HeatWave AutoML progress tracking can be used to monitor the progress of training, inference and explanations for HeatWave AutoML. The goal of progress tracker is to provide visibility to the end user about the execution status of the HeatWave AutoML operations, – e.g, how much an operation has progressed, which stages have been completed, any error has happened during the operation, or the operation has been aborted.
HeatWave AutoML operations such as model training and prediction explanations can take a significant amount of time for large datasets. This is because training incorporates automation of multiple steps, including preprocessing, row and column selection, hyperparameter optimization, and the final model build. Additionally, the time taken at each stage varies by the data set – hence, it may not be clear to the end user as to when the operation is likely to finish. Similarly, explaining a prediction also requires large amount of computation because column values must be iteratively substituted to compute each column’s importance to the prediction. Therefore, progress tracking feature has been added which addresses this challenge and provides visibility into these machine learning operations. Note that while progress tracker can be used to track progress of any HeatWave AutoML operation, it makes most sense to track the progress of these two operations.

Progress Tracker: Usage for ML_TRAIN
The progress tracker can be invoked on HeatWave AutoML using SQL queries. To initiate progress tracking, the user needs to open two MySQL client terminals. The first terminal is used to start the machine learning query, while the second terminal is used to monitor progress of the operation.

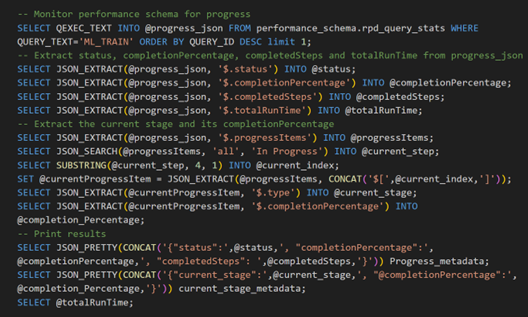
The first query selects progress metadata from performance schema and the subsequent queries extract high-level information from the progress metadata such as status, completionPercentage, completedSteps, current_stage, etc.
The snaphots provided below show progress status at various stages of query execution. These are accessed by repeated invocations of the performance schema.
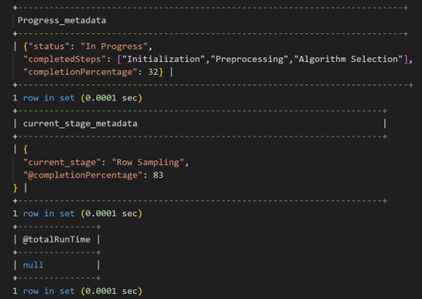
stages are 100% completed, Row Sampling stage is 83% completed
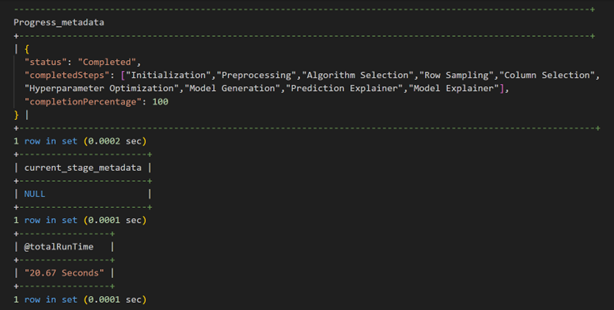
The progress metadata above shows that training has been 100% completed, and the completed steps are:
- Initialization, Preprocessing, Algorithm Selection, Row Sampling, Column Selection, Hyperparameter Optimization, Model Generation, Prediction Explainer, Model Explainer
The progress metadata also shows that the total training runtime was 20.67 Seconds.
Progress Tracker: Usage for ML_EXPLAIN_TABLE
To use the tracker on ML_EXPLAIN_TABLE, the user needs to open two MySQL client terminals. The first terminal is used to start the machine learning query, while the second terminal is used to monitor progress of the operation.

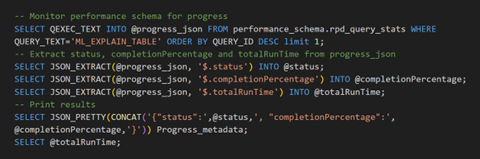
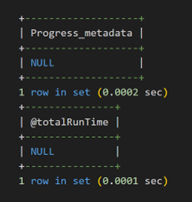
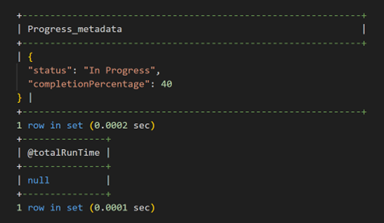
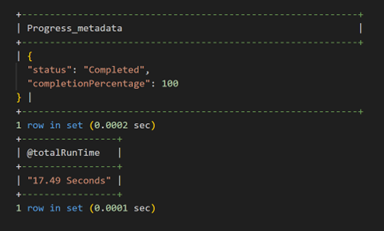
The progress metadata shows that explain table has been 100% completed, and the total runtime was 17.49 seconds.
One can also view the details of the progress tracker in the video below:
In summary, prior to the introduction of progress tracking, users were not able to monitor the progress of long running ML queries such as ML_TRAIN or ML_EXPLAIN_TABLE. With the introduction of the progress tracker, users now gain better visibility into the progress of such queries.
