Oracle Cloud Infrastructure (OCI) offers many unique services, including cluster network, an ultra-high performance network with support for remote direct memory access (RDMA). In our previous First Principles video blog, Building a High Performance Network in the Public Cloud, we explained how OCI’s cluster network uses RDMA over Converged Ethernet (RoCE) on top of NVIDIA ConnectX RDMA NICs to support high-throughput and latency-sensitive workloads. In this blog we discuss how we have further enhanced our offering to support superclusters, which are designed to scale to tens of thousands of NVIDIA GPUs without compromising the performance that customers have come to expect from our networks. The following video highlights some of the technologies undergirding superclusters.
Superclusters
Figure 1 illustrates superclusters with RDMA network connectivity. Each GPU node has 8 NVIDIA A100 Tensor Core GPUs with a total of 1.6Tbps (1600Gbps) of full-duplex connectivity to the network fabric. The network fabric is designed to be nonblocking and offers full bisection bandwidth to all hosts. (Bisection bandwidth is the minimum amount of bandwidth available between any two parts of the network.)
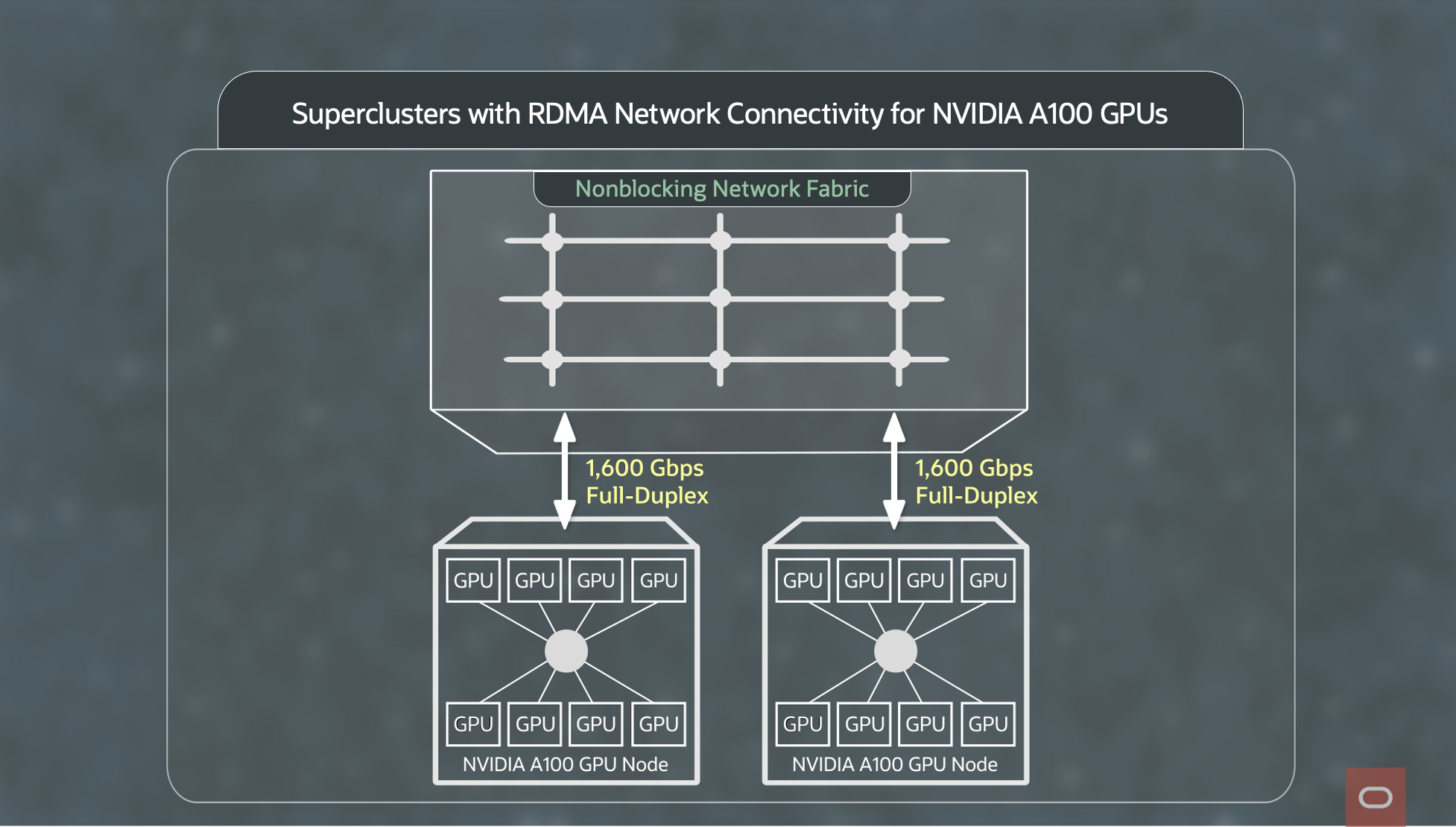
Figure 1: Superclusters with RDMA network connectivity
Figure 2 shows the topology of the network fabric. The network fabric uses a classic 3-tier Clos topology and easily scales to tens of thousands of GPUs. We explain how it scales in the above video.
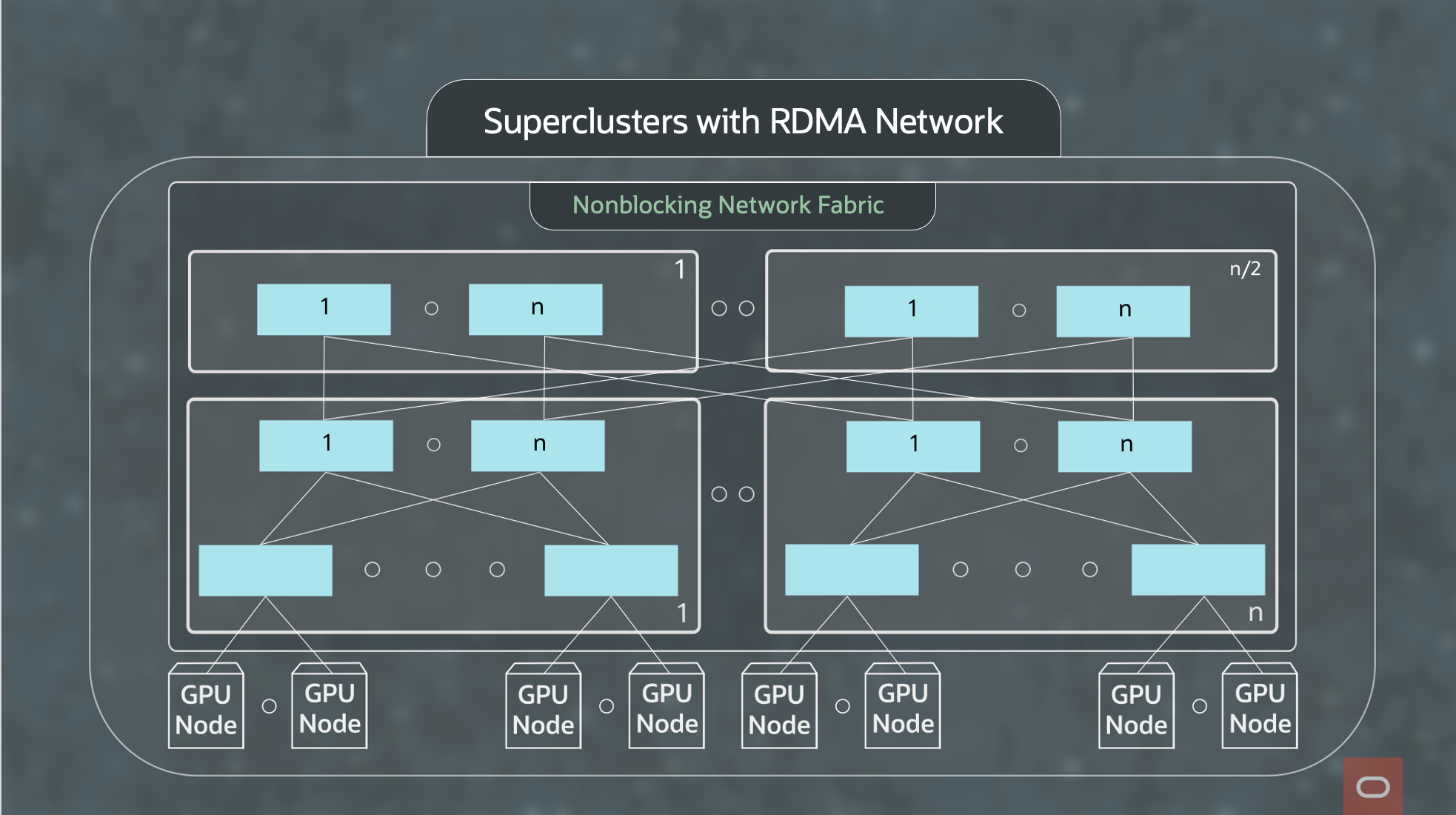
Figure 2: Superclusters with RDMA network fabric
Ultra-high performance at scale
Superclusters are a massive network with multiple petabits-per-second of bisection bandwidth. It was necessary to develop new techniques to deliver the same ultra-high performance at a much larger scale. OCI uses a multi-tier Clos topology to build a nonblocking network fabric that scales to tens of thousands of GPUs.
While a traditional GPU cluster fits within a few rows in one room of a datacenter, the large-scale supercluster can span multiple rooms (aka data-halls) within a building or even multiple adjoining buildings in a datacenter complex. The cable distance between two GPUs can be longer, which results in some packets going across these data-halls and incurring slightly higher latency. Even though the latency increase may only be a few microseconds, we wanted to minimize that. At OCI, we use two different techniques to do so:
- Provide “placement hints” to customers such that workloads using locality hints automatically experience lower average latency.
- Use “intelligent workload placement” to reduce the fiber distance.
The result of these two techniques is that workloads tend to operate across GPUs that are physically close to each other on the network, and customers experience the lowest possible latency.
The network supports Quality of Service (QoS) and sets aside lossless queue(s) for the GPU traffic. These queues have been further tuned to be aware of the longer cable distances, thus slightly higher network latency, while still providing lossless networking.
Conclusion
OCI has taken great care in prioritizing workload performance and in avoiding cutting corners at the expense of performance. Our goal has been and remains to deliver the highest performance at the largest scale possible. Customers can expect continued innovation from OCI in this space. To find similar exciting architectural deep-dives and insights, visit our First Principles homepage.
Related Blogs:
What’s next: training large language AI models at quintillions of operations on OCI
Oracle and NVIDIA solve the largest AI and NLP models
Running Applications on Oracle Cloud Using Cluster Networking
Large Clusters, Lowest Latency: Cluster Networking on Oracle Cloud Infrastructure

