This is the fifth article in our series about MySQL NDB Cluster replication. In many cases, it’s enough to replicate between two clusters located in different data centers or cloud regions to achieve the desired availability level and disaster protection. However, for some use cases, there is a need to replicate data between even more clusters, for example when it’s desirable to locate data closer to the users. This article will explain how to scale out the circular replication clusters described in the earlier article into a solution that keeps data in three, four, or even more clusters replicated. We sometime refer to such a topology as merge replication, whereas each cluster will replicate changes from every other cluster. Another popular term for this kind of topology would be mesh replication, that might better indicate how clusters interact with each other to pull data from those they are interested to synchronize with.
The merge replication topology is built using active-active and conflict detection which are unique features that enhance the standard MySQL replication mechanism.
The concepts described in the article build on those previously written about MySQL NDB Cluster replication:
- Single-channel replication
- Dual-channel replication for redundancy
- Circular replication for active-active clusters
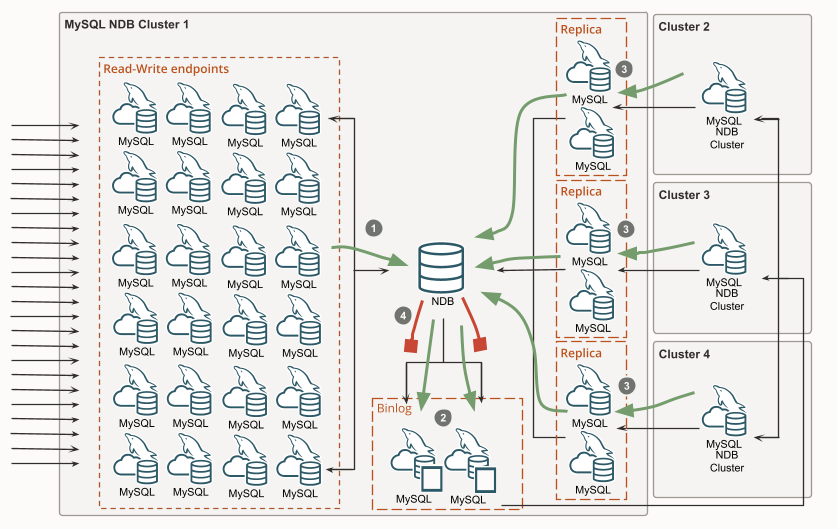
This diagram shows a logical view of the components required for merge replication of active-active clusters using redundant binlog and replica MySQL servers. There are four clusters where only the first cluster is drawn out while the others are collapsed. In this configuration, each cluster will replicate directly from every other cluster in the topology. To avoid endless data change propagation, the loop is terminated by configuring the binlog MySQL Server not to write changes coming from a replica MySQL Server, this is done using –log-replica-updates=0.
- The MySQL clients use the frontend MySQL servers to read and write data in NDB.
- Both binlog MySQL servers write the changes from NDB to their binary log in a redundant fashion. These two binlog MySQL servers will then act as the source for the three other clusters.
- The replica MySQL servers fetch and apply the changes from the three other clusters into the NDB data nodes.
- Both binlog MySQL servers are configured with –log-replica-updates=0 and will NOT write the replica changes applied to NDB to their binary log. The loop is terminated!
The same thing happens with changes done by the MySQL clients using the MySQL servers on all the other clusters, their changes will be written to the binary logs by the binlog MySQL servers in the cluster. When they are replicated to other clusters those changes will not be written to the binary log of those clusters. This data flow is not depicted in the diagram since it involves the same logical parts once again.
The number of binlog MySQL servers in each cluster is normally constant at two. Using two allows for highly available and redundant writing of the changes that occur in NDB to the binary log. These MySQL servers also act as the source for the other clusters, allowing replicas to connect, start from a given position, and continuously receive new changes as they occur. When there is a need for software upgrade, maintenance, or unplanned failure, replication can be switched over to use the other MySQL Server to allow continuously replicating data.
For each other cluster in the topology, there needs to be at least one replica MySQL Server which is responsible for connecting to the source and fetching changes. The most common approach is to have two replica MySQL servers for redundancy, each one configured to replicate from one of the binlog MySQL servers in the source cluster. At any given time, there should only be one replica MySQL Server actively replicating changes, the other one will be on standby waiting for the command to take over.
The process of switching over replication to use the other replica and binlog MySQL Server is commonly referred to as channel switchover. This slightly differs from standard MySQL replication terminology where we talk about different channels in the same MySQL Server while MySQL NDB Cluster replication the channel is meant to be another MySQL Server. When using MySQL NDB Cluster replication it’s always the default channel that is used and thus the switch is made to another set of MySQL servers.
The advantage of using merge replication compared to circular replication is that clusters can be added or removed without affecting another cluster. In this topology each cluster can be seen as fairly self-contained and in charge of where it replicates data from, which makes for a scalable solution.
Horizontal scalability of the system
The diagram shows only 24 frontend read-write MySQL servers which is far from the max limit of 240 in each cluster. By varying the number of MySQL Server instances in each cluster the capacity can be horizontally scaled in the topology, thus adapting to high as well as low traffic conditions. In the logical view, we have depicted the NDB data nodes as a single database, which is of course not entirely justifying the distributed database’s capability to process data in parallel on a large number of nodes. Scaling the number of NDB data nodes from 2 to 144 gives yet another scaling dimension allowing the cluster’s performance to be adapted to suit the applied load conditions. Scaling out the capacity of the binlog and replica MySQL servers can similarly be achieved by splitting their work and distributing it across more instances.
Production use
The merge replication topology described in this article, with three or four replicated clusters, is used in 5G cloud native core where it provides data storage for network functions that require the high availability, low latency, and performance provided when using MySQL NDB Cluster. Using Kubernetes the clusters are deployed to different geographical regions and availability zones from which they are replicated to each other.
Managing clusters of this scale is challenging regardless of using modern cloud environments like Oracle Cloud Infrastructure (OCI), sovereign clouds, private clouds, on-prem clouds, or any other kind of data center. For managing NDB clusters in the popular Kubernetes environment, Oracle provides the Kubernetes Operator for MySQL NDB Cluster. Another proven alternative is the MySQL NDB Cluster Manager (MCM) which once installed on the host instances, will manage the NDB data nodes, the NDB management server, and all the MySQL servers using the MCM shell from any place that can connect to the system.
Summary
This article explains how to create a merge replication topology suitable for scaling out active-active replication between more than two MySQL NDB clusters. While the topology may look complex at first glance, its core building blocks are the binlog MySQL Server and the replica MySQL Server which each implements a separate logical function in the cluster. The desired HA redundancy is achieved by deploying multiple instances in each functional role. This topology can also be described as a mesh replication where indiviual clusters can join or leave the topology.
More information
For more details on how to configure replication see:
- MySQL Docs – NDB Cluster Replication: Bidirectional and Circular Replication
- MySQL Docs – mysqld –log-replica-updates=[0|1]
- MySQL Docs – Introduction to NDB Operator
- MySQL Docs – MySQL Cluster Manager (MCM) User Manual
MySQL NDB Cluster is open-source and can be downloaded both in source and binary form at MySQL Downloads where you find both our newly released LTS version 8.4 as well as our innovation releases.
The source code is also available at the MySQL Server repository on GitHub and is frequently used by universities when studying the inner details of advanced high-performance distributed databases.
