
T228.CALENDAR_YEAR as c5, T185.PROD_CATEGORY as c6
from CHANNELS T147, PRODUCTS T185,
DUMMY_SALES T220, TIMES T228
where ( T220.TIME_ID < to_date('2014/01/01','YYYY/MM/DD')
and T228.TIME_ID = T220.TIME_ID
and T147.CHANNEL_ID = T220.CHANNEL_ID
and T185.PROD_ID = T220.PROD_ID)
group by T147.CHANNEL_CLASS,
T185.PROD_CATEGORY,
T228.CALENDAR_QUARTER_DESC,
T228.CALENDAR_YEAR),
SAWITH0 AS
( select distinct 0 as c1, D1.c3 as c2, D1.c4 as c3, D1.c5 as c4,
D1.c6 as c5, D1.c2 as c6, D1.c1 as c7, cast(NULL as DOUBLE PRECISION ) as c8
from SACOMMON1340 D1),
SAWITH1 AS
( select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4,
D1.c5 as c5, D1.c6 as c6, D1.c7 as c7, D1.c8 as c8, sum(D1.c7) as c9
from SAWITH0 D1
group by D1.c1, D1.c2, D1.c3, D1.c4, D1.c5, D1.c6, D1.c7, D1.c8),
SAWITH2 AS
( select distinct 1 as c1, D1.c3 as c2, D1.c4 as c3, D1.c5 as c4,
D1.c6 as c5, D1.c2 as c6, D1.c1 as c7
from SACOMMON1340 D1),
SAWITH3 AS
( select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4,
D1.c5 as c5, D1.c6 as c6, D1.c7 as c7, sum(D1.c6) as c8, sum(D1.c7) as c9
from SAWITH2 D1
group by D1.c1, D1.c2, D1.c3, D1.c4, D1.c5, D1.c6, D1.c7),
SAWITH4 AS
(( select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5,
D1.c6 as c6, D1.c7 as c7, D1.c8 as c8,
sum(D1.c9) over (partition by D1.c3, D1.c4, D1.c5) as c9
from SAWITH1 D1
union all
select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5,
D1.c6 as c6, D1.c7 as c7,
sum(D1.c8) over (partition by D1.c3, D1.c4, D1.c5) as c8,
sum(D1.c9) over (partition by D1.c3, D1.c4, D1.c5) as c9
from SAWITH3 D1 ))
select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5,
D1.c6 as c6, D1.c7 as c7, D1.c8 as c8, D1.c9 as c9
from SAWITH4 D1 order by c1, c3, c5, c4;
$ sqlplus sh/oracle12345@localhost:1521/poco SQL> set time on timing on pages 0 lines 200 -- セッション単位でのパラレルクエリ有効化(強制的にパラレル度16) alter session force parallel query parallel 16 ; -- CPUバウンドなSQLの実行 @query_CPU.sql ...(省略)... 経過: 00:00:19.59
パラレルクエリを有効化する簡単な方法は、「alter session force parallel query parallel <並列度> ;」を実行したいセッションで実行するだけです。この有効化したセッションでは無効化「alter session disable parallel query;」もしくはセッションの切断(例: SQL Plusの終了)を行うまでの間に実行するクエリ(SELECT文)は、強制的に指定した並列度でパラレル実行されます。ちなみ、DML文に対してパラレル実行を有効化したい場合は「alter session force parallel dml parallel <並列度> ;」、DDL文に対しては「alter session force parallel ddl parallel <並列度> ;」があります。これらの「force」部分を「enable」と書くこともできますが、これには「パラレル実行を有効にできる状況の際に有効化する」というニュアンス含まれ強制ではなくなります。パラレル化を判断する要素が増えますので十分な理解が必要となってきますので、是非ともマニュアル「VLDBおよびパーティショニング・ガイド」の「パラレル実行の使用」を参考にしてみてください。また、初期化パラメータ「PALALLEL_DEGREE_POLICY」をデフォルト値(MANUAL)から変更することで、インスタンス単位で自動パラレル度設定を有効化することが可能です。こちらも「リファレンス・マニュアル」をご確認ください。
ということで前置きが長くなりましたが、SQL Plusの実行結果を見る限り、見事に高速化(72秒から約20秒)したことが確認できていますね。リアルタイムSQL監視レポートでも確認してみましょう。
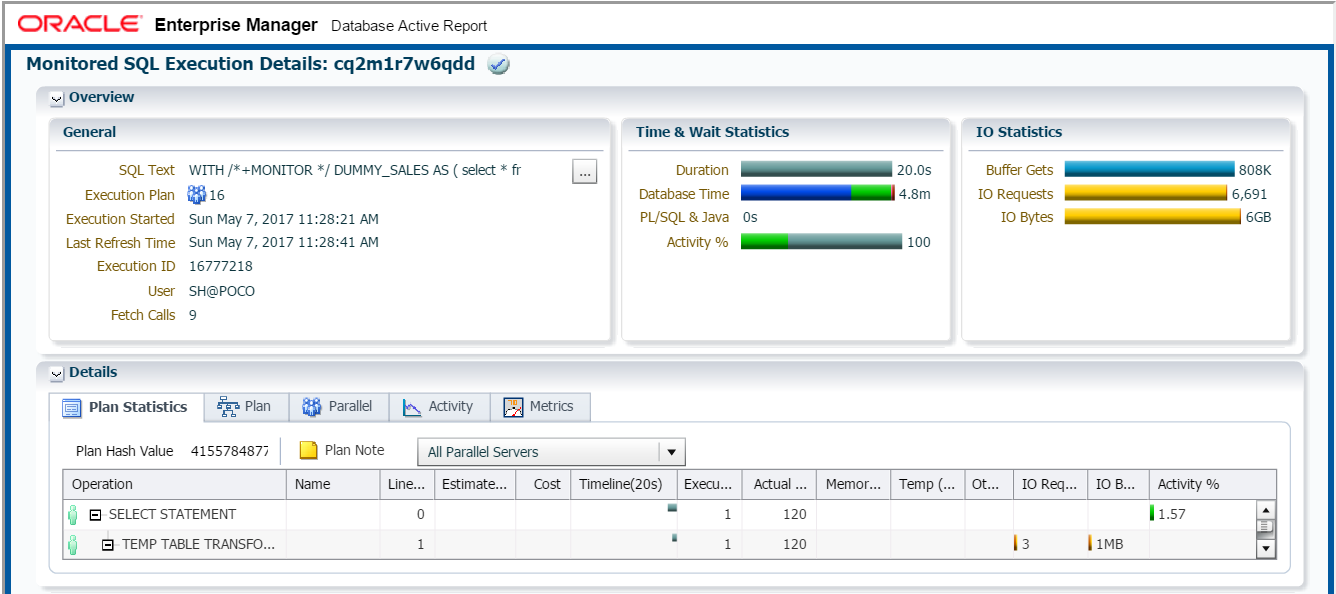
如何でしょうか?パラレル実行が有効化されているのかは、「Overview」ブロック内の一番左側の「General」ブロック内の2行目「Execution Plan」に複数人の図とともに「16」という数字が表示されていますので、ここから並列度16でのパラレル実行が行われたことが確認できます。SQLの実行時間は真ん中の「Time & Wait Statistics」の「Duration」で「20.0s」だったと記録されていますね。
ちょっと難しい部分かもしれませんが、あえて触れさせていただくと、「Duration」の下の「Database Time」の値が「4.8m」つまり、4.8分と表示されている点です。約20秒間しかSQL文を実行していなかったのに4.8分間とは疑問に思った方はシリアル実行時のリアルタイムSQL監視レポートとも見比べてみてください。シリアル実行時はサーバープロセスが一人ですから、Durationの値とDatabase Timeの値は同じになりますが、パラレル実行は複数のプロセスがSQL実行中に同時に動くわけですから、それら全部のプロセスの累積時間になっているわけです。
ということは、複数のCPUコアを同時に使えたことも意味していますから、下段「Details」ブロック内の「Activity」タブを開いてみましょう。おお!!如何でしょうか?シリアル実行時には常時1CPUコアしか活用できない為に長時間化していましたが、パラレル実行のおかげで複数のCPUコアが使われていることが確認できますね。8CPUコアしかないのに、12個や20個のCPUコアを使っているように見えますが、まあ同時に動いたプロセス数ぐらいに思ってもらえればと思います。
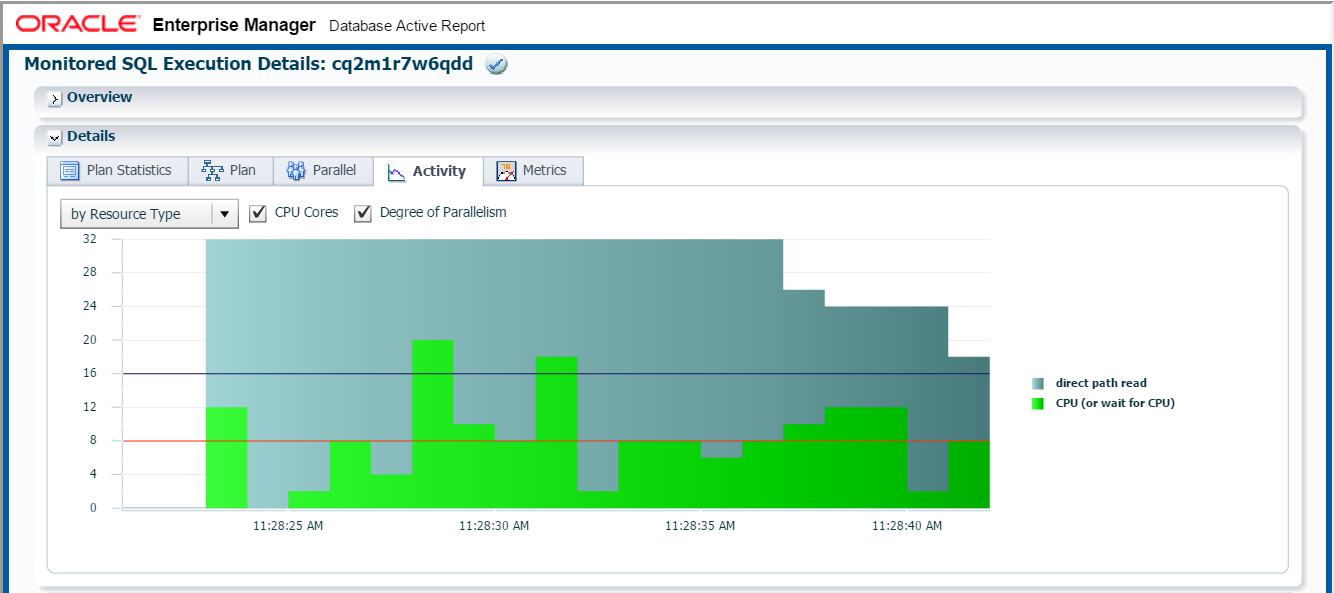
ここで皆様には思い出していただきたい。小学校の算数で学習した四角形の面積の公式「四角形の面積 = 縦 × 横」を。「面積が総CPU処理量」だとして、「縦がCPUコア数」で「横が処理時間」です。同じSQL(四角形)のCPU処理量(面積)を求めるのに、CPUコア数(縦)が長くなったので処理時間(横)が短くなっているのですよ。コンピュータの処理は算数なんだと私は思っています。
ちなみに、上のグラフにはCPU以外にも「direct path read」が多く発生しているようですね。これってなんでしたっけ?ディスクからバッファ・キャッシュを経由せずに大量データを読み込む際に発生する待機イベントでしたね。つまり、CPUバウンドなSQLをパーティション化、パラレル実行化とチューニングしてきたら、いつの間にかI/OバウンドなSQLに傾向が変化したってことも気づいて頂きたいです。もちろんSQL文は一切書き換えていませんよ。面白いですねーパフォーマンスチューニングって!
4. I/Oバウンドなクエリ(SELECT文)を並列度16でパラレル実行し、その実行時間、傾向やボトルネックをリアルタイムSQL監視レポートで確認してください。
$ view query_IO.sql
WITH /*+MONITOR */
SACOMMON1340 AS
( select sum(T220.AMOUNT_SOLD) as c1, sum(T220.QUANTITY_SOLD) as c2,
T147.CHANNEL_CLASS as c3, T228.CALENDAR_QUARTER_DESC as c4,
T228.CALENDAR_YEAR as c5, T185.PROD_CATEGORY as c6
from CHANNELS T147, PRODUCTS T185,
SALES T220, TIMES T228
where ( T220.TIME_ID < to_date('2014/01/01','YYYY/MM/DD')
and T228.TIME_ID = T220.TIME_ID
and T147.CHANNEL_ID = T220.CHANNEL_ID
and T185.PROD_ID = T220.PROD_ID)
group by T147.CHANNEL_CLASS,
T185.PROD_CATEGORY,
T228.CALENDAR_QUARTER_DESC,
T228.CALENDAR_YEAR),
SAWITH0 AS
( select distinct 0 as c1, D1.c3 as c2, D1.c4 as c3, D1.c5 as c4,
D1.c6 as c5, D1.c2 as c6, D1.c1 as c7, cast(NULL as DOUBLE PRECISION ) as c8
from SACOMMON1340 D1),
SAWITH1 AS
( select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4,
D1.c5 as c5, D1.c6 as c6, D1.c7 as c7, D1.c8 as c8, sum(D1.c7) as c9
from SAWITH0 D1
group by D1.c1, D1.c2, D1.c3, D1.c4, D1.c5, D1.c6, D1.c7, D1.c8),
SAWITH2 AS
( select distinct 1 as c1, D1.c3 as c2, D1.c4 as c3, D1.c5 as c4,
D1.c6 as c5, D1.c2 as c6, D1.c1 as c7
from SACOMMON1340 D1),
SAWITH3 AS
( select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4,
D1.c5 as c5, D1.c6 as c6, D1.c7 as c7, sum(D1.c6) as c8, sum(D1.c7) as c9
from SAWITH2 D1
group by D1.c1, D1.c2, D1.c3, D1.c4, D1.c5, D1.c6, D1.c7),
SAWITH4 AS
(( select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5,
D1.c6 as c6, D1.c7 as c7, D1.c8 as c8,
sum(D1.c9) over (partition by D1.c3, D1.c4, D1.c5) as c9
from SAWITH1 D1
union all
select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5,
D1.c6 as c6, D1.c7 as c7,
sum(D1.c8) over (partition by D1.c3, D1.c4, D1.c5) as c8,
sum(D1.c9) over (partition by D1.c3, D1.c4, D1.c5) as c9
from SAWITH3 D1 ))
select D1.c1 as c1, D1.c2 as c2, D1.c3 as c3, D1.c4 as c4, D1.c5 as c5,
D1.c6 as c6, D1.c7 as c7, D1.c8 as c8, D1.c9 as c9
from SAWITH4 D1 order by c1, c3, c5, c4;
$ sqlplus sh/oracle12345@localhost:1521/poco SQL> set time on timing on pages 0 lines 200 -- セッション単位でのパラレルクエリ有効化(強制的にパラレル度16) alter session force parallel query parallel 16 ; -- IOバウンドなSQLの実行 @query_IO.sql ...(省略)... 経過: 00:00:20.10
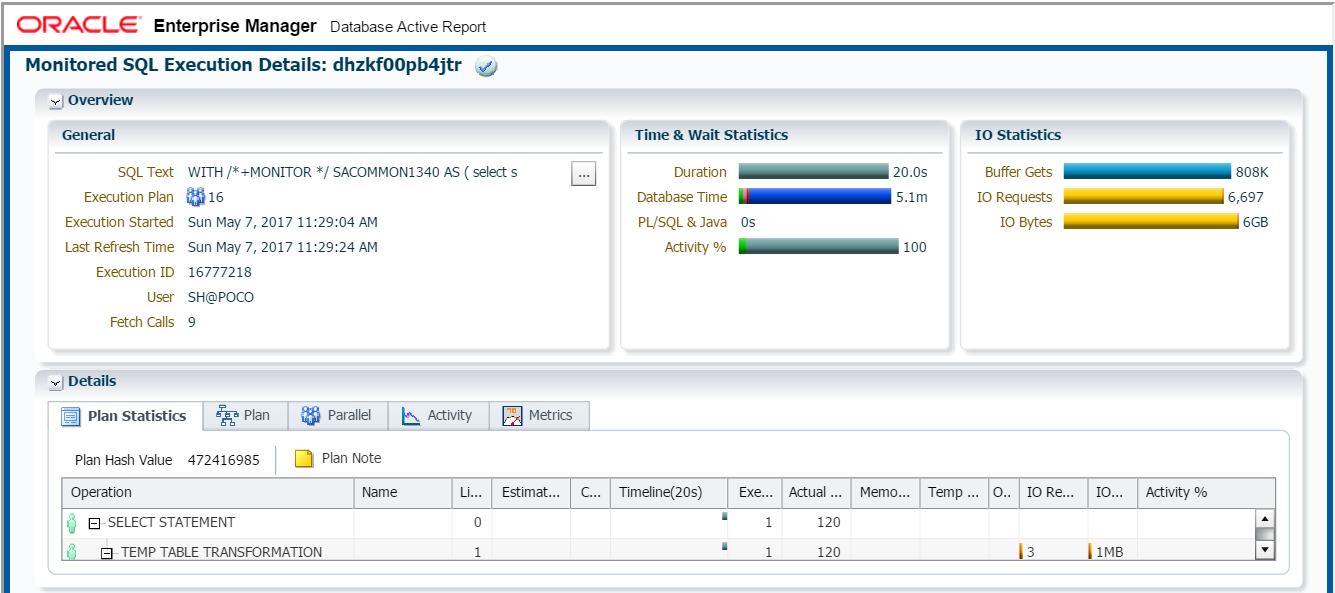
はい、I/OバウンドなSQLに対しても並列度16でパラレル実行させてみましたが、あまり効果はありませんでしたね(逆に1秒遅くなっちゃった?)I/OバウンドなSQLはI/O処理時間がボトルネックになっていたわけで、同時に使えるCPUコア数が増えたとしても、今回のケースでは意味がなかったのでしょう。(「Database Time」の青帯(I/O時間)が大部分を占めているので意味なし)それよりも一人のサーバープロセスで行っていた処理をパラレル化によって複数プロセスに分散したり結果を取りまとめたり、CPU処理でやるべきことが増えてしまったのが敗因だと推測しています。
ということで、パラレル化までのチューニング効果を以下に整理してみましょう。

さあ、CPUバウンドなSQLとI/OバウンドなSQLのいずれもが20秒前後まで高速化してきましたね。次回は持ち越しとさせていただいた圧縮技術を活用してさらなる高速化を目指していきましょう。圧縮の効果がどちらのSQLにどのように効果があるのか、ぜひ楽しみにしていてください。(先に知りたい方は、Oracle Code Tokyo 2017での[PDF] [YouTube] を先にどうぞ!)
今回も最後までお付き合い頂きまして、ありがとうございました。次回もご愛読のほど、よろしくお願いします!
