Summary
In the previous blog post a new feature to configure BLOB storage in a table was introduced, designed to help reduce memory footprint. The post explored how to configure and monitor table memory, as well as the the impact BLOB columns can have in MySQL Cluster’s NDB storage engine. In this second part of the series, the performance benefits of configuring BLOB storage are explored, focusing on the inline and part aspect of NDB BLOB models, and the batching at the API level. The goal is to show that by optimizing BLOB storage, it is not only possible to save memory but also to improve the overall performance of the database through faster query execution and reduced latency. Hopefully by the end of this post, readers should have a deeper understanding of how to optimize BLOB storage and be able to apply these best practices to their own MySQL Cluster deployments.
Tuning BLOB Storage for Performance
To get the most out of BLOB storage in MySQL Cluster, it’s essential to understand the various tuning options available. By adjusting these parameters, BLOB storage can be optimised to meet the specific needs of the application and improve overall performance.
There are four key tuning options to consider:
- BLOB_INLINE_SIZE: This parameter controls the size of the BLOB that is stored inline in the table. Adjust this value to balance the trade-off between memory usage and performance. A larger value means more data is stored inline, reducing the need for additional storage and improving performance, but also increases row’s memory usage. This is a COMMENT NDB_COLUMN option.
- ndb-blob-read-batch-bytes: This parameter determines the amount of data that is read in batch within a single NDB transaction. By increasing this value, it is possible to reduce the number of round trips between the application and the database if the data being transfered needs to be split into multiple batches. With lesser batches there is more performance (i.e., less round-trips), but too high value for quite sizeable BLOB values can make bad use of the network.
- ndb-blob-write-batch-bytes: Similar to the read batch size, but this parameter controls the amount of data that is written in batch within a single NDB transaction.
- ndb-replica-blob-write-batch-bytes: This parameter is specific to replicated environments and controls the amount of data that is written in batch when applying a replicated NDB transaction.
Among these parameters, the ndb-replica-blob-write-batch-bytes was not addressed since this post did not evaluate replication performance. However, the effect is the same as using ndb-blob-write-batch-bytes, except it is used by the applier thread instead of the SQL session threads.
Benchmarking
To demonstrate the performance benefits of tuning BLOB storage, a high-performance server and a popular benchmarking tool were used. The test environment consisted of a Dell EMC PowerEdge R7525 server, equipped with dual-socket AMD EPYC 7742 processors, 2 TB of RAM, and four 3TB NVMe SSDs (only 2 NVMe drives were used, as it is enough for the use case). This powerful server provides a robust platform for testing the performance of MySQL Cluster with various BLOB storage configurations.
The benchmarking tool was Sysbench, a widely-used open-source utility, employed to simulate various workloads and measure the performance of MySQL Cluster. Custom scripts for Sysbench were created, that specifically tune the BLOB_INLINE_SIZE option, which allow testing the impact of different inline sizes on performance.
Test Setup
The test setup consisted on two NDB data nodes and sixteen MySQL servers, both running version MySQL Cluster 9.4.0 innovation release.
Each NDB data node used the following main parameters:
NoOfReplicas = 2
DataMemory = 512G
SharedGlobalMemory=2G
NumCPUs = 64
MaxNoOfExecutionThreads=64
NoOfFragmentLogParts = 32
# Transporter NDB configuration
TotalSendBufferMemory=128M
# Prevents disk-swapping
LockPagesInMainMemory = 1
# Allocates sufficient REDO log to cope with sysbench prepare step
RedoBuffer=256M
FragmentLogFileSize=32M
NoOfFragmentLogFiles=512
TimeBetweenLocalCheckpoints=20
On the other hand, each MySQL server used the following main parameters:
ndbcluster
ndb-batch-size=65536 # 64KB (default) | 4194304 # 4MB (tested)
ndb-blob-write-batch-bytes=65536 # 64KB (default) | 4194304 # 4MB (tested)
ndb-blob-read-batch-bytes=65536 # 64KB (default) | 4194304 # 4MB (tested)
For the full configuration, see in this Gist link.
The test runs varied the size of BLOB values across 8 different tables, with the total data volume approximatelly matching the available data memory (512GB). Each table contained a single BLOB column to accommodate the data under test.
Below is a list of the BLOB values sizes tested, along with their respective BLOB_INLINE_SIZE (“inline“) configuration:
- BLOB 4KB byte (inline = 4096 bytes)
- MEDIUMBLOB 24KB byte (inline = 24576 bytes)
- LONGBLOB 64KB byte (inline = 29736 bytes [max])
- LONGBLOB 448KB byte (inline = 29736 bytes [max])
N.B.: The default inline size is always 256 bytes (exception exists for JSON columns). See Part 1 of this series for more information.
Each Sysbench thread operation performed 90% of point select queries and 10% updates to the BLOB value. An increasingly number of concurrent Sysbench threads (representing concurrent users or connections) defines each run scenario, benchmarking the deployment’s scalability. These threads simulate concurrent users executing the most possible transactions (i.e., no rate limiting).
The tagged words default and inline indicate whether the BLOB column was configured with BLOB_INLINE_SIZE (inline) or was not (default). These tags are used throughout the text: inline means the BLOB column is configured to fit the maximum possible of the data in the main table row, while default means only part of it (256 bytes to be precise) fits in the main table and the rest is stored in the Parts table. If the value is too big to fit in the main table row – as is the case with 64KB and 448KB values (NDB has a maximum of 30K bytes per row) – then the maximum possible is stored the main table’s row, and the remainder is goes into the Parts table. Refer to the NDB string storage requirements and to Part 1 of this series for more information.
Results
As aforementioned, the results will show the comparison between the inline and the default version of the BLOB column. For BLOB values under the 30K byte mark, i.e. 4KB and 24KB, a comparison with VARBINARY is also provided, illustrated with the binary keyword.
Below are the results for 4KB BLOB. The tables were created in a similar manner as shown in the subsequent listing.
CREATE TABLE sbtestY (/* key data */, data BLOB COMMENT “NDB_COLUMN=BLOB_INLINE_SIZE=4096”) ENGINE = NDB;
CREATE TABLE sbtestZ (/* key data */, data VARBINARY(4096)) ENGINE = NDB;
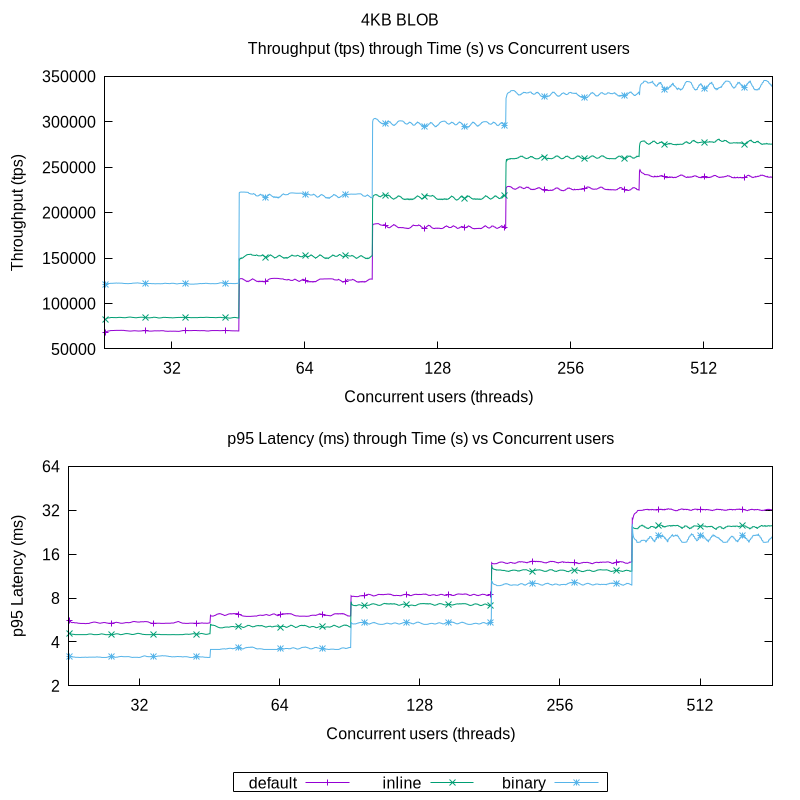
As the results show, there is around 15% to 20% increase in throughput using inline versus default. On the other hand, using binary increases the throughput by approximatelly 50% over inline. It can also be seen that the throughput begins to be bounded with 512 concurrent users, and that is due to prohibitively values of latency, which should be close to or under 10ms. That subject is explored further in the Analysis section.
Following are the results for 24KB BLOB (using MEDIUMBLOB data type). The tables were created in a similar manner as shown in the subsequent listing.
CREATE TABLE sbtestY (/* key data */, data MEDIUMBLOB COMMENT “NDB_COLUMN=BLOB_INLINE_SIZE=24576”) ENGINE = NDB;
CREATE TABLE sbtestZ (/* key data */, data VARBINARY(24576)) ENGINE = NDB;
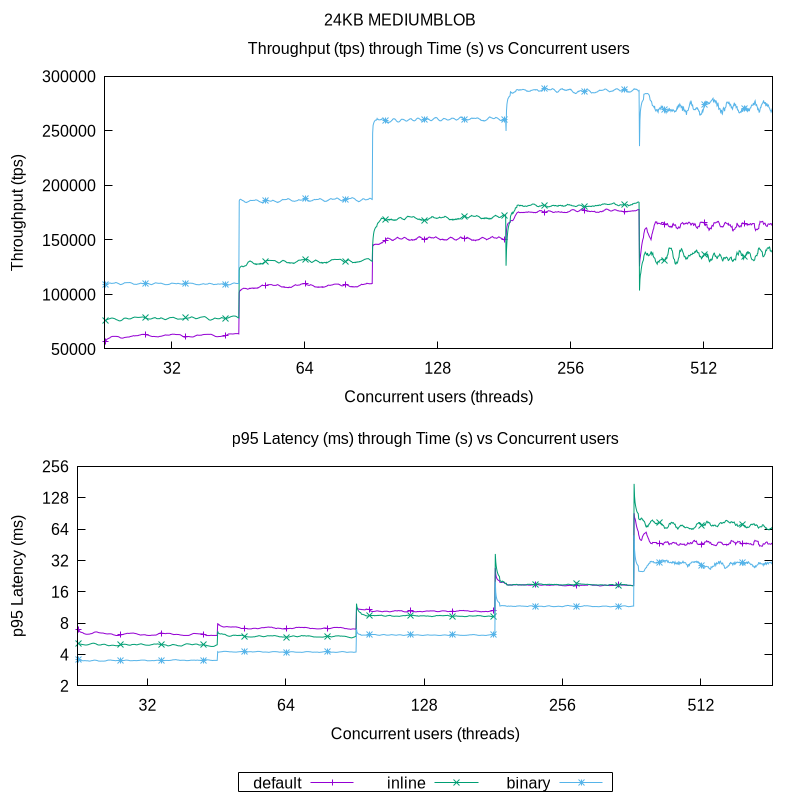
As with the previous result, the 24KB BLOB performs between 10% to 33% better with inline versus default. But, with 256 concurrent users, the latency of the queries converges to high values and hence the throughput. For 512 users, a reduced throughput is observed therefore indicating a scale-up limit. While with binary the same 30% to 50% increase in throughput can be be seen, the scale-up limit is also observed through the increased latency and the throughput being bounded (approximatelly the same with 256 and 512 users).
Now are the results for 64KB BLOB (using LONGBLOB data type). The tables were created in a similar manner as shown in the subsequent listing.
CREATE TABLE sbtestY (/* key data */, data LONGBLOB COMMENT “NDB_COLUMN=BLOB_INLINE_SIZE=29736”) ENGINE = NDB;
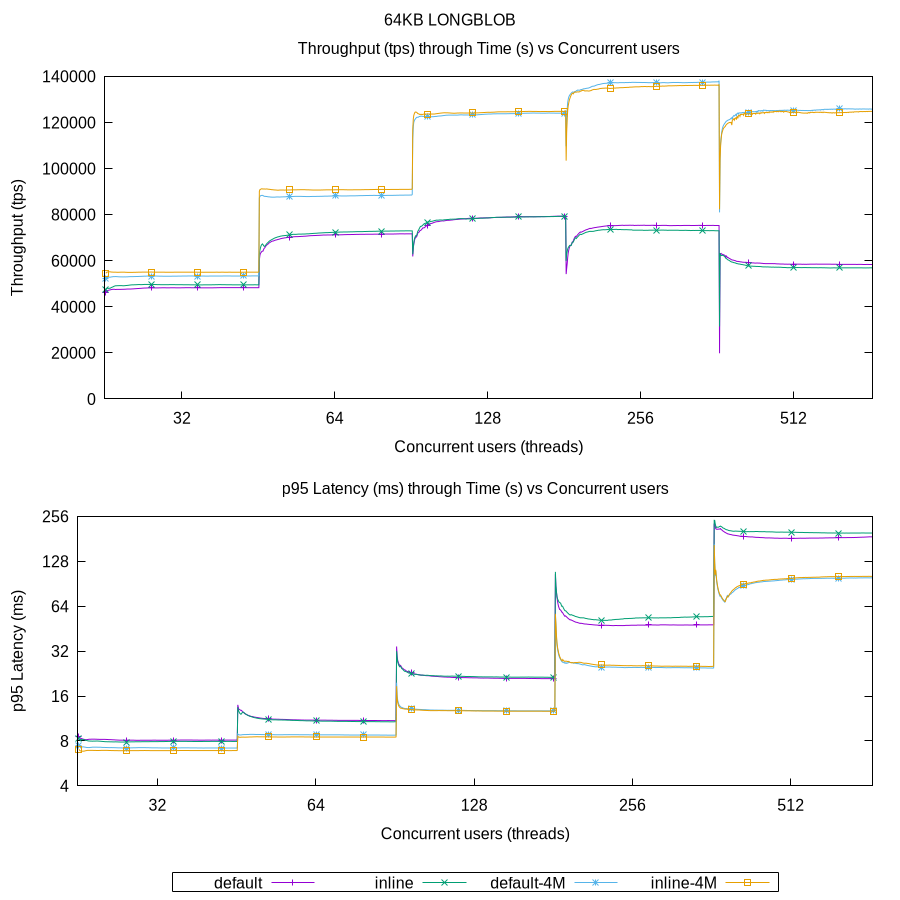
Now with the 64KB BLOB, there are two new lines included, default-4M and inline-4M, meaning that the MySQL server parameters ndb-blob-read-batch-size, ndb-blob-write-batch-size and ndb-batch-size were set to 4MB (see above the configuration).
It can now be observed that, even with 128 concurrent users, there are healthier latency values with a larger batch size for BLOB in comparison with the default batch size. This translates to continuously higher throughput from 32 to 128 concurrent users, increasing approximatelly 60% from 32 to 64 users and 33% from 64 to 128 users. However, the throughput becomes bounded due to the increasingly latency of the transactions, increasing only 5% from 128 to 256/512 users.
With more bandwidth available to each connection, i.e., less concurrent users (32 and 64), a slight increase of throughput can still be obtained using inline versus the default. On the other hand, there can be seen an improvement of throghput of about 5% for 32 users between inline-4M and default-4M, even when that is not clear in the latency graphs (it is around the same). Thus, it suggests that more data through the wire is increasing the transaction rate. However, with more pressure in the system a convergence can be seen, thus showing that inline versus default makes little difference. But it is clear that the 4MB of increased batch size allows more than 50% of better throughput and latency values.
Finally, the results for 448KB BLOB (using LONGBLOB data type) are provided. The tables were created in a similar fashion as the ones for 64KB (above).
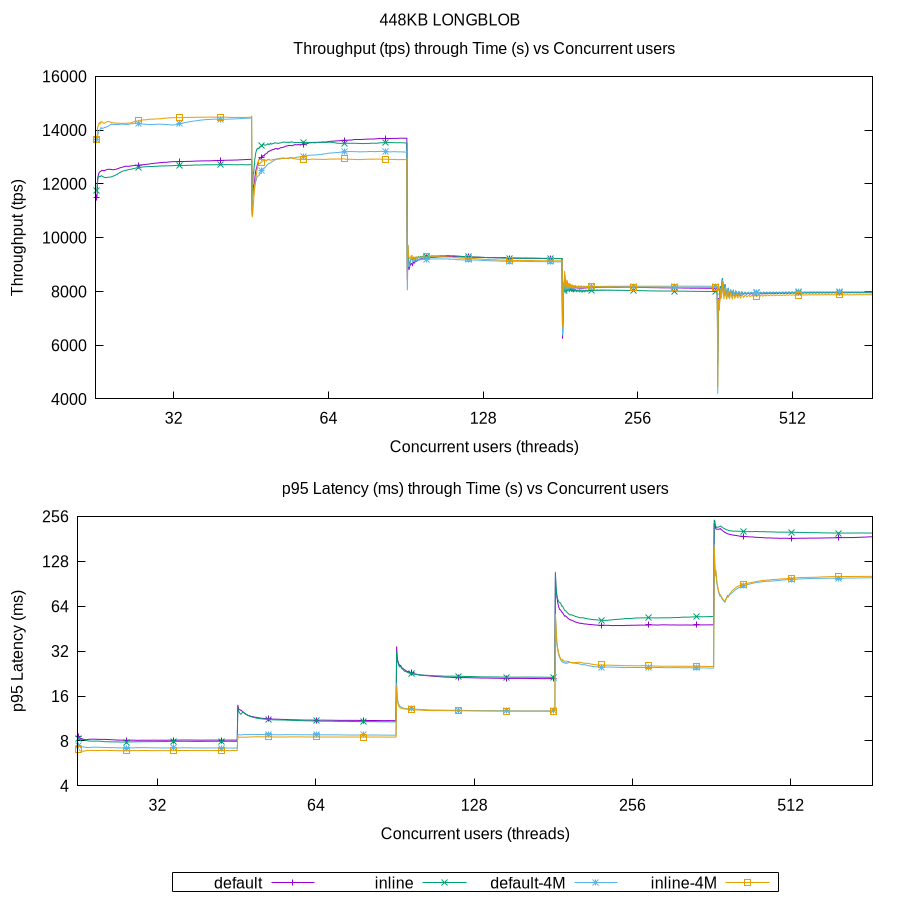
Like with the previous, the 448KB BLOB graphs also include the two new lines, default-4M and inline-4M.
It can now be observed that there are improvements in the results with only 32 concurrent users. From 64 users onwards the results show a convergence toward very high latency values, causing throughput momentum to falter. In the end, throughput is capped at approximatelly 8,000 transactions per second, meaning that each MySQL Server (of the 16) is processing 500 transactions per second. For this system topology, it can be concluded that the limitations are due to hardware rather than configuration. Once again, increasing the batch size allows transactions to complete faster, leaving more capacity subsequent transactions to execute. This proves that more data over the wire – up to a certain point (as discussed in the next section, Analysis) – improves overall performance.
Analysis
Based on the results obtained, the following indicators were observed:
- When latency was in acceptable values (e.g., 10ms to 15ms):
- Fitting the maximum possible of the BLOB in the main table (inline) resulted in better throughput.
- When latency was less acceptable (e.g., between 20ms to 100ms):
- Resorting to more rows in the Parts table (NDB$BLOB_X_Y) sometimes resulted in better throughput.
- That was mainly observable on 24KB BLOBs.
- Resorting to more rows in the Parts table (NDB$BLOB_X_Y) sometimes resulted in better throughput.
- Batching improved the overall performance, especially for BLOB values that required extra headroom (64KB and 448KB)
- VARBINARY is always more performant and therefore a better option if the total value size per row 30K bytes.
- Prohibitive high transaction latency for a very large number of concurrent users:
- That was exacerbated by larger BLOB values.
While improvements were achieved with batching and carefully tuned inline size, the system still struggled to keep up with a large number of concurrent users; indicator on Point 5. As mentioned in the Setup section, the benchmarks were run on a single high-performance machine; therefore the observed latency with a high number of concurrent users can be attributed to limited system resources, which are insuficient to provide adequate capacity for each TCP channel in these extreme scenarios. It is important to note, once again, that these users are Sysbench threads executing the maximum possible number of transactions (i.e., no rate limiting).
Regarding Point 2, it was found that sometimes storing data in the Parts table resulted in a slightly better throughput, directly correlated with lower latency. Since NDB is a highly distributed solution, it excels at delivering high throughput with low latency. When TCP channels become strained, having more data served by the a single node (the owner of the row in the inline case) might not be benefitial because that node can become a bottleneck and lag behind the overall pace of operations happening within the cluster. In such cases, distributing data across more NDB data nodes helps balance the workload, allowing operations to be processed more evenly across the cluster.
That effect is visible when comparing the default and inline configurations with 24KB BLOBs. With greater reliance on the Parts table, rows of this table are distributed across the NDB data nodes, which reduces the load on Send and LDM threads (see MaxNoOfExecutionThreads) and on each node’s respective TCP links to the SQL NDB API node. (Refer to NDB architecture for an overview of each node type in the Cluster).
Conclusion
As seen, a configurable BLOB_INLINE_SIZE gives the user much flexibility to its table layout (as explained on Part 1 of the series) and does improve the performance of the table’s BLOB operations. It was noticed that the higher the latency experienced by the overall system, i.e., large BLOB values and higher concurrency, the convergence of the inline and default became prevalent, causing throughput to falter. But if the system could scale horizontally (e.g., adding more remote nodes) then these limitations can be overcome.
It was also found that a carefully designed batch size increases throughput, especially when larger BLOB values and higher concurrency justify increased batching. However, note that an excessively large batch size can be counterproductive. As explained in the documentation of ndb-blob-read-batch-bytes, executing the BLOB operation with too much read/write can saturate the TCP channel, leading to more round-trips and/or larger packets.
