※ 本記事は、Shrinidhi Kulkarni, Madhu Kumar Sによる”Replicate Oracle Database 23ai JSON-relational duality view data in real-time using Oracle GoldenGate 23ai“を翻訳したものです。
2025年1月29日
Oracle GoldenGate 23ai (23.6.0.24.10)では、Oracle JSONリレーショナル二面性およびGoldenGate Data Streamsを使用した、イベントベースのpub/subアーキテクチャでのフル機能のビジネス・オブジェクトのレプリケートがサポートされるようになりました。これは、Oracle Database JSONリレーショナル二面性ビューとOracle GoldenGate Data Streamsの2つの新しいOracleテクノロジ機能を組み合せることで実装されます。
Oracle GoldenGate 23ai (23.6)では、JSONリレーショナル二面性ビューおよびJSONコレクション表の次のレプリケーション・ユースケース/シナリオがサポートされています:
- Data StreamsへのJSONリレーショナル二面性ビューまたはJSONコレクション表(あるいはその両方): Oracle GoldenGateは、JSON二面性ビューに対する変更をJSONオブジェクトとしてGoldenGate Data Streamsにレプリケートできます。
- JSONコレクション表とJSONコレクション表: Oracle GoldenGateは、JSONコレクション表間でデータをレプリケートできます。
- 二面性ビューからコレクション表へ: Oracle GoldenGateでは、二面性ビューからコレクション表にデータをレプリケートできます。基本的に、これらの2つのJSONに焦点を当てた機能間でデータを移動します。
- 二面性ビュー(基礎となる表)と二面性ビュー(基礎となる表)間のレプリケーション: Oracle GoldenGateでは、ビューをレプリケートせずに、基礎となる表を二面性ビューから二面性ビューにレプリケートできます。JSON二面性ビューに対してサプリメンタル・ロギングが有効になっている場合、既存のリレーショナル表の上に余分なREDOが生成されます。
ノート: 二面性ビューから別のビューへのレプリケーションはサポートされていません。
このブログでは、最初のシナリオ(JSONリレーショナル二面性ビューからData Streamsへのレプリケーション)について説明します。
構成ステップ:
- 前提条件
- JSONリレーショナル二面性ビューを作成します。
- JSONリレーショナル二面性ビューのサプリメンタル・ロギングの有効化
- Oracle GoldenGate for OracleデプロイメントにExtractおよび証跡ファイルを作成します。
- Oracle GoldenGate Distribution ServiceからのData Streamsの追加
- GoldenGate Data Streamsのコンシューマとしてのダウンストリーム・アプリケーションの構成
- 変更データをテストのためにソース文書/表に挿入します。
- Data Streamsからの変更データの使用。
前提条件:
- Oracle GoldenGate for Oracle 23ai (23.6)をインストールします。
- デプロイメント構成: Oracle 23aiデプロイメント用のGoldenGateを追加するには、Oracle GoldenGate Configuration Assistant (oggca)プログラムを実行して、Oracle GoldenGate Configuration Assistantウィザードを使用してデプロイメントを追加するには、ここで説明するステップを対話型またはサイレントmode.Followでウィザードを起動します。
- Oracle Database 23ai (23.6)インスタンス
このブログの範囲では、OCIベース・データベース・サービスを使用してOracle Database 23.6インスタンスをプロビジョニングします。
ノート: Oracle DatabaseからOracleまたはOracle以外のデータベースにJSONリレーショナル二面性ビュー・データをJSONドキュメントとしてレプリケートするためのOracle GoldenGateのサポートがOracle Database 23.6リリースで追加されました。
JSONリレーショナル二面性ビューの作成
JSONリレーショナル二面性ビューは、リレーショナル・データベース表に格納されているデータをJSONドキュメントとして公開します。ドキュメントは実体化されます。(オンデマンドで生成され、保存はされません。) 二面性ビューは、データを概念と操作の両方の二面性(リレーショナルと階層の両方に編成)にします。1つ以上の同じ表に格納されているデータに対して異なる二面性ビューをベースにし、同じ共有データに対して異なるJSON階層を提供できます。
ここでは、イベントの出席者スケジュール・データを使用して、JSONリレーショナル二面性ビューの機能を示します。この例では、必要なタイプのJSONドキュメントの分析から開始し、対応するエンティティとその関係の定義に進みます。その後、これらの表に基づいてリレーショナル表および二面性ビューが作成されます。
出席者イベント・スケジュールの例では、出席者、セッションおよび講演者の3種類のJSONドキュメントを使用するドキュメント中心のアプリケーションがあるとします。これらの種類はそれぞれ別の種類のデータを共有しています。次に例を示します:
- 出席者ドキュメントには、出席者に関する情報に、出席者が参加するセッションの識別が含まれます。
- セッション・ドキュメントには、特定のセッションに関する情報に、セッションの詳細、セッションが行われる部屋、およびそのセッションに出席するスピーカーが含まれます。
- 講演者文書には、講演者に関する情報に、講演者が講演しているセッションが含まれます。
出席者イベント・スケジュールの例、表
正規化されたエンティティは、データベース表としてモデル化されます。エンティティ関係は、参加表間の結合としてモデル化されます。表の参加者、セッション、attendee_session、speakerおよびspeaker_sessionは、参加者イベント・スケジュール・アプリケーションで使用される参加者、セッションおよびスピーカーのJSONドキュメントを提供し、サポートする二面性ビューを実装するために使用されます。
出席者イベント・スケジュール・ベース表およびJSONリレーショナル二面性ビューの作成
この例では、主キー列を含む各表を作成し、その値は一連の整数および一意のキー列名として自動的に生成されます。これにより、主キー列に一意索引も暗黙的に作成されます。この例では、外部キー索引も作成します。
CREATE TABLE jdvuser.ATTENDEE ( ID NUMBER PRIMARY KEY, NAME VARCHAR2(100), COMPANY VARCHAR2(100) ); CREATE TABLE jdvuser.SESSIONSS ( SESSION_ID VARCHAR2(10) PRIMARY KEY, SESSION_NAME VARCHAR2(100), SESSION_TIME TIMESTAMP, ROOM VARCHAR2(50) ); CREATE TABLE jdvuser.ATTENDEE_SESSION ( ATTENDEE_ID NUMBER, SESSION_ID VARCHAR2(10), PRIMARY KEY (ATTENDEE_ID, SESSION_ID), FOREIGN KEY (ATTENDEE_ID) REFERENCES jdvuser.ATTENDEE(ID), FOREIGN KEY (SESSION_ID) REFERENCES jdvuser.SESSIONSS(SESSION_ID) ); CREATE TABLE jdvuser.SPEAKER ( ID NUMBER PRIMARY KEY, NAME VARCHAR2(100) ); CREATE TABLE jdvuser.SPEAKER_SESSION ( SPEAKER_ID NUMBER, SESSION_ID VARCHAR2(10), PRIMARY KEY (SPEAKER_ID, SESSION_ID), FOREIGN KEY (SPEAKER_ID) REFERENCES jdvuser.SPEAKER(ID), FOREIGN KEY (SESSION_ID) REFERENCES jdvuser.SESSIONSS(SESSION_ID) );
JSONリレーショナル二面性ビューの定義
CREATE or replace JSON RELATIONAL DUALITY VIEW
jdvuser.attendeeSchedule AS
SELECT JSON {
'_id': a.ID,
'name': a.NAME,
'company': a.COMPANY
,'schedule' :
json[ select json{
'ATTENDEE_ID' : ass.ATTENDEE_ID,
'attendee_sess_id' : ass.session_id,
unnest(
select JSON {
'code': s.SESSION_ID,
'session_name': s.SESSION_NAME,
'time': s.SESSION_TIME,
'room': s.ROOM,
'speakers' : json[
select json{'speaker_sess_id' : ss.SESSION_ID,
'speaker_session_speaker_id' : ss.SPEAKER_ID,
unnest(
select json{
'speaker_id' : sp.id,
'speaker_name' : sp.name}
from jdvuser.speaker sp with insert update nocheck
where sp.id = ss.speaker_id)}
from jdvuser.speaker_session ss with insert update nocheck
where ss.session_id = s.session_id]}
from jdvuser.sessionss s with insert update nocheck
where s.SESSION_ID = ass.SESSION_ID)}
from jdvuser.ATTENDEE_SESSION ass with insert update nocheck
where ass.ATTENDEE_ID = a.id ]}
FROM jdvuser.ATTENDEE a with insert update delete nocheck;
JSONリレーショナル二面性ビューのサプリメンタル・ロギングの有効化
- 適切な権限を持つデータベース・ユーザーの作成およびOracleデータベース構成の設定については、「Oracle GoldenGateのためのデータベースの準備」を参照してください。
- データベース接続の追加:
- 管理サービスUIを起動し、ログインします。
- 左側のナビゲーション・ペインから「DB Connections」をクリックします。「DB Connections」の横にあるプラス記号(+)をクリックします。
- データベース資格証明の別名を指定します。たとえば、jrdv.UseはEZconnect構文で、「User ID」フィールドにデータベース接続を構成します: username@hostname:port/service_name
- データベース・ユーザーがデータベースにログインするために使用するパスワードを指定します。「Submit」をクリックします。
- データベースの接続アイコンをクリックして、接続が正しく機能していることを確認します。接続が成功すると、チェックポイントおよびハートビート表を設定するその他のセクションが表示されます。
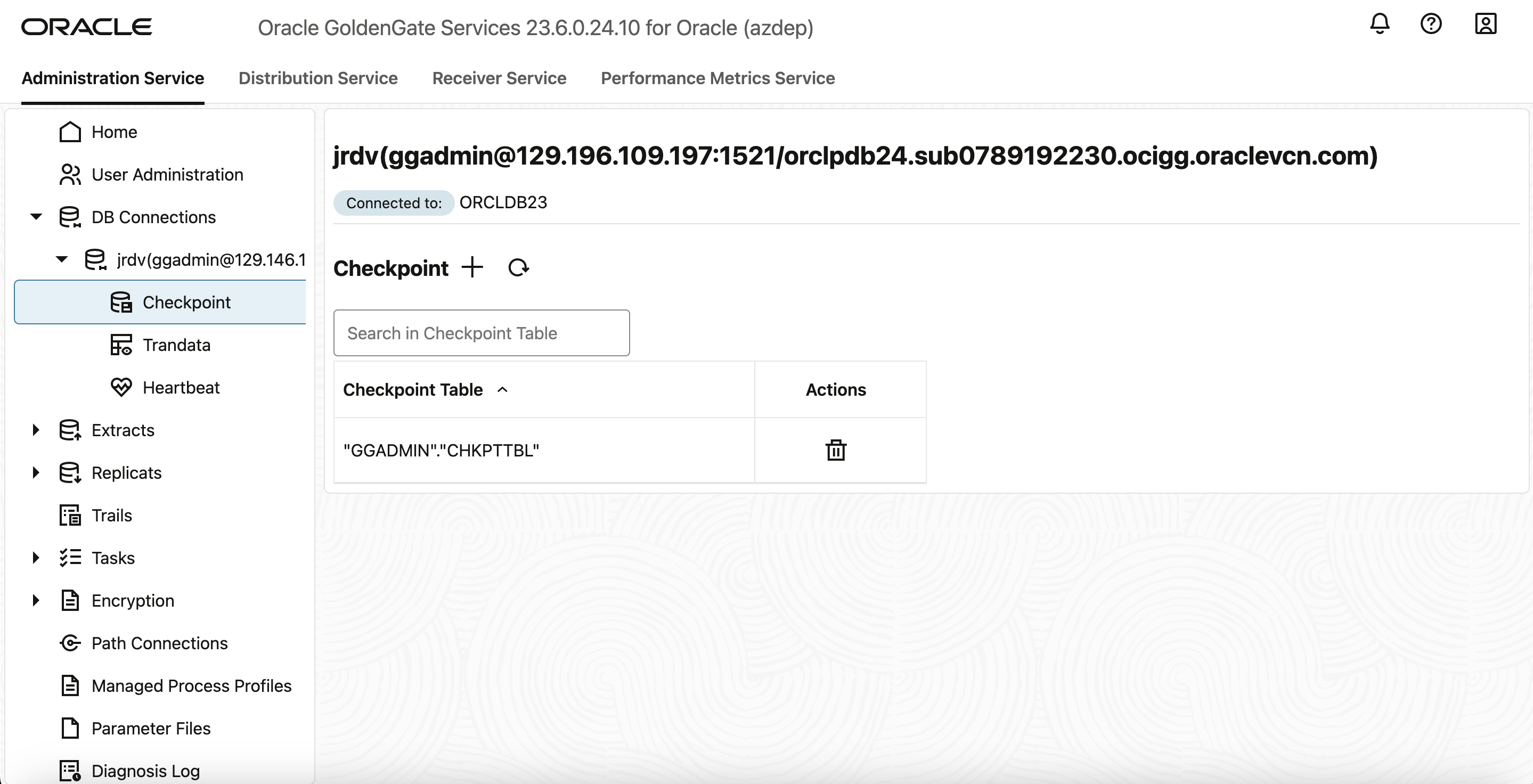
- データベースに正常に接続した後、Extractで必要なTRANDATA、SCHEMATRANDATA、チェックポイントおよびハートビート表を追加できます。
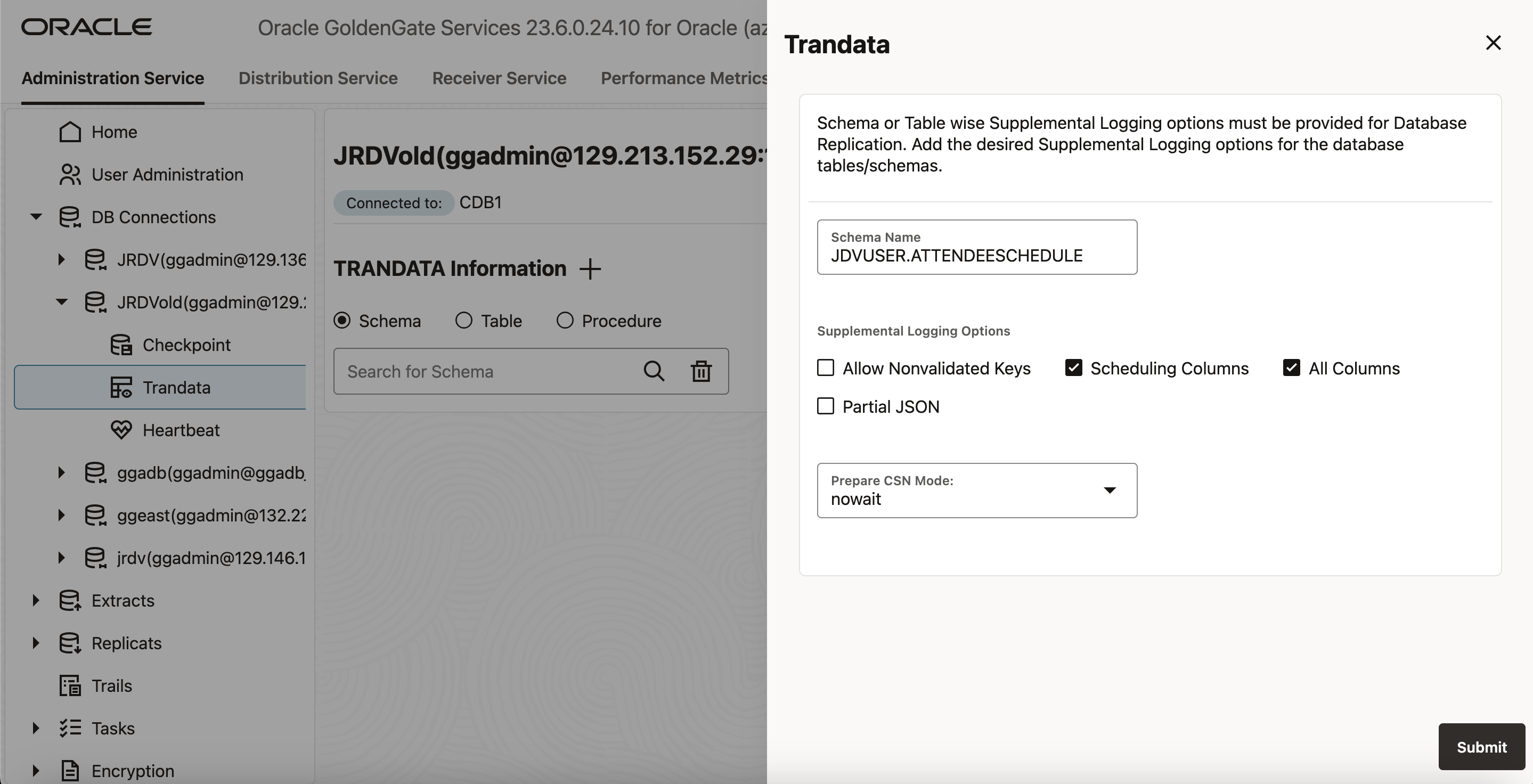
- JSONリレーショナル二面性ビューのサプリメンタル・ロギングを有効にするには、「DB Connections」ページからデータベースに接続し、「Trandata」メニューを選択してから、次のステップを実行します:
必要に応じて「Table」オプションを選択し、プラス記号をクリックして追加します。
サプリメンタル・ロギングを設定する必要があるJSONリレーショナル二面性ビューの名前を入力します。「Submit」をクリックします。 - CDCを使用しない初期ロードの場合、ADD TRANDATAをスキップできます。
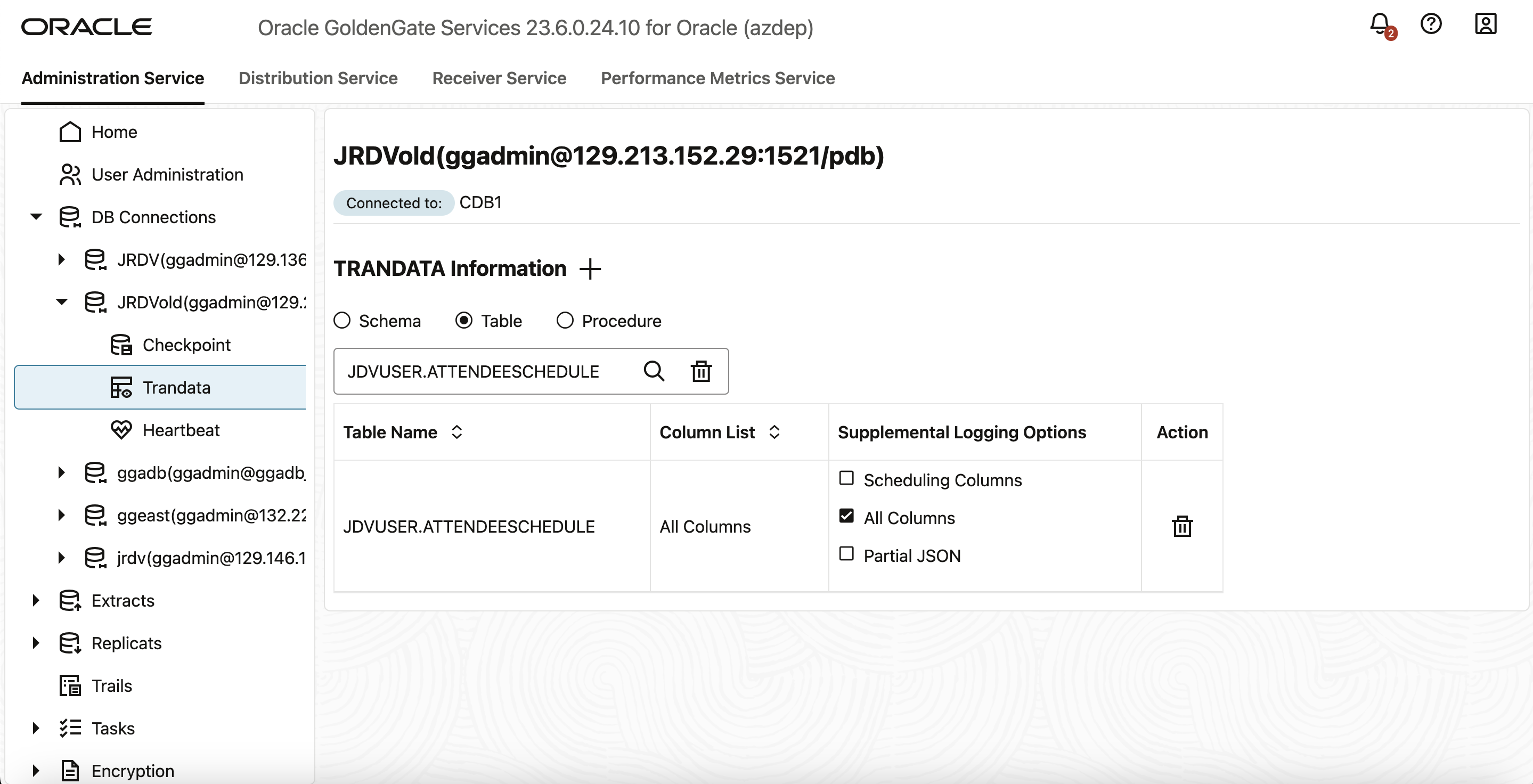
- trandataを追加した後、検索アイコンを使用して、trandataを追加したJSONリレーショナル二面性ビューを検索できます。これにより、トランザクション情報が表示されます。次の図は、プラガブル・データベースPDBのattendeescheduleのtrandata情報を示しています。
Oracle ExtractのGoldenGateの作成および構成
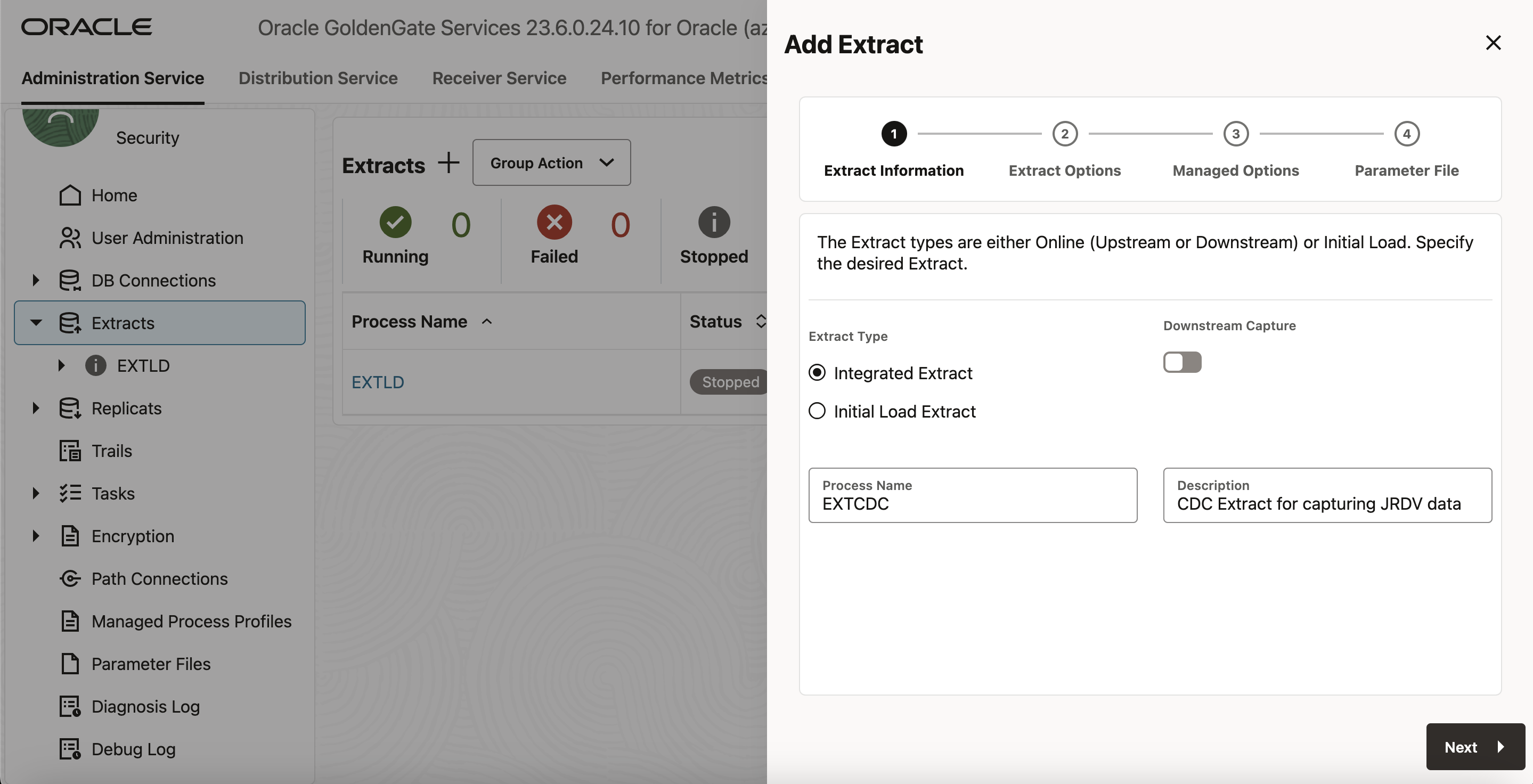
- この項では、Extractプロセス(EXTCDC)を追加します。Extractプロセスは、ソース・データベースからデータを取得し、証跡ファイル(zz)に書き込みます。
- 管理サービスのホームページで、「Extract」セクションの下にあるプラス記号(+)をクリックします。
- 「Extract Information」画面で、「Integrated Extract」を選択します。
- 「Process Name」にExtractプロセスの名前を指定します。Extractプロセスの名前は最大8文字です。r
- 説明: 作成するExtractプロセスの説明。「Next」をクリックします。
- 「Extractオプション」画面で、次の設定を構成します:
ソース資格証明: データベースのドメインを指定します。
Alias: ソース・ログインのデータベース接続として使用するユーザーID別名を指定するか、表示されたオプションから選択します。 - 「Extract Trail Name」にzzを指定し、「Next」をクリックします。
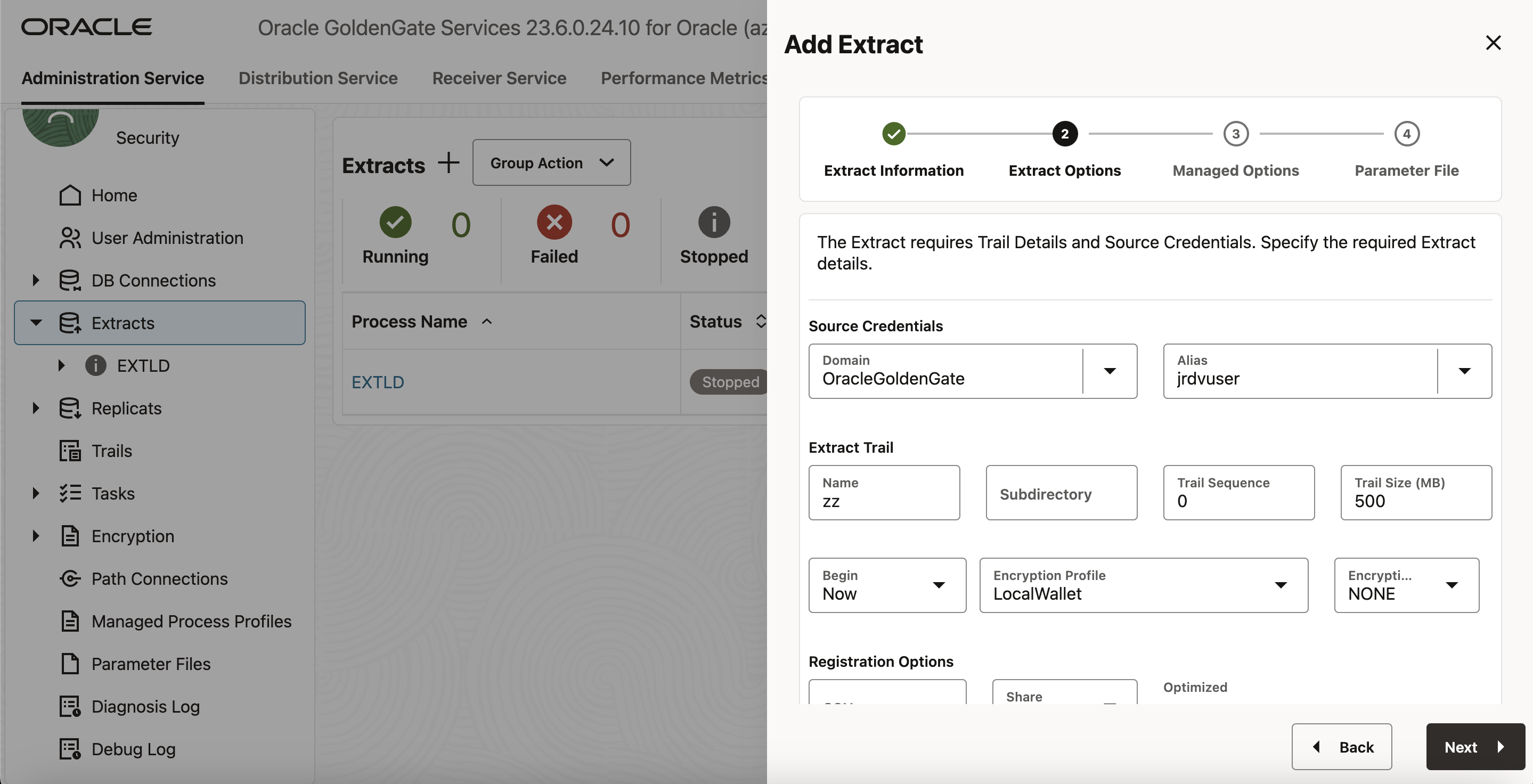
- 「Managed Options」画面で、「Default」プロファイルを選択するか、Extractプロセスの自動起動および自動再起動オプションを構成します。
- 「Next」をクリックします。「Parameter File」画面で、テキスト領域のパラメータ・ファイルを編集して、取得するJSONリレーショナル二面性ビュー名を追加できます。
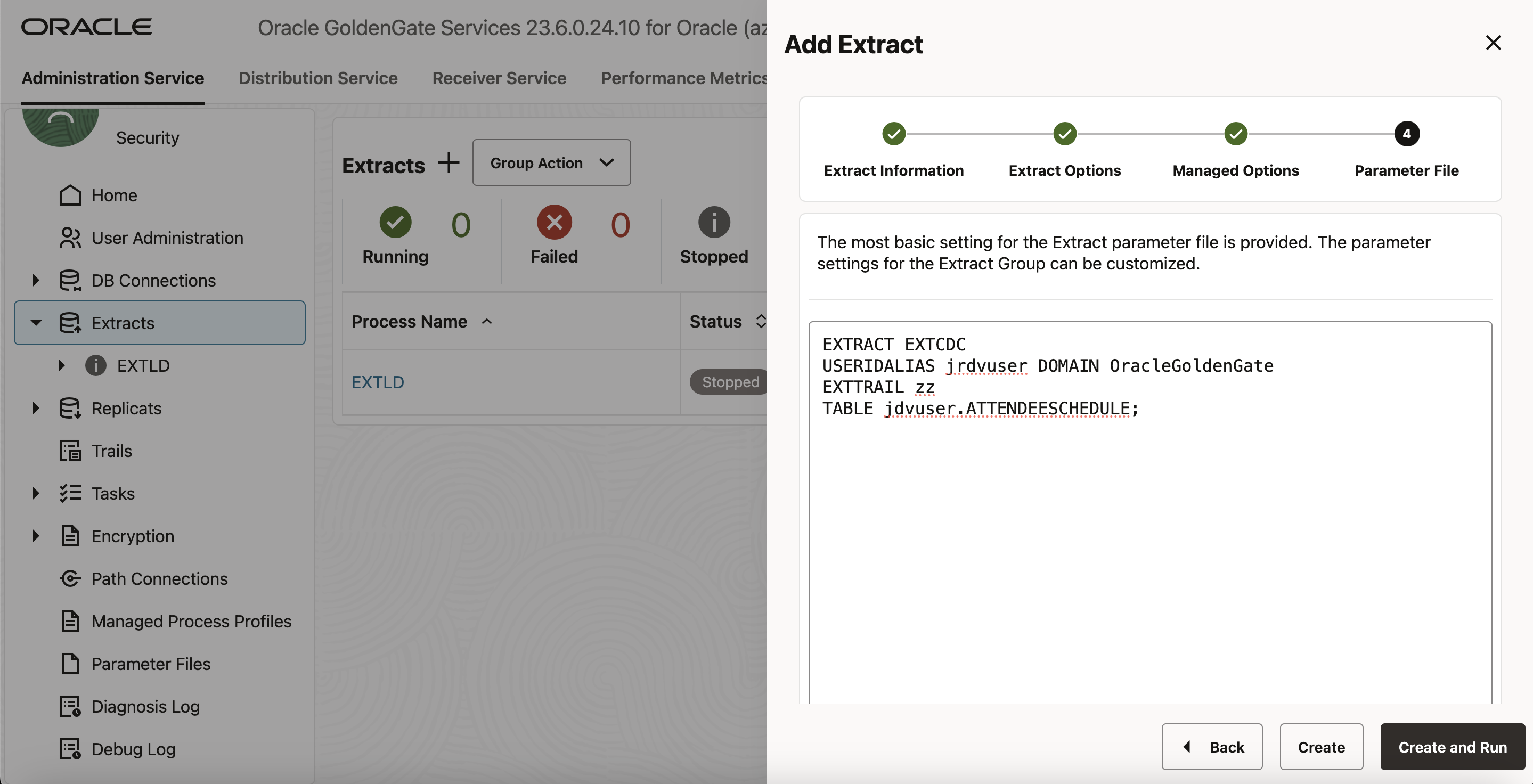
- 「Create and Run」をクリックして、Extractを作成して起動します。「Create」を選択すると、Extractが作成されますが、Extractオプションを使用して起動する必要があります。
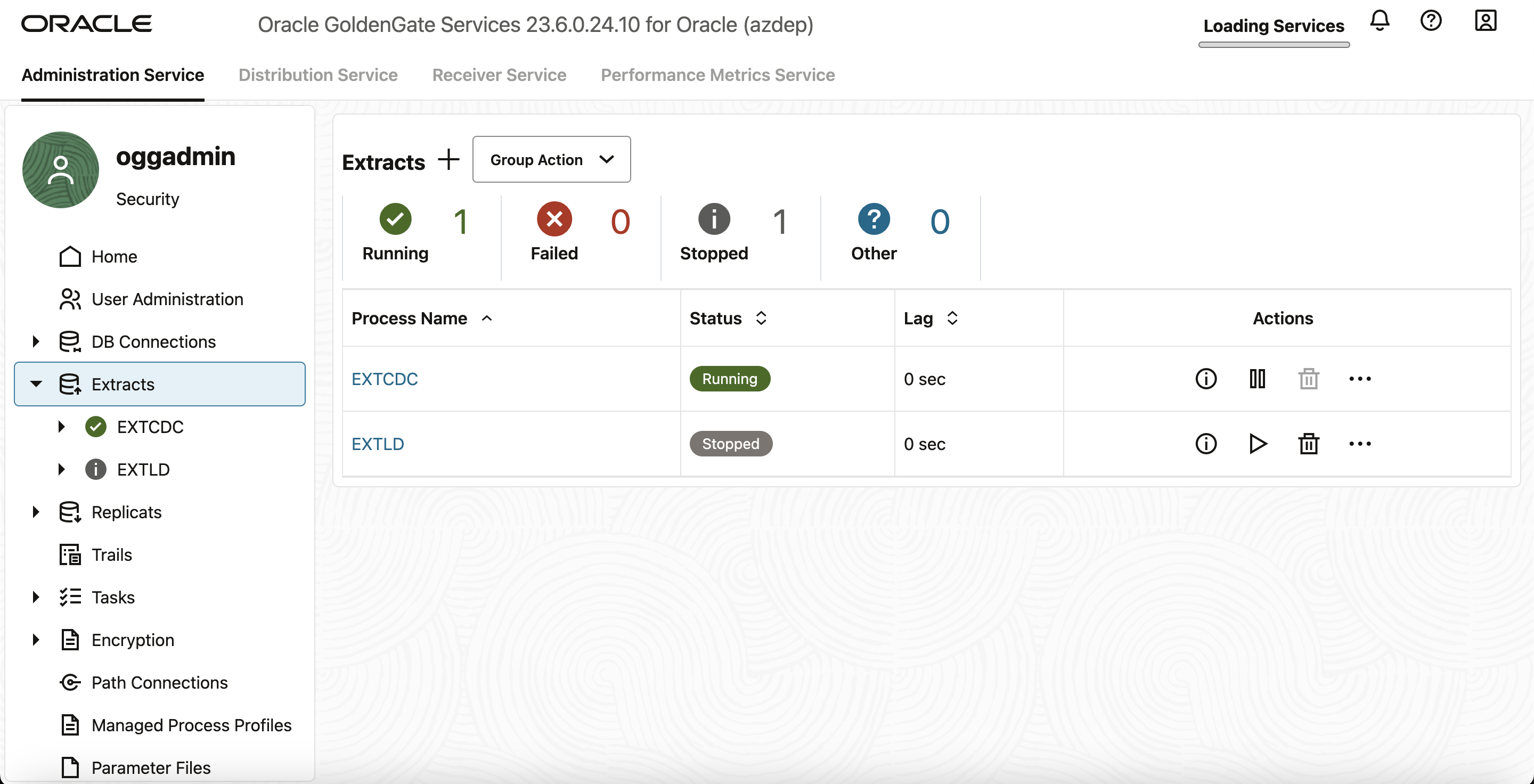
- Extractのステータスを確認するには、管理サービスの左側のナビゲーション・ペインから「Extracts」を選択します。
Oracle GoldenGate Distribution ServiceからのGoldenGate Data Streamsの構成
Data Streamsは、分散サービスから作成されます。Distribution Serviceにログインして、データ・ストリーム・プロセスの作成を開始します。
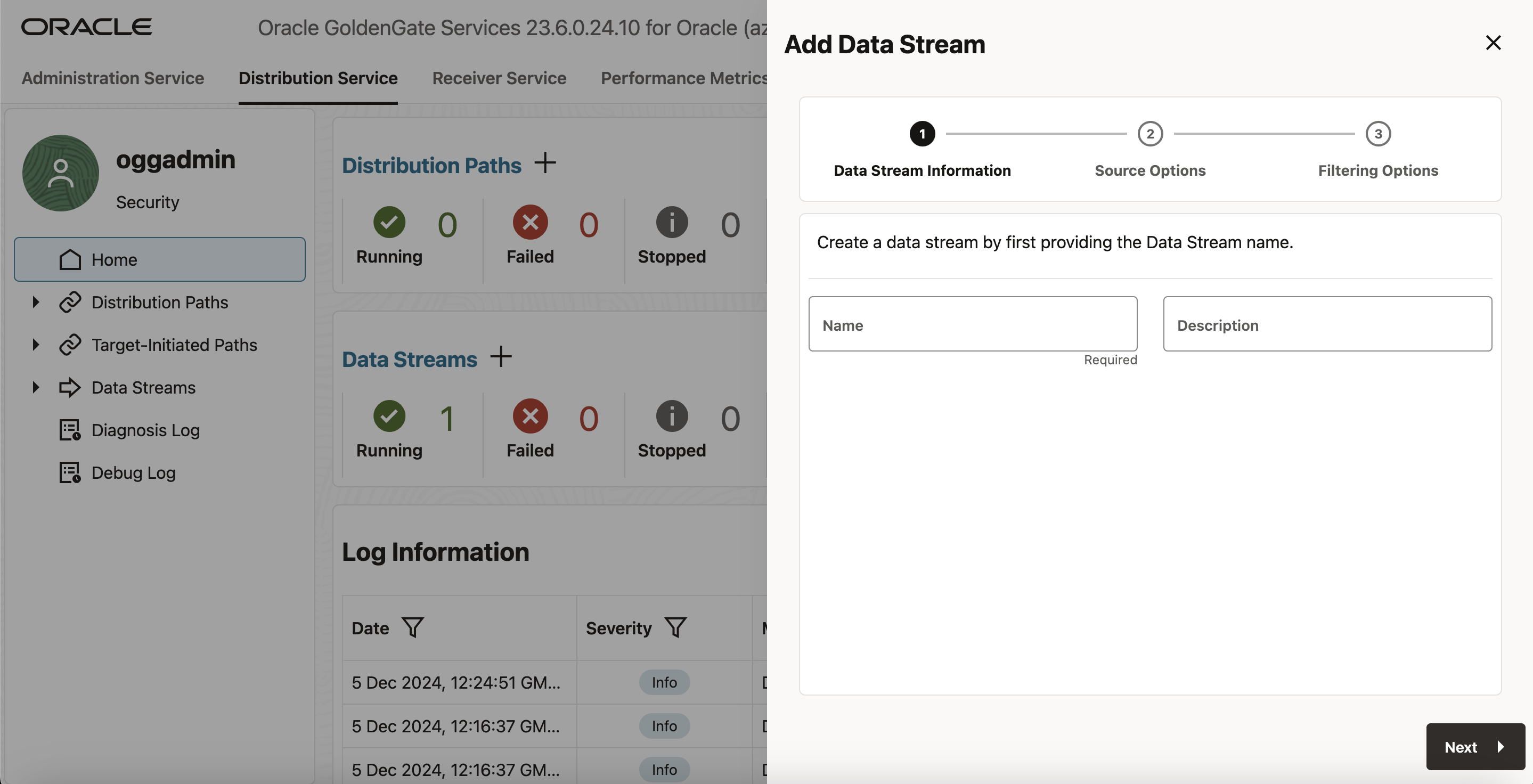
- 分散サービスのホームページで、「Data Streams」の横にあるプラス(+)記号をクリックして、データ・ストリームの作成を開始します。
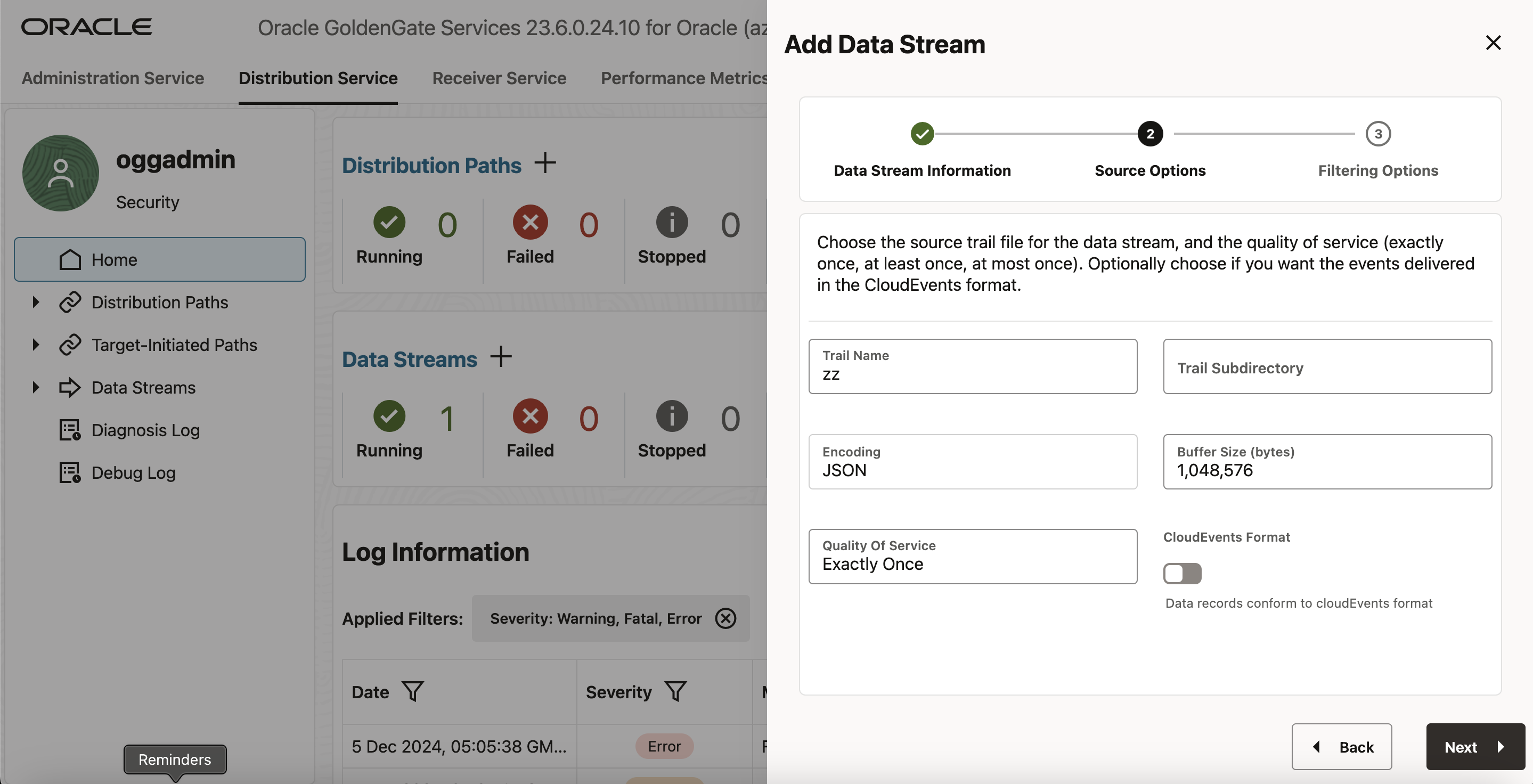
- 「Data Stream Information」ページで、「Name」ボックスにデータ・ストリーム・プロセス名を入力し、その説明を追加します。「Next」をクリックします。
- 「Source Options」ページで、証跡名にzzと入力します。
- (オプション)「Filtering Options」ページには、たとえば「Include only DML Object Type」のフィルタ・ルールを含めると除外できる様々なオプションがあります。
- 「Create Data Stream」をクリックします。
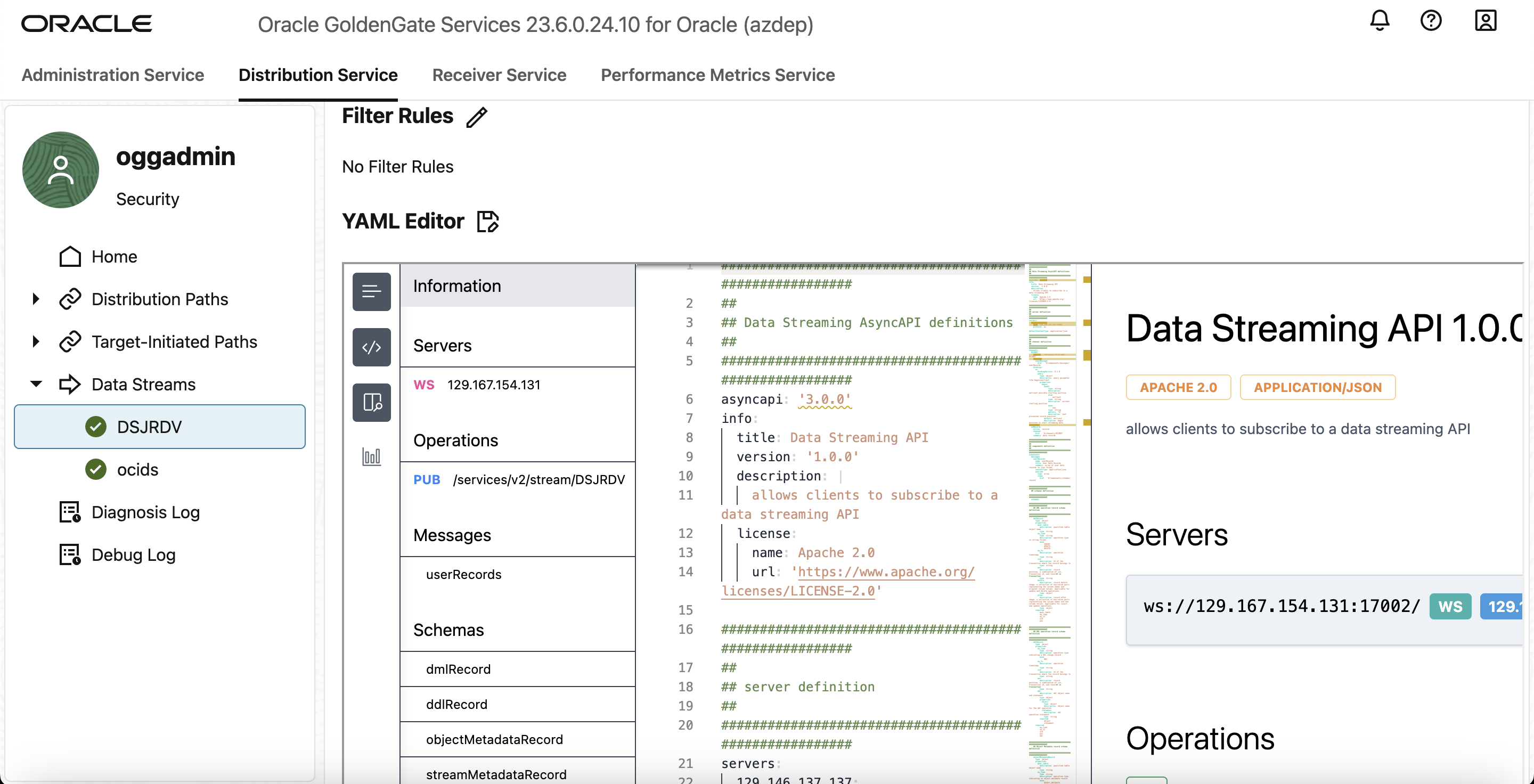
- 作成したデータ・ストリームをクリックして、ストリームのYAMLドキュメントのデータ・ストリーミングAsyncAPI定義を表示します。
GoldenGate Data Streamsのコンシューマとしてのダウンストリーム・アプリケーションの構成
Oracle GoldenGate Data Streamsは、プログラミング言語に依存しないため、任意のプログラミング言語で記述されたクライアントと対話できます。通常、クライアント・プログラムは単純で小規模ですが、ユーザーは、データ・ストリーミング・サービスと対話するためにクライアント・コードを手動で実装する必要があります。
AsyncAPI仕様をOracle GoldenGate Data Streamsに採用すると、次の利点があります:
- 業界標準のAPI仕様でデータ・ストリーム・サービスAPIを記述し、APIドキュメントを自動的に生成する機能。
- @asyncapi/generatorを使用してクライアント側のコードを自動的に生成します。
データ・ストリーム・リソースが作成されると、このデータ・ストリーム・エンドポイントへのアクセス方法を記述したカスタマイズ済非同期API仕様ドキュメントへのURLリンクがHTTPレスポンスで返されます。その後、このYAMLドキュメントを使用して、@asyncapi/generatorを使用してクライアント側のコードを生成できます。
@asyncapi/generatorでwebsocketプロトコルをサポートするには、GitHubで@asyncapi/generatorのwebsocketクライアント・テンプレートを実装/メンテナンスする必要もあります。
websocket-client-templateの詳細は、GitHubリポジトリを参照してください:
https://github.com/oracle-samples/websocket-client-template
このブログの範囲では、単純なnodeJSアプリケーションを使用して、GoldenGateデータ・ストリーム・チャネルからのデータを消費できます。ここに示すステップバイステップの詳細に従って、NodeJSアプリケーションを構成し、Oracle GoldenGate Data Streamsからデータを消費します。
レプリケーションをテストするためのソースでのDMLの実行
実表(ATTENDEE、SESSIONSS、SPEAKER、ATTENDEE_SESSIONおよびSPEAKER_SESSION)にデータを挿入するか、JSONリレーショナル二面性ビューATTENDEESCHEDULEに直接挿入できます。
INSERT INTO JRDV.SPEAKER (ID, NAME) VALUES (102, ‘Rahul’);
INSERT INTO JRDV.ATTENDEE (ID, NAME, COMPANY) VALUES (1, ‘Will’, ‘ACME Inc’);
INSERT INTO JRDV.ATTENDEE (ID, NAME, COMPANY) VALUES (2, ‘Raymond’, ‘WRIME AI’);
INSERT INTO JRDV.SESSIONSS (SESSION_ID, SESSION_NAME, SESSION_TIME, ROOM) VALUES (‘S001’, ‘Introduction to JSON’, TO_TIMESTAMP(‘2024-09-15 09:00:00’, ‘YYYY-MM-DD HH24:MI:SS’), ‘Room 101’);
INSERT INTO JRDV.SESSIONSS (SESSION_ID, SESSION_NAME, SESSION_TIME, ROOM) VALUES (‘S002’, ‘Advanced SQL Techniques’, TO_TIMESTAMP(‘2024-09-15 11:00:00’, ‘YYYY-MM-DD HH24:MI:SS’), ‘Room 102’);
INSERT INTO JRDV.SPEAKER_SESSION (SPEAKER_ID, SESSION_ID) VALUES (101, ‘S001’);
INSERT INTO JRDV.SPEAKER_SESSION (SPEAKER_ID, SESSION_ID) VALUES (102, ‘S002’);
INSERT INTO JRDV.ATTENDEE_SESSION (ATTENDEE_ID, SESSION_ID) VALUES (1, ‘S001’);
INSERT INTO JRDV.ATTENDEE_SESSION (ATTENDEE_ID, SESSION_ID) VALUES (2, ‘S002’);
commit;
Insert into jrdv.ATTENDEESCHEDULE (DATA) values (‘{“_id”:5,”name”:”Shawn”,”company”:”WRIME AI”,”schedule”:[{“ATTENDEE_ID”:5,”attendee_sess_id”:”S005″,”code”:”S005″,”session_name”:”Machine Learning in Databases”,”time”:”2024-09-15T11:00:00″,”room”:”Room 105″,”speakers”:[{“speaker_sess_id”:”S005″,”speaker_session_speaker_id”:105,”speaker_id”:105,”speaker_name”:”Cetin”}]}],”_metadata”:{“etag”:”953321179FA5E16D26BB009D199EE3E1″,”asof”:”00000000007B54D9″}}’);
Insert into jrdv.ATTENDEESCHEDULE (DATA) values (‘{“_id”:6,”name”:”Don”,”company”:”RYTHM CORP”,”schedule”:[{“ATTENDEE_ID”:6,”attendee_sess_id”:”S006″,”code”:”S006″,”session_name”:”Spatial graph Programming”,”time”:”2024-09-16T09:00:00″,”room”:”Room 106″,”speakers”:[{“speaker_sess_id”:”S006″,”speaker_session_speaker_id”:106,”speaker_id”:106,”speaker_name”:”Ronald”}]}],”_metadata”:{“etag”:”B22F4BC1BC2FF28533180C0C1BFAA18F”,”asof”:”00000000007B54D9″}}’);
commit;
-
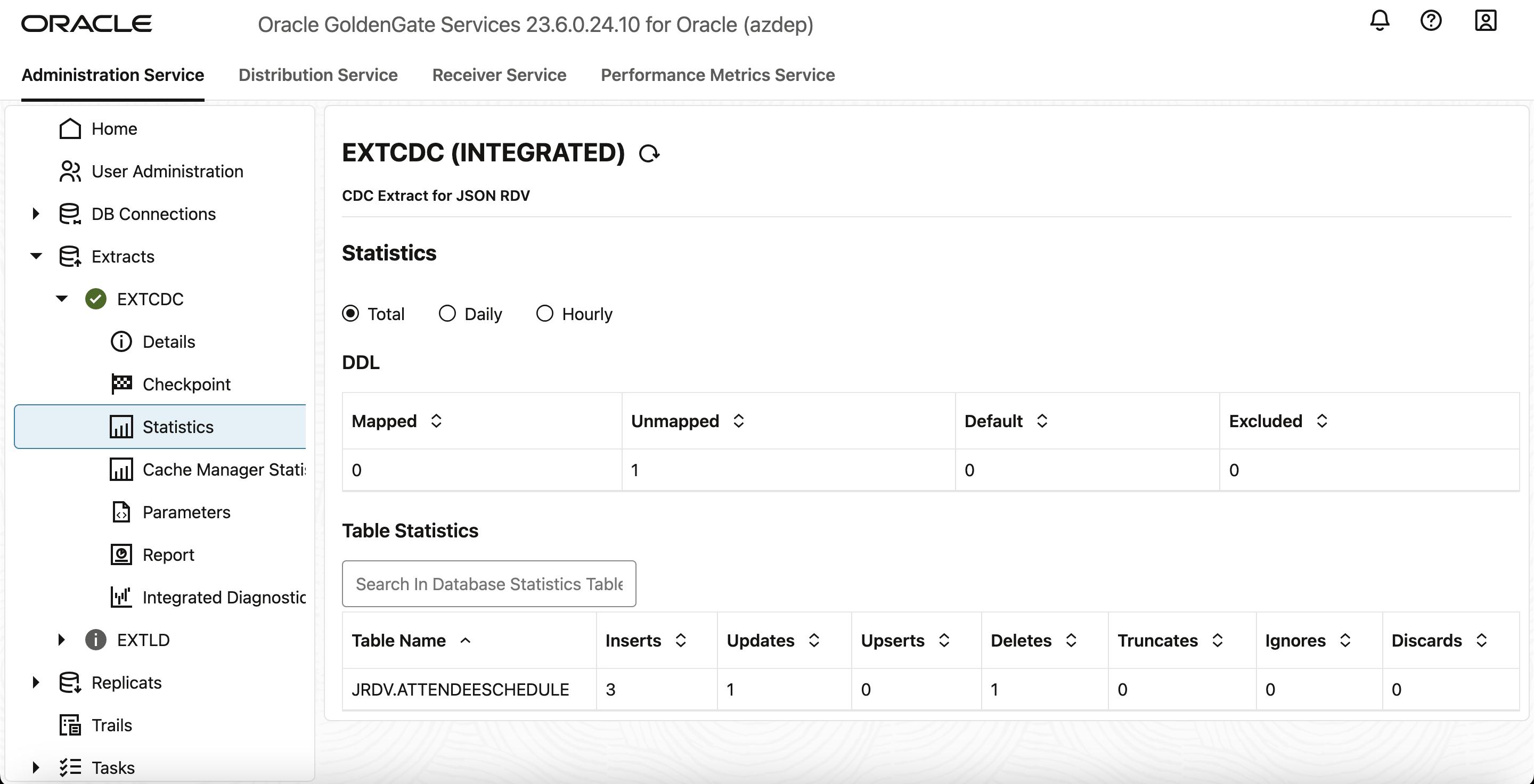
DMLがExtractプロセスによって取得されたことを確認します。「Extract in Administration Service」で、「Statistics」タブをクリックして、取得したDMLの数を表示します。
データ・ストリームからの変更データの消費またはプレビュー
最後に、ダウンストリーム・コンシューマ・アプリケーションを実行して、GoldenGateデータ・ストリーム・チャネルによって公開されたデータ・レコードを取得および検証します。
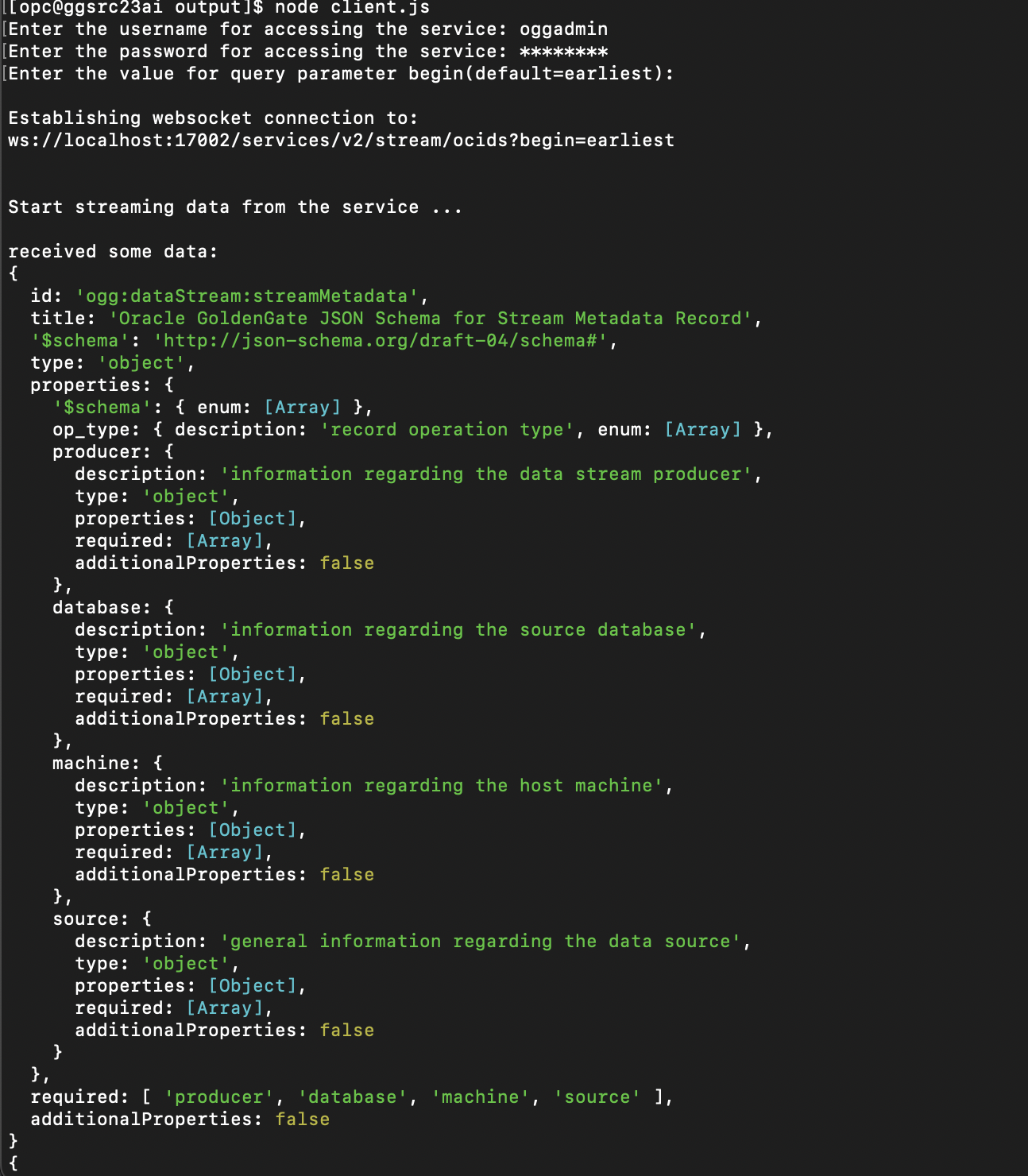
ソースOracleデータベースで作成されたJSONリレーショナル二面性ビューのペイロード内にDDLとDMLの両方を表示できる必要があります。

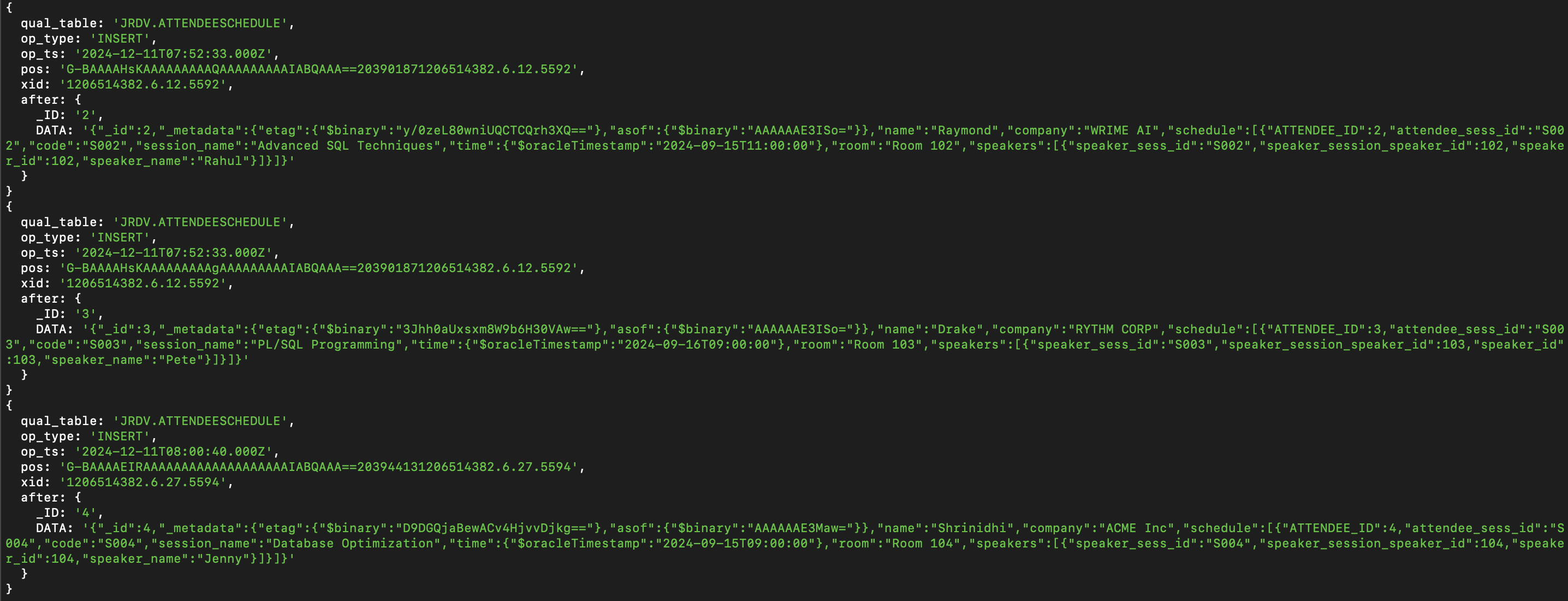
結論として、ビジネス・オブジェクトをOracle JSONリレーショナル二面性およびGoldenGate Data Streamsでレプリケートすると、データ・オブジェクトが一意であることを保証することで、データ製品が優先され、アプリケーション、トランザクション・ファブリック、データ/イベント・メッシュおよびデータ・ファブリックの信頼できる唯一の情報源になります。
