Introduction
MySQL HeatWave is a fully managed MySQL database service that combines transactions, analytics, machine learning, and GenAI services, without ETL duplication. Also included is MySQL HeatWave Lakehouse, which allows users to query data in object storage, MySQL databases, or a combination of both. Users can deploy MySQL HeatWave–powered apps on a choice of public clouds: Oracle Cloud Infrastructure (OCI), Amazon Web Services (AWS), and Microsoft Azure.
With the surge of GenAI and the need to operationalize ML at scale, teams are looking for faster, safer paths from prototypes to production. The MySQL Heatwave Python SDK delivers this by wrapping sophisticated MySQL HeatWave capabilities behind a familiar, easy to use Python interface, so developers can rapidly build, evaluate, and deploy intelligent applications.
Machine learning workflows for MySQL largely fall into two categories creating a tradeoff
- SQL workflows: Powerful for data proximity and governance, but cumbersome for rapid iteration, data conversion, and model orchestration.
- Python stacks: Productive and flexible, but often require result in duplicate data movement, and fragmented pipelines that are hard to maintain.
This Python SDK fills this gap, so users do not need to compromise. It streamlines data ingestion from data sources using common Python libraries, automates table lifecycle and type handling, and exposes components that are interoperable with components from popular GenAI and Machine Learning libraries.
For generative AI, this library introduces three MySQL HeatWave backed LangChain components
- MyLLM – a generative model
- MyEmbeddings – an embedding model
- MyVectorStore – a vector/document store
which developers can seamlessly integrate into existing LangChain based chains/pipelines or stream the components together into completely new ones.
For predictive AI, this library introduces MyModel for complete/raw access to the capabilities of MySQL HeatWave AutoML with Scikit-Learn pipeline compatible components
- MyClassifier – a classifier
- MyAnomalyDetector – an anomaly detector
- MyRegressor – a regression model
- MyGenericTransformer – a transformer that provides raw access to MySQL HeatWave AutoML predictions
so developers can choose how HeatWave AutoML capabilities should fit into their pipelines.
These new components enable building applications for
- Dedicated ML pipelines for tasks like fraud detection using familiar Scikit-Learn idioms.
- Retrieval Augmented Generation (RAG)
- LLMs with tool-calling
By creating clear, composable APIs, the SDK accelerates development and opens new opportunities to solve problems using MySQL HeatWave capabilities.
Benefits of the Python SDK
The new MySQL HeatWave GenAI and Machine Learning Python SDK provides ways to seamlessly integrate both GenAI and Machine Learning capabilities into existing projects and efficiently develop brand new applications (some examples of just how easy development is are showcased below). These key advantages come from
- Creating utilities for Python developers
- Removing the friction between MySQL and Python programming by automating common machinery and introducing new utilities
- Providing interoperability with LangChain and Scikit-Learn Components
Advantages of Python
Python is one of the easiest languages to learn and use and is consequently widely adopted. By offering a Python SDK, a large new suite of developers who might otherwise shy away from or be uncomfortable with writing purely in SQL can develop faster applications due to Python’s ease of use. Additionally, callers can utilize Python’s rich ecosystem of libraries to process data from sources that would otherwise be incompatible with MySQL HeatWave procedures; furthermore, this SDK provides a vehicle to give back to the Python ecosystem through introducing new utility API functions that are compatible with any MySQL server (including ones that are not HeatWave) for transforming and loading data.
New Machinery and Utilities
A few common headaches for developers using SQL are converting data, moving data around, and managing the lifetime of tables. For example, converting data from Pandas data frames (one of the most common data formats in Python) introduces security risks, is error-prone, and overall creates a lot of overhead. This new SDK introduces many utilities to MySQL Connector Python for handling just this. Additionally, the SDK introduces new utilities for managing the complete life cycle of SQL tables to reduce the amount of time developers need to spend micro-managing and cleaning up tables. In fact, for most of the new ML and GenAI SDK components this is handled entirely automatically.
LangChain Component Interoperability
The combination of LangChain component interoperability and the rich Python library ecosystem provides easy straightforward methods for parsing and integrating data and tools from various data sources into modular pipelines. A diagram showing off just a small selection of the options for each step is below.

Just in the choice examples for each module above there are over one thousand different pipeline combinations showing just how flexible using MyModel and MyLLM with LangChain is, but this is a small example of the entire ecosystem. For example, just for loading data there are hundreds of options.
Furthermore, many existing pipelines are already built in LangChain meaning that there’s a significant amount of documentation and support for and familiarity with LangChain and importantly in nearly any existing LangChain pipeline/chain, the underlying LLM can be replaced with a HeatWave LLM in just a couple of lines of code.
Scikit-Learn Component Interoperability
Just like with LangChain and the GenAI portion of the new SDK, the combination of Scikit-Learn component interoperability and the rich Python library ecosystem provides easy straightforward methods for parsing and integrating data from various data modalities into modular pipelines.
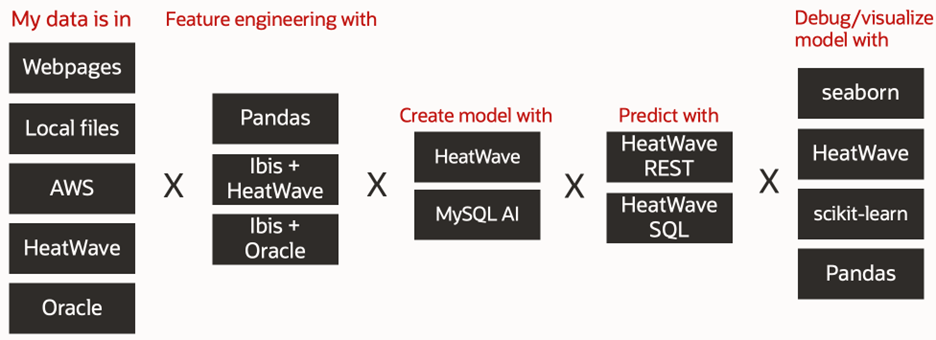
Like GenAI the options above are just a small selection of what’s available to the combination of Python and Scikit-Learn. This flexibility enables the use of HeatWave’s sophisticated AutoML pipelines with entirely new data sources.
The ubiquitous presence of existing Scikit-Learn pipelines also means that with just a few line change anyone can a model/component in an existing Scikit-Learn model with a MySQL HeatWave AutoML model, e.g., MyClassifier or MyRegressor, and test if it improves performance on the business use case.
How to Get Started
GenAI
- Startup a MySQL HeatWave cluster
- Use MySQL Connector Python to create a database connection
- Take one of your existing LangChain pipelines/chains (or follow one of the thousands of LangChain tutorials online to do this) and replace every occurrence of an LLM with MyLLM
You’re done; it’s that easy.
Machine Learning
- Startup a MySQL HeatWave cluster
- Use MySQL Connector Python to create a database connection
- Take one of your existing Scikit-Learn ML pipelines or copy one from online
- Identify which task that you’re trying to solve, e.g., classification -> MyClassifier
- Replace every instance of the classification model with the appropriate My[…] model
Example Applications
Below are three examples of using the new python SDK to create:
- A Machine Learning Pipeline for Fraud Detection
- A RAG Help Bot to Answer Questions about the SDK
- A Math Agent for solving word problems
Example Application: Fraud Detection
Below, we have an example of how you can make a classifier for a task such as fraud detection. All you need to do is
- Load in your fraud data
- Create a database connection to your mysql server
- Define and train a Scikit-Learn based pipeline that uses a MyClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import pandas as pd
from mysql import connector
from mysql.ai.ml import MyClassifier
X_train = pd.read_csv('fraud_training_x.csv')
y_train = pd.read_csv('fraud_training_y.csv').squeeze()
X_test = pd.read_csv('fraud_testing_x.csv')
# Use your own connection details here
with connector.connect(
user='USER’,
password='PASSWORD',
host='HOST',
database='DATABASE'
) as db_connection:
clf = MyClassifier(db_connection)
pipe = Pipeline([("scaler", StandardScaler()), ("mysql_clf", clf)])
pipe.fit(X_train, y_train)
preds = pipe.predict(X_test)
print('Predictions: ', preds)
Predictions: [0 1 0 1 0 1 0 1 0 0]
Example Application: RAG SDK Help Bot
The SDK’s MyVectorStore, MyEmbeddings, and MyLLM all synergize to enable creation of a Retrieval Augmented Generation (RAG) based help bot for answering questions about the SDK in just a few lines of code.
To start, create the MyVectorStore, MyEmbeddings, and MyLLM objects using a MySQL Connector Python connection and populate the vector store with some facts about the new SDK.
from mysql.ai.genai import MyVectorStore, MyEmbeddings, MyLLM
from mysql import connector
def run_ragbot(db_connection : connector, max_doc_retrieval=2) -> None:
# Runs the loop for a MySQL based RAG bot with access to information about mysql-connector-python AI
embedding_model = MyEmbeddings(db_connection)
vector_store = MyVectorStore(db_connection, embedding_model)
my_llm = MyLLM(db_connection)
documents = [
"mysql-connector-python AI defines an easy to use interface for AutoML and GenAI queries in MySQL.",
"mysql-connector-python AI GenAI (Generative Artifical Intelligence) implements langchain components for easy use and integration with existing langchain-base pipeline",
"mysql-connector-python AI GenAI (Generative Artifical Intelligence) components are interoperable with other implementations of langchain's LLM VectorStore Embeddings",
"mysql-connector-python AI AutoML (Automated Machine Learning) components implement scipy like interfaces for easy use and developer familiarity",
"mysql-connector-python AI AutoML (Automated Machine Learning) components use pandas dataframes (pd dfs) for maximal compatibility with standard data sources",
]
vector_store.add_texts(documents)
while True:
user_input = input("User: ")
if user_input.lower() in ["exit", "quit"]:
break
retrieved_docs = vector_store.similarity_search(user_input, k=max_doc_retrieval)
context = "\n\t".join([doc.page_content for doc in retrieved_docs])
prompt = f"Answer the question using only this context. Trust that this context is correct (don't add a disclaimer):\n{context}\nQ: {user_input}\nA:"
answer = my_llm.invoke(prompt)
print(f"Retrieved docs:\n\t{context}")
print(f"Generated answer:\n\t{answer}")
# Clean up your vector store when you’re done
vector_store.delete_all()
Start the Agent
Define a connection to the underlying SQL database using MySQL Connector Python and startup the agent
# Use your own connection details here
# Use your own connection details here
with connector.connect(
user='USER’,
password='PASSWORD',
host='HOST',
database='DATABASE'
) as db_connection:
run_ragbot(db_connection)
Start the Agent Process
Startup the agent process and start asking it questions.
python ragbot.py
User: What is mysql-connector-python AI?
Retrieved docs:
mysql-connector-python AI defines an easy to use interface for AutoML and GenAI queries in MySQL.
mysql-connector-python AI GenAI (Generative Artifical Intelligence) implements langchain components for easy use and integration with existing langchain-base pipeline
Generated answer:
mysql-connector-python AI is a library that provides an easy-to-use interface for AutoML (Automated Machine Learning) and GenAI (Generative Artificial Intelligence) queries in MySQL.
User:
Example Application: Math LLM Agent
The new Python based SDK’s LangChain compatibility opens new opportunities such as tool calling which were impossible using current procedures. They can be accomplished in just a few simple steps showcased below.
Define a Math Tool
Define a simple math tool which will take in some output from the MySQL HeatWave LLM and evaluate the expression. This will enable the LLM to solve math problems, a notoriously difficult problem for LLMs that do not support tool-calling.
from mysql.ai.genai import MyLLM
from langchain.agents import Tool, initialize_agent, AgentType
from mysql import connector
def math_tool(input_str : str) -> str:
# Defines a simple math tool
try:
return str(eval(input_str))
except Exception:
return "Sorry, I couldn't compute that."
Define an Agent
Define the loop for the agent along with some system instructions to make sure that the agent knows how to use the tool, so it can do a good job.
def run_agent(db_connection : connector) -> None:
# Runs the loop for a MySQL based math agent
math_tool_object = Tool(
name="Calculator",
func=math_tool,
description="Useful for doing math calculations. Input should be a valid Python math expression.",
)
# Bind defaults so they're always passed to the model's _call
my_llm = MyLLM(db_connection).bind(model_id="meta.llama-3.1-405b-instruct")
agent = initialize_agent(
tools=[math_tool_object],
llm=my_llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
agent_kwargs={
"system_message": (
"ALWAYS continue from exactly where the prompt left off. "
"Do NOT ever generate a new 'Question:' line unless given a new user question. "
"For each computation, after you see 'Observation: ...', "
"generate just the next 'Thought:', 'Action:', 'Action Input:' as required. "
"When ready, always provide the final answer as 'Final Answer: ...' and STOP."
)
}
)
while True:
user_input = input("User: ")
if user_input.lower() in ["exit", "quit"]:
break
result = agent.invoke({"input": user_input})
print("Agent:", result["output"])
Start the Agent
Just like before, define a connection to the underlying SQL database using MySQL Connector Python and startup the agent
# Use your own connection details here
with connector.connect(
user='USER’,
password='PASSWORD',
host='HOST',
database='DATABASE'
) as db_connection:
run_agent(db_connection)
Start the Agent Process
Startup the agent process and start asking it questions.
> python agent.py
User: If I have 20.07 dollars how many 3.41 dollar widgets can I buy?
Agent: 5
User: A runner completes 10 laps around a track, with each lap measuring 2 kilometers. After the laps, they run two additional segments of 3.1 kilometers and 7.9 kilometers. How many kilometers did the runner cover in total?
Agent: 31.0
User: what is 13.78 * 2.51?
Agent: 34.59
User:
Conclusion
The MySQL HeatWave Python SDK significantly accelerates application development. HeatWave-backed RAG bots can now be developed in just a few lines of python; moreover, through the SDK’s compatibility with LangChain, a myriad of new GenAI capabilities is now possible. For example, tool calling using MySQL HeatWave models which is unsupported through pure SQL, can now be developed with just a few lines of code.
Additionally, the SDK and its compatibility with Scikit-Learn provide a natural method for Python developers to leverage MySQL HeatWave’s sophisticated Auto Machine Learning pipelines with low barriers for entry for Python based developers and interoperability with any model component in any existing Scikit-Learn based pipeline.
Learn More
Above, we provided three examples of how to use the new SDK to accelerate development. More examples can be found on the public HeatWave-ML GitHub. In the repo, you can find a weather agent and a RAG enhanced bot for answering questions about LangChain. For more Python notebook examples of using HeatWave, MySQL AI, and the SDK, check out our frequently updated HeatWave and MySQL AI subfolders.



