※ 本記事は、Sanjay Basu PhDによる”The role of GPU memory for training large language models“を翻訳したものです。
2023年10月20日
ディープ・ラーニングの急速な進化によって、コンピューティング能力の需要は鈍化しています。低精度フォーマットを処理するGPUコアなどの進歩により、GPUのコンピュート能力は劇的に向上しましたが、メモリ・システムはそのペースに追いついていません。メモリー・ウォールと呼ばれるコンピュートとメモリーの間のこの増大する不均衡が、ますます大きくなるディープ・ラーニング・モデルをトレーニングする際の重要なボトルネックとなっています。
メモリ・システムとコンピューティングの進化
ニューラル・ネットワーク内の基本的な計算を調べて、メモリー帯域幅がモデルのスケーリングを妨げる理由を理解する必要があります。密行列乗算は、ディープ・ラーニング・ワークロードの算術的強度を占めます。GPUの進化により、これらのコンピュートバウンドの行列操作に費やされる時間は、もはや主要な懸念事項ではありません。かわりに、パフォーマンスは、多くの場合、メモリーバウンド操作、動的ランダムアクセスメモリー(DRAM)からレジスタへのデータ移動によって制限されます。
最新のネットワークでは、いくつかのよく行われる操作により帯域幅不足します。バッチ基準のような正規化手法では、グローバル・データ・アクセスが必要であり、データの再利用が少なくなります。FLOPsのコストは安価ですが、頻繁なメモリー転送によって計算が停止する可能性があります。同様に、アクティベーション関数や重みの初期設定などのポイントワイズ操作も単一要素に触れるため、帯域幅コストが増加します。マルチクラスの予測に不可欠なSoftMax分類子は、数千の出力ニューロンにわたって正規化されます。簡潔な整流化線形ユニット(ReLU)によって、データの近傍性が低くなります。
メモリー・システムは、コンピューティングと同じ速さで進行していません。DRAMは、帯域幅ではなく、年間約15%の容量を拡張できます。データの移動を減らし、モデル・アーキテクチャおよびトレーニング・アルゴリズムでのデータの再利用を増やすことは、メモリー・ウォールと戦うことが不可欠です。ソフトウェアおよびハードウェア・コードは、ディープ・ラーニング・ワークロード用に特殊なアクセラレータおよびメモリー・サブシステムを構築するためにも、その約束を守ります。このようなイノベーションがないと、メモリ帯域幅は、これまで以上に大きく、より強力なAIモデルの実現を阻止し続けています。
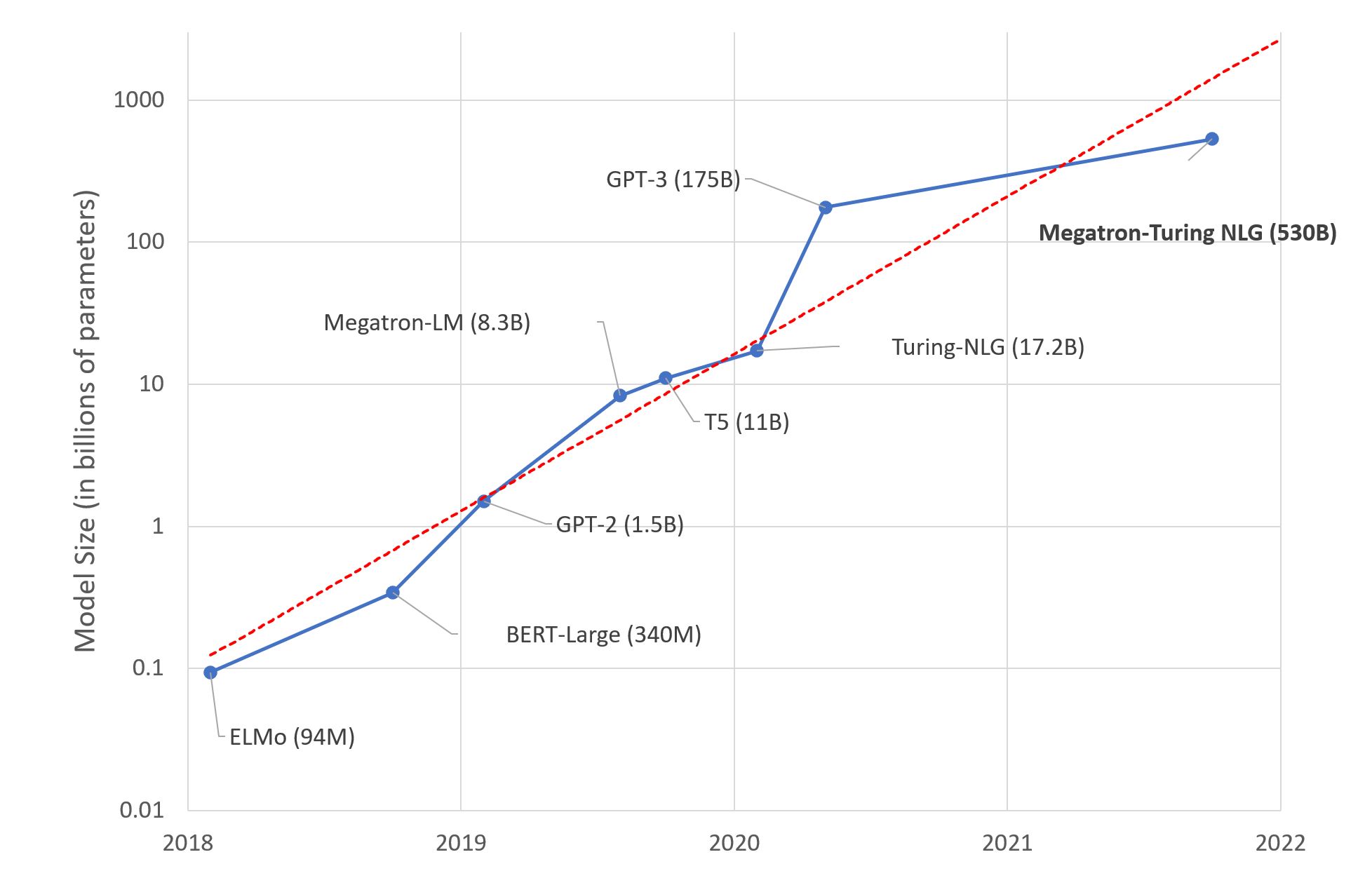
BERTのような自然言語処理(NLP)アーキテクチャの導入により、モデルのパフォーマンスが行列の乗算速度に依存しなくなる重要な瞬間が明らかになりました。当時、Volta100のようなGPUはコンピューティング能力の頂点を表していました。ただし、それ以来、モデルサイズの急激な増加は、純粋なFLOPSの進歩をはるかに超えています。
現代の自然言語モデルは、数百億のパラメータを上回ることがよくあります。たとえば、GPT-3には1750億のパラメータがあり、BERTの元の1億1,500万を超えるパラメータがあります。一方、GPUのパフォーマンスは、V100と比較して3倍から4倍程度しか向上していません。その結果、トレーニング・ランタイムは行列の乗算時間より優位ではなく、データ移動によるものです。
この相違は、計算のスループットを補完するために、メモリー帯域幅とキャッシュの重要性が増していることを強調しています。モデル・サイズの大きさで増加しているため、FLOPSではなくデータの移動が重要なボトルネックになっています。大規模なモデルから精度の向上を引き続き実現するため、メモリ・アーキテクチャ、データ・エンコーディング、移動削減アルゴリズムの革新が重要な優先事項となっています。過去10年の計算中心のスケーリングでは、2020年代のAIの進捗を後押しするために、メモリ、インターコネクト、ソフトウェアのより包括的なコード設計を行う必要があります。
コンピュートバウンドである行列の乗算は2018年にピークFLOPSの99%以上を占めていましたが、実世界のランタイムでは61%に過ぎませんでした。FLOPSを250倍から700倍削減する必要があるにもかかわらず、正規化やポイントワイズ機能などのメモリー・バウンド操作では、実行時間が40%増加しました。この比較では、算術スループットとメモリー帯域幅の間の不均衡が増大しています。
非常に大規模な最新のネットワークは、明らかにこのメモリの壁にぶつかっています。たとえば、産業推奨モデルに表を埋め込むと数百テラバイトに達し、言語モデルでは、重みのみに数百ギガバイトが使用されるようになりました。トレーニングと推論の時間は、計算ではなく、データ移動によって大きくなっています。根本原因は、GPU近くに十分なメモリー帯域幅および容量をコスト効率よくプロビジョニングできないことです。ムーアの法則によりFLOPSは急速に向上しましたが、メモリ・システムはそのペースに追いついていません。その結果、データは計算リソースを十分に利用するために十分な速さでALUにストリーミングできません。
この格差の意味
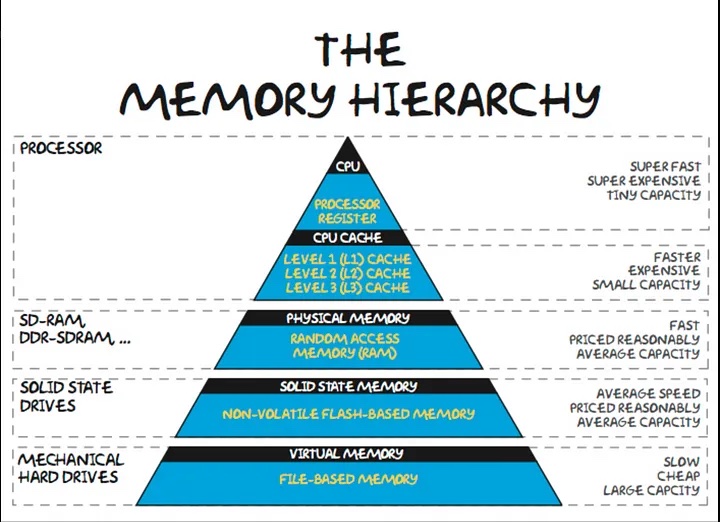
将来を見据えて、AIモデルの継続的なスケーリングには、メモリとインターコネクト・ファブリックを専用ソフトウェア・スケジューリングでコード設計する必要があります。安いFLOPSの改善がメモリを上回る時代が終わりました。新しいレベルのインテリジェンスを実現するには、回路からアルゴリズムへのクロススタック・アーキテクチャの進歩を通じて、メモリ・ウォールに革新的に対処する必要があります。メモリー階層によって、大規模なディープ・ラーニング・モデルのトレーニングに基本的なボトルネックが作成されます。オンチップSRAMは、最速のアクセスを提供しますが、容量は大幅に制限されています。何十億ものパラメータを持つモデルに十分なSRAMを専用にすると、非現実的なシリコン領域が消費され、プロセス・スケーリングからのリターンが減少します。
オフチップDRAMは、低コストで高い容量を実現しますが、レイテンシは100倍高くなります。ムーアの法則により長らくDRAMの高密度化が推進されてきましたが、コストは過去10年間にわたって停滞しています。モデル・サイズが爆発するにつれて、メモリーはサーバー・コストの50%以上を占めています。2016年から2022年まで、GPUのメモリ容量は5回拡大し、コンピュートは46回増加しました。
容量を超えるメモリー帯域幅によって、トレーニングのパフォーマンスが制限されます。HBMなどの高帯域幅のメモリ・スタックでは、この問題が軽減されますが、3Dパッケージングによる一般的なDRAMのGBあたりのコストが10倍から20倍になります。A100の最先端の帯域幅にもかかわらず、データ移動のボトルネックが原因で、モデルが使用可能なFLOPSが十分に利用されていないことがよくあります。最適化により、使用率は約60%に増加しますが、次世代のH100で6倍高いFLOPSではさらに多くのトリックが必要になります。
今後のアーキテクチャ・イノベーションは、大規模なキャッシュと分散共有メモリーを介したオフチップ・トラフィックを最小限に抑えることを目的としています。ただし、全体的に、スケーリングの計算はメモリー・システムに比べてはるかに大きく影響します。新しいアルゴリズムとハードウェアは、利用率を最大化するために、データの再利用、精度、および移動をターゲットとする必要があります。コアやFLOPSを追加するだけでは、算術とメモリのギャップが広がることはありません。ムーアの法則の終わりは、メモリ・ウォールをスーパースケールのモデルトレーニングにとって重要な障害としました。
AIでブレークスルーを実現するには、メモリー・ウォールの面でハードウェアおよびソフトウェア・コードを設計し直す必要があります。しかし、新しいアーキテクチャを探索するには、柔軟なインフラストラクチャが必要です。Oracle Cloud Infrastructure(OCI)は、次世代のGPUインスタンスと高速クラスタ・ネットワーキングを通じて、この実験のための強力なプラットフォームを提供します。研究者は、複数のGPUを備えた専用ベア・メタルおよび仮想マシン(VM)に直接アクセスして最適化されたシステムでアイデアをプロトタイプ作成し、最先端のスループットを実現できます。ワークロードは、低レイテンシのRDMAクラスタ・ネットワーク間でスケーリングでき、新しいレベルの分散トレーニング・パフォーマンスを実現できます。
最先端の機能とクラウド・インフラストラクチャの利便性を組み合わせることで、データ・サイエンティストはサーバーの管理ではなくAIの推進に集中できます。レガシー・テクノロジーの限界を超えてイノベーションを行うには、最も要求の厳しいディープ・ラーニング・ワークロードをOCIに今すぐ導入してください。AI専用の比類のない機能を備えたOracleは、メモリー・ウォールを克服するための画期的なアプローチを探るのに最適な環境を提供します。次世代の人工知能のロックを解除する鍵は、コンピューティング、メモリ、インターコネクトをどのように組み合せて設計するかを再考することです。
まとめ
Oracle独自のRDMAクラスタ・ネットワークは、クラウド・プロバイダのメモリー・ボトルネックに対する最適なソリューションを提供します。
Oracle Cloud無料トライアルをお試しください。300USドルの無料クレジットが付いた30日間のトライアルでは、Oracle Cloud Infrastructure Data Scienceサービスにアクセスできます。詳細は、次のリソースを参照してください:
-
OCI GPU製品とRDMAクラスタ・ネットワークについて読む
-
GitHubのOCI Data Scienceサンプル・リポジトリのすべてのファイルを含む完全なサンプル
-
サービス・ドキュメントを参照してください。
-
YouTubeプレイリストに関するチュートリアルをご覧ください。
-
LiveLabsで「data science」を検索し、試してください。
