In this blog, we will take a look at how MySQL HeatWave Lakehouse works with some of the popular file formats like Parquet and Avro.
MySQL HeatWave Lakehouse enables querying data in the object storage stored in a variety of file formats, such as CSV, Parquet, and Avro. Most databases also support exporting their data to one of these formats—CSV, Parquet, or Avro, and HeatWave Lakehouse can also load these exports (from Aurora, Redshift, MySQL, etc…) from object storage. Customers can query hundreds of terabytes of data in files in object storage and optionally combine it with transactional data in MySQL databases, without having to copy data from object storage into the MySQL database. MySQL HeatWave Lakehouse scales up to 512 nodes and allows customers query up to half a petabyte of data.
MySQL HeatWave is a fully managed database service that provides OLTP, OLAP, machine learning, and data lake querying capabilities. It uses machine learning to automate various aspects of the database services which reduces the burden of tuning and database management. It is the only cloud database service that combines transactions, analytics, automated machine learning, and data lake querying into a single MySQL database system.
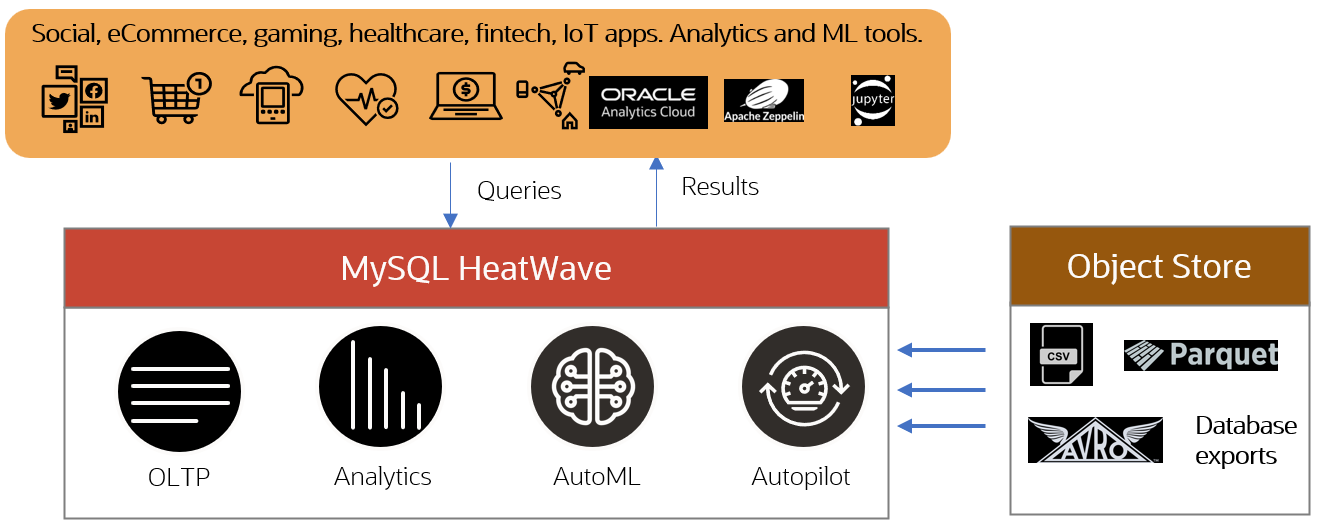
When working with data in an object storage, customers face the challenge of processing data in multiple file formats. Different applications and producers, like telemetry services, IoT sensors, streams, connected devices, etc… can send their data in CSV, Parquet, Avro, and other file formats. CSV (Comma Separated Value) files are text files and store their data row-wise. Parquet is a binary file format—it stores its data in a hybrid columnar format; which means that the data is organized by columns, rather than rows (as in CSV files). Parquet also supports compression.
Information on Parquet and Avro file formats
Parquet
Parquet is a popular and an efficient open-source, column-oriented file format, where data is stored by columns rather than rows. This allows for efficient compression, better query performance, increasing cache utilization, and minimize unnecessary reads when retrieving selected columns, making it highly suitable for analytical workloads and big data processing.
Parquet is used in both Big Data frameworks and in Machine Learning and Data Science workflows.
- Data processing: Preferred by Apache Spark for big data processing. Similarly, Apache Hive, a data warehousing and SQL-like query language for Hadoop, often uses Parquet as its storage format.
- Data integration and ETL: When it comes to moving and transforming data, Parquet becomes an ideal choice because of efficient data retrieval and compressed storage. Data Integration tools such as Apache NiFi and ETL frameworks like Talend, they all support and use Parquet format.
- Several Python libraries like Pandas, PyArrow, and PySpark can read Parquet files. This makes Parquet a popular choice for data manipulation and analysis in data science workflows. It is therefore important that a Lakehouse solution provide support for reading and querying data in Parquet files too.
Several cloud data warehousing, data lake services, and cloud providers support and use Parquet as a columnar storage format for data ingestion, improved query performance, and with analytics tools. Additionally, some data warehousing and data lake services use the Parquet format for time-backup capabilities, both for efficient recovery and to save on storage space and costs. For example, Amazon Aurora uses only the Parquet format for backup-and-restore.
Avro
Avro, like CSV, stores its data as rows. However, it is different in many other respects. It also is a binary format. It also stores the data’s schema as JSON, which makes it easy to deserialize and interpret the data—because of this rich metadata. Also, an Avro format file is internally split into blocks so that these blocks can be processed in parallel, allowing scale-out processing. Avro is row-oriented, and it is therefore used in several publisher-subscriber workflows and where data is read off a stream by a subscriber and written to object storage, from where the data is used by other applications. Avro’s support by several languages also makes it a popular choice when communicating between different applications and processes. Microservices and log aggregation are two other popular use-cases where Avro is a preferred format.
Avro is also the data format of choice in Lakehouse table formats such as Apache Iceberg.
This table compares the three file formats across a spectrum of criteria.
| CSV |
Parquet |
Avro |
|
| Popularity |
Very high |
High |
High |
| Physical data layout |
Row-oriented |
Column-oriented |
Row-oriented |
| Optimized for |
Writes |
Reads, analytics |
Writes, binary serialization |
| Compression |
None |
Very good |
Good |
| Schema evolution |
None |
Good |
Very good |
| Size of same TPC-H table |
Large |
Very small |
Small |
| Load speed into HeatWave Lakehouse |
Good |
Good |
Good |
| Human readable |
Yes |
No |
No |
| Complex/nested fields |
No |
Yes |
Yes |
| Typical platforms (not limited to) |
Most DBs and applications |
Hadoop, Impala, Spark, Athena, Redshift, BigQuery,… |
Hadoop, Spark SQL, Kafka, OracleDB, Azure, BigQuery, … |
HeatWave Lakehouse has support for these open file formats widely used in data lakes.
- Data load: These benefit from the same highly scalable and performant data load architecture as is employed for CSV files.
- Data query: We deliver identical data query performance across all supported file formats and data sources.
- Feature set: HeatWave Lakehouse supports a similar feature set across all file formats, adding features when facilitated by metadata.
Users can make their choice for file format that best suits their application and business needs without worrying about load or query performance or feature set supported by HeatWave Lakehouse.
HeatWave Lakehouse supports different compression algorithms available in Avro—deflate, snappy, as well as uncompressed Avro files. The same high-level of load performance is present for Avro as with other file formats. Query performance is identical across all supported file formats.
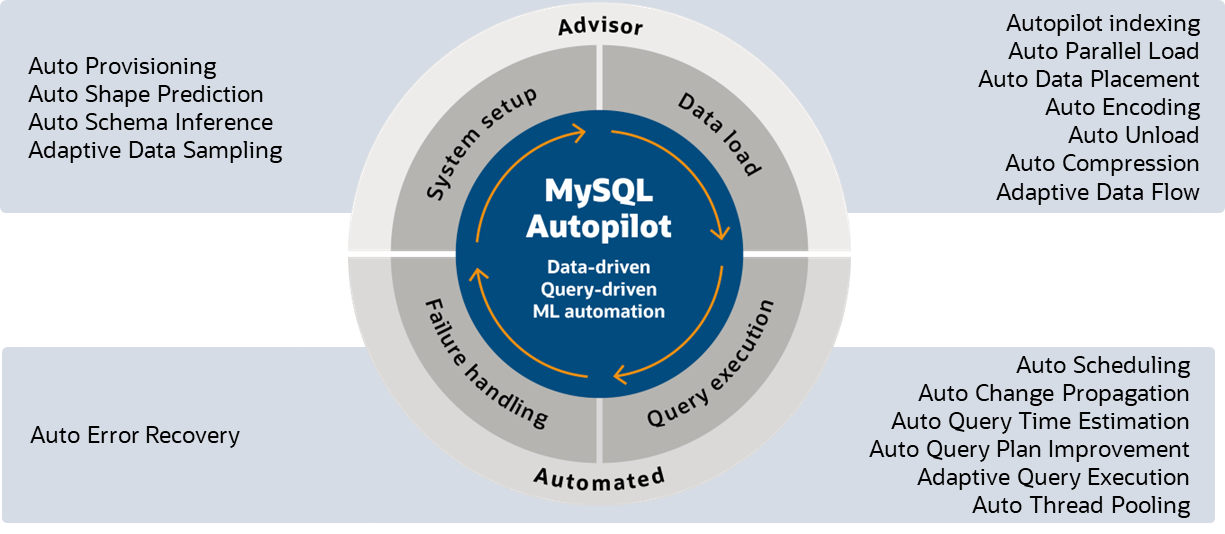
MySQL Autopilot automates many tasks associated with data loading and achieving high-performance querying
Machine Learning on Object Storage data
Customers can now train, predict, and explain their machine learning models on data loaded from object storage—in both OCI and AWS, and this support includes data in CSV, Parquet, and Avro files (in addition to data from database exports). HeatWave AutoML uses a common set of APIs to Train, Predict, and Explain a model, irrespective of whether the data is in object storage or in the database. This simplifies the tasks for the user as they have a single, unified APIs to perform machine learning. Once loaded into HeatWave from object storage, users can create a model, train the model, and use this trained model to make predictions. The interactive console simplifies the process of creating models, explaining them, deriving inferences, and performing scenario analysis so that even a non-technical user can easily use machine learning.
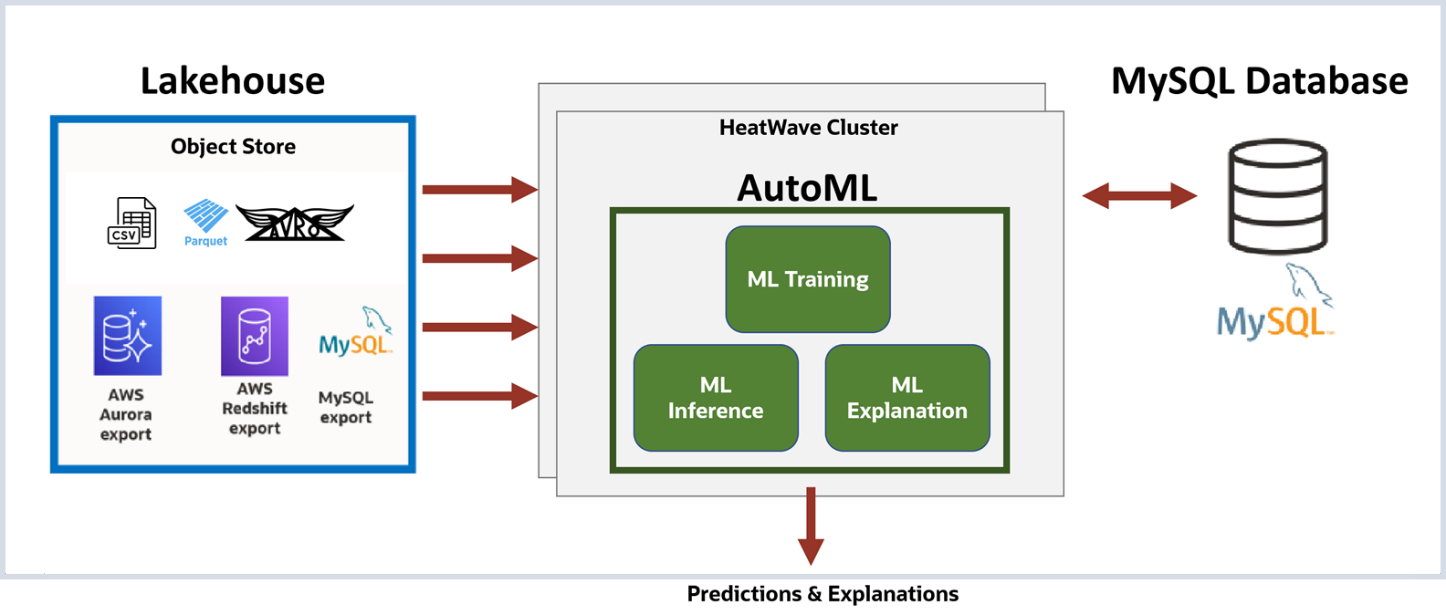
Machine learning on object storage data with HeatWave AutoML
Loading Parquet and Avro data into HeatWave Lakehouse
In this example, we use a table from the TPC-H schema—CUSTOMER— in object storage. This could be a single file or multiple files, and MySQL Autopilot can work with different options. More information is available in the documentation.
To call Autopilot, we will set some parameters, like the database(s) we want to load data into, the list of tables we want to load data into, and information about the location and format of the files containing data for those tables.
In this case, we will load data from the customer.pq file into the customer table, that we will name customer_ext.
--Set the database name(s) to be loaded.
mysql> SET @db_list = '["tpch"]';
-- Set the external table parameters that provide information on how data is organized.
-- We can specify several databases and tables, with each table having its own options.
mysql> SET @ext_tables = '[{
"db_name": "tpch",
"tables": [{
"table_name": "customer_ext",
"dialect": {
"format": "parquet"
},
"file": [{
"par": "https://objectstorage.../customer.pq"
}]
}]
}]';
-- Set the options and invoke Auto Parallel Load with the specified options.
mysql> SET @options = JSON_OBJECT('external_tables', CAST(@ext_tables AS JSON));
mysql> CALL sys.heatwave_load(@db_list, @options);
After Auto-parallel load has finished running, it generates a script that contains all the commands required to create the schema if it does not exist; create the table, and load data from object storage into the table. Assuming enough capacity in the cluster, it can also run the generated script automatically and load the tables (in `normal` mode). As you can see, Autopilot also used the metadata information available in the Parquet file to extract the column names and data types. Furthermore, Autopilot used its Adaptive Data Sampling and Auto Schema Inference capabilities to make accurate inferences about the precision of these columns.
+-----------------------------------------------------------------------------------+
| Load Script |
+-----------------------------------------------------------------------------------+
| CREATE TABLE `tpch`.`customer_ext`( |
| `C_CUSTKEY` bigint, |
| `C_NAME` varchar(20) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `C_ADDRESS` varchar(40) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `C_NATIONKEY` int, |
| `C_PHONE` varchar(15) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `C_ACCTBAL` decimal(15,2), |
| `C_MKTSEGMENT` varchar(10) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN', |
| `C_COMMENT` varchar(116) COMMENT 'RAPID_COLUMN=ENCODING=VARLEN' |
| ) ENGINE=lakehouse SECONDARY_ENGINE=RAPID |
| ENGINE_ATTRIBUTE='{"file": [{"par": "https://objectstorage.../customer.pq"}], |
| "dialect": {"format": "parquet"}}'; |
| ALTER TABLE /*+ AUTOPILOT_DISABLE_CHECK */ `tpch`.`customer_ext` SECONDARY_LOAD; |
+-----------------------------------------------------------------------------------+
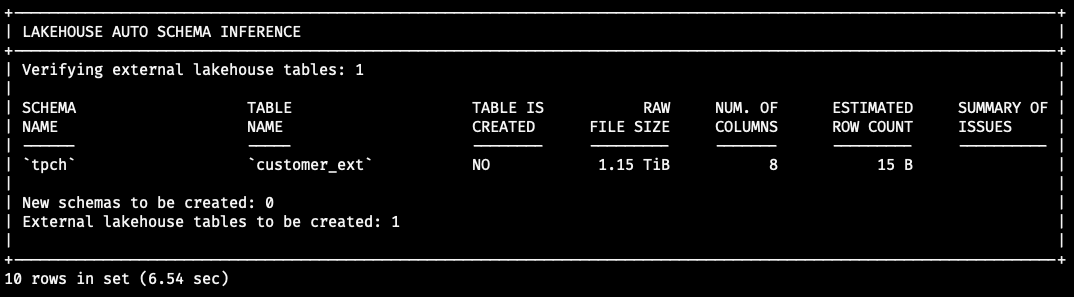
You can run these statements as-is, or modify them, to change the column name, for example. Once these statements finish running, the table is ready to be queried in HeatWave.
Once loaded into HeatWave, this table is available for querying using standard MySQL commands.
Links:
- HeatWave Lakehouse
- HeatWave Lakehouse documentation
- Loading data from external sources: documentation
- Blog: Using MySQL Autopilot with HeatWave Lakehouse
- Blog: Getting Started with HeatWave Lakehouse
- Oracle CloudWorld: HeatWave Lakehouse performance demos
