※ 本記事は、Mickey Boxellによる”Non-Destructive Kubernetes Worker Node Updates“を翻訳したものです。
2025年8月27日
はじめに
OCI Kubernetes Engine (OKE)ユーザーがブート・ボリュームの置換を通じてワーカー・ノードを更新できることをお知らせします。この機能により、Kubernetesバージョン、ホストOSイメージなど、管理対象ノード・プール内の仮想マシンとベア・メタルOCIコンピュート・インスタンスの両方に支えられたワーカー・ノードのプロパティを更新でき、基礎となるインスタンスを破棄する必要はありません。ブート・ボリュームの置換では、ベア・メタル・インスタンスの終了および置換に比べてはるかに高速にアップグレードできます。また、インスタンス自体が終了しないため、元の終了後に新しいインスタンスを作成する容量が不十分である可能性がなくなります。OKEを介してノードをサイクリングすることは、Kubernetesが認識し、Kubernetesレベルの可用性構成を尊重します。
背景
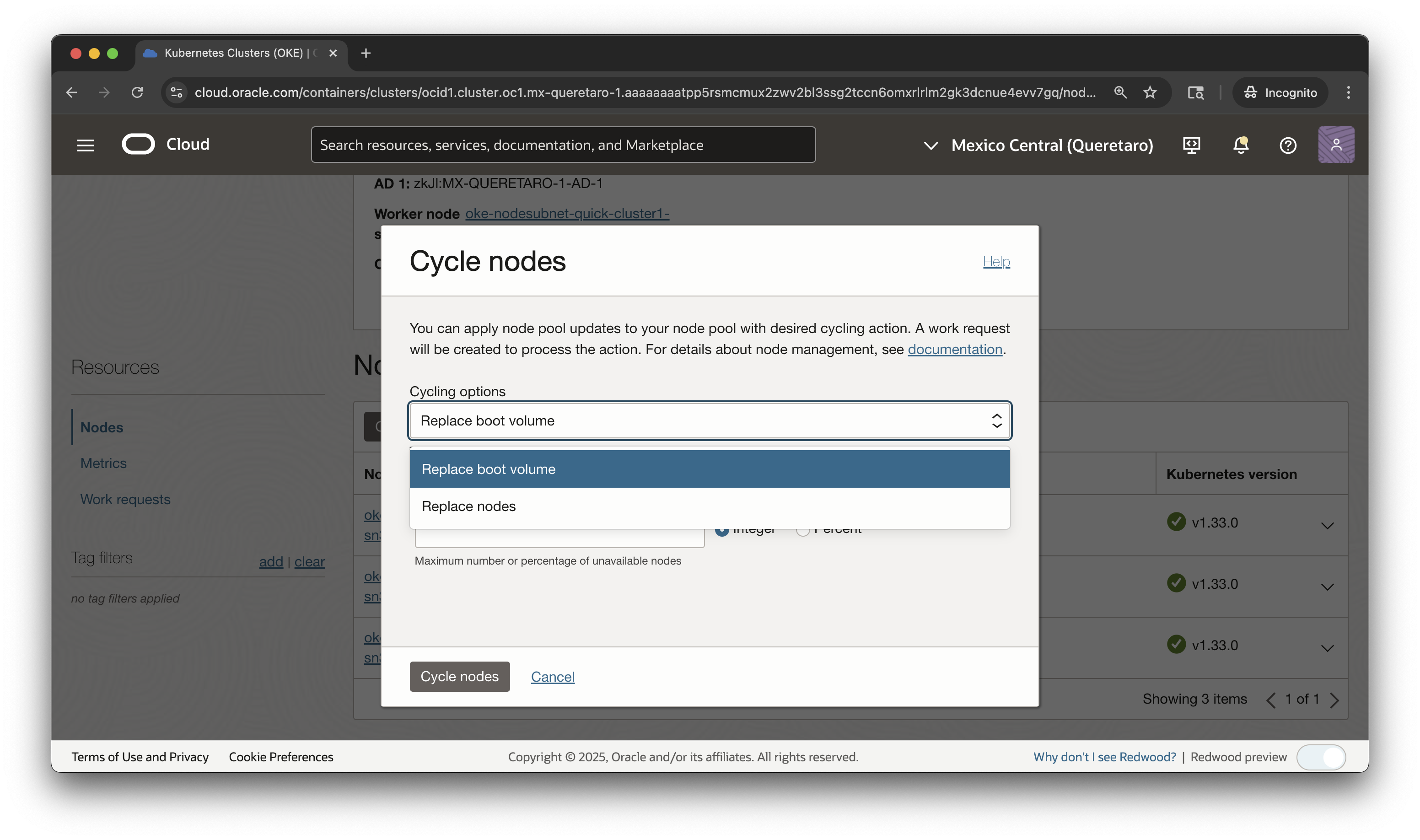
OKEクラスタの管理対象ワーカー・ノードの更新プロセスを簡素化するワーカー・ノード・サイクリングが導入されました。これにより、更新されたプロパティを実行しているノードを使用して、ノード・プール内のすべての既存ノードの置換をトリガーできます。ノード・プールのプロパティを変更してから、ノードを循環して変更を適用します。
元のバージョンのノード・サイクリングは、仮想マシン・インスタンス(主流のワーカー・ノード・タイプ)によってバックアップされたワーカー・ノードにのみ適用でき、ベア・メタルによってバックアップされたワーカー・ノードは除外されていました。長年にわたり、インスタンス・タイプによって提供される高パフォーマンスと強力な分離のために、ワーカー・ノードにベア・メタル・コンピュート・インスタンスを採用する顧客が増え始めました。これは、ベア・メタルGPUインスタンスを使用してモデル・トレーニングのパフォーマンスを最大限に高めたいAI/MLワークロードを持つ多数のお客様にとって特に当てはまりました。これらの顧客は、更新をノードに適用する必要性に対処し、新しいインスタンスの再起動にかかるリサイクル時間を短縮する方法で支援したいと考えていました。
ブート・ボリュームの置換
2024年、OCI Computeは、インスタンスを終了せずに既存のインスタンスをブート・ボリュームからリストアできる機能であるブート・ボリュームの置換をリリースしました。数回のクリックまたはAPIコールで既存のインスタンスをアップグレードするための簡単なパスを提供しました。OKEでは、この機能を利用して、仮想マシンとベア・メタル・インスタンスの両方でバックアップされたノードに更新を適用できるようになりました。ブート・ボリュームの置換によって、ノードを終了および置換しなくても、次のワーカー・ノード・プロパティを更新できます:
-
Kubernetesバージョン
-
ホスト・イメージ
-
ノード・メタデータ
-
SSH公開キー
-
ブート・ボリューム・サイズ
他のノード・プール・プロパティ(ノードのシェイプやKMSキーなど)を更新する必要があるユーザーは、ワーカー・ノードの終了および置換を通じて更新できます。
ワーカー・ノードのブート・ボリュームを置換すると、ワーカー・ノードをホストしているコンピュート・インスタンスが停止され、ブート・ボリュームが置換されて、ブート・ボリュームを置換する前の状態に戻されます。ブート・ボリュームの置換によってノードをサイクリングする場合、インスタンス自体は終了されず、同じOCIDおよびネットワーク・アドレスが保持されます。
ワークロードの可用性の確保
ブート・ボリュームを置換するには、インスタンスを停止する必要があります。これにより、ノードで実行されているすべてのワークロードが中断されます。OKEには、ワークロードの中断を回避するための構成オプションが用意されています。maxUnavailable値を指定することで、更新操作中に同時に使用できないワーカー・ノードの数を制御できます。また、OKEでは、削除されるワークロードに関係なく、操作をタイムアウトするか、置換を続行するかを選択する前に、削除猶予期間、退避(ドレイン) の許容時間を指定できます。アプリケーションに適したpod disruption budgetsを利用して、操作全体で十分な数のレプリカ・ポッドが実行されていることを確認できます。
ノード・プールを選択し、ワーカー・ノードのブート・ボリュームを置換して循環するように指定すると、OKEは自動的にノードを終了するため、追加のワークロードはスケジュールされません。その後、それらのワークロードを退避(ドレイン)して、ブート・ボリュームの置換中にpodがまだ実行されていた場合に発生する可能性のある中断を回避します。各ワーカー・ノードをホストしているインスタンスのブート・ボリュームは、インスタンスを終了せずに置換されます。また、ワーカー・ノードを終了および退避(ドレイン)することなく、ワーカー・ノードをただちに終了することもできます。
ブート・ボリューム置換でノードを更新するタイミング
インスタンスの終了と置換、またはブート・ボリュームの置換によるノード・サイクリングによるワーカー・ノードの更新は、いくつかのシナリオで役に立つ手順です:
-
Kubernetesバージョンの新規バージョンがリリースされ、新しい機能にアクセスするためにワーカー・ノードをアップグレードする場合。
-
選択したワーカー・ノード・ホストOSの新しいバージョンが使用可能であり、適用する必要があるセキュリティ・パッチがある場合。
-
ワーカー・ノード・ホストをカスタマイズするために使用するcloud-initスクリプトを更新しようと考えている場合。
-
組織ポリシーに準拠するには、SSHキーをローテーションする必要がある場合。
ノード・サイクリングを介してワーカー・ノードのブート・ボリュームを置換する必要があります:
-
ベア・メタル・インスタンスによってバックアップされたワーカー・ノードに更新を適用する場合。
-
ワーカー・ノードに更新を適用する場合、特定のフォルト・ドメインで必要なシェイプの容量制限に直面している場合。
ブート・ボリュームの置換を使用するノードでアクションを実行するもう1つの大きな理由は、ブート・ボリュームの構成ドリフトによって発生する問題を修正することです。この場合、ノード・プールのプロパティを更新せずにブート・ボリュームの置換を実行し、既存のボリュームを元のブート・ボリュームと同じプロパティを持つ新しくプロビジョニングされたボリュームに置き換えます。詳細は、Kubernetesワーカー・ノードの修復を参照してください。
まとめ
ブート・ボリュームの置換によってノードを循環させると、インスタンスを終了および置換しなくてもインスタンスを更新できます。このアプローチでは、ベア・メタル・インスタンスによってバックアップされた管理対象ノード(GPUアクセラレータがAIモデル・トレーニングに使用されているノードなど)を初めて更新できます。ブート・ボリュームの置換によるサイクリングも、目的のシェイプの容量が制約された場合にノードを更新するための優れたソリューションです。
詳細は、次のリソースを参照してください:
