※ 本記事は、Mickey Boxellによる”Kubernetes Worker Node Repair“を翻訳したものです。
2025年8月27日
はじめに
OCI Kubernetes Engine (OKE)ユーザーが障害のあるワーカー・ノードで修復アクションを実行できることをお知らせします。この変更により、ノード・ヘルスの問題に対処するために、クラスタ内の管理対象ノードおよび自己管理ノードのブート・ボリュームをリブートまたは置換できます。これらの修正アクションは、OKE APIとKubernetes APIを介してネイティブに実行でき、Kubernetesレベルの可用性構成が考慮されます。
背景
障害の発生したノードは、パフォーマンスの低下やアプリケーションのダウンタイムにつながる可能性があります。ホスト・レベルの問題に対処するための長年のアプローチは、単に問題のあるノードを終了し、新しい正常なノードに置き換えることです。OKEクラスタでは、これはノード・プール・サイクルを介してノード・プール・レベルで実行することも、特定のワーカー・ノードを削除してノード・レベルで実行することもできます。不健全なノードを終了し、それらを新しい健全なノードに置き換えることは、ノードの健全性に影響を与える問題の大部分に対処する優れた方法ですが、一部のケースではより穏やかなアプローチを検討する価値があります。
代替修理オプション
インスタンスの終了および置換(ノードのブート・ボリュームのリブートまたは置換を含む)の代替手段は、問題の修正を迅速化し、ワークロードの中断を短縮します。これらの選択肢は、ステートフルなワークロードを扱っていて、マシン間で状態を移す際に多大な手間と注意を伴うユーザーにとって有効です。また、ベア・メタル・インスタンスのユーザー(たとえば、AIモデル・トレーニング・ワークロードを持つユーザー)にもメリットがあります。このワークロードでは、新しいインスタンスの起動に必要な長いリサイクル時間を避ける必要があります。
リブート
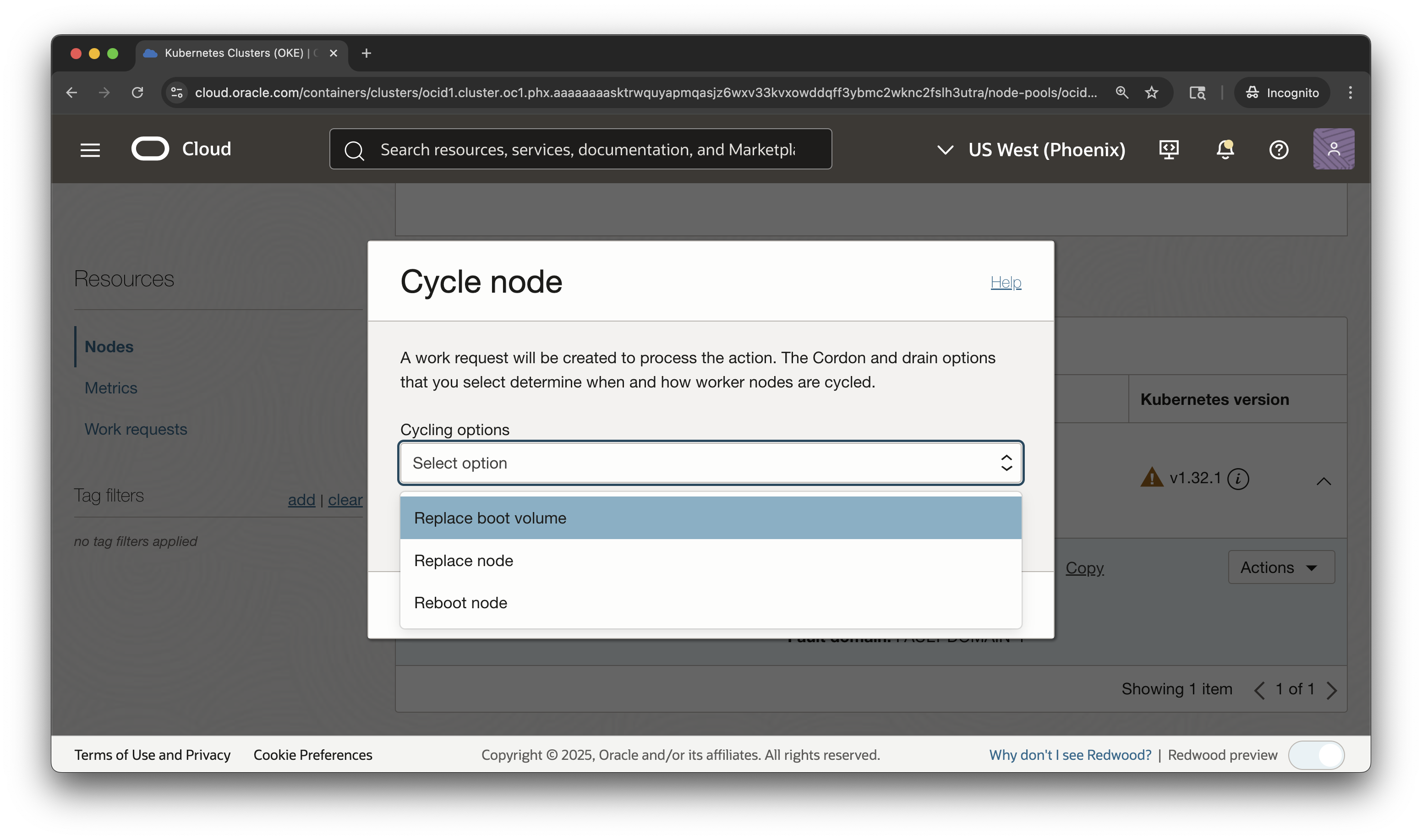
リブートすると、インスタンスを再起動してエラー状態を解決できます。Kubernetesのコンテキストで、ワーカー・ノードを再起動すると、ノードをホストしているコンピュート・インスタンスの電源が再投入されます。ノードを再起動すると、オペレーティング・システムにshutdownコマンドを送信してインスタンスを再起動します。コマンドを発行すると、ノードが停止され、ドレインされます。これにより、Kubernetesが新しいワークロードをノードにスケジュールしたり、既存のワークロードを新しいノードにオフロードしたり、OSに停止する時間が与えられ、インスタンスの電源が切断されてから再びオンになります。終了および置換とは対照的に、インスタンス自体は終了せず、同じOCIDおよびネットワーク・アドレスを保持します。
場合によっては、ホストの問題を解決するために単純な電源再投入で十分です。たとえば、ベア・メタルGPUユーザーは、ジョブ・パフォーマンスの低下や、 GPUメモリチップの温度が高温となり、サーマルスロットリングが発生していることを示す状態に 直面する場合があります。または、ホストが予期したGPU数より少ないと報告していること、またはハードウェアがバスから外れていることなど。NVIDIA Fabric Managerの起動に失敗したり、NCCLジョブの実行に失敗したりすると、NVLinkエラーが表示される可能性があります。これらすべての場合において、問題を修正する最初の手順はノードのリブートです。
ブート・ボリュームの置換
ブート・ボリュームの置換では、ワーカー・ノードをホストしているインスタンスのブート・ボリュームを置換する簡単なパスが提供されます。ブート・ボリュームの構成ドリフトによって発生した問題が検出された場合は、ノード・プールのプロパティを更新せずに、ブート・ボリュームの置換を実行して修正できます。これにより、ノードのブート・ボリュームは、元のブート・ボリュームと同じプロパティを持つ、新しくプロビジョニングされたブート・ボリュームに置き換えられます。コマンドを発行すると、ノードが停止および退避(ドレイン) され、インスタンスが停止し、ブート・ボリュームがスワップ・アウトされ、インスタンスがボリューム交換プロセスの前の状態に戻ります。このアプローチは、GPUドライバのバージョンを更新するなどしてノード上でアクションを実行して元の状態を変更し、インスタンスまたはインスタンスを元の状態に戻す場合に役立ちます。
ブート・ボリュームの置換によって管理対象ノードを修復するもう1つの方法は、新しいホスト・イメージやcloud-initスクリプトなど、更新されたプロパティを持つブート・ボリュームに既存のブート・ボリュームを交換することです。このアプローチの詳細は、Non-Destructive Kubernetesワーカー・ノードの更新を参照してください。
Kubernetes中心のアプローチ
Kubernetes APIを使用した修復
ノード修復の最もエキサイティングな側面の1つは、OCI ComputeインスタンスがKubernetes APIを介して直接支援するワーカー・ノードに対してアクションを実行する機能です。Kubernetes APIを通じてこれらの新しい修正アクションを直接実行することを好む多くのユーザーと話し合いました。サポートされているオプションでもあるノードのブート・ボリュームを再起動または置換するためにOCI APIをコールする必要はなく、Kubernetesカスタム・リソースおよびノード・セレクタを使用してKubernetes APIを介して直接実行できます。この機能は、KubernetesとOCI API間の分割されたジャンプ・エクスペリエンスを回避し、拡張性にも役立ちます。たとえば、クラスタ管理スタックの上流レイヤーにノードの問題の可視化で一般的に使用される操作ツールであるnode-problem-detectorを持つユーザーは、ツールによって生成されたノード条件を新しく使用可能なノード・アクションに活用して、ノードの問題を自動的に修正できます。
削除猶予期間
Kubernetes APIを介して新しいアクションを使用可能にすることに加えて、アクション自体もKubernetesの可用性のベスト・プラクティスを尊重します。ノード・サイクリングおよび削除APIを介してノードを終了および置換する既存の機能と同様に、再起動およびブート・ボリュームの置換では、削除猶予期間、ノードに対してアクションを実行する前にノードをコード化および排出できるようにする時間の長さを設定するオプションが提供されます。このオプションは、ワークロードに設定されたpod disruption budgetsを考慮して、ノードでのアクションの実行時にポッドがまだ実行されていた場合に発生する可能性のある中断を回避します。削除猶予期間の終了までにポッドの削除に失敗した場合は、操作を取り消すか、アクションを続行するかを選択できます。
maxUnavailableノード
ノード・プール内のすべてのノードのブート・ボリュームを置換するなど、複数のノードで一度にアクションを実行する場合、サービスの可用性およびコストの要件を満たすようにOKEの動作を調整できます。アップグレード操作中に同時に使用できないノード数を指定できます。これはmaxUnavailableと呼ばれます。一度に使用できないノードの数が多いほど、並行して多くのノードを修復できます。ただし、使用できないノードの数が多いほど、サービスの可用性が低下する可能性があります。管理対象ノード・プールを選択し、その中のすべてのノードの終了と置換、およびその中のすべてのノードのブート・ボリュームの置換を選択できます。現時点では、管理対象ノード・プールを選択して、その中のすべてのノードを再起動することはできません。ノードを個別に再起動する必要があります。
包括的なノード・サポート
この機能の目標は、OKE管理対象ノード、自己管理ノード、OCI仮想マシン・シェイプおよびベア・メタル・シェイプに支えられたノードなど、すべてのタイプのノードを修復できるようにすることでした。従来、最も一般的に使用されるタイプのOKEノードは、仮想マシンによってバックアップされた管理対象ノード・プール内のノードです。ベア・メタル・シェイプや自己管理ノードなど、このタイプの外部のノードでは、使用可能な操作機能が少なくなりました。すべてのノード・タイプで統一されたエクスペリエンスを提供するために、すべてのノード・タイプがこれらの新しい操作機能を利用できるようにすることが重要でした。
まとめ
インスタンスの終了および置換は、ノードの健全性の問題に対処する唯一の方法ではなくなりました。ノードのブート・ボリュームをリブートまたは置換すると、多数のホスト・レベルの問題に対処できます。これは、インスタンスの終了および置換に比べて、修正が速く、ワークロードの中断が短いという利点があります。これらの代替アクションは、Kubernetesの可用性設定を尊重し、OCI APIを通じて、またはKubernetes APIを通じて直接トリガーすることで、KubernetesとOCI APIの間でジャンプする断されたエクスペリエンスを回避し、拡張性にもつながります。
詳細は、次のリソースを参照してください:
