The rapid evolution of deep learning has brought about an insatiable demand for computing power. While GPU compute capabilities have dramatically increased thanks to advances like GPU cores handling reduced precision formats, memory systems haven’t kept pace. This growing imbalance between compute and memory, known as the memory wall, has become a key bottleneck in training ever-larger deep learning models.
The evolution of memory systems and computing
We must examine the fundamental computations within neural networks to understand why memory bandwidth impedes model scaling. Dense matrix multiplications dominate the arithmetic intensity of deep learning workloads. The time spent on these compute-bound matrix ops is no longer the primary concern thanks to GPU evolution. Instead, performance is often limited by memory-bound operations, data movement from dynamic random-access memory (DRAM) to registers.
Several ubiquitous operations in modern networks are particularly bandwidth hungry. Normalization techniques like batch norms require global data access and reduce data reuse. Although cheap in FLOPs, their frequent memory transfers can stall computations. Similarly, pointwise ops like activation functions and weight initialization touch single elements, increasing bandwidth costs. The SoftMax classifier, vital for multiclass prediction, normalizes across thousands of output neurons. Despite their simplicity rectified linear units (ReLUs) lower data locality.
Memory systems haven’t progressed at the same rapid rate as computing. DRAM scales in capacity, not bandwidth, around 15% per year. Reducing data movement and increasing data reuse in model architectures and training algorithms is imperative to combat the memory wall. Software and hardware codesign to build specialized accelerators and memory subsystems for deep learning workloads also holds promise. Absent these innovations, memory bandwidth continues to throttle the realization of ever larger and more powerful AI models.
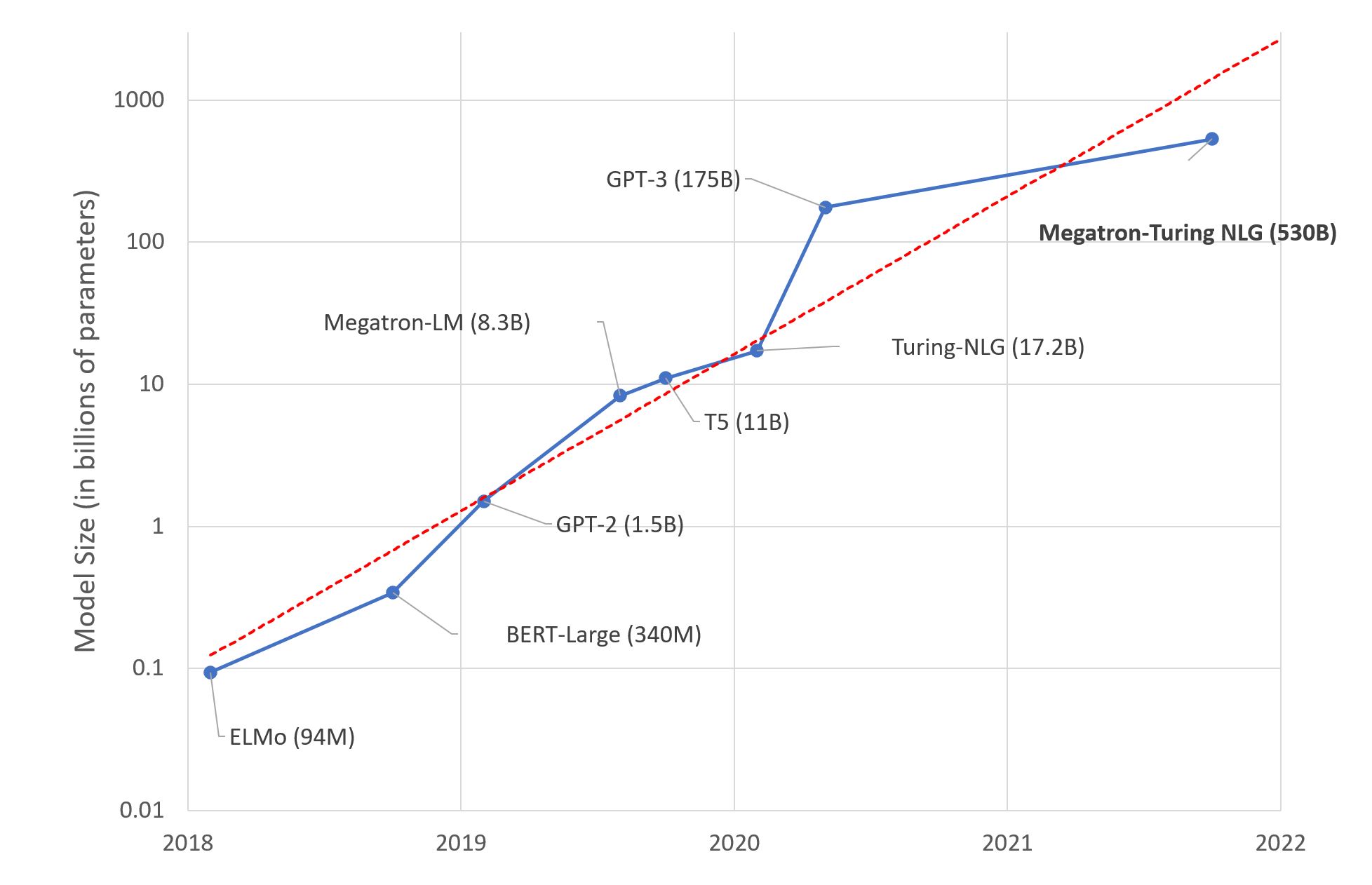
The introduction of natural language processing (NLP) architectures like BERT marked a pivotal moment where model performance became less dependent on matrix multiplication speed. At the time, GPU like Volta100 represented the pinnacle of computing power. However, since then, the exponential growth of model size has far outpaced advances in raw FLOPS.
Modern natural language models now frequently exceed hundreds of billions of parameters. For example, GPT-3 contains 175 billion parameters, over 1,500 times more than BERT’s original 110 million. Meanwhile, GPU performance has increased by only around 3–4 times over the V100. As a result, training runtime is no longer dominated by matrix multiplication time, but instead by data movement.
This divergence highlights the growing importance of memory bandwidth and caching to complement arithmetic throughput. With model sizes increasing by orders of magnitude, data movement, not FLOPS, has become the key bottleneck. To continue reaping accuracy gains from larger models, innovations in memory architectures, data encoding, and movement-reducing algorithms have become critical priorities. The compute-centric scaling of the past decade must give way to more holistic codesign of memory, interconnects, and software to fuel AI progress in the 2020s.
While compute-bound matrix multiplications accounted for over 99% of peak FLOPS in 2018, they contributed just 61% of real-world runtimes. Memory-bound operations like normalization and pointwise functions, despite requiring 250–700 times less FLOPS, consumed 40% more run time. This comparison highlights the growing imbalance between arithmetic throughput and memory bandwidth.
Extremely large modern networks have clearly hit this memory wall. For example, the embedding tables in industrial recommendation models can reach hundreds of terabytes, while language models now use hundreds of gigabytes for weights alone. Training and inference time is dominated not by computation now, but by data movement. The root cause is the inability to cost-effectively provision of sufficient memory bandwidth and capacity near the GPUs. Though Moore’s law has rapidly increased FLOPS, memory systems haven’t kept pace. The result is that data can’t stream to ALUs fast enough to utilize computational resources fully.
What this disparity means
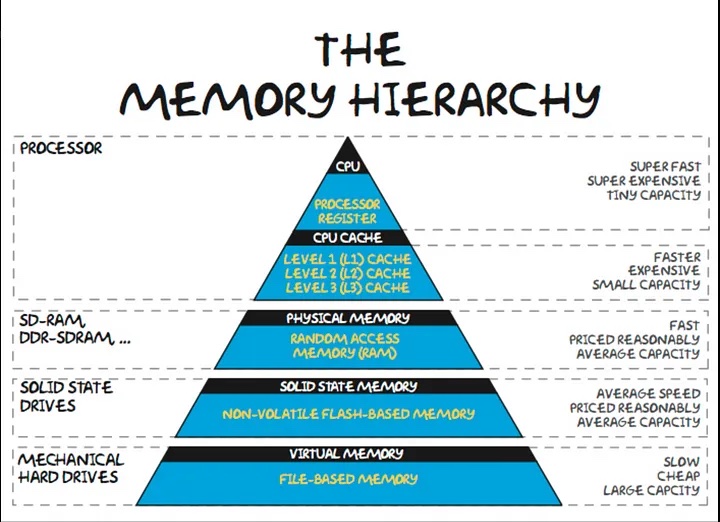
Looking ahead, the continued scaling of AI models requires codesigning memory and interconnect fabrics with specialized software scheduling. The era of cheap FLOPS improvements outpacing memory is over. To deliver new levels of intelligence, we must innovatively address the memory wall through cross-stack architectural advances from circuits to algorithms. The memory hierarchy creates fundamental bottlenecks in training large deep learning models. On-chip SRAM offers the fastest access but severely limited capacity. Dedicating sufficient SRAM for models with hundreds of billions of parameters would consume impractical silicon area, with diminishing returns from process scaling.
Off-chip DRAM delivers higher capacity at lower cost, but with 100-times higher latency. While Moore’s Law long-drove DRAM density, costs have stagnated over the past decade. As model size has exploded, memory now constitutes over 50% of server costs. From 2016 to 2022, GPU memory capacity expanded five times, while compute increased 46 times.
Beyond capacity, memory bandwidth limits training performance. High-bandwidth memory stacks like HBM mitigate this issue, but at 10–20 times the cost per GB of typical DRAM because of 3D packaging. Despite A100’s bleeding-edge bandwidth, models frequently under-utilize available FLOPS due to data movement bottlenecks. Optimizations increase utilization to approximately 60%, but six-times higher FLOPS in next-gen H100 will require even more tricks.
Future architectural innovations aim to minimize off-chip traffic through larger caches and distributed shared memory. But overall, compute scaling far outpaces memory systems. New algorithms and hardware must target data reuse, precision, and movement to maximize utilization. Simply adding more cores or FLOPS can’t overcome the widening gap between arithmetic and memory. The end of Moore’s Law has made the memory wall the primary obstacle to superscale model training.
To achieve breakthroughs in AI, we must rethink hardware and software codesign in the face of the memory wall. But exploring novel architectures requires flexible infrastructure. Oracle Cloud Infrastructure (OCI) offers a powerful platform for this experimentation through its next-generation GPU instances and high-speed cluster networking. Researchers can prototype ideas on optimized systems with direct access to dedicated bare metal and virtual machines (VMs) with multiple GPUs, delivering leading edge throughput. Workloads can scale across low-latency RDMA cluster networks, unlocking new levels of distributed training performance.
By combining cutting edge capabilities with the convenience of cloud infrastructure, data scientists can focus on advancing AI rather than managing servers. To innovate beyond the limits of legacy technology, deploy your most demanding deep learning workloads on OCI today. With unmatched capabilities purpose-built for AI, Oracle provides the perfect environment to explore groundbreaking approaches to overcoming the memory wall. The key to unlocking the next generation of artificial intelligence lies in reimagining how we architect compute, memory, and interconnects together.
Conclusion
Oracle’s unique RDMA cluster network provides the best solution to the memory bottleneck in cloud providers.
Try Oracle Cloud Free Trial! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service. For more information, see the following resources:
-
Read about the OCI GPU offerings and the RDMA cluster network
-
Full sample including all files in OCI Data Science sample repository on GitHub
-
Visit our service documentation.
-
Try one of our LiveLabs. Search for “data science.”
